






目录
前言
大家好,我是白熊快跑。距离上次博客良久,再不更新大学就要过完了。最近毕业设计项目用到了基于树莓派、Ubuntu、ROS的视觉识别检测,视觉任务之一是识别4种不同的外卖袋。参考《ROS机械臂开发与实践》(王晓云,2023),主流做法有三种,对应三个ROS包:
- find_object_2d
- ORK
- darknet_ros
其中darknet_ros【1】基于YOLO算法,而YOLO我一直久仰大名。怎么用,官方指南说得差不多了,接下来我们重点说怎么用自己的数据集训练YOLO模型,并且用到darknet_ros里。
实际中,博主使用系统为Ubuntu22.04,任务是训练4类外卖袋的YOLOv3模型,并且新旧版都试了一次。
这个是新版ultralytics训练结果返图:

这个是darknet_ros下用旧版pjreddieYOLOv3模型的识别结果:
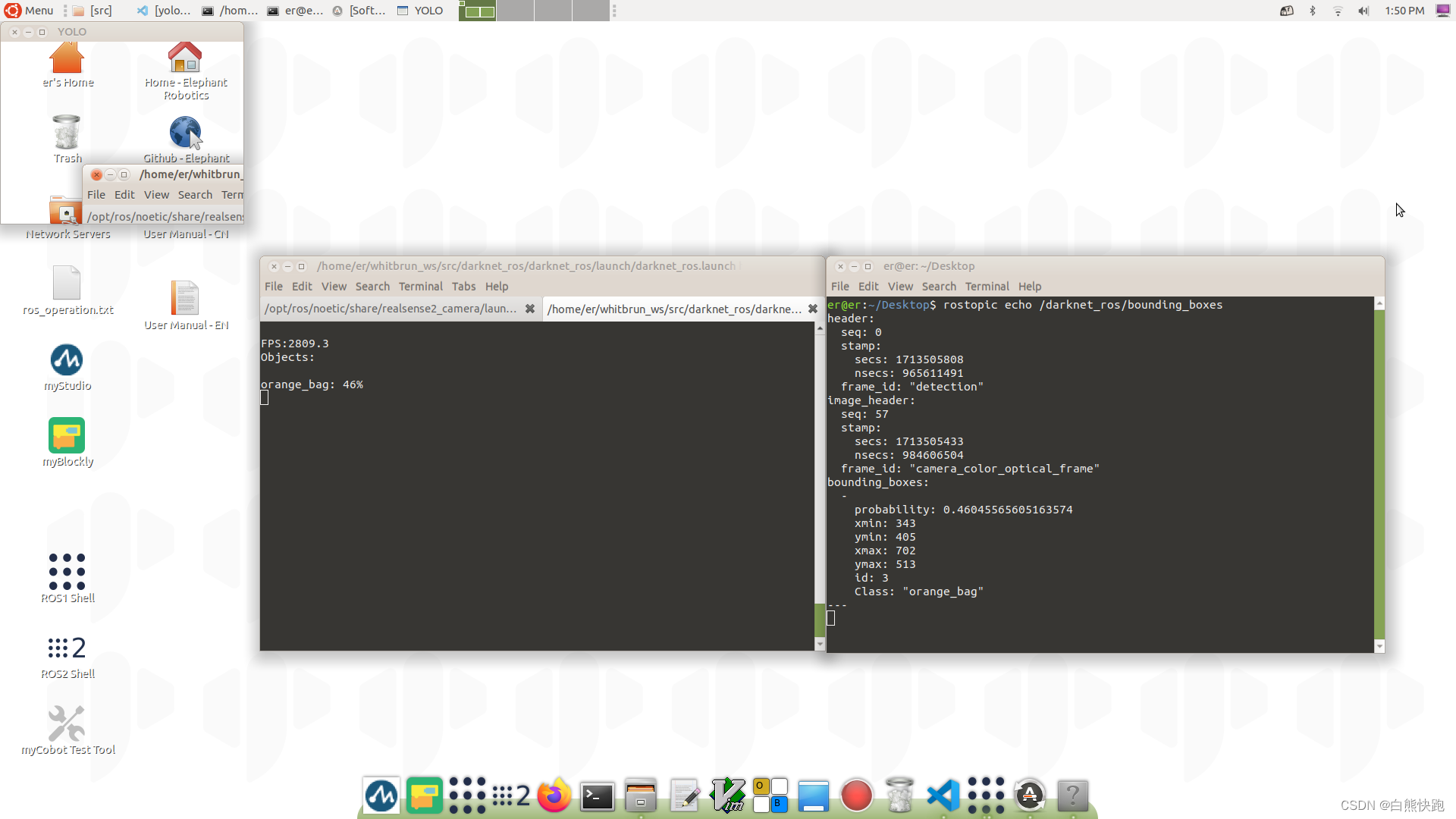
这方面网上资料其实并不少,但考虑到绝大部分教程没将新旧两个版本区别开一次性说清楚;而且大都步骤繁杂,虽然正确,但不利于理解。现在博主特意将这方面内容都整理成一篇博客,力求避免上述通病,通过一篇博客,让大家在使用YOLOv3训练自己数据集这块儿,不在门外,而在门内。
正文如下。
【1】darknet_ros项目链接:leggedrobotics/darknet_ros: YOLO ROS: Real-Time Object Detection for ROS (github.com)
正文:
一、新旧版比较与使用
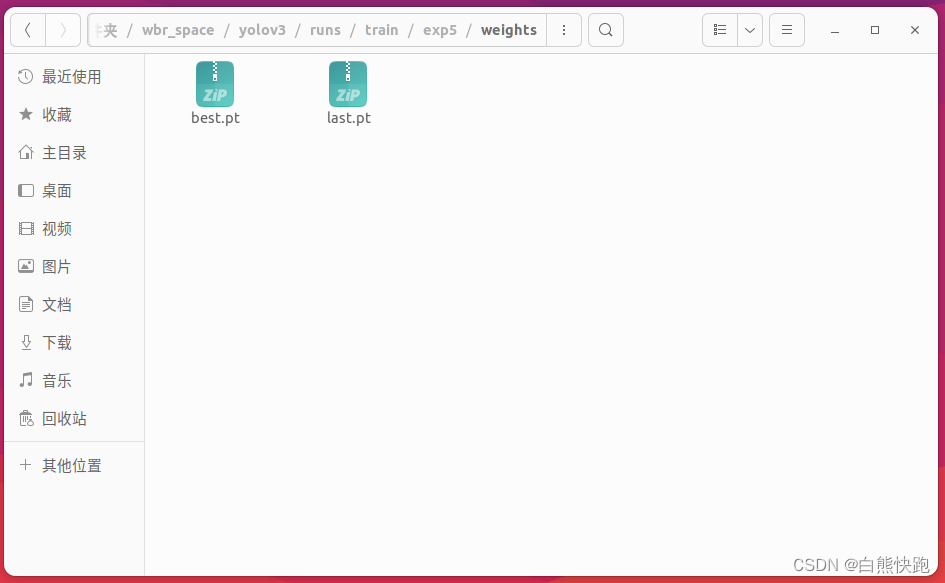
博主歪打正着,新旧两个版本都用到了——先是用了新版本ultralytics训练,得到了训练结果*.pt文件;结果发现不对啊,想要在darknet_ros里使用YOLOv3模型,还得是用旧版本pjreddie训练的*.weights。clone新旧版本github:
下面是新旧版简单对比。
| 版本 | 主要Python库依赖 | 训练结果 |
|---|---|---|
| ultralytics(新) | PyTorch | *.pt(如图1-1) |
| pjreddie(旧) | CUDA、CUDNN、TensorFlow | *.weights(如图1-2) |
二、训练准备(ultralytics版)
0 检查环境&安装依赖
博主自己的环境是Python 3.8.18和pytorch-lightning 2.1.3,这一步可参考博客yolov3模型训练——使用yolov3训练自己的模型_yolov3.pt对应的yaml文件是哪个-CSDN博客(虽然这篇说的是Windows版...)
