







能力有限看图理解把。以下的图值得反复琢磨
常用的字典的数据结构
hashmap skip list Trie前缀树 FST
Trie前缀树
Trie:相邻有序的term更又可能具有相同的前缀值,那么通过前缀存储就可以节省存储空间
但是你会发现后缀也重复,但是前缀树无法满足后缀也复用
FST 有限状态转换器 (编译原理学过的)
FSM(Finite State Machines)有限状态机: 表示有限个状态集合以及这些状态之间转移和动作的数学模型。其中一个状态被标记为开始状态,0个或更多的状态被标记为final状态
FSA:有限状态接收机
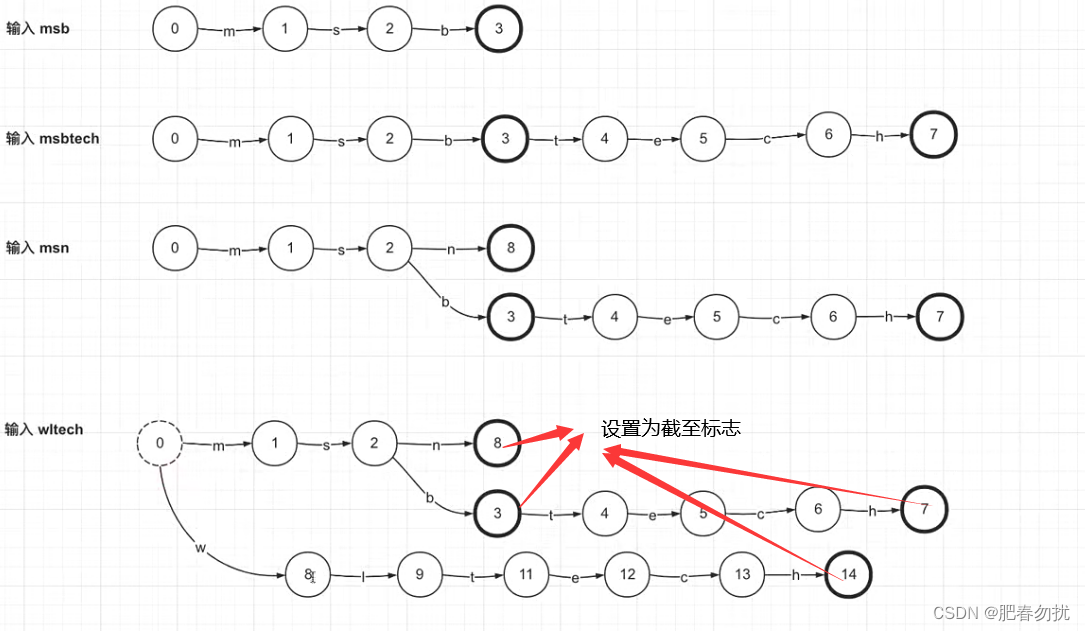
这样输入最后一个就变成了这样
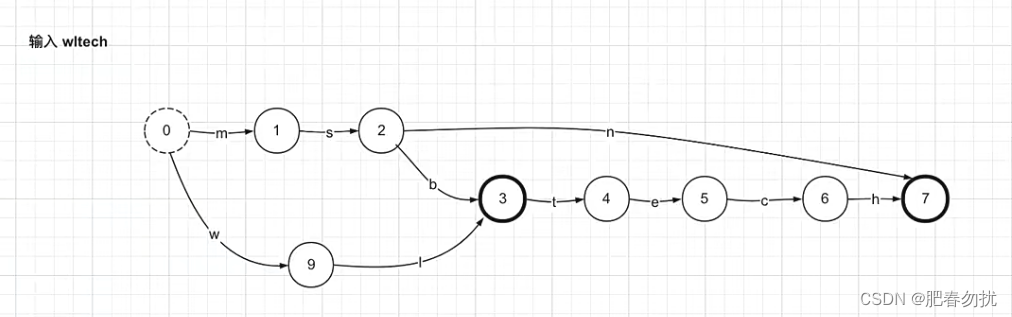
确定性:在任何给定状态下,对于任何输入,最多只能遍历一个transtion
非循环:不可能重复遍历同一个状态
Final唯一性:当且仅当有限状态机在输入序列的末尾处于最终状态时,才接受特定的输入序列
以上例子,如果输入‘wl’会怎样?其实就是可以搜索到的了。因为l指向的节点3已经是final节点了。为解决这样的问题,引出FST
FST简述及它的查询过程
FST:有限状态转化机
FST最重要的功能是可以实现key到value的映射,相当于HashMap<K,V>。FST的查询速度比hashMap慢一点,但是内存消耗比hashMap小很多。FST在lucene大量使用:倒排索引的存储,同义词词典的存储,搜索关键字建议等等。
对于es来说,它是基于lucence开发,底层的数据结构使用的就是fst,它的主要优点:
查询快
极致压缩空间占用
特性:
确定性:在任何给定状态下,对于任何输入,最多只能遍历一个transtion
非循环:不可能重复遍历同一个状态
transducer: 转化器有相关的值(payload),final节点会输出一个值
比起前面的前缀树以及FSA,在存储的时候多了一个value值。
考虑以下输入字符:

