







代码开源:
目录
7.1 有限状态机的概念
有限状态机,指的是根据若干个状态位进行状态转换的操作,状态机头部只需分析当前状态即可唯一确定目前的操作,经过操作之后对状态进行修改,然后再次进入状态机头部,如此往复。
有限状态机在编译原理中很常用,因为其在词法分析和语法分析中非常使用。对请求报文的分析也是同理,通过状态的转换后逐步移动标志位,将本质是一个字符串的报文解析成有序的数据集合。
如下就是一个简单的有限状态机,A->B->C
STATE_MACHINE()
{
State cur_State = type_A;
while( cur_State != type_C )
{
Package _pack = getNewPackage();
switch( cur_State )
{
case type_A:
process_package_state_A( _pack );
cur_State = type_B;
break;
case type_B:
process_package_state_B( _pack );
cur_State = type_C;
break;
}
}
}7.2 分析请求报文的基本思路
7.2.1 主状态机的基本思路
请求报文有4个部分:请求行,请求头,空行,请求数据
对主状态机来说只有一个关键信息是有效的,即当前主状态(分析请求行、分析请求头、分析请求数据)
主状态机内部需要处理对应的业务逻辑,函数之间有对应的接口,即分析结果(还未分析完毕、已经分析出完整报文、错误语法等等)
写法上,“分析请求行/分析请求头/分析请求数据”+对分析结果的处理 构成一个完整的处理逻辑。
至于分析请求行、分析请求头、分析请求数据处理逻辑的内部结构,对主状态机来说是透明的。
7.2.2 主状态机的处理逻辑
- 每遇到一行完整的数据,根据当前的主状态位,进行相应的处理逻辑
- 处理逻辑分为两部分:
- 送入分析函数
- 分析分析函数的返回值
- 处理逻辑分为两部分:
1.分析请求行
请求行的组成部分:请求方法,URL,协议版本
对类型这样的数据进行处理:GET /index.html HTTP/1.1
因此只需要调用strpbrk进行移动,然后将空格置为'\0',即可完成分隔,然后使用strcasecmp进行对应的比较即可
需要注意的是url可能有http://,需要去掉(即m_url后移7个位置)
2.分析请求头
请求头的每行形如:Connection: keep-alive
因此只需匹配完毕key部分,比如"Connection:",然后去除空格,再对value部分进行处理即可,这里的去除空格可以使用strcspn函数
3.分析请求数据
在分析请求头的时候获取了正文长度对应的值"m_content_length",则只需要将当前读缓冲区长度与m_content_length+请求行长度+请求头长度进行比较即可。
若比较为false,说明还没读完,将EPOLLIN写入内核然后直接退出,这样下次调用epoll_wait的时候就会再次进入Read函数进行recv,然后就可以读取后面的了
分析三个部分的时候都有可能遇到报文不完整的情况,即返回NO_REQUEST,程序处理到这个情况就将EPOLLIN写入内核然后直接退出,这样下次调用epoll_wait的时候就会再次进入Read函数进行recv,进行进一步的处理。
4. 次状态机:分析报文将其分隔为句子
从报文格式处我们可以得知报文句子结束位置是"\r\n",因此程序的目的就是将其置为"\0\0",并将每个句子的开头位置发送给主状态机进行处理。
