







第一章 对象
本文编译平台 为VS2017 ,第一章为简介,后面章节会展开
类对象所占用的空间
A obja:
int ilen = sizeof(objal) ; //sizeof(A) = 1,为什么sizeof(空类)=1而不等于0?
cout << ilen << endl:
因为obja有地址,所以至少为1
- 成员函数不占用类对象的内存空间
- 一个类对象至少占用1个字节的内存空间
- 成员变量是包含在每个对象中的,是占用对象字节
成员函数每个类只诞生一个(跟着类走),而不管你用这个类产生了多少个该类的对象
对象结构的发展和演化
c++对象模型逐步建立起来
-
非静态的成员变量跟着类对象走(存在对象内部),也就是每个类对象都有自己的成员变量。
-
静态成员变量跟对象没有什么关系,所以肯定不会保存在对象内部,是保存在对象外面(表示所占用的内存空间和类对象无关)的。
-
成员函数:不管静态的还是非静态,全部都保存在类对象之外。所以不管几个成员函数,不管是否是静态的成员函数,对象的sizeof都是不增加的
-
虚函数:不管几个虚函数,sizeof()都是多了4个字节。
类本身―指向虚函数的指针(一个或者一堆)要有地方存放,存放在一个表格里,这个表格我们就称为“虚函数表(virtual table 【vtbl】)这个虚函数表一般是保存在可执行文件中的,在程序执行的时候载入到内存中来。
虚函数表是基于类的,跟着类走的;
说说类对象,这四个字节的增加,其实是因为虚函数的存在;
因为有了虚函数的存在,导致系统往类对象中添加了一个指针,这个指针正好指向这个虚函数表,很多资料上把这个指针叫vptr ;
这个vptr的值由系统在适当的时机(比如构造函数中通过增加额外的代码来给值)。
- 如果有多个数据成员,那么为了提高访问速度,某些编译器可能会将数据成员之间的内存占用比例进行调整。
this指针调整
C继承自 A 和 B
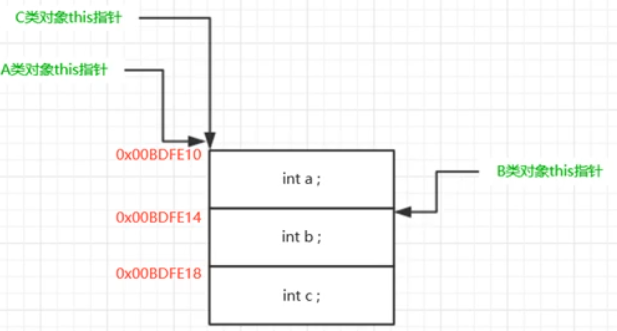
如果派生类只从一个基类继承的话,那么这个派生类对象的地址和基类子对象的地址相同。但如果派生类对象同时继承多个基类,那么大家就要注意:
-
第一个基类子对象的开始地址和派生类对象的开始地址相同。
后续这些基类子对象的开始地址和派生类对象的开始地址相差多少呢?
那就得吧前边那些基类子对象所占用的内存空间干掉。 -
总结:你调用哪个子类的成员函数,这个this指针就会被编译器自动调整到对象内存布局中对应该子类对象的起始地址那去; (看汇编) 例如——myc.B::funcB()
分析obj目标文件,构造函数语义
- 构造函数;
默认构造函数(缺省构造函数):没有参数的构造函数;
“合成的默认构造函数”,只有在必要的时候,编译器才会为我们合成出来,而不是必然或者必须为我们合成出来。
每个.cpp源文件会编译生成一个.obj(.o) linux下gcc -c,最终把很多的.obj(.o)文件链接到一起生成一个可执行。介绍在windows下怎么看obj这件。
用 dumpbin 把.obj文件内容导出成可查看文件my.txt,这个my. txt格式,一般被认为是COFE:通用对象文件格式((Common Object File Format)
编译器会在哪些必要的时候帮助我们把默认的构造函数合成出来呢?
