







主要参考了《深入linux内核》和《Linux内核深度解析》,另外简单浅析了一下相关内容
文章目录
ARM64-页表缓存(TLB)
为了改进虚拟地址到物理地址的转换速度,避免每次转换都需要查询内存中的页表,处理器厂商在内存管理单元(MMU)里增加一个TLB(Translation LookasideBuffer)的高速缓存,TLB直译为转译后备缓冲器,也被翻译为页表缓存。
TLB为CPU的一种缓存,由存储器管理单元用于改进虚拟地址到物理地址的转译速度。TLB 用于缓存一部分标签页表条目。
TLB可介于 CPU 和CPU缓存之间,或在CPU缓存和主存之间,这取决于CPU缓存使用的是物理寻址或是虚拟寻址。
TLB表项格式
不同处理器架构的TLB表项的格式不同。
ARM64处理器的每条TLB表项不仅包含虚拟地址和物理地址,
也包含属性:内存类型、缓存策略、访问权限、地址空间标识符(ASID)及虚拟机标识符(VMID)
地址空间标识符区分不同进程的页表项,虚拟机标识符区分不同虚拟机的页表项。
TLB管理
若内核修改了可能缓存在TLB里面的页表项,那么内核必须负责使用旧的TLB表项失效,内核定义每种处理器架构必须实现的函数,具体可查阅源码分析如下:
arch\arm64\include\asm\tlbflush.h
页表改变之后刷新TLB的函数
static inline void flush_tlb_all(void); // 使所有的TLB表项失效
// 使指定用户地址空间的所有TLB表项失效,参数mm是进程的内存描述符
static inline void flush_tlb_mm(struct mm_struct *mm);
// 使指定用户地址空间的某个范围TLB表项失效,
// 参数vma虚拟内存区域,start是起始地址,end是结束地址。
static inline void flush_tlb_range(struct vm_area_struct *vma,
unsigned long start, unsigned long end);
// 使指定用户地址空间里面的指定虚拟页的TLB表项失效,
// 参数vma是虚拟内存区域,uaddr是一个虚拟页中的任意虚拟地址
static inline void flush_tlb_page(struct vm_area_struct *vma,
unsigned long uaddr);
// 使内核的某个虚拟地址范围的TLB表项失效,参数start是起始地址,end是结束地址
static inline void flush_tlb_kernel_range(unsigned long start, unsigned long end);
// 内核把进程从一个处理器迁移到另一个处理器以后,调用该函数以更新页表缓存或上下文特定信息
void tlb_migrate_finish(struct mm_struct *mm);
修改页表项以后把页表项设置到页表缓存
由软件管理页表缓存的处理器必须实现该函数,例如MIPS处理器
ARM64处理器的内存管理单元可以访问内存中的页表,把页表项复制到页表缓存,所以ARM64架
构的函数update_mmu_cache什么都不用做
当TLB没有命中时,ARM64处理器的内存管理单元自动遍历内存中的页表,把页表复制到TLB,不需要软件把页表写到TLB,所以ARM64架构没有提供写TLB的指令。
TLB失效指令
ARM64架构提供一条TLB失效指令
TLBI <type> <level> {IS} {,<Xt>}
- 字段常见选项
- ALL:所以表项
- VMALL:当前虚拟机的阶段1所有的表项,即表项的VMID是当前虚拟机的VMID,虚拟机里面运行客户操作系统的虚拟地址转换成物理地址分成两个阶段,第1阶段把虚拟地址转换成中间物理地址,第2阶段把中间物理地址转换成物理地址。
- ASID:匹配寄存器Xt指定的ASID的表项。
- VA:匹配寄存器Xt指定的虚拟地址和ASID的表项。
- VAA:匹配寄存器Xt指定的虚拟地址并且ASID可以是任意值的表项。
- 字段指定异常级别
- E1:异常级别1。E2:异常级别2。E3:异常级别3。
- 字段{IS}表示内部共享,即多个核共享 ,如果不使用字段IS,表示非共享,只被一个核使用。
- 字段Xt是X0-X31中的任何一个寄存器
// 使所有核的所有TLB表项失效
static inline void flush_tlb_all(void)
{
// 确保屏障之前的存储指令执行完毕,dsb是数据同步的屏障
dsb(ishst);
// 是所有核上匹配VMID,阶段1和异常级别1的所有TLB表项失效
__tlbi(vmalle1is);
// 确保之前的TLB失效指令执行完毕,ish表示数据同步屏障指令对所有和起作用
dsb(ish);
// 指令同步屏障,冲刷处理器流水线,重新读取屏障指令后面的所有指令
isb();
}
// 宏展开
static inline void flush_tlb_all(void)
{