因此只需要对其进行逐行处理即可。需要维护一个指针指向当前检查的位置,这个指针的位置从读缓冲区开始的地方开始,结束于缓冲区尾部(由read_buf_index表示)
逐行分析有三种情况,即语法错误、读到完整的行、未读完
- 第一种情况即'\r'与'\n'不是按照"\r\n"排列
- 第二种情况即读到"\r\n"
- 第三种情况即还未读到结束部分,但是已经遍历到缓冲区尾部,这说明还未读完
读到一行的时候指针指向的位置是行末了,因此需要额外维护一个指向行首部的指针,在检查指针遇到新行之后将行首部指针指向它,这样就可以在主状态机中将行首部指针作为参数发给处理逻辑了。
5. 提到的函数的API
#include <strings.h>
int strcasecmp(const char *s1, const char *s2);
-C语言中判断字符串是否相等的函数,忽略大小写
size_t strspn(const char *s, const char *accept);
-参数
- str1 -- 要被检索的 C 字符串。
- str2 -- 该字符串包含了要在 str1 中进行匹配的字符列表。
-返回值
返回 str1 中第一个不在字符串 str2 中出现的字符下标。
char *strpbrk(const char *str1, const char *str2)
-检索字符串 str1 中第一个匹配字符串 str2 中字符的字符,不包含空结束字符。
也就是说,依次检验字符串 str1 中的字符,当被检验字符在字符串 str2 中也包含时,
则停止检验,并返回该字符位置。
-简单来说就是传回str2中任意字符在str1中最早出现的位置7.2 在分析请求报文的时候对应的状态机样式
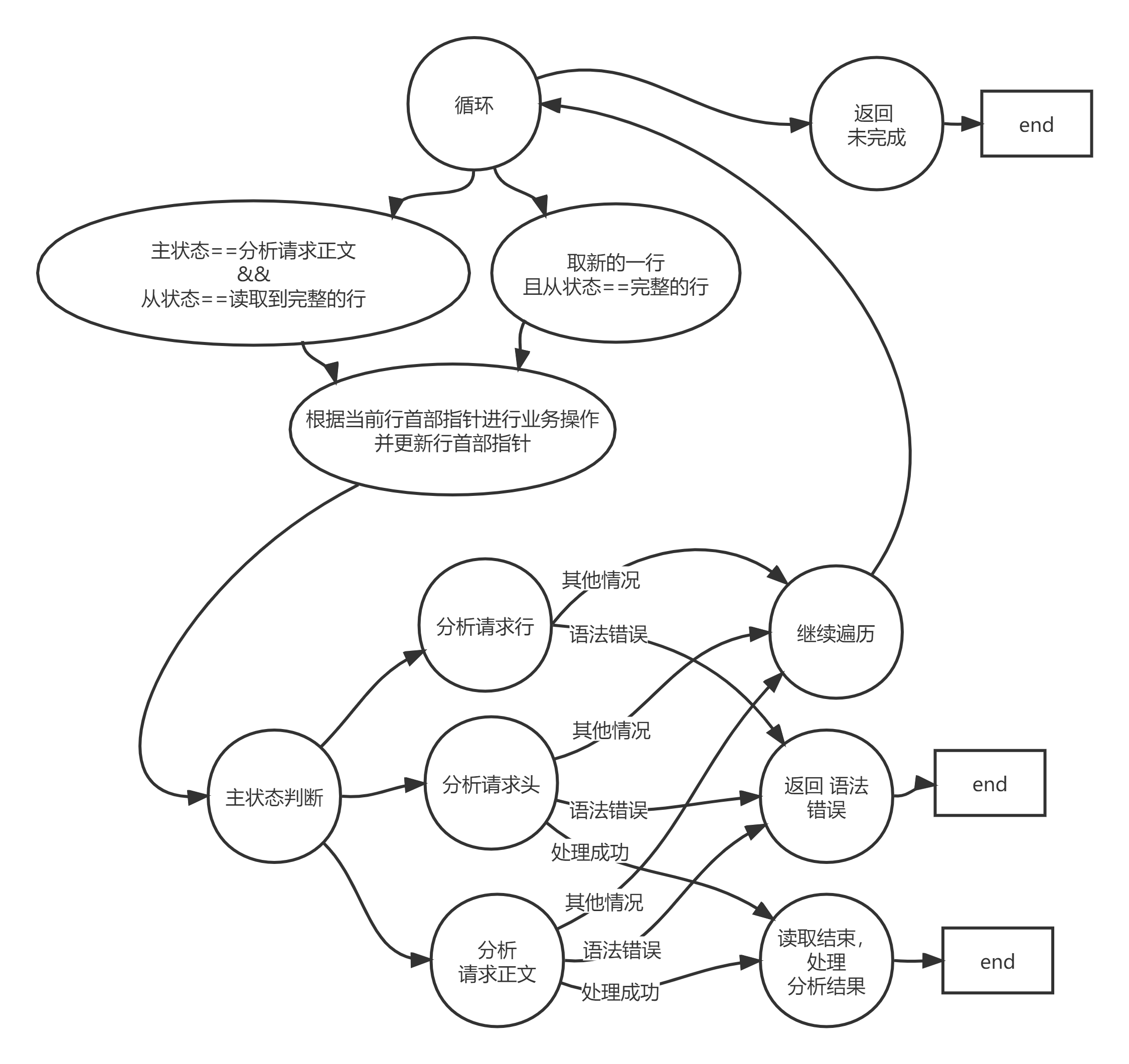
状态转移图
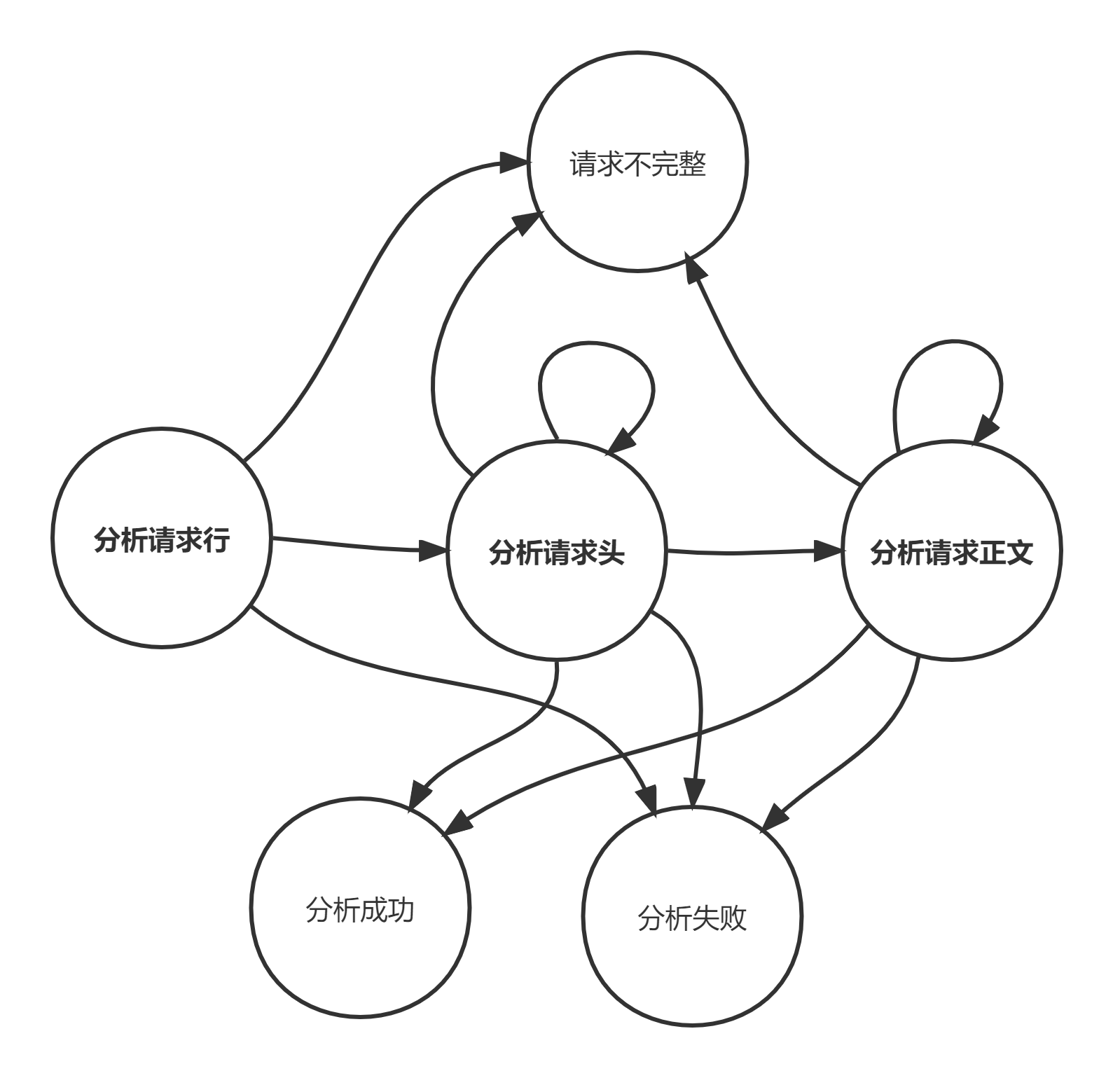
7.3 具体实现
//============== 主状态机 ===================
// 解析HTTP请求
http_conn::HTTP_CODE http_conn::process_read()
{
LINE_STATUS line_status = LINE_OK;
HTTP_CODE ret = NO_REQUEST;
char *text = NULL;
while ((m_check_state == CHECK_STATE_CONTENT && line_status == LINE_OK) \
|| ((line_status = parse_line()) == LINE_OK))
{ // 解析到了一行完整的数据 或者解析到了请求体,也是完整的数据
// 获取一行数据
text = get_line();
#ifdef patse_message
printf("\n即将解析的数据: %s\n", text);
#endif
m_start_line = m_checked_index;
// printf("got 1 http line : %s\n",text);
switch (m_check_state)
{
case CHECK_STATE_REQUESTLINE:
{
ret = parse_request_line(text);
// 分析返回值
if (ret == BAD_REQUEST)
{