- 该类MBTX没有任何构造函数,但包含一个类类型的成员ma,而该对象ma所属于的类MATX有一个缺省的构造函数。
这个时候,编译器就会为该类MBT拾成一个默认的构造函数,合成的目的是为了调用MATx里的默认构造函数。换句话说:编译器合成了默认的MBTX构造函数,并且在其中安插代码,调用MATX的缺省构造函数;
构造函数语义续
-
父类带缺省构造函数,子类没有任何构造函数,那因为父类这个缺省的构造函数要被调用,所以编译器会为这个子类合成出一个默认构造函数
合成的目的是为了调用这个父类的构造函数。换句话说,编译器合成了默认的构造函数,并在其中安插代码,调用其父类的缺省构造函数
-
如果一个类含有虚函数,但没有任何构造函数时
因为虚函数的存在,
a)编译器会给我们生成一个基于该类的虚函数表vftable。
b)把类的虚函数表地址赋给类对象的虚函数表指针(赋值语句/代码);
我们可以把虚函数表指针看成是我们表面上看不见的一个类的成员函数。
编译器给我们往MBTX缺省构造函数中增加了代码:
(1)生成了类MBTX的虚函数表
(2)调用了父类的构造函数
(3)因为虚函数的存在,把类的虚函数表地址赋给对象的虚函数表指针。
当我们有自己的默认构造函徵时,编译器会根据需要扩充我们自己写的构造函数代码,比如调用父类构造函数,给对象的虚函数表指针赋值编译器干了很多事,没默认构造函数时必要情况下帮助我们合成默认构造必数,如果我们有默认构造函数,编译器会根据需要扩充默认构造
- 如果一个类带有虚基类,编译器也会为它合成一个默认构造函数。
虚继承的目的是让某个类做出声明,承诺愿意共享它的基类。其中,这个被共享的基类就称为虚基类(Virtual Base Class),本例中的 A 就是一个虚基类。在这种机制下,不论虚基类在继承体系中出现了多少次,在派生类中都只包含一份虚基类的成员。
- vbtable虚基类表,vftalble(虚函数表);虚基类结构,编译器为子类和父类都产生了“合成的默认构造函数”
拷贝构造函数语义
传统上,大家认为:如果我们没有定义一个自己的考贝构造函数,编译器会帮助我们合成一个拷贝构造函数。这个合成的挂贝构造函数,也是在必要的时候才会被编译器合成出来。
-
成员变量初始化手法,比如int这种简单类型,直接就按值就拷贝过去,编译器不需要合成考贝构造函数的情况下就帮助我们把这个事情办了
-
我们自己也没有写类A的拷贝构造函数,编译器也没有帮助我们生成拷贝构造函数。
我们却发现myal对象的一些成员变量值确实被拷贝到mya2中去。这是编译器内部的一些直接拷贝数据的实现手法,
比如类A中有类类型ASon成员变量asubobj,也会递归是的去拷贝类ASon的每个成员变量。
某些情况下,如果我们不写自己的拷贝构造函数,编译器就会帮助我们合成出拷贝构造函数来。
那编译器在什么情况下会帮助我们合成出拷贝构造函数来呢?那这个编译器合成出来的拷贝构造函数又要干什么事情呢?