后边那个其实就是他的出度。
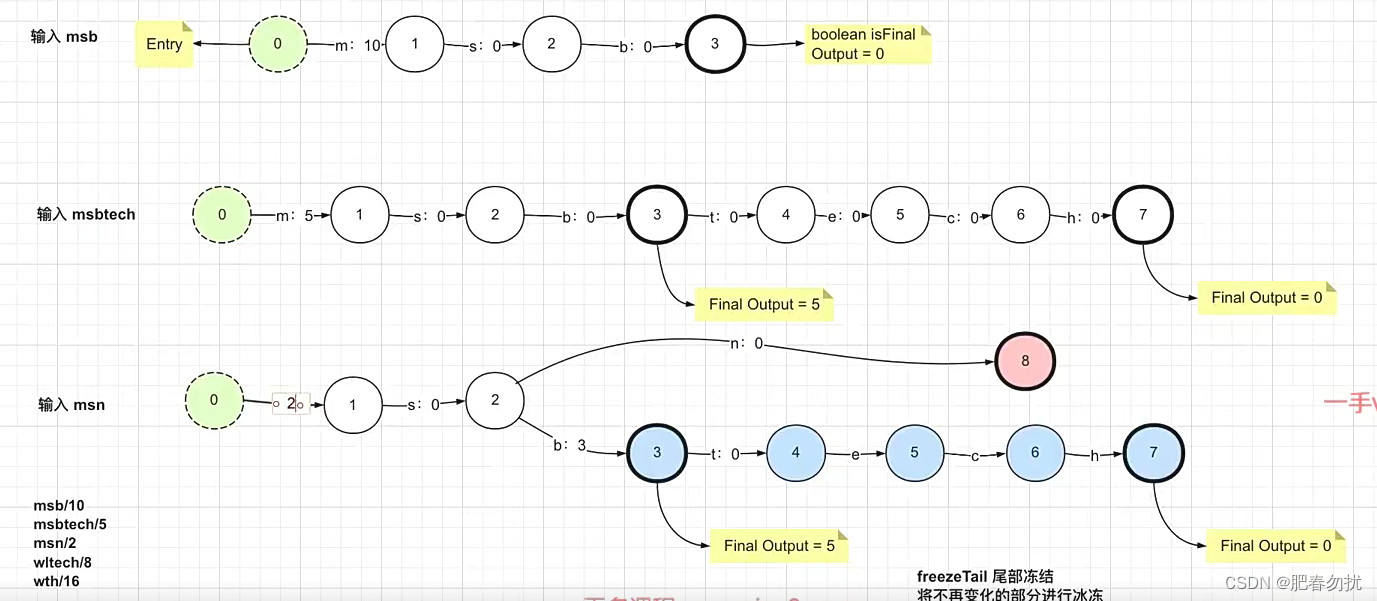
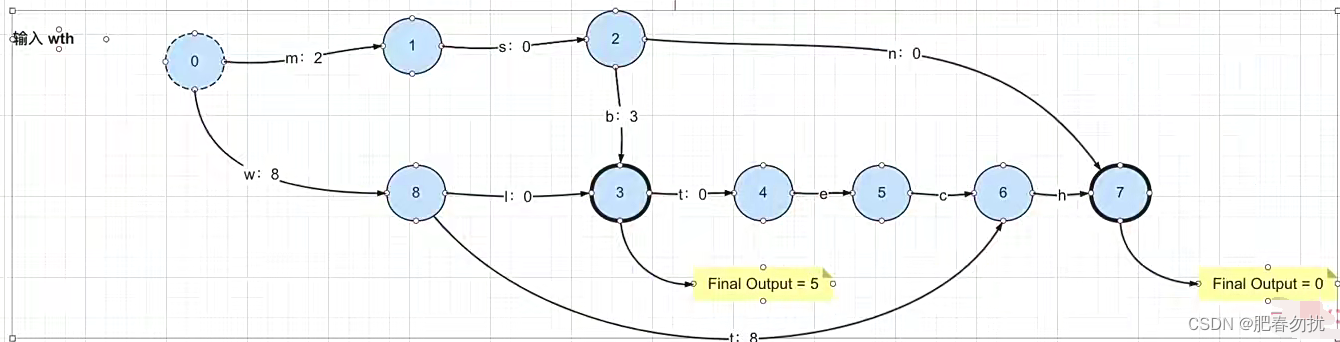
看上边那个过程 ,当你的出度满足你所需的出度的时候才算匹配成功。就比如wi去匹配的时候就匹配不到了。 我们加了一个value 和Finaloutput
能力有限看图理解把。以上的图值得反复琢磨















 510
510











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