asm volatile("dsb ishst" : : : "memory");
asm ("tlbi vmalle1is" : :);
asm volatile("dsb ish" : : : "memory");
asm volatile("isb" : : : "memory");
}
/*
此函数和flush_tlb_all区别在于:
1、指令dsb中字段ish换成nsh,nsh是非共享(non-shareable),表示数据同步屏障指令仅仅在当前核起作用;
2、指令tlbi没有携带字段is,表示仅仅使当前核的TLB表项失效。
*/
static inline void local_flush_tlb_all(void)
{
dsb(nshst);
__tlbi(vmalle1);
dsb(nsh);
isb();
}
地址空间标识符 ASID 和 ASID版本号
为了减少在进程切换时清空页表缓存的需要,ARM64处理器的页表缓存(TLB)使用非全局(not global, nG)位区分内核和进程的页表项,使用地址空间标识符(Address SpaceIdentifer,ASID)区分不同进程的页表项。
ARM64处理器ASID长度是由具体实现定义的,可以选择8位或者16位,寄存器ID_AA64MMFRO_EL1(AArch64内存模型特性寄存器0,AArch64 Memory Model FeatureRegister 0)的字段ASIDBits存放处理器支持的ASID长度。
在SMP系统中,ARM64架构要求ASID在处理器的所有核上是唯一的。
平时为了方便描述,假设ASID长度是8位,ASID只有256个值,其中0是保留值,可分配ASID范围是1-255,进程的数量可能超过255个,两个进程ASID可能相同,如何解决此问题,内核引入ASID版本号:
- a.每个进程有一个 64位的软件ASID ,低8位存放硬件ASID,高56位存放ASID版本号;
- b.64位全局变量的高56位保存全局ASID版本号;
- c.当进程被调度时,比较进程的ASID版本号和全局ASID版本号,如果版本号相同,直接使用上次分配的硬件ASID(全局ASID版本号未更新)。否则需要给进程重新分配硬件ASID。
引入ASID版本号好处在哪里:避免每次进程切换都需要清空页表缓存,只需要在==硬件ASID回绕(从255回到0清空后变为1)==时把处理器的页表缓存清空。
内存描述符的成员context存放架构特定的内存管理上下文,数据类型是结构体mm context_t。ARM64架构定义结构体类型如下:
arch\arm64\include\asm\mmu.h
#ifndef __ASM_MMU_H
#define __ASM_MMU_H
typedef struct {
atomic64_t id; // 成员id存放内核给进程分配的软件ASID
void *vdso;
unsigned long flags;
} mm_context_t;
全局变量asid_bits保存ASID长度,全局变量asid_generation的高56位保存全局ASID版本号,位图asid_map记录哪些ASID被分配。
每处理器变量active_asids保存处理器正在使用的ASID,即处理器正在执行的进程的ASID;每处理器变量reserved_asids存放保留的ASID,用来在全局ASID版本号加1时保存处理器正在执行的进程的ASID。
处理器给进程分配ASID时,如果ASID分配完了(变为0),那么把全局ASID版本号加1,重新从1开始分配ASID,针对每个处理器,使用该处理器的reserved_asids保存该处理器正在执行的进程的ASID,并且把该处理器的active_asids设置为0。
active_asids为0具有特殊含义,说明全局ASID版本号变化,ASID从255回绕到1。
当全局ASID版本号加1时,每个处理器需要清空页表缓存,位图tlb_flush_pending保存需要清空页表缓存的处理器集合。
arch\arm64\mm\context.c
static u32 asid_bits; // 保存ASID长度
static DEFINE_RAW_SPINLOCK(cpu_asid_lock);
static atomic64_t asid_generation; // 高56位保存全局ASID版本号
static unsigned long *asid_map; // 位图asid_map记录哪些ASID被分配
static DEFINE_PER_CPU(atomic64_t, active_asids); // 保存处理器正在使用的ASID
static DEFINE_PER_CPU(u64, reserved_asids); // 保留的ASID,用来在全局ASID版本号加1时保存处理器正在执行的进程的ASID
static cpumask_t tlb_flush_pending;
当进程被调度时,函数check_and_switch_context负责检查是否需要给进程重新分配ASID