- 如果一个类A没有拷贝构造函数,但是含有一个类类型cTB的成员变量。
该类型cTB含有拷贝构造函数,那么
当代码中有涉及到类A的拷贝构造时,编译器就会为类A合成一个拷贝构造函数。
编译器合录的转贝构造函数往往都是干一些特殊的事情。如果只是一些类成员娈量值的拷贝这些事,编译器是不用专门合成出拷贝构造函数
- 如果一个类CTBSon没有拷贝构造函数,但是它有一个父类CTB,父类有拷贝构造函数,
当代码中有涉及到类CTBSon的拷贝构造时,编译器会为CTBSon合成一个拷贝构造函数,调用父类的拷贝构造函数。 - 如果一个类CTBSon没有拷贝构造函数,但是该类声明了或者继承了虚函数
当代码中有涉及到类CTBSon的拷贝构造时,编译器会为其合成—个拷贝构造函数,往这个拷贝构造函数里插入语句。 - 如果一个类没有拷贝构造函数,但是该类含有虚基类
当代码中有涉及到类的拷贝构造时,编译器会为该类合成一个拷贝构造函数;
程序转化语义
我们写的代码,编译器会对代码进行拆分,拆分成编译器更容易理解和实现的代码。
站在程序员角度/站在编译器角度
定义时初始化
- 步骤一:定义一个对象,为对象分配内存。从编译器视角来看,这句是不调用X类的构造函数。
步骤二:直接调用对象的拷贝构造国数去了;
参数的初始化
X x0;
//func(x0); —— 值传递
//老编译器视角 —— func(x0)
X tmpobj://编译器产生一个临时对象
tmpobj.X::X(x0);//调用拷贝构造函数
func(tmpobj)://用临时对象调用func
tmpobj.X::~x0://func()被调用完成后,本析构被调用。
返回值初始化
- 程序员角度 —— 一次构造函数、一次拷贝构造函数
X func() {
X x0;
return x0; // 系统产生临时对象并把x0的内容拷贝构造给了临时对象。
}
X my = func();
- 编译器角度
//编译器对上述代码的理解(编译器角度)
X my ;//不会调用X的构造函数 —— 直接在外面先构造一个X,再传进去使用
func(my);
void func(X &extra) {
x0;//从编译器角度,这行不调用x的构造函数
//...
extra.X::x(x0);
return;
}
程序员视角
func().functest();
编译器视角
X my;//不会调用X的构造函数
(func(my),my).functest();//逗号表达式:先计算表达式1,再计算表达式2,整个逗号表达式的结果是表达式2的值;
程序员视角
X(*pf)()://定义个函数指针
pf = func;
pf().functest();
编译器视角
X my; //不调用构造函数
void (pf)(X &);
pf = func;
pf(my);
my.functest();
程序的优化
CTempValue ts1(10, 20);
Double(ts1);
- 开发者层面的优化(开发者视角)
//函数(开发者视角)
CTempValue Double(CTempValue &ts)
{
//CTempValue tmpm; //消耗一个构造函数,一个析构函数
//tmpm.val1 = ts.val1 * 2;
//tmpm.val2 = ts.val2 * 2;
//return tmpm; //生成一个临时对象,然后调用拷贝构造函数把tmpm的内容拷贝构造到这个临时对象中去,然后返回临时对象。
// //这个临时对象也消耗了一个拷贝构造函数 ,消耗了一个析构函数;
//
return CTempValue(ts.val1 * 2, ts.val2 * 2); //生成一个临时对象。
}
Double(ts);
// 原来是 一次 构造 + 一次 拷贝构造
// 优化后 一次 构造
- 编译器视角
CTempValue ts1; //开辟空间
ts1.CTempValue::CTempValue(10, 20);
CTempValue tmpobj;
Double(tmpobj, ts1);
-
linux编译器g++优化,针对与返回临时对象这种情况。NRV优化(Named Return Value)。
RVO(Return Value Optimization) ;
g++ -fno-elide-constructors 2_8.cpp -o 2_8直接把开发者层面的优化做了,两次构造(优化了一次拷贝)
程序优化续、拷贝构造续,深浅拷贝
//第九节 程序优化续、拷贝构造续,深浅拷贝
cout << "--------begin-----------" << endl;
X x10(1000);
cout << "-------------------" << endl;
X x11 = 1000; // 隐式类型转换
cout << "-------------------" << endl;
X x12 = X(1000);
cout << "-------------------" << endl;