return BAD_REQUEST;
}
break;
}
case CHECK_STATE_HEADER:
{
ret = parse_headers(text);
if (ret == BAD_REQUEST)
{
return BAD_REQUEST;
}
else if (ret == GET_REQUEST)
{
// 解析到完整的请求头
return do_request();
}
break;
}
case CHECK_STATE_CONTENT:
{
ret = parse_content_complete(text);
if (ret == BAD_REQUEST){
return BAD_REQUEST;
}
else if (ret == GET_REQUEST){
// 解析到完整的请求头
return do_request();
}
line_status = LINE_OPEN;
break;
}
default:{
return INTERNAL_ERROR;
}
}
}
return NO_REQUEST;
}
// 解析HTTP请求行,获取请求方法 ,目标URL,HTTP版本
http_conn::HTTP_CODE http_conn::parse_request_line(char *text)
{
// 1.解析请求行
// GET /index.html HTTP/1.1
// 1.1 请求方法 URL 协议版本
// 初始化以及填入\0进行分隔
char *index=text;
// method
char *method = text;
// m_url
index=strpbrk(index, " \t");
if (!index) return BAD_REQUEST;
*(index++) = '\0'; // 填充以及移动
m_url=index;
// m_version
index=strpbrk(index, " \t");
if (!index) return BAD_REQUEST;
*(index++) = '\0'; // 填充以及移动
m_version=index;
// 1.2 进行分析判断和进一步处理
// method,只允许GET
if (strcasecmp(method, "GET") == 0){
m_method = GET;
}
else{
return BAD_REQUEST;
}
// url分析
// 比如http://192.168.110.129:10000/index.html 需要去掉 http:// 这7个字符
if (strncasecmp(m_url, "http://", 7) == 0)
{
m_url += 7;
// 跳到第一个/的位置
m_url = strchr(m_url, '/');
}
if (!m_url || m_url[0] != '/')
return BAD_REQUEST;
// version分析
if (strcasecmp(m_version, "HTTP/1.1") != 0)
return BAD_REQUEST;
// 2.更新检测状态,检测完请求行以后需要检测请求头
m_check_state = CHECK_STATE_HEADER;
// 3.return
#ifdef patse_message
printf("请求头解析成功\n url:%s,version:%s,method:%s\n", m_url, m_version, method);