__schedule() -> context_switch() -> switch_mm_irqs_off() -> switch_mm() -> check_and_switch_context()
arch/arm64/mm/context.c
函数new_context负责分配ASID
函数flush_context负责重新初始化ASID分配状态
虚拟机标识符
虚拟机里面运行的客户操作系统的虚拟地址换成物理地址分两个阶段:第1阶段把虚拟地址转换成中间物理地址,第2阶段把中间物理地址转换成物理地址。
- 第1阶段转换由客户操作系统的内存控制,和非虚拟化的转换过程相同。
- 第2阶段转换由虚拟机监控器控制,虚拟机监控器为每个虚拟机维护一个转换表,分配一个虚拟机标识符(Virtual MachineIdentifier,VMID),寄存器VTTBR_EL2(虚拟化转换表基准寄存器,VirtualizationTranslation Table Base Register)存放当前虚拟机的阶段2转换表的物理地址。
巨型页
当运行内存需求量较大的应用程序时,如果使用长度为4KB的页,将会产生较多的TLB未命中和缺页异常,严重影响应用程序的性能。如果使用长度为2MB甚至更大的巨型页,可以大幅减少TLB未命中和缺页异常的数量,大幅提高应用程序的性能。这才是内核引入巨型页(Huge Page)的真正原因。
巨型页首先需要处理器能够支持,然后需要内核支持,内核有两种实现方式:
- 使用hugetlbfs伪文件系统实现巨型页;
- hugetlbfs文件系统是一个假的文件系统,只是利用了文件系统的编程接口。使用hugetlbfs文件系统实现的巨型页称为hugetblfs巨型页、传统巨型页或标准巨型页,这里统一称为标准巨型页。
- 透明巨型页。
优缺点
- 标准巨型页的优点是预先分配巨型页到巨型页池,进程申请巨型页的时候从巨型池取,成功的概率很高,缺点是应用程序需要使用文件系统的编程接口。
- 透明巨型页(临时巨型页)的优点是对应用程序透明,缺点是动态分配,在内存碎片化的时候分配成功的概率很低。
处理器对巨型页的支持
ARM64处理器支持巨型页的方式有两种。
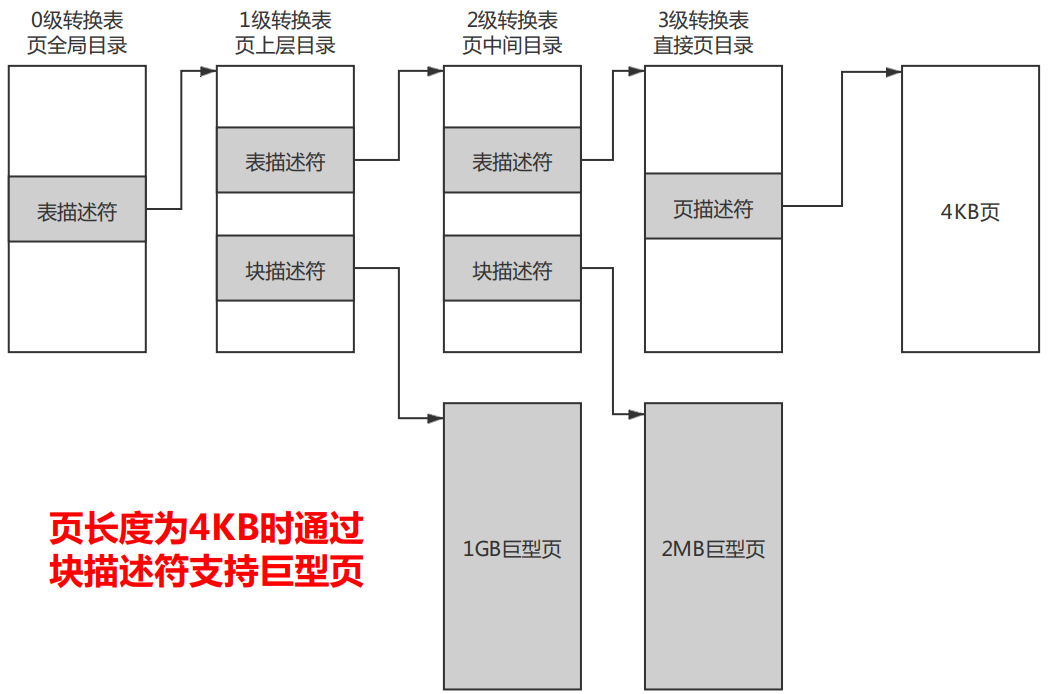
(1)通过块描述符支持。
(2)通过页/块描述符的连续位支持。
通过块描述符支持巨型页
如果页长度是4KB,那么使用4级转换表,0级转换表不能使用块描述符,1级转换表的块描述符指向1GB巨型页,2级转换表的块描述符指向2MB巨型页。
如果页长度是16KB,那么使用4级转换表,0级转换表不能使用块描述符,1级转换表不能使用块描述符,2级转换表的块描述符指向32MB巨型页。
如果页长度是64KB,那么使用3级转换表,1级转换表不能使用块描述符,2级转换表的块描述符指向512MB巨型页。
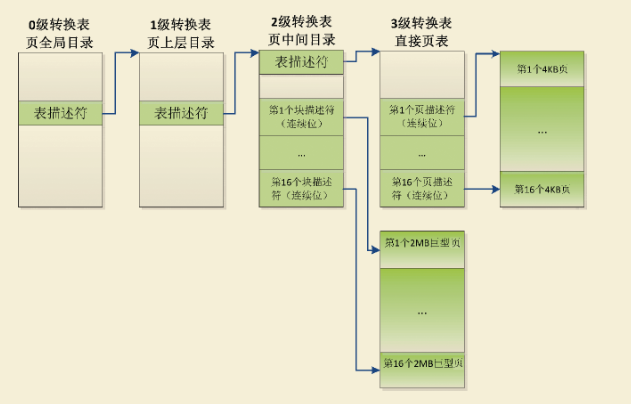
通过页/块描述符的连续位支持巨型页
页/块描述符中的连续位指示表项是一个连续表项集合中的一条表项,一个连续表项集合可以被缓存在一条TLB表项里面。
通常所说的,进程申请了n页的虚拟内存区域,然后申请了n页的物理内存区域,使用n个连续的页表项把每个虚拟页映射到物理页,每个页表项设置了连续标志位,当处理器的内存管理单元遍历内存的页表时,访问到n个页表项中的任何一个页表项。
发现页表项设置了连续标志位,就会把n个页表项合并以后填充到TLB表项 (n是固定)。
-
假设:页长度为4KB,那么使用4级转换表,1级转换表的块描述符不能使用连续位;2级转换表的块描述符支持16个连续块,即支持(16*2MB=32MB)巨型页,3级转换表的页描述符支持16个连续页,即支持(16*4KB=64K)巨型页。
如下图,页长度为4KB时通过页/块描述符的连续位支持巨型页
-
假设:如果页长度16KB,那么我们使用4级转换表,2级转换表的块描述符支持32个连续块,即支持(32*32MB=1GB)巨型页; 3级转换表的页描述符支持128个连续页,即支持(128*16KB=2MB)巨型页。
-
假设:如果页长度64KB,那么使用3级转换表,2级转换表的块描述符不能使用连续位;3级转换表的页描述符支持32个连续页。即支持(32*64KB=2MB)巨型页。
标准巨型页
使用方法
编译内核时需要打开配置宏CONFIG_HUGETLBFS和CONFIG_HUGETLB_PAGE(打开配置宏CONFIG_HUGETLBFS的时候会自动打开)。
通过文件“/proc/sys/vm/nr_hugepages”指定巨型页池中永久巨型页的数量,预先分配指定数量的永久巨型页到巨型页池中。另一种方法是在引导内核时指定内核参数“hugepages=N”以分配永久巨型页,这是分配巨型页最可靠的方法,因为内存还没有碎片化。
有些平台支持多种巨型页长度。**如果要分配特定长度的巨型页,必须在内核参数“hugepages”前面添加选择巨型页长度的参数“hugepagesz=<size>[kKmMgG]”。可以使用内核参数“default_hugepagesz=<size>[kKmMgG]”选择默认的巨型页长度。**文件“/proc/ sys/vm/nr_hugepages”表示默认长度的永久巨型页的数量。