首先,大家按照自己需要安装PtTorch。
第二步,依据requirements按照其他依赖,如下操作:
$ cd yolov3
$ pip install -r requirements.txt最后,使用 git 命令直接下载YOLOv3(ultralytics版)的源码工程:
$ git clone https://github.com/ultralytics/yolov3.git
$ cd yolov31 数据集准备
1.1 收集图片&打标签
首先,收集一大堆*.jpg图片(你也可以用别的格式,只是后面要把每张图片的路径都写到一个文件里,需要你自行修改),但不必着急全部丢到一个文件夹,分类放好有利于后面打标签。
第二步,下载imgImg,并打开软件,步骤如下(见图2-1和图2-2)。注意,这一步应当不做任何输出标签格式的调整,输出*.xml文件就是我们要的东西。
$ git clone https://github.com/HumanSignal/labelImg.git
$ cd labelImg
$ python labelImg.py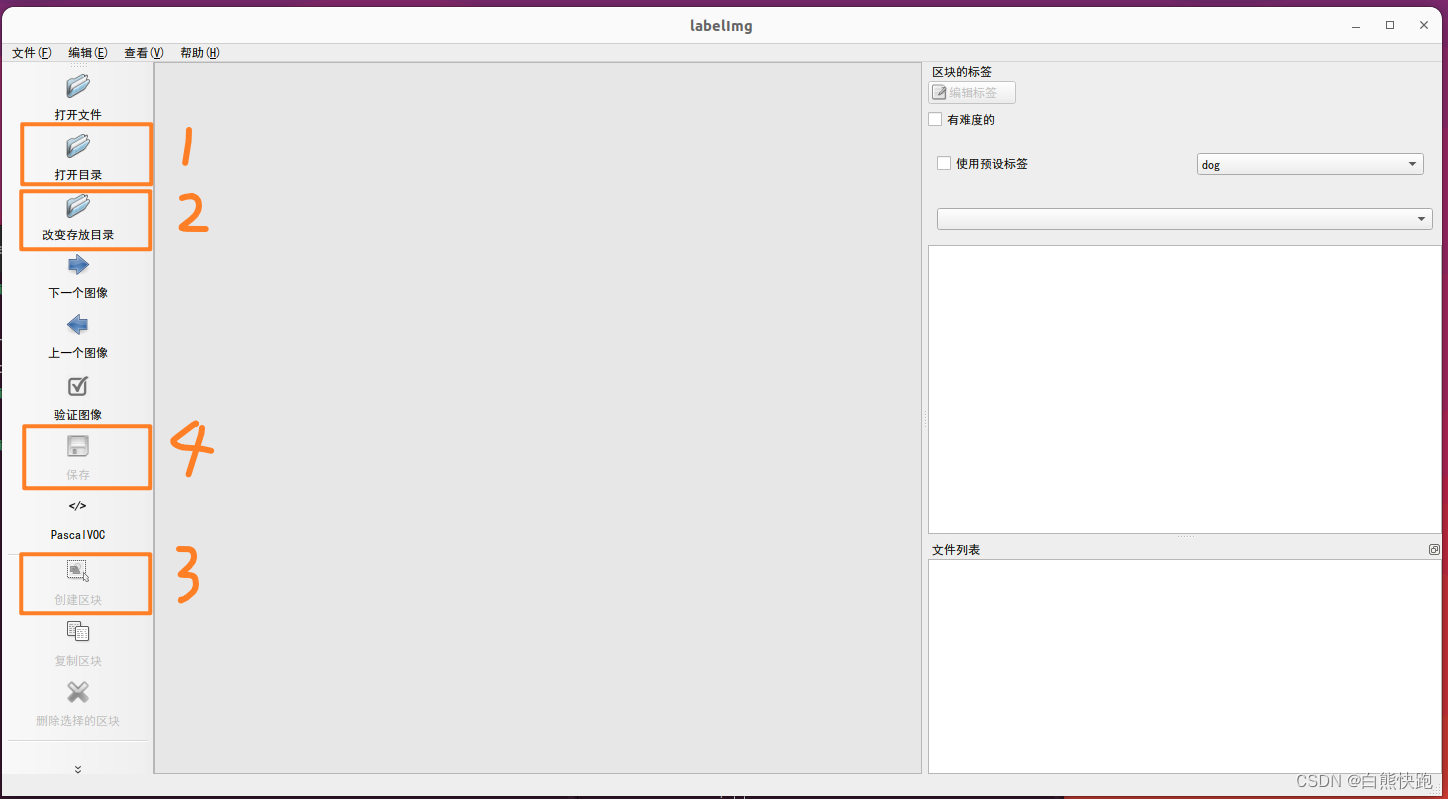
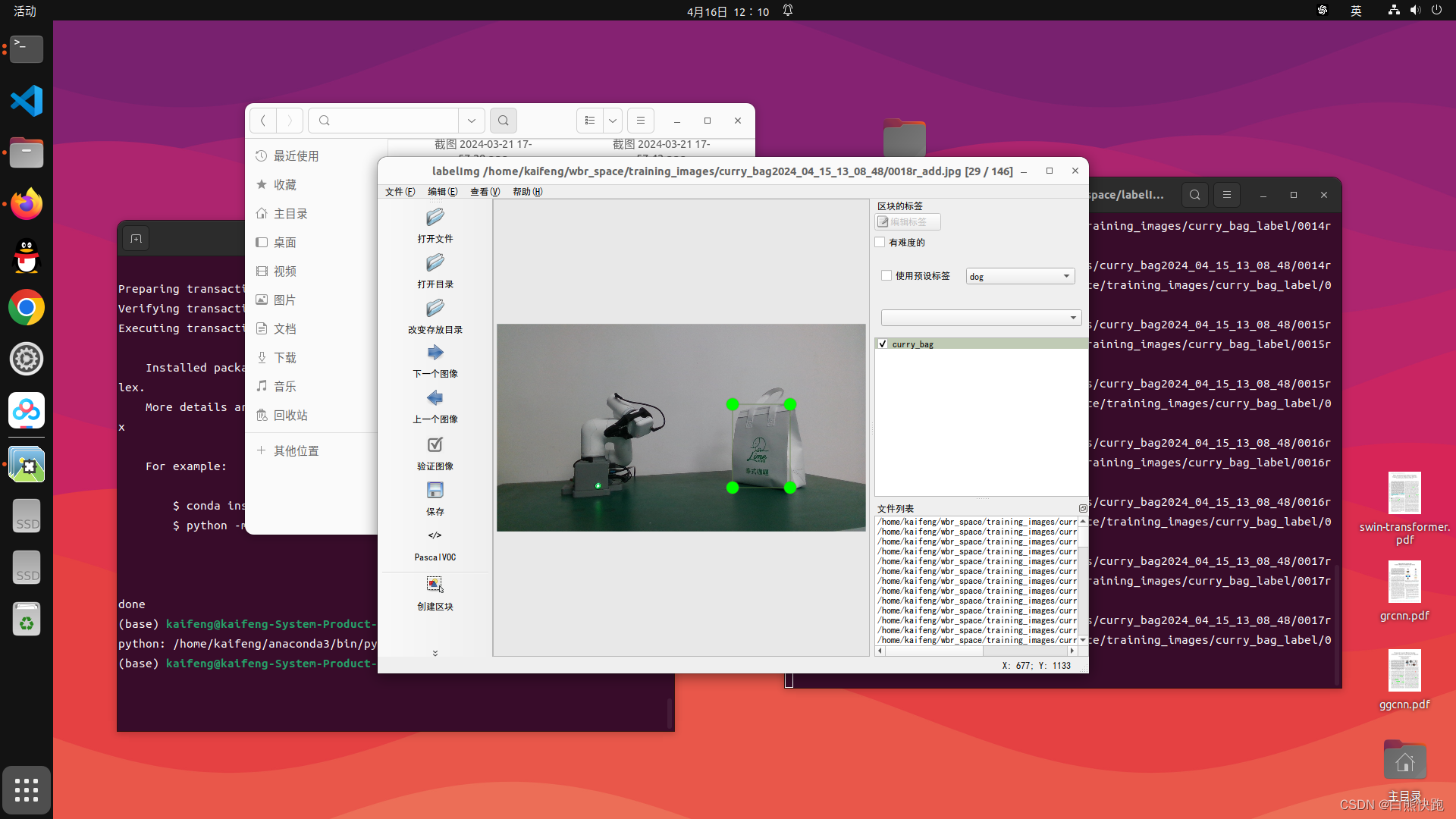
这里再介绍几个labelImg常见的快捷键,不然这一步可太废手了。(这么良心的博主都不点赞收藏吗?)