#endif
return NO_REQUEST;
}
// 解析HTTP请求头
http_conn::HTTP_CODE http_conn::parse_headers(char *text)
{
/**
* "Connection:"
* "Content-Length:"
* "Host:"
*/
// 被perse_line处理过后,若text为空行,说明请求头已经结束
if (text[0] == '\0')
{
// 若HTTP请求有消息体(m_content_length!=0) 则继续读取消息体
if (m_content_length != 0)
{
m_check_state = CHECK_STATE_CONTENT;
return NO_REQUEST;
}
// 否则读完成
return GET_REQUEST;
}
else if (strncasecmp(text, "Connection:", 11) == 0)
{
text += 11; // 去除key
text += strcspn(text, " \t"); // 去除开头的空格和\t
if (strcasecmp(text, "keep-alive") == 0)
{
m_keepalive = true;
}
else if (strcasecmp(text, "close") == 0)
{
m_keepalive = false;
}
}
else if (strncasecmp(text, "Content-Length:", 15) == 0)
{
text += 15; // 去除key
text += strcspn(text, " \t"); // 去除开头的空格和\t
m_content_length = atol(text);
}
else if (strncasecmp(text, "Host:", 5) == 0)
{
text += 5; // 去除key
text += strcspn(text, " \t"); // 去除开头的空格和\t
m_host = text;
}
else
{
#ifdef patse_message
printf("解析失败,不知名的请求头: %s\n", text);
#endif
}
return NO_REQUEST;
}
// 解析HTTP请求内容
http_conn::HTTP_CODE http_conn::parse_content_complete(char *text)
{
// 根据m_content_length查看内容是否完全读入
if (m_read_index >= (m_checked_index + m_content_length))
{
// 数据完整
text[m_content_length] = '\0';
return GET_REQUEST;
};
// 返回不完整
return NO_REQUEST;
}
// 在分析完成以后进行具体的处理
http_conn::HTTP_CODE http_conn::do_request()
{
// 更新
int sumlen = strlen(m_url) + strlen(root_directory) + 1;
snprintf(m_filename, std::min((int)(FILENAME_MAXLEN), sumlen), "%s%s", root_directory, m_url);
