







顺序表
1-8
对于顺序存储的长度为N的线性表,访问结点和增加结点的时间复杂度分别对应为O(1)和O(N)。
- T
- F
1-10
对于顺序存储的长度为N的线性表,删除第一个元素和插入最后一个元素的时间复杂度分别对应为O(1)和O(N)。
- T
- F
1-9
若某线性表最常用的操作是存取任一指定序号的元素和在最后进行插入和删除运算,则利用顺序表存储最节省时间。
- T
- F
1-11
线性表L如果需要频繁地进行不同下标元素的插入、删除操作,此时选择顺序存储结构更好。
- T
- F
2-10
在N个结点的顺序表中,算法的时间复杂度为O(1)的操作是:
- A.访问第i个结点(1≤i≤N)和求第i个结点的直接前驱(2≤i≤N)
- B.在第i个结点后插入一个新结点(1≤i≤N)
- C.删除第i个结点(1≤i≤N)
- D.将N个结点从小到大排序
2-14
顺序表中第一个元素的存储地址是100,每个元素的长度为2,则第5个元素的地址是( )。
- 108
第5个的位序是4,第一个位序为0,A=100+2*4=108
(第5个元素的头,也是第4个元素的尾)
2-15
已知二维数组 A 按行优先方式存储,每个元素占用 1 个存储单元。若元素 A[0][0] 的存储地址是 100,A[3][3] 的存储地址是 220,则元素 A[5][5] 的存储地址是:
- 300
设每行有x个元素,A[0][0]=100,A[3][0]=100+3 * 1 * x,A[3][3]=A[3][0]+3 * 1=220,所以解得x=39,A[5][5]=100+5*39+5=300
单链表、循环链表、双向链表
1-13
在具有N个结点的单链表中,访问结点和增加结点的时间复杂度分别对应为O(1)和O(N)。
- T
- F
1-14
将N个数据按照从小到大顺序组织存放在一个单向链表中。如果采用二分查找,那么查找的平均时间复杂度是O(logN)。
- T
- F
1-15
若用链表来表示一个线性表,则表中元素的地址一定是连续的。
- T
- F
1-16
链表 - 存储结构
链表中逻辑上相邻的元素,其物理位置也一定相邻
- T
- F
1-17
链表 - 存储结构
链表是一种随机存取的存储结构。
- T
- F
2-16
线性表若采用链式存储结构时,要求内存中可用存储单元的地址
(1分)
- B.连续或不连续都可以
2-17
在具有N个结点的单链表中,实现下列哪个操作,其算法的时间复杂度是O(N)?
(2分)
- A.在地址为p的结点之后插入一个结点
- B.删除开始结点
- C.遍历链表和求链表的第i个结点
- D.删除地址为p的结点的后继结点
2-18
将线性表La和Lb头尾连接,要求时间复杂度为O(1),且占用辅助空间尽量小。应该使用哪种结构?
(2分)
- A.单链表
- B.单循环链表
- C.带尾指针的单循环链表
- D.带头结点的双循环链表
2-19
线性表L在什么情况下适用于使用链式结构实现?
(1分)
- A.需不断对L进行删除插入
- B.需经常修改L中的结点值
- C.L中含有大量的结点
- D.L中结点结构复杂
2-20
对于一个具有N个结点的单链表,在给定值为x的结点后插入一个新结点的时间复杂度为
(2分)
- A.O(1)
- B.O(N/2)
- C.O(N)
- D.O(N2)
2-21
链表不具有的特点是:
(1分)
- A.插入、删除不需要移动元素
- B.方便随机访问任一元素
- C.不必事先估计存储空间
- D.所需空间与线性长度成正比
2-22
设h为不带头结点的单向链表。在h的头上插入一个新结点t的语句是:
(2分)
- A.h=t; t->next=h->next;
- B.t->next=h->next; h=t;
- C.h=t; t->next=h;
- D.t->next=h; h=t;
2-23
在单链表中,若p所指的结点不是最后结点,在p之后插入s所指结点,则执行
(2分)
- A.s->next=p; p->next=s;
- B.s->next=p->next; p=s;
- C.s->next=p->next; p->next=s;
- D.p->next=s; s->next=p;
2-24
带头结点的单链表h为空的判定条件是:
(2分)
- A.h == NULL;
- B.h->next == NULL;
- C.h->next == h;
- D.h != NULL;
2-25
对于一非空的循环单链表,h和p分别指向链表的头、尾结点,则有:
(2分)
- A.p->next == h
- B.p->next == NULL
- C.p == NULL
- D.p == h
2-26
在双向循环链表结点p之后插入s的语句是:
(3分)
- A.p->next=s; s->prior=p; p->next->prior=s ; s->next=p->next;
- B.p->next->prior=s; p->next=s; s->prior=p; s->next=p->next;
- C.s->prior=p; s->next=p->next; p->next=s; p->next->prior=s;
- D.s->prior=p; s->next=p->next; p->next->prior=s; p->next=s;