- 上方工具栏 查看->自动保存模式 :开启自动保存后,点击下一张自动保存标签结果
- 上方工具栏 查看->单一类别模式 :如果某一次打标签所有图片都是只出现一个类别的物体,选中这个模式以后,对下一张图片打标签就不需要再输入标签名了(所以推荐大家把同一类图片放一个文件夹,标完一个文件夹就把labelImg关掉,再标就再打开)
- 快捷键 w :创建一个矩形框(区块)
- 快捷键 d :下一张图片
第三步,标好所有图片后,在根目录下data文件夹下新建两个文件夹Images和Annotations,将所有图片*.jpg文件丢到Images文件夹下,所有标签*.xml文件丢到Annotations文件夹(这个命名后面会用上)。检查两者数量是否相同,不相同回上一步补足。
1.2 数据集加工(ultralytics版)
划重点,ultralytics版和pjreddie版数据集加工步骤是不同的!是不同的!是不同的!下面一张表格来说说两者的异同:
版本 加工步骤 加工结果 ultralytics版
- 将图片数据集的所有文件名分成训练集、测试集、验证集,比例7:2:1,分别写入三个txt文件中
- 将xml标签文件转成YOLO的txt标签文件
- 将图片数据集的所有文件和标签文件夹的所有txt标签文件分别放入三个文件夹内
images和labels两个文件夹,每个文件夹内分别有train、test、val三个文件夹;images的三个文件夹存着所有的jpg文件,labels的三个文件夹存着所有txt文件 pjreddie版
- 将图片数据集的所有文件名分成训练集、测试集、验证集,比例9:0.9:0.1,分别写入三个txt文件中
- 将xml标签文件转成YOLO的txt标签文件,并生成三个txt文件内含训练集、测试集、验证集图片文件的路径
takeaway_train.txt、takeaway_test.txt、takeaway_val.txt
ultralytics版加工步骤如下,一共三步,分别编写3个Python文件并运行:
1. 编写createImgTxt.py
这一步是为了生成含有训练集、测试集、验证集所有文件名的三个文件,方便后续的操作(但并不直接用到训练过程中)
先在根目录./data下新建一个ImageSets文件夹,再在darknet根目录下新建createImgTxt.py文件。
# createImgTxt.py
import os
import random
trainval_percent = 0.9
train_percent = 2/9
xmlfilepath = 'data/Annotations/'
txtsavepath = 'data/ImageSets/'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent) #0.9*num
tr = int(tv * train_percent) #num*0.9*(2/9)
trainval = random.sample(list, tv)
test = random.sample(trainval, tr)
ftrainval = open(txtsavepath+'trainval.txt', 'w')
ftest = open(txtsavepath+'test.txt', 'w')
ftrain = open(txtsavepath+'train.txt', 'w')
fval = open(txtsavepath+'val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n' # without the postfix
if i in trainval:
ftrainval.write(name) # train and test take 0.9 at total
if i in test:
ftest.write(name) # test takes 0.2
else:
ftrain.write(name) # train takes 0.7
else:
fval.write(name) # val takes 0.1
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()然后,命令行运行createImgTxt.py。
$ cd yolov3
$ python createImgTxt.py结果如下图所示,其中trainval.txt是中间产物,可删。

2. 编写createLabels.py