printf("m_filename :%s\n", m_filename);
// m_filename = "resources" + "/xxxxxxx"
// 获取文件相关信息
int ret = stat(m_filename, &m_file_stat);
if (ret == -1)
{
perror("stat");
return NO_RESOURCE;
}
// 判断访问权限
if (!(m_file_stat.st_mode & S_IROTH))
{
return FORBIDDEN_REQUEST;
}
// 判断是否是目录
if (S_ISDIR(m_file_stat.st_mode))
{
return BAD_REQUEST;
}
// 对文件操作 只读方式打开
int fd = open(m_filename, O_RDONLY);
// 创建内存映射
m_address_mmap = (char *)mmap(0, m_file_stat.st_size, PROT_READ, MAP_PRIVATE, fd, 0);
#ifdef mmap_print
printf("\nmmap :==================\n %s\n\n", m_address_mmap);
#endif
close(fd);
return FILE_REQUEST; // 获取文件成功
}
//================== 从状态机 ====================
http_conn::LINE_STATUS http_conn::parse_line()
{
// 根据\r\n
char temp;
for (; m_checked_index < m_read_index; ++m_checked_index)
{
temp = m_read_buf[m_checked_index];
if (temp == '\r')
{ // 遇到'\r' 进行判断
if ((m_checked_index + 1) == m_read_index){
// '\r'为最后一个,说明有数据未完
return LINE_OPEN;
}
else if (m_read_buf[m_checked_index + 1] == '\n')
{
// 完整的一句,将 \r\n 变为 \0
m_read_buf[m_checked_index++] = '\0';
m_read_buf[m_checked_index++] = '\0';
// 相当于 x x+1 = \0 then x+=2
return LINE_OK;
}
return LINE_BAD;
}
else if (temp == '\n'){
if ((m_checked_index > 1 && m_read_buf[m_checked_index - 1] == '\r'))
{ // 这次的第一个和上一次的最后一个是一个分隔
m_read_buf[m_checked_index - 1] = '\0';
m_read_buf[m_checked_index++] = '\0';
return LINE_OK;
}
}
}
return LINE_OPEN;
}














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