通过文件“/proc/sys/vm/nr_overcommit_hugepages”指定巨型页池中临时巨型页的数量,当永久巨型页用完的时候,可以从页分配器申请临时巨型页。
nr_hugepages是巨型页池的最小长度,(nr_hugepages + nr_overcommit_hugepages)是巨型页池的最大长度。这两个参数的默认值都是0,至少要设置一个,不然分配巨型页会失败。
创建匿名的巨型页映射,其代码如下:
#define MAP_LENGTH (10 * 1024 * 1024)
addr = mmap(0, MAP_LENGTH, PROT_READ | PROT_WRITE,
MAP_ANONYMOUS | MAP_HUGETLB, -1, 0);
如果要创建基于文件的巨型页映射,首先管理员需要在某个目录下挂载hugetlbfs文件系统:
mount -t hugetlbfs \
-o uid=<value>,gid=<value>,mode=<value>,pagesize=<value>,size=<value>,\
min_size=<value>,nr_inodes=<value> none <目录>
各选项的意思如下。
(1)选项uid和gid指定文件系统的根目录的用户和组,默认取当前进程的用户和组。
(2)选项mode指定文件系统的根目录的模式,默认值是0755。
(3)如果平台支持多种巨型页长度,可以使用选项pagesize指定巨型页长度和关联的巨型页池。如果不使用选项pagesize,表示使用默认的巨型页长度。
(4)选项size指定允许文件系统使用的巨型页的最大数量。如果不指定选项size,表示没有限制。
(5)选项min_size指定允许文件系统使用的巨型页的最小数量。挂载文件系统的时候,申请巨型页池为这个文件系统预留选项min_size指定的巨型页数量。如果不指定选项min_size,表示没有限制。
(6)选项nr_inodes指定文件系统中文件(一个文件对应一个索引节点)的最大数量。如果不指定选项nr_inodes,表示没有限制。
假设在目录“/mnt/huge”下挂载了hugetlbfs文件系统,应用程序在hugetlbfs文件系统中创建文件,然后创建基于文件的内存映射,这个内存映射就会使用巨型页。
#define MAP_LENGTH (10 * 1024 * 1024)
fd = open("/mnt/huge/test", O_CREAT | O_RDWR, S_IRWXU);
addr = mmap(0, MAP_LENGTH, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
应用程序可以使用开源的hugetlbfs库,这个库对hugetlbfs文件系统做了封装。使用hugetlbfs库的好处如下。
(1)启动程序时使用环境变量“LD_PRELOAD=libhugetlbfs.so”把hugetlbfs库设置成优先级最高的动态库,malloc()使用巨型页,对应用程序完全透明,应用程序不需要修改代码。
(2)可以把代码段、数据段和未初始化数据段都放在巨型页中。
查看巨型页信息
通过文件执行:cat /proc/meminfo
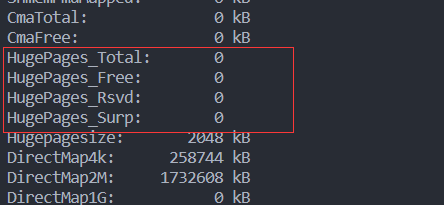
这些字段的意思如下。
(1)HugePages_Total:巨型页池的大小。
(2)HugePages_Free:巨型页池中没有分配的巨型页的数量。
(3)HugePages_Rsvd:“Rsvd”是“Reserved”的缩写,意思是“预留的”,是已经承诺从巨型页池中分配但是还没有分配的巨型页的数量。预留的巨型页保证应用程序在发生缺页异常的时候能够从巨型页池中分配一个巨型页。
(4)HugePages_Surp:“Surp”是“Surplus”的缩写,意思是“多余的”,是巨型页池中临时巨型页(临时分配的)的数量。临时巨型页的最大数量由“/proc/sys/vm/nr_overcommit_hugepages”控制。
(5)Hugepagesize:巨型页的大小。
实现原理
巨型页池
内核使用巨型页池管理巨型页。有的处理器架构支持多种巨型页长度,每种巨型页长度对应一个巨型页池,有一个默认的巨型页长度,默认只创建巨型页长度是默认长度的巨型页池。比如ARM64架构在页长度为4KB的时候支持巨型页长度是1GB 32MB 2MB 64KB,默认的巨型页长度是2MB,默认只有创建巨型页长度是2MB的巨型页池。
**默认只创建巨型页长度是2MB的巨型页池。**如果需要创建巨型页长度不是默认长度的巨型页池,可以在引导内核时指定内核参数“hugepagesz=<size>[kKmMgG]”,长度必须是处理器支持的长度。
可以使用内核参数“default_hugepagesz=<size>[kKmMgG]”选择默认的巨型页长度