在yolov3根目录下新建createLabels.py文件。其中,txt标签结果保存到./data/labels里面。实际使用时需要把classes数组里的类别名称改成你的类别名称,并且注意记下这个顺序(后面3.2配置文件修改会用,顺序不对会识别结果对不上)。博主的顺序是curry_bag、coffee_bag、red_bag、orange_bag。
# createLabels.py
#-- coding:utf-8 -
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test','val']
classes = ['curry_bag','coffee_bag','red_bag','orange_bag'] # 修改成自己数据集的类别名称
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('data/Annotations/%s.xml' % (image_id))
out_file = open('data/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
print(wd)
for image_set in sets:
if not os.path.exists('data/labels/'):
os.makedirs('data/labels/')
image_ids = open('data/ImageSets/%s.txt' % (image_set)).read().strip().split()
for image_id in image_ids:
convert_annotation(image_id)然后,命令行运行createLabels.py。
$ cd yolov3
$ python createLabels.py3. 编写createImgDir.py
在yolov3根目录下新建createImgDir.py文件。最终生成的images文件夹和labels文件夹放置在./data/Takeaway_data,文件夹路径请大家根据自己实际修改,本章3.2将会用到。
# createImgDir.py
import os
import shutil
imgset_dir = 'data/ImageSets/'
img_from_dir = 'data/Images/'
img_to_dir = 'data/Takeaway_data/images/'
label_from_dir = 'data/labels/'
label_to_dir = 'data/Takeaway_data/labels/'
def move_file(dataset_class):
with open(imgset_dir+dataset_class+'.txt','r',encoding='utf-8') as f:
i_to_dir = os.path.join(img_to_dir,dataset_class)
l_to_dir = os.path.join(label_to_dir,dataset_class)
if not os.path.exists(i_to_dir):
os.makedirs(i_to_dir)
if not os.path.exists(l_to_dir):
os.makedirs(l_to_dir)
for line in f.readlines():
line = line.strip('\n')
i_from_dir = img_from_dir + str(line) + '.jpg'
l_from_dir = label_from_dir + str(line) + '.txt'
shutil.copy(i_from_dir,i_to_dir)
shutil.copy(l_from_dir,l_to_dir)
move_file('train')
move_file('test')
move_file('val')然后,命令行运行createImgDir.py。
$ cd yolov3
$ python createImgDir.py最终分别在images和labels两个文件夹下生成train、test、val三个文件夹,取train为例图片文件如图2-3,标签文件图2-4所示。
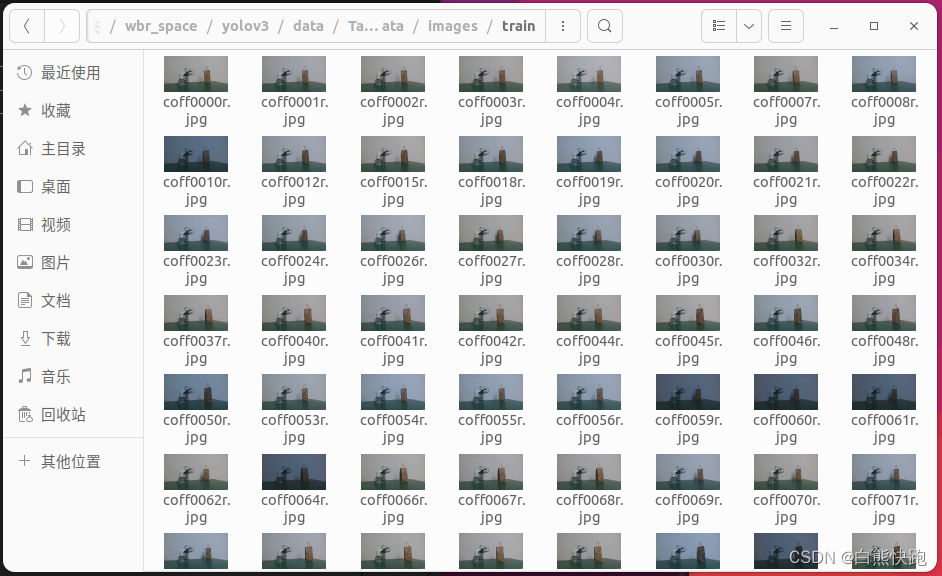
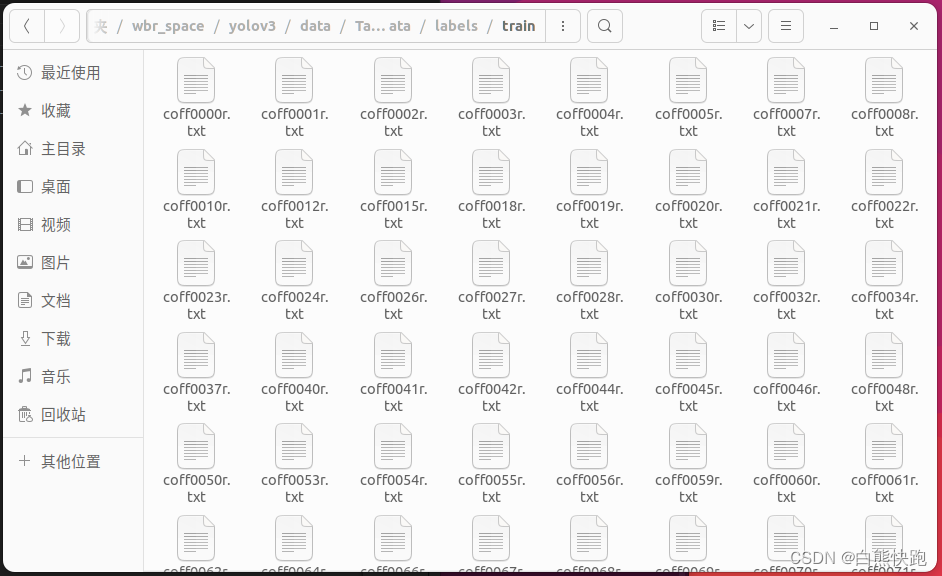
2 初权重准备
加载预训练权重进行网络的训练可以减小缩短网络训练时间,并且提高精度。预训练权重越大,训练出来的精度就会越高,但是其检测的速度就会越慢。不同的预训练权重对应着不同的网络层数。