2-27
在双向链表存储结构中,删除p所指的结点,相应语句为:
(3分)
- A.p->prior=p->prior->prior; p->prior->next=p;
- B.p->next->prior=p; p->next=p->next->next;
- C.p->prior->next=p->next; p->next->prior=p->prior;
- D.p->next=p->prior->prior; p->prior=p->next->next;
2-29
To insert s after p in a doubly linked circular list, we must do:
(3分)
- A. p->next=s; s->prior=p; p->next->prior=s ; s->next=p->next;
- B. p->next->prior=s; p->next=s; s->prior=p; s->next=p->next;
- C.s->prior=p; s->next=p->next; p->next=s; p->next->prior=s;
- D. s->prior=p; s->next=p->next; p->next->prior=s; p->next=s
2-30
To delete p from a doubly linked list, we must do:
(3分)
- A.p->prior=p->prior->prior; p->prior->next=p;
- B.p->next->prior=p; p->next=p->next->next;
- C.p->prior->next=p->next; p->next->prior=p->prior;
- D.p->next=p->prior->prior; p->prior=p->next->next;
2-28
将两个结点数都为N且都从小到大有序的单向链表合并成一个从小到大有序的单向链表,那么可能的最少比较次数是:
(2分)
- A.1
- B.N
- C.2N
- D.NlogN
2-31
已知表头元素为c的单链表在内存中的存储状态如下表所示:
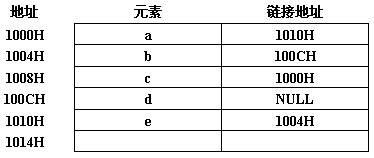
现将f存放于1014H处,并插入到单链表中,若f在逻辑上位于a和e之间,则a、e、f的“链接地址”依次是:
(2分)
- A.1010H, 1014H, 1004H
- B.1010H, 1004H, 1014H
- C.1014H, 1010H, 1004H
- D.1014H, 1004H, 1010H
2-32
For a non-empty doubly linked circular list, with h and t pointing to its head and tail nodes, respectively, the FALSE statement is:
(2分)
- A.t->next == h
- B.h->pre == t
- C.t->pre->next == t
- D.h->next == t
2-33
For a non-empty doubly linked circular list, with h and t pointing to its head and tail nodes, respectively, the TRUE statement is:
(2分)
- A.t->next == h
- B.h->pre == NULL
- C.t->next == h->next
- D.h->next == t
3-2多选
链表 - 时间复杂度
在包含 n 个数据元素的链表中,▁▁▁▁▁ 的时间复杂度为 O(n)。
(2分)
- A.访问第 i 个数据元素
- B.在第 i (1≤i≤n) 个结点后插入一个新结点
- C.删除第 i (1≤i≤n) 个结点
- D.将 n 个元素按升序排序
4-1填空
设单链表的结点结构为(data,next),next为指针域,已知指针px指向单链表中data为x的结点,指针py指向data为y的新结点 , 若将结点y插入结点x之后,则需要执行以下语句:
py->next=px->next;
px->next=py;
5-1
下列代码的功能是返回带头结点的单链表L的逆转链表。
List Reverse( List L )
{
Position Old_head, New_head, Temp;
New_head = NULL;
Old_head = L->Next;
while ( Old_head ) {
Temp = Old_head->Next;
Old_head->Next = New_head;
;
New_head = Old_head;
Old_head = Temp;
}
L->Next = New_head;
;
return L;
}















 3414
3414











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









