







文章目录
一、理论知识
1.感知机
给定输入x,权重w,和偏移b,感知机输出:


2.XOR问题
感知机不能拟合XOR问题,他只能产生线性分割面

3.多层感知机
多层感知机和softmax没有本质区别,只是多加了一层隐藏层 没有隐藏层就是softmax回归,加上隐藏层就是多层感知机
4.多层感知机的从零开始实现
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
2.实现一个具有单隐藏层的多层感知机,他包含256个隐藏单元
num_inputs, num_outputs, num_hiddens = 784, 10, 256
W1 = nn.Parameter(torch.randn(
# 生成随机数字的tensor
num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(
num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
3.实现ReLU激活函数
def relu(X):
# 生成和X同样形状的全0矩阵
a = torch.zeros_like(X)
return torch.max(X, a)
4.实现模型
def net(X):
X = X.reshape((-1, num_inputs))
H = relu(X@W1 + b1) # 这里“@”代表矩阵乘法
return (H@W2 + b2)
5.计算损失
loss = nn.CrossEntropyLoss(reduction='none')
6.多层感知机的训练过程与softmax回归的训练过程完全相同
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr)
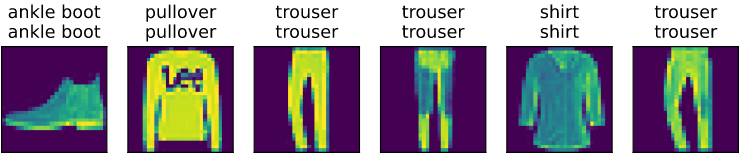
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)

7.预测
d2l.predict_ch3(net, test_iter)
5.多层感知机的简洁实现
1.导包
import torch
from torch import nn
from d2l import torch as d2l
2.模型实现
net = nn.Sequential(nn.Flatten(),
nn.Linear(784,256),
nn.ReLU(),
nn.Linear(256, 10))
def init_weights(m): #初始化模型参数
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01) #使用正态分布进行赋值,均值为0,方差为0.01
net.apply(init_weights) #将每一层进行初始化
3.训练
batch_size, lr, num_epochs = 256, 0.1, 10
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
train_iter.num_workers = 0
test_iter.num_workers = 0
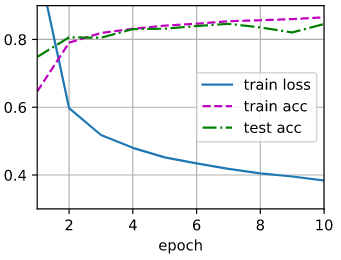
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
【相关总结】
1.torch.randn()
生成随机数字的tensor
这些随机数字满足标准正态分布
torch.randn(size) size可以为一个数字或者一个元组
import torch
x = torch.randn(3)
y = torch.randn(2,3)
print(x)
print(y)
tensor([-0.1201, -1.0340, 0.7885])
tensor([[-0.5694, 0.0461, 1.0315],
[-1.0342, -0.9757, -0.1844]])
2.torch.zeros_like()
torch.zeros_like(input, dtype=None, layout=None, device=None, requires_grad=False)
返回一个与给定输入张量形状和数据类型相同,但所有元素都被设置为零的新张量。
import torch
x = torch.tensor([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
y = torch.zeros_like(x)
print(y)
tensor([[0, 0, 0],
[0, 0, 0],
[0, 0, 0]])
3.nn.CrossEntropyLoss()
损失函数的交叉熵损失函数
reduction用于控制输出的类型,默认为’mean’
| none | 没有操作,会返回多个样本的损失,每个样本的损失值都会被返回,不会进行求和和平均操作 |
|---|---|
| mean | 输出的结果求平均值 |
| sum | 输出的结果求和 |
怎么计算呢【参考博客】
假设一共有三种类别,batchsize=1,那么输入size为(1,3),具体值为torch.Tensor([[-0.7715, -0.6205,-0.2562]])。标签值为target = torch.tensor([0]),这里标签值为0,表示属于第0类。loss计算如下
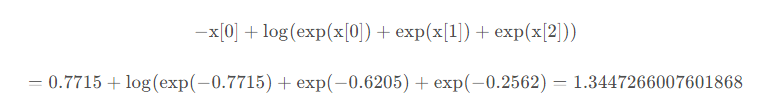
import torch
import torch.nn as nn
import math
loss=nn.CrossEntropyLoss()
input=torch.Tensor([[-0.7715, -0.6205,-0.2562]])
target = torch.tensor([0])
output = loss(input, target)
print(output)
tensor(1.3447)
4.net.apply(weights_init)
进行模型初始化使用的方法之一
会递归的将weights_init函数应用到字模块进行初始化,也包括自身。
net = nn.Sequential(nn.Flatten(),
nn.Linear(784,256),
nn.ReLU(),
nn.Linear(256, 10))
def init_weights(m): #初始化模型参数
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01) #使用正态分布进行赋值,均值为0,方差为0.01
net.apply(init_weights) #将每一层进行初始化
比如我们的代码,会对两个nn.Linear层分别进行初始化
















 1126
1126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