预训练权重下载地址:Releases · ultralytics/yolov3 (github.com)
参考博客:yolov3模型训练——使用yolov3训练自己的模型_yolov3.pt对应的yaml文件是哪个-CSDN博客
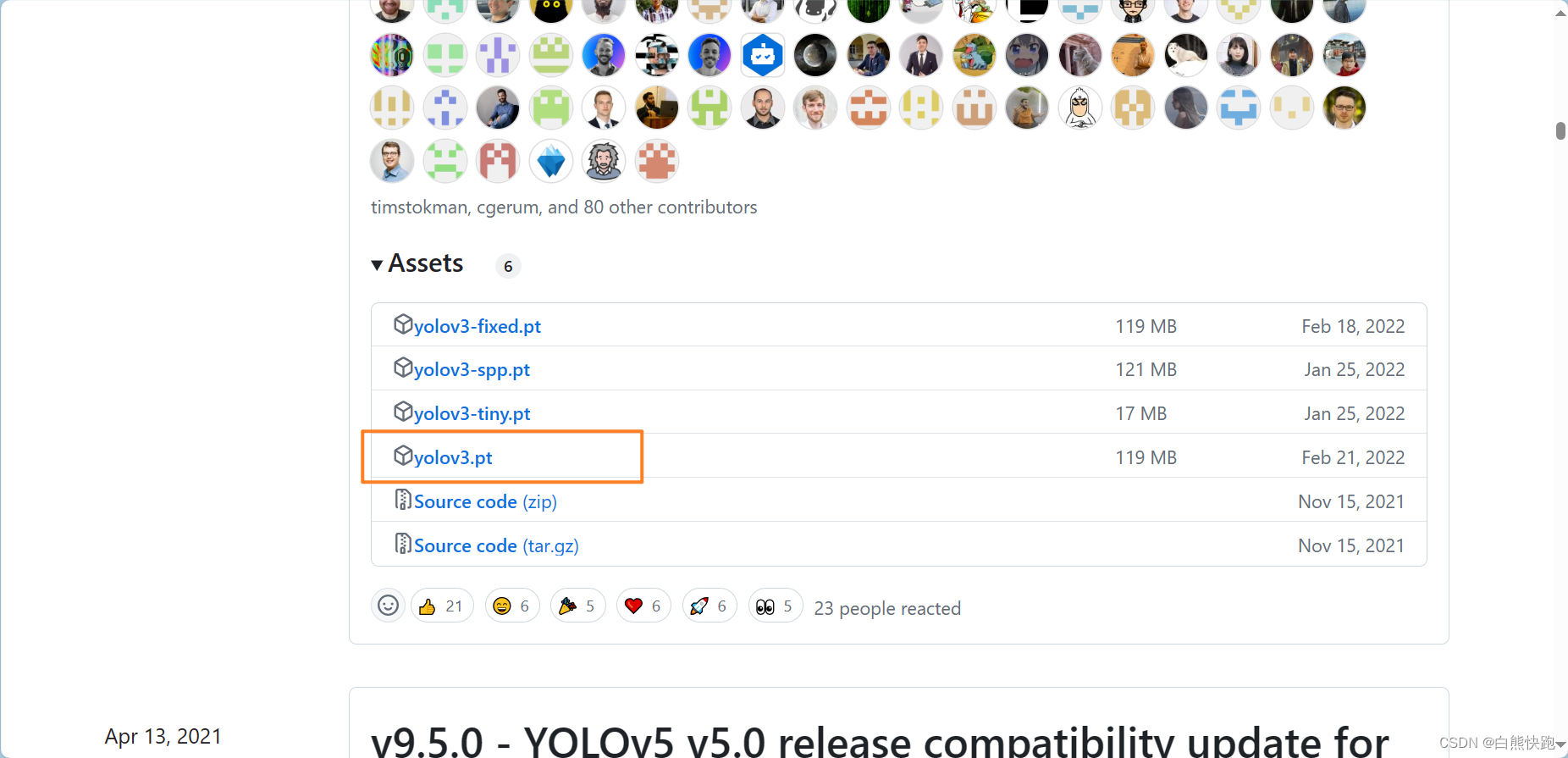
如图2-5,博主选择下载yolov3.pt初权重,并放置在yolov3根目录下新建一个weights里(如图2-6),后面会用。大家可根据自身需要下载其他权重,注意这里的选择需和配置信息里的cfg选择对应。
3 配置信息修改(ultralytics版)
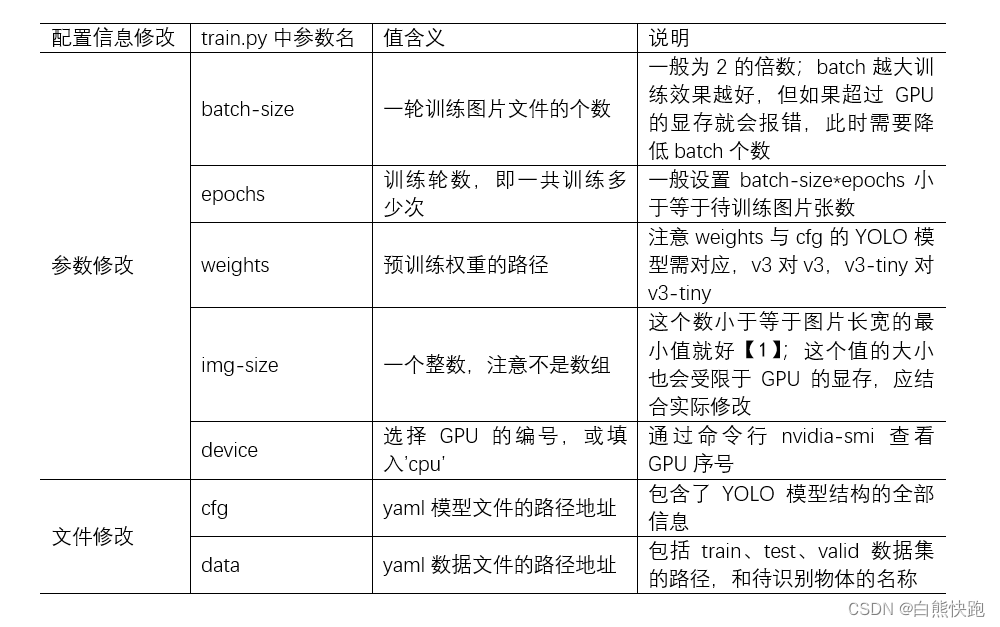
用自己数据集训练YOLO模型,说到底就是修改YOLO配置信息,一般有7项,可以分为两类,修改的位置有以下区别(详细说明看下两节):
- 参数修改:仅需要在根目录下train.py修改对应参数的默认值
- 文件修改:不仅需要在根目录下train.py修改对应参数的默认路径,还需要修改对应文件的文件内容
【1】参考资料:YOLO V5 测试图像时 img_size 的设置问题_yolov5 imgsize-CSDN博客
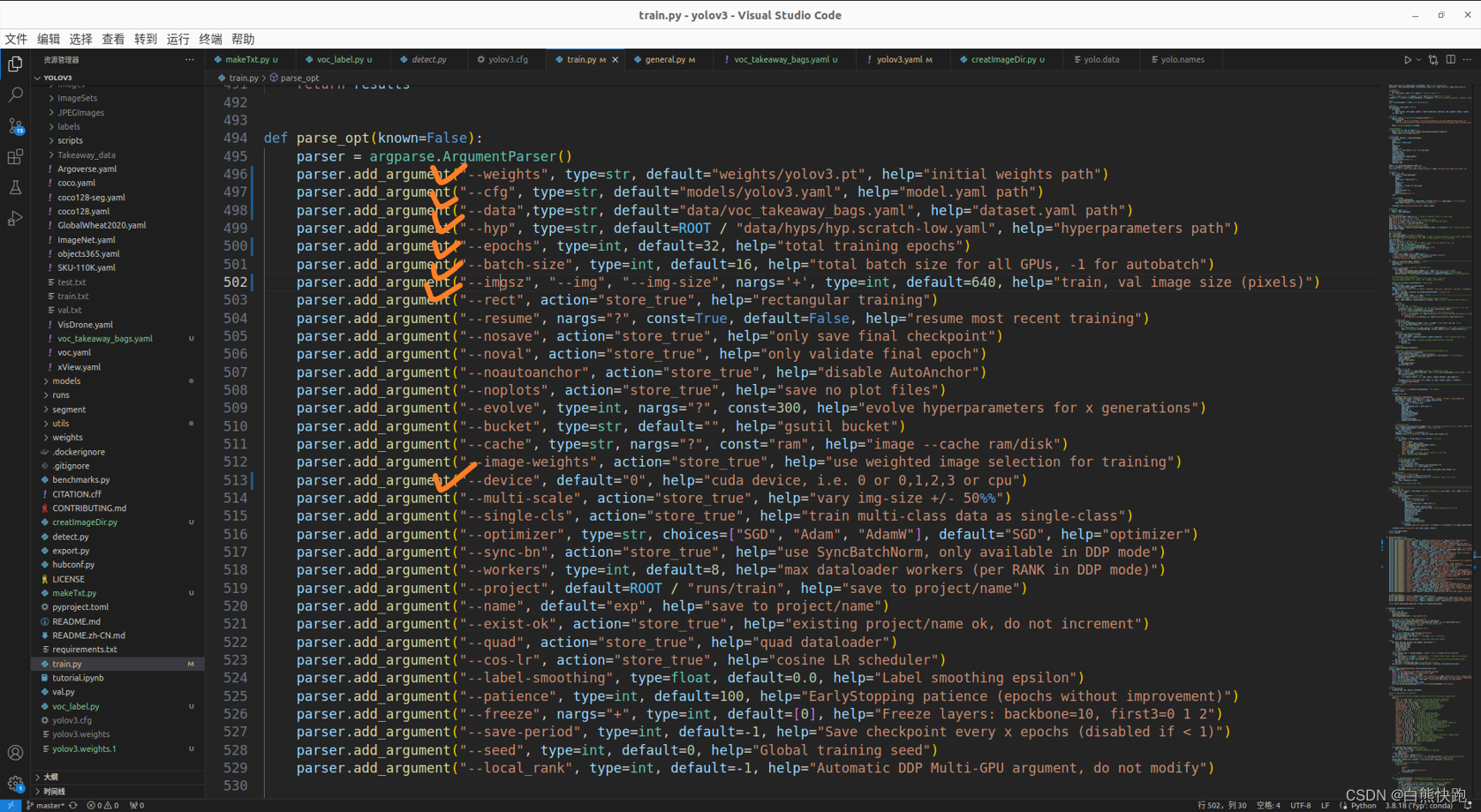
博主自己在train.py对这7项配置信息的修改如下图。
3.1 配置参数修改
下面这一节来说说博主自己在train.py修改的参数值。
- batch-size
设定为16,测试过更高,但显卡带不动哩...
- epochs
设定为32,博主图片训练集总共图片大概440张,16*32>=440
- weights
选择前面我们下载好的yolov3.pt的路径
- img-size
博主图片数据集每张图片都是1280x720(宽x高),这里可以写720,实际是填了640
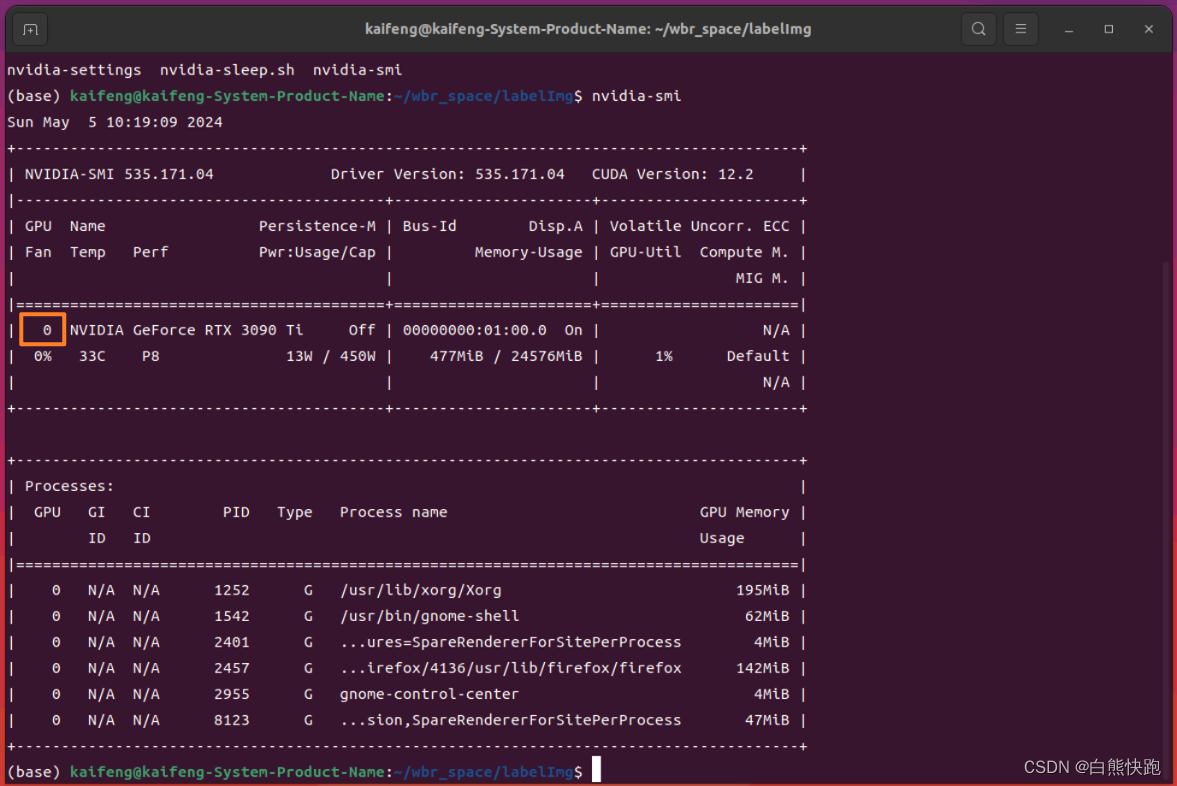
- device
英伟达显卡用命令行查看GPU序号
$ nvidia-smi结果如图2-9,博主只有一张显卡(恰好比较好呢~),序号为0,因此这里也填0即可
3.2 配置文件修改
- 修改cfg文件
第一步,找到根目录下./models/yolov3.yaml文件。
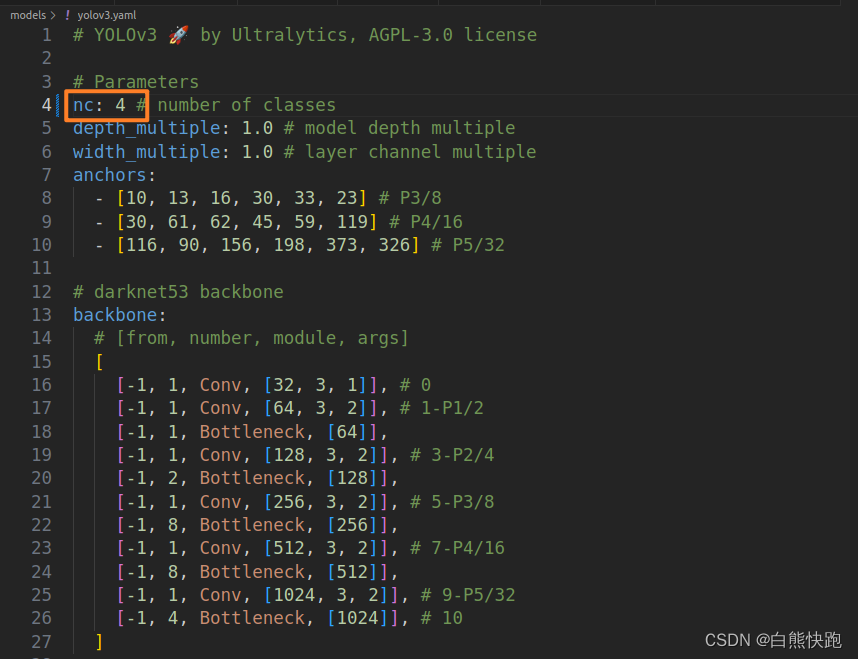
第二步,修改其中nc(number of classes)为4。
最后,记得在train.py里修改data的值为当前yolov3.yaml路径(如图2-8)。
- 修改data文件
第一步,找到根目录下./data/voc.yaml文件。voc.yaml本来是VOC数据集的配置文件,我们基于它修改成自己的版本。这里博主复制一份,更名为voc_takeaway_bags.yaml。
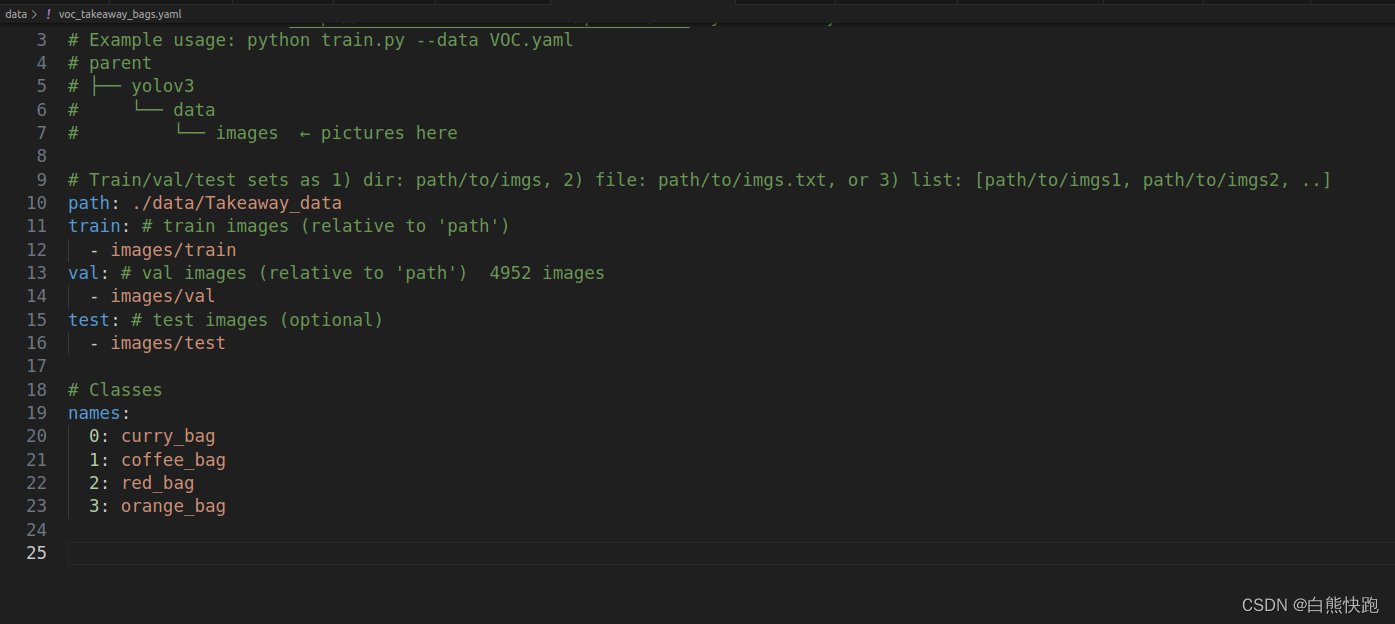
第二步,修改train、test、valid数据集的文件夹路径,并填入4个识别类的名称curry_bag、coffee_bag、red_bag、orange_bag(与1.2第二步对应)。接着把后面所有内容(基本是关于VOC数据集下载)删掉,最终效果如下图。
最后,记得在train.py里修改data的值为当前voc_takeaway_bags.yaml路径(如图2-8)。
三、训练开始及结果测试(ultralytics版)
直接运行train.py,开始训练。训练的结果保存在根目录下./runs/train下。
测试识别效果,步骤参考链接:yolov3模型训练——使用yolov3训练自己的模型_yolov3.pt对应的yaml文件是哪个-CSDN博客
下面重点说说pjreddie版的训练和使用。
四、训练准备(pjreddie版)
0 检查环境&安装依赖
YOLOv3(pjreddie版)使用的是开源的神经网络框架 Darknet53,有 CPU 和 GPU 两种模式。默认使用的是 CPU 模式。
首先,我们 git 命令直接下载YOLOv3(pjreddie版)的源码工程:
$ git clone https://github.com/pjreddie/darknet如果想用CPU版可以跳过以下步骤,直接到0.2。下面重点说一下使用GPU版需要做的操作,分为以下两步:
- 安装CUDA和CUDNN
- 修改pjreddie版工程根目录下Makefile
0.1 pjreddie版使用GPU版本
1. 安装CUDA和CUDNN