相关数据结构
巨型页池的数据结构是结构体hstate
// 全局变量hugetlb_max_hstate是巨型页池的数量
int hugetlb_max_hstate __read_mostly;
// 全局变量是默认巨型页池的索引
unsigned int default_hstate_idx;
// 全局数组hstates是巨型页池数组
struct hstate hstates[HUGE_MAX_HSTATE];
巨型页池中的巨型页分为两种。
- 永久巨型页:是保留的,不能有其他用途,被预先分配到巨型页池,当进程释放永久巨型页的时候,永久巨型页被归还到巨型页池。
- 临时巨型页:也称为多余的(surplus)巨型页,当永久巨型页用完的时候,可以从页分配器分配临时巨型页;进程释放临时巨型页的时候,直接释放到页分配器。当设备长时间运行后,内存可能碎片化,分配临时巨型页可能会失败。
struct hstate
巨型页池的数据结构hstate的主要成员
struct hstate {
// 分配永久巨型页并添加到巨型页池中的时候,在允许的内存节点集合中轮流从每个内存节点分配永久巨型页,这个成员用来记录下次从哪个内存节点分配永久巨型页
int next_nid_to_alloc;
// 从巨型页池释放空闲巨型页的时候,在允许的内存节点集合中轮流从每个内存节点释放巨型页,这个成员用来记录下次从哪个内存节点释放巨型页
int next_nid_to_free;
unsigned int order; // 巨型页的长度,页的阶数
unsigned long mask; // 巨型页页号的掩码,将虚拟地址和掩码按位与,得到巨型页页号
unsigned long max_huge_pages; // 永久巨型页的最大数量
unsigned long nr_huge_pages; // 巨型页的数量
unsigned long free_huge_pages; // 空闲巨型页的数量
unsigned long resv_huge_pages; // 预留巨型页的数量,它们已经承诺分配但还没有分配
unsigned long surplus_huge_pages; // 临时巨型页的数量
unsigned long nr_overcommit_huge_pages; // 临时巨型页的最大数量
struct list_head hugepage_activelist; // 每个内存节点一个空闲巨型页链表
struct list_head hugepage_freelists[MAX_NUMNODES]; // 把已分配出去的巨型页链接起来
unsigned int nr_huge_pages_node[MAX_NUMNODES]; // 每个内存节点中巨型页的数量
unsigned int free_huge_pages_node[MAX_NUMNODES]; // 每个内存节点中空闲巨型页的数量
unsigned int surplus_huge_pages_node[MAX_NUMNODES]; // 每个内存节点中临时巨型页的数量
#ifdef CONFIG_CGROUP_HUGETLB
/* cgroup control files */
struct cftype cgroup_files[5];
#endif
char name[HSTATE_NAME_LEN]; // 巨型页池的名称,格式是“hugepages-<size>kB”
};
预先分配永久巨型页
预先分配指定数量的永久巨型页到巨型页池中有两种方法。
1)最可靠的方法是在引导内核时指定内核参数“hugepages=N”来分配永久巨型页,因为内核初始化的时候内存还没有碎片化。
有些处理器架构支持多种巨型页长度。如果要分配特定长度的巨型页,必须在内核参数“hugepages”前面添加选择巨型页长度的参数“hugepagesz=<size>[kKmMgG]”。
内核参数“hugepages=N”的处理函数是hugetlb_nrpages_setup
函数hugetlb_hstate_alloc_pages负责预先分配指定数量的永久巨型页
长度超过页分配器支持的最大阶数的巨型页已经从引导内存分配器中分配
如果巨型页长度小于或等于页分配器支持的最大阶数,那么从页分配器分配永久巨型页,添加到巨型页池中。
2)通过文件“/proc/sys/vm/nr_hugepages”指定默认长度的永久巨型页的数量。内核参数“hugepages=N”的处理函数是hugetlb_nrpages_setup。
文件“/proc/sys/vm/nr_hugepages”的处理函数是hugetlb_sysctl_handler,最终调用函数set_max_huge_pages来增加或减少永久巨型页
挂载hugetlbfs文件
hugetlbfs文件系统在初始化的时候,调用函数register_filesystem以注册hugetlbfs文件系统,hugetlbfs文件系统的结构体如下