X x13 = (X)1000;
cout << "--------end-----------" << endl;
//VS2019 调用了4次构造函数(类型转换构造函数)
//gcc(未优化) 第二、三、四次是 构造 + 拷贝
//从编译器视角(不优化)
//第一行
X x10;
x10.x::x(1000);
//后边三行
X _tmp0;
_tmp0.x::x(1000);//带一个参数的构造函数被调用
X x12;
x12.x::x(_tmp0); //拷贝构造函数被调用
_tmp0.x::~x(); //调用析构。
-
总结:当编译器面临用一个类对象作为另外一个类对象初值的情况,各个编译器表现不同。但是所有编译器都为了提高效率而努力。
我们也没有办法确定我们自己使用的编译器是否一定会调用拷贝构造函数。 -
拷贝构造函数是否必须有? 不一定,视情况而定。
如果你只有一些简单的成员变量类型,int,double,你会发现你根本不需要拷贝构造函数;编译器内部本身就支持成员变量的
// //bitwise(按位) copy 按位拷贝
X x0;
x0.m_i = 150;
X x1(x0); //有自己的拷贝构造函数编译器是必然会调用的。
cout << x1.m_i << endl; //编译器支持bitwise拷贝,所以x1.m_i = 150;
- 当需要处理很复杂的成员变量类型的时候。
因为我们增加了自己的拷贝构造函数,导致编译器本身的bitwise拷贝能力失效,所以结论:
如果你增加了自己的拷贝构造函数后,就要对各个成员变量的值的初始化负责了;
深浅拷贝问题;
成员初始化列表说
-
(1)何时必须用成员初始化列表
- 如果这个成员是个引用
- 如果这个成员是个const
- 如果这个类是继承一个基类,并且基类中有构造函数,这个构造函数里边还有参数
- 如果成员变量类型是某个类类型,而这个类的构造函数带参数时
-
(2)使用初始化列表的优势(提高效率)
除了必须用初始化列表的场合,我们用初始化列表还有什么其他目的? 有,就是提高程序运行效率。
对于类类型成员变量xobj放到初始化列表中能够比较明显的看到效率的提升
但是如果是个简单类型的成员变量 比如 int m_test,其实放在初始化列表或者放在函数体里效率差别不大;
提醒:成员变量初始化尽量放在初始化列表里,显得 高端,大气上档次,考官对这个感兴趣。
// 大家把初始化列表中的代码看成是函数体内代码的一部分; —— 但编译器做了优化
A(int tmpvalue) :xobj(1000), m_test2(m_test),m_test(100)
//站在编译器视角
/*X xobj;
xobj.X::X(1000)*/
{
//m_test = m_test2;
cout << "mtest = " << m_test << endl;
cout << "mtest2 = " << m_test2 << endl;
//m_test = 100;
//站在编译器视角 ———— xobj = 1000(在函数体里写)
//X tmpobj; //生成一个临时对象
//tmpobj.X::X(1000); //临时对象调用构造函数
//xobj.X::operator=(tmpobj); //调用的是xobj的拷贝赋值运算符。
//tmpobj.X::~X(); //调用析构函数回收对象
//xobj = 1000; //构造一个临时对象,把临时对象内容给了xobj,释放掉临时对象
//m_test = 500;
}
- (3)初始化列表细节探究
说明:
(3.1)初始化列表中的代码可以看作是被编译器安插到构造函数体中的,只是这些代码有些特殊。
(3.2)**这些代码 是在任何用户自己的构造函数体代码之前被执行的。**所以大家要区分开构造函数中的
//用户代码 和 编译器插入的 初始化所属的代码。
(3.3)这些列表中变量的初始化顺序是 定义顺序,而不是在初始化列表中的顺序。
老师 不建议 在初始化列表中 进行 两个 都在初始化列表中出现的成员之间的初始化
int m_test;
int m_test2;
//构造函数
//A(int tmpvalue) //这里却构造了xobj,耗费了一次调用构造函数的机会
//站在编译器视角
/*X xobj;
xobj.X::X();*/
//大家把初始化列表中的代码看成是函数体内代码的一部分;
//A(int tmpvalue) :xobj(1000), m_test2(100), m_test(m_test2) //这种代码是错误的,初始化顺序是错的,m_test先初始化
A(int tmpvalue) :xobj(1000), m_test2(m_test),m_test(100)
{
}















 242
242











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