使用GPU版,首先需要安装CUDA和CUDNN,这里可以参考博客:Ubuntu 20.04安装CUDA & CUDNN 手把手带你撸_ubuntu20.04安装cuda-CSDN博客
博主CUDA安装的是12.2版本,CUDNN安装的是Ubuntu22.04的对应版本。
2. 修改pjreddie版工程根目录下Makefile
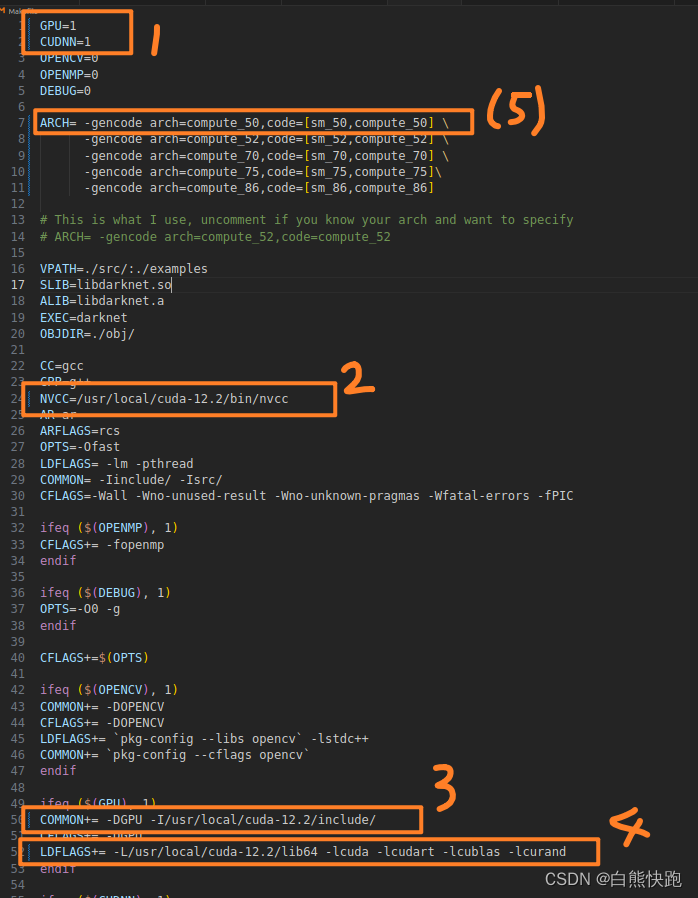
修改的地方有 4 处。其中,第 1 处 GPU=1,CUDNN=1,表示使用 GPU 和 CUDNN,若使用 CPU 的话,置为 0 即可;第 2 处将 NVCC 设为本地安装 nvcc 的实际目录;第 3 处将 COMMON+ 设为本地 cuda 的头文件目录;第 4 处将 LDFLAGS+ 设为 cuda 的库目录(参考博客:从零开始带你一步一步使用YOLOv3训练自己的数据_yolov3训练过程-CSDN博客)第5处是博主实践中遇到了报错,搜索之后,删掉了含30和35的那两行。
0.2 开始编译
完成以上步骤,到darknet根目录下,make工程(无论CPU版还是GPU版都需要)。
$ cd darknet
$ make1 数据集准备
1.1 收集图片&打标签
这一步和前面第二章的1.1是一模一样的(文件的保存路径名也一模一样!),请大家返回前面查看。
1.2 数据集加工(pjreddie版)
划重点,ultralytics版和pjreddie版数据集加工步骤是不同的!是不同的!是不同的!下面一张表格来说说两者的异同:
版本 加工步骤 加工结果 ultralytics版
- 将图片数据集的所有文件名分成训练集、测试集、验证集,比例7:2:1,分别写入三个txt文件中
- 将xml标签文件转成YOLO的txt标签文件
- 将图片数据集的所有文件和标签文件夹的所有txt标签文件分别放入三个文件夹内
images和labels两个文件夹,每个文件夹内分别有train、test、val三个文件夹 pjreddie版
- 将图片数据集的所有文件名分成训练集、测试集、验证集,比例9:0.9:0.1,分别写入三个txt文件中
- 将xml标签文件转成YOLO的txt标签文件,并生成三个txt文件内含训练集、测试集、验证集图片文件的路径
takeaway_train.txt、takeaway_test.txt、takeaway_val.txt
pjreddie版加工步骤如下,一共两步,分别编写2个Python文件并运行。
1. 编写createImgTxt.py
这一步是为了生成含有训练集、测试集、验证集所有文件名的三个文件,方便后续的操作(但并不直接用到训练过程中)其中大部分词句和ultralytics版是一致的,只是训练集、测试集、验证集比例设置上的差异。
先在根目录./data下新建一个ImageSets文件夹,再在yolov3根目录下新建createImgTxt.py文件。
#createImgTxt.py
import os
import random
trainval_percent = 0.1 # val and test take 0.1 at total
train_percent = 0.9
xmlfilepath = 'data/Annotations'
txtsavepath = 'data/ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
test = random.sample(trainval, tr) # for test set
ftrainval = open('data/ImageSets/trainval.txt', 'w')
ftest = open('data/ImageSets/test.txt', 'w')
ftrain = open('data/ImageSets/train.txt', 'w')
fval = open('data/ImageSets/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n' # without the postfix
if i in trainval:
ftrainval.write(name)
if i in test:
ftest.write(name) # test takes 0.1*0.9
else:
fval.write(name) # val takes 0.1*0.1
else:
ftrain.write(name) # train takes 0.9
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
然后,命令行运行createImgTxt.py。