fs/hugetlbfs/inode.c
static struct file_system_type hugetlbfs_fs_type = {
.name = "hugetlbfs",
.mount = hugetlbfs_mount,
.kill_sb = kill_litter_super,
};
挂载hugetlbfs文件系统的时候,挂载函数调用hugetlbfs文件系统的挂载函数hugetlbfs_mount,创建超级块和根目录,把文件系统和巨型页池关联起来。
如图3.66所示,超级块的成员s_fs_info指向hugetblfs文件系统的私有信息;成员s_blocksize是块长度,被设置为巨型页的长度
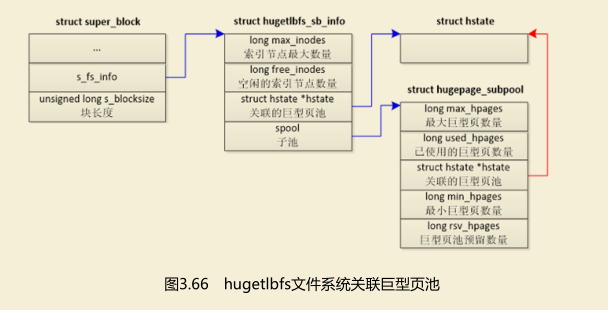
结构体hugetlbfs_sb_info 描述hugetblfs文件系统的私有信息。
1)成员max_inode是允许的索引节点最大数量。
2)成员free_inodes是空闲的索引节点数量。
3)成员hstate指向关联的巨型页池。
4)如果指定了最大巨型页数量或最小巨型页数量,那么为巨型页池创建一个子池,成员spool指向子池。
结构体hugepage_subpool描述子池(从巨型页池中分出来的一个池子)的信息。
1)成员max_hpages是允许的最大巨型页数量。
2)used_hpages是已使用的巨型页数量,包括分配的和预留的。
3)成员hstate指向巨型页池。
4)成员min_hpages是最小巨型页数量。
5)成员rsv_hpages是子池向巨型页池申请预留的巨型页的数量。
其他系统调用
创建文件
调用系统调用open(),在hugetlbfs文件系统的一个目录下创建一个文件的时候,系统调用open最终调用函数hugetlbfs_create()为文件分配索引节点(结构体inode)并且初始化,索引节点的成员i_fop指向hugetlbfs文件系统特有的文件操作集合hugetlbfs_file_operations,这个文件操作集合的成员mmap方法是函数hugetlbfs_file_mmap(),这个函数在创建内存映射的时候很关键。
创建内存映射
在hugetlbfs文件系统中打开文件,然后基于这个文件创建内存映射时,系统调用mmap将会调用函数hugetlbfs_file_mmap()。
函数hugetlbfs_file_mmap()的主要功能如下。
1)设置标准巨型页标志VM_HUGETLB 和不允许扩展标志VM_DONTEXPAND。
2)虚拟内存区域的成员vm_ops指向巨型页特有的虚拟内存操作集合hugetlb_vm_ops。
3)检查文件的偏移是不是巨型页长度的整数倍。
4)调用函数hugetlb_reserve_pages(),向巨型页池申请预留巨型页。
分配和映射到巨型页
第一次访问巨型页的时候触发缺页异常,函数handle_mm_fault发现虚拟内存区域设置了标志VM_HUGETLB,调用巨型页的页错误处理函数hugetlb_fault。函数hugetlb_fault发现页表项是空表项,调用函数hugetlb_no_page以分配并且映射到巨型页。
函数hugetlb_no_page的执行过程如下。
1)在文件的页缓存中根据文件的页偏移查找页。
2)如果在页缓存中没有找到页,调用函数alloc_huge_page以分配巨型页。如果是共享映射,那么把巨型页加入文件的页缓存,以便和其他进程共享页。
3)设置页表项。
4)如果第一步在页缓存中找到页,映射是私有的,并且执行写操作,那么执行写时复制。
写时复制
假设进程1创建了私有的巨型页映射,然后进程1分叉生成进程2和进程3。其中一个进程试图写巨型页的时候,触发页错误异常,巨型页的页错误处理函数hugetlb_fault调用函数hugetlb_cow以执行写时复制。
函数hugetlb_cow的执行过程如下。
1)如果只有一个虚拟页映射到该物理页,并且是匿名映射,那么不需要复制,直接修改页表项设置可写。
2)分配巨型页。
3)处理分配巨型页失败的情况。
- 如果触发页错误异常的进程是创建私有映射的进程,那么删除所有子进程的映射,为子进程的虚拟内存区域的成员vm_private_data设置标志
HPAGE_RESV_UNMAPPED,让子进程在发生页错误异常的时候被杀死。 - 如果触发页错误异常的进程不是创建私有映射的进程,返回错误。
4)把旧页的数据复制到新页。
5)修改页表项,映射到新页,并且设置可写。
透明巨型页
透明巨型页(Transparent Huge Page,THP)对进程是透明的,如果虚拟内存区域足够大,并且允许使用巨型页,那么内核在分配内存的时候首先选择分配巨型页,如果分配巨型页失败,回退分配普通页。
使用方法
透明巨型页的配置宏如下所示。
(1)CONFIG_TRANSPARENT_HUGEPAGE:支持透明巨型页。
(2)CONFIG_TRANSPARENT_HUGEPAGE_ALWAYS:总是使用透明巨型页。
(3)CONFIG_TRANSPARENT_HUGEPAGE_MADVISE:只在进程使用madvise(MADV_HUGEPAGE)指定的虚拟地址范围内使用透明巨型页。
(4)CONFIG_TRANSPARENT_HUGE_PAGECACHE:文件系统的页缓存使用透明巨型页。
可以在引导内核的时候通过内核参数开启或关闭透明巨型页。
(1)transparent_hugepage=always
(2)transparent_hugepage=madvise
(3)transparent_hugepage=never
可以在运行过程中开启或关闭透明巨型页
(1)总是使用透明巨型页。
echo always >/sys/kernel/mm/transparent_hugepage/enabled
(2)只在进程使用madvise(MADV_HUGEPAGE)指定的虚拟地址范围内使用透明巨型页。
echo madvise >/sys/kernel/mm/transparent_hugepage/enabled
系统调用madvise针对透明巨型页提供了两个Linux私有的建议值。
(1)MADV_HUGEPAGE表示指定的虚拟地址范围允许使用透明巨型页。
(2)MADV_NOHUGEPAGE表示指定的虚拟地址范围不要合并成巨型页。
(3)禁止使用透明巨型页。
echo never >/sys/kernel/mm/transparent_hugepage/enabled
分配透明巨型页失败的时候,页分配器采取什么消除内存碎片的策略?可以配置以下策略。
(1)直接回收页,执行同步模式的内存碎片整理。
echo always >/sys/kernel/mm/transparent_hugepage/defrag
(2)异步回收页,执行异步模式的内存碎片整理。
echo defer >/sys/kernel/mm/transparent_hugepage/defrag
(3)只针对madvise(MADV_HUGEPAGE)指定的虚拟内存区域,异步回收
页,执行异步模式的内存碎片整理。
echo defer+madvise >/sys/kernel/mm/transparent_hugepage/defrag
(4)只针对madvise(MADV_HUGEPAGE)指定的虚拟内存区域,直接回收
页,执行同步模式的内存碎片整理。这是默认策略。
echo madvise >/sys/kernel/mm/transparent_hugepage/defrag
(5)不采取任何策略。
echo never >/sys/kernel/mm/transparent_hugepage/defrag
可以查看透明巨型页的长度,单位是字节:
cat /sys/kernel/mm/transparent_hugepage/hpage_pmd_size
透明巨型页扫描线程定期扫描允许使用透明巨型页的虚拟内存区域,尝试把普通页合并成透明巨型页。
可以通过文件“/sys/kernel/mm/transparent_hugepage/khugepaged/pages_to_scan”配置每次扫描多少页(指普通页),默认值是一个巨型页
包含的普通页数量的8倍。
可以通过文件“/sys/kernel/mm/transparent_hugepage/khugepaged/scan_sleep_millisecs”配置两次扫描的时间间隔,单位是毫秒,默认值是
10秒。
实现原理
虚拟内存区域vm_area_struct的成员vm_flags增加了以下两个标志。
(1)VM_HUGEPAGE表示允许虚拟内存区域使用透明巨型页,进程使用madvise(MADV_HUGEPAGE)给虚拟内存区域设置这个标志。
(2)VM_NOHUGEPAGE表示不允许虚拟内存区域使用透明巨型页,进程使用madvise(MADV_NOHUGEPAGE)给虚拟内存区域设置这个标志。
注意:标志VM_HUGETLB表示允许使用标准巨型页。
虚拟内存区域满足以下条件才允许使用透明巨型页。
(1)以下条件二选一。
-
总是使用透明巨型页。
-
只在进程使用madvise(MADV_HUGEPAGE)指定的虚拟地址范围内使用透明巨型页,并且虚拟内存区域设置了允许使用透明巨型页的标志。
(2)虚拟内存区域没有设置不允许使用透明巨型页的标志。
假设一个虚拟内存区域允许使用透明巨型页,访问虚拟内存区域的时候,如果没有映射到物理页,那么生成页错误异常,页错误异常处理程序的处理过程如下。
(1)首先尝试在页上层目录分配巨型页。如果触发异常的虚拟地址所属的虚拟巨型页超出虚拟内存区域,或者分配巨型页失败,那么回退,尝试在页
中间目录分配巨型页。
(2)尝试在页中间目录分配巨型页。如果触发异常的虚拟地址所属的虚拟巨型页超出虚拟内存区域,或者分配巨型页失败,那么回退,尝试分配普通页。
(3)分配普通页。
页上层目录级别的巨型页和页中间目录级别的巨型页仅仅大小不同,页上层目录级别的巨型页大。以页中间目录级别的巨型页为例说明,分配巨型页的时候,会分配直接页表,把直接页表添加到页中间目录的直接页表寄存队列中。
直接页表寄存队列有什么用处呢?