$ cd yolov3
$ python createImgTxt.py2. 编写createLabels_and_ImagePaths.py
在darknet根目录下新建createLabels_and_ImagePaths.py文件,这一步不仅将全部xml标签文件转换到txt标签文件,并保存到./data/labels里面,而且生成三个txt文件内含训练集、测试集、验证集图片文件的路径(在本章3.2中将会被使用)
其中,txt标签文件全部保存到./data/labels里面。实际使用时需要把classes数组里的类别名称改成你的类别名称,并且注意记下这个顺序(后面3.2配置文件修改会用,顺序不对会识别结果对不上)。博主的顺序是curry_bag、coffee_bag、red_bag、orange_bag。
# createLabels_and_ImagePaths.py
#-*- coding:utf-8 -*
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test','val']
classes = ['curry_bag','coffee_bag','red_bag','orange_bag']
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('data/Annotations/%s.xml' % (image_id))
out_file = open('data/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('data/labels/'):
os.makedirs('data/labels/')
image_ids = open('data/ImageSets/%s.txt' % (image_set)).read().strip().split()
list_file = open('data/takeaway_%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write('%s/data/Images/%s.jpg\n' % (wd, image_id))
convert_annotation(image_id)
list_file.close()然后,命令行运行createLabels_and_ImagePaths.py。
$ cd yolov3
$ python createLabels_and_ImagePaths.py2 初权重准备
命令行输入指令下载,下载到根目录./weights下。
$ cd darknet
$ mkdir weights
$ cd weights
$ wget https://pjreddie.com/media/files/darknet53.conv.74也可以通过博主上传的百度网盘下载呢(馋.jpg):
链接:https://pan.baidu.com/s/1X_4p68_gDmkOikj0-5QNEQ?pwd=1231
提取码:1231
3 配置信息修改(pjreddie版)
pjreddie版配置信息的修改依然分成两类:
- 参数修改:需要到YOLO网络架构文件里面修改(博主选择了yolov3-voc.cfg文件)
- 文件修改:cfg文件除了包括参数信息,还需要做其他修改以适应识别对象的种类。此外还需要修改data文件和names文件。
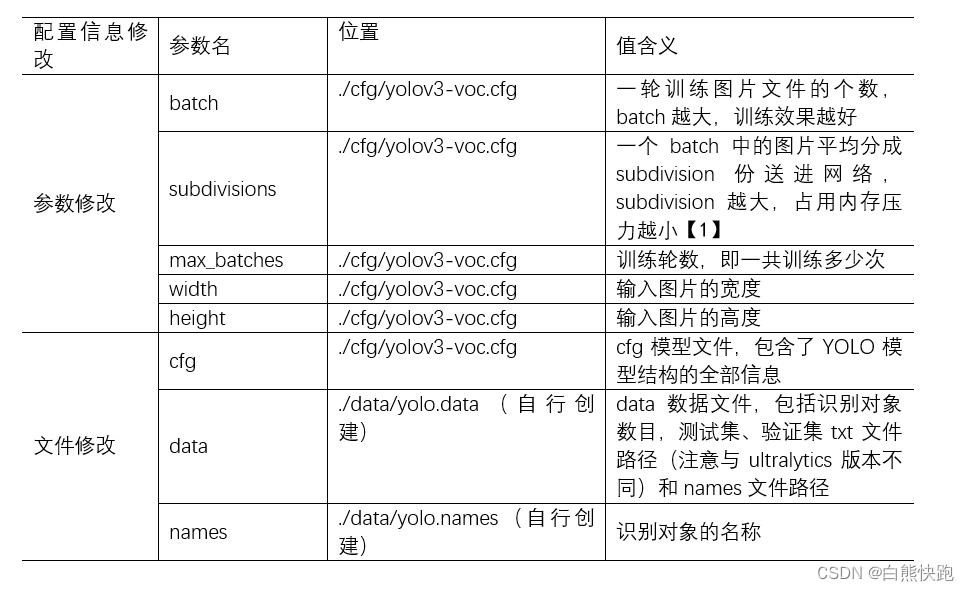
【1】yolov3.cfg参数解读 - 玩转机器学习 - 博客园 (cnblogs.com)
3.1 配置参数修改
在./cfg/yolov3-voc.cfg中,修改5项参数的值。
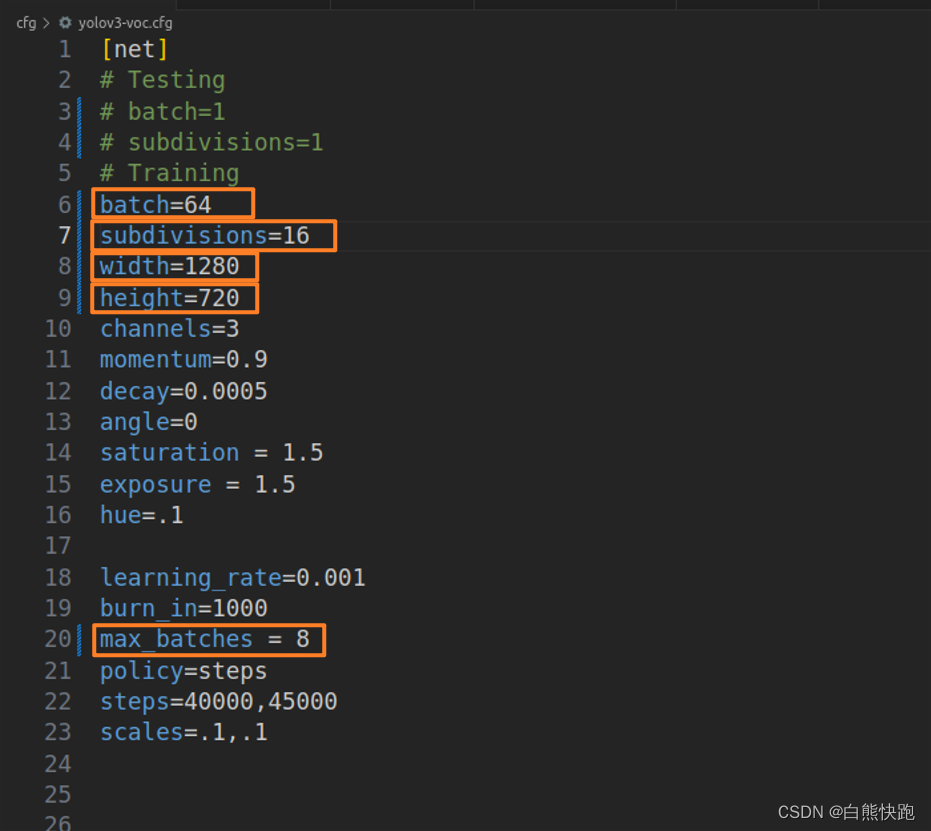
3.2 配置文件修改
- 修改cfg文件
参考博客链接,这个地方这篇讲得很详细:darknet-yolov3训练自己的数据集(超详细) - AnswerThe - 博客园 (cnblogs.com)
在./cfg/yolov3-voc.cfgyolov3-voc.cfg中,总共会搜出3个含有yolo的地方。每个地方都必须要改2处:
filters = 27
classes = 4
其中:filters=3*(5+classes_len),且classes_len为待识别对象种类数目,这里以我的工程为例3*(5+4)=27。此外,可修改:random = 0(是否要多尺度输出,默认是1,显存小可改为0)
- 新建并编写yolo.data文件