当释放巨型页的一部分时,巨型页分裂成普通页,需要从直接页表寄存队列取一个直接页表。直接页表寄存队列分两种情况。
(1)如果每个页中间目录使用独立的锁,那么每个页中间目录一个直接页表寄存队列,头节点是页中间目录的页描述符的成员pmd_huge_pte(见图3.69)。
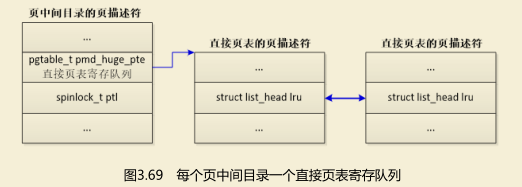
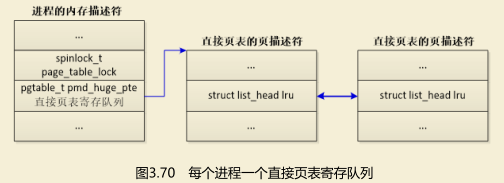
(2)如果一个进程的所有页中间目录共用一个锁,那么每个进程一个直接页表寄存队列,头节点是内存描述符的成员pmd_huge_pte(见图3.70)。
透明巨型页的分裂
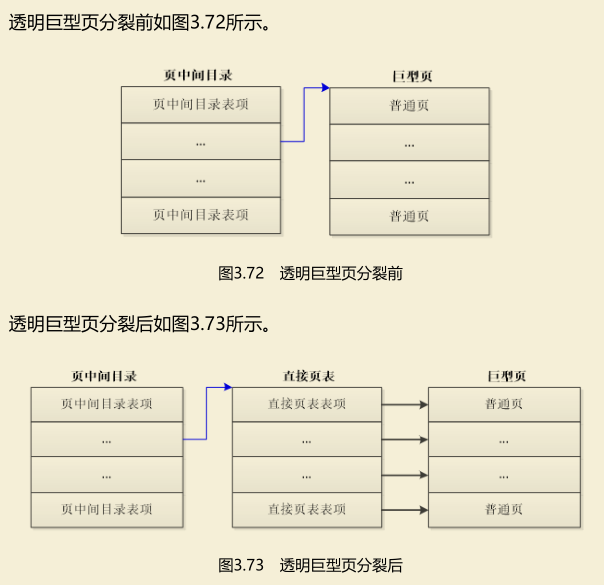
当进程使用munmap释放巨型页的一部分时,需要把巨型页分裂成普通页。
以页中间目录级别的巨型页为例说明,执行过程如下。
(1)先把巨型页分裂成普通页。从直接页表寄存队列取一个直接页表,页中间目录表项指向直接页表,直接页表的每个表项指向巨型页中的一个普通页。
(2)释放普通页,把直接页表表项删除。
内核有一个透明巨型页线程(线程名称是khugepaged),定期地扫描允许使用透明巨型页的虚拟内存区域,尝试把普通页合并成巨型页。
在分配透明巨页时,会把进程的内存描述符加入透明巨型页线程的扫描链表中,如果分配透明巨型页失败,回退使用普通页,透明巨型页线程将会尝试把普通页合并成巨型页。
透明巨型页线程的数据结构如图3.71所示。
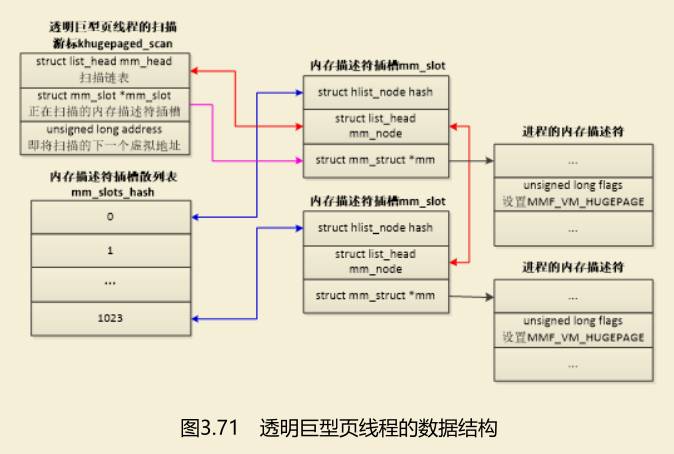
(1)扫描游标khugepaged_scan:成员mm_head是扫描链表的头节点,扫描链表的成员是内存描述符插槽;成员 mm_slot 指向当前正在扫描的内存描述符插槽,成员 address是即将扫描的下一个虚拟地址。
(2)内存描述符插槽mm_slot:成员mm指向进程的内存描述符,成员hash用来加入散列表,成员mm_node用来加入扫描链表。
(3)内存描述符插槽散列表mm_slots_hash。
(4)加入扫描链表的内存描述符设置了标志MMF_VM_HUGEPAGE。














 2669
2669











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