在./data/下新建yolo.data文件,写入以下内容,请大家按照自己识别的类别和数据集路径修改。(实际项目val集数据太少,用test集代替之)

- 新建并编写yolo.names文件
在./data/下新建yolo.names文件,由上到下顺序需和本章1.2顺序一致。

五、训练开始及结果使用(pjreddie版)
1 训练与测试
回到darknet根目录,输入以下指令开始训练。(博主电脑只有一个GPU,使用了GPU0,查看GPU序号的操作和第二章3.1一致)
$ cd darknet
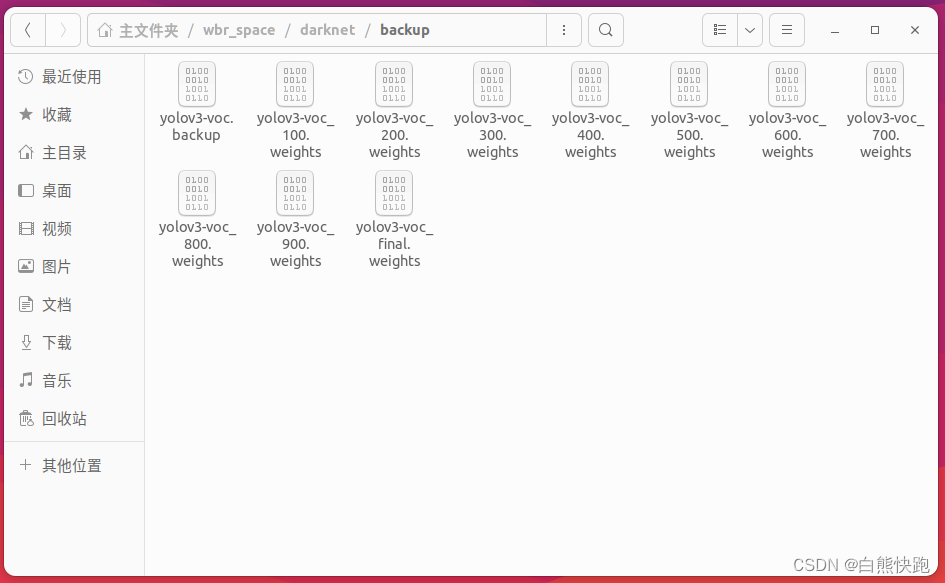
$ ./darknet detector train data/yolo.data cfg/yolov3-voc.cfg weights/darknet53.conv.74 -gups 0在这个过程中在backup文件夹下会保存对应迭代次数的中间结果,前1000次内每100次保存一个,超过1000次,每1000保存一次。
参考博客:Darknet——yolo3训练自己的数据集+在ros环境下实现目标检测实战教程(二)——训练自己的权重文件_yolov3评估权重-CSDN博客
训练的结果如下图。
选择一张图片测试,在darknet根目录下可以看到predictions.jpg的更新。
$ ./darknet detect cfg/yolov3-voc.cfg backup/yolov3-voc_900.weights data/Images/coff0018r.jpg2 将训练好的模型运用到darknet_ros
参考博客链接:在ROS中实现darknet_ros(YOLO V3)检测以及训练自己的数据集_darknet_ros编译错误cmake error at /usr/share/cmake-3.5-CSDN博客,这篇后面讲到了使用自己的权重
首先默认大家已经修改过darknet_ros订阅的摄像头topic,可以正确获取到当前摄像头的图像信息。接下来分三步讲解将训练好的模型运用到darknet_ros:
第一步,darknet_ros/darknet_ros/yolo_network_config里面有两个文件夹cfg和weights,把之前用到的yolov3-voc.cfg文件和训练好的权重文件yolov3-voc_900.weights移动到到相应的文件夹。注意cfg文件夹下原有一个yolov3-voc.cfg,因此把我们拖入的文件重命名为yolov3-voc_takeaway.cfg。
第二步,在darknet_ros/darknet_ros/config里面复制yolov3-voc.yaml重命名为yolov3-voc_takeaway.yaml,修改其中内容如下。注意将config_file和weight_file替换成自己训练好的cfg文件和weights文件名。
yolo_model:
config_file:
name: yolov3-voc_takeaway.cfg
weight_file:
name: yolov3-voc_900.weights
threshold:
value: 0.3
detection_classes:
names:
- curry_bag
- coffee_bag
- red_bag
- orange_bag
第三步,进入darknet_ros/darknet_ros/launch,将darknet_ros.launch里面network_param_file修改为自己的yolov3-voc_takeaway.yaml(注意区分该yaml文件和上面的cfg,别弄混),如下:
<!-- ROS and network parameter files -->
<arg name="ros_param_file" default="$(find darknet_ros)/config/ros.yaml"/>
<arg name="network_param_file" default="$(find darknet_ros)/config/yolov3-voc_takeaway.yaml"/>最后,启动摄像头,启动darknet_ros,检查是否能检测出想要的结果。
至此本篇博客就结束啦,我是白熊快跑,如果这篇内容有帮到你,或者想看到更多这样风格的博客,记得关注我哦~
求点赞求收藏,你的点赞和收藏就是对我最大的鼓励!我们下期见~















 1504
1504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









