







文章目录
学习raft过程的知识总结,比较粗陋,想多少写多少
raft要解决的问题
作为共识性算法,通过多数派投票来保证各个副本的内容一致,本质上是状态机复制问题。
raft 的节点由日志和状态机组成,状态机保存一些变化的参数,如当前的index、租期、follower同步的最新日志index 等等;日志即一系列的日志文件。
raft 的子模块
为了便于理解 (论文里面一直吐槽 Paxos 的难以理解),raft 将状态机复制问题 分为了 3个子模块,即:
- leader 选举
- 日志复制
- 安全性
raft 节点的3个角色
- leader 由它来决定日志写入的情况,通过选举确认
- follower 除leader以外的节点,接受leader的消息
- candidator 投票时候的节点
- leaner 论文里面没有提,但是在节点增减的时候会有节点只学习不投票,在tidb 的实现里面被称为 leaner
raft 的两种RPC 请求
- RequestVote RPCs(请求投票):由 candidate 在选举过程中发出(5.2 节中描述)
- AppendEntries RPCs(追加条目):由 leader 发出,用来做日志复制和提供心跳机制(5.3 节中描述)。
raft 的安全性
- 只要有任何服务器节点将一个特定的日志条目应用到它的状态机中,那么其他服务器节点就不能在同一个日志索引位置上存储另外一条不同的指令
- 相同任期和index 的日志是一样的,并且之前的日志都一样
raft 的选举
leader 节点会广播心跳来维持自己leader 的身份,当超过时间未收到广播,follower会转换为 candidator ,给自己“拉票”,产生一个任期(一个 单调递增的数字)和当前的日志 index 和 term ,广播给其他节点。
即 通过 RequestVote 请求来进行选举,超过半数的follower响应后,自动转为leader。
之所以 RequestVote 的请求带有当前的日志 index 和 term,是确保只有含有最新的日志的 follower可以被选举为leader,假如 follower收到 RequestVote 请求,但是自己的日志比请求里面的新,会拒绝投票。
对于“选票被瓜分的情况”
可能会有多个节点同时参选,然后都没有凑够1/2 的选票;或者大部分节点都把选票投给了自己,也没有凑够1/2 的选票。
对于这类情况,解决办法是 设定一个随机选举超时时间,这样参选就有先有后,更容易选举成功。
论文的 Section 9.3 提到,只需要很小的随机选举超时时间,就可以极大地改善 split vote 的问题
仅仅加入 5ms 的随机化时间,就大大改善了选举过程
raft 的日志复制
由leader 来决定日志复制到哪个位置,leader 通过 AppendEntries 请求来将当前的index和上一个index 同步给follower。若超过半数节点响应写入完成,则leader 会更新状态机,试做已提交
间接同步之前的日志
若follower 之前的日志都和leader 相同,那只需要复制最新的要写入的日志即可。
若follower 之前的日志与 leader 不同,那leader 会把 index 回退1 ,重新发送,直到找到双方的共同相同的日志index,follower将不同的部分删掉,然后逐个同步leader 的日志。
成员变更
raft 集群可能有机器变更的情况——去掉旧机器或者增加新机器。
包含旧机器的信息(例如ip)的配置称为 Cold,新机器的信息称为 Cnew
为了避免 Cold 和Cnew 两个不同集群配置的集群各自选出leader 导致脑裂,raft有成员变更模式
增加一个 Cold,new 的中间态,此时 leader要投票成功,必须获取 Cold 和 Cnew 里面各自半数节点的投票才行。然后 leader 就可以安全地同步Cnew的日志。
在超过半数节点为 Cnew 的配置的时候,就可以试做配置更新成功。
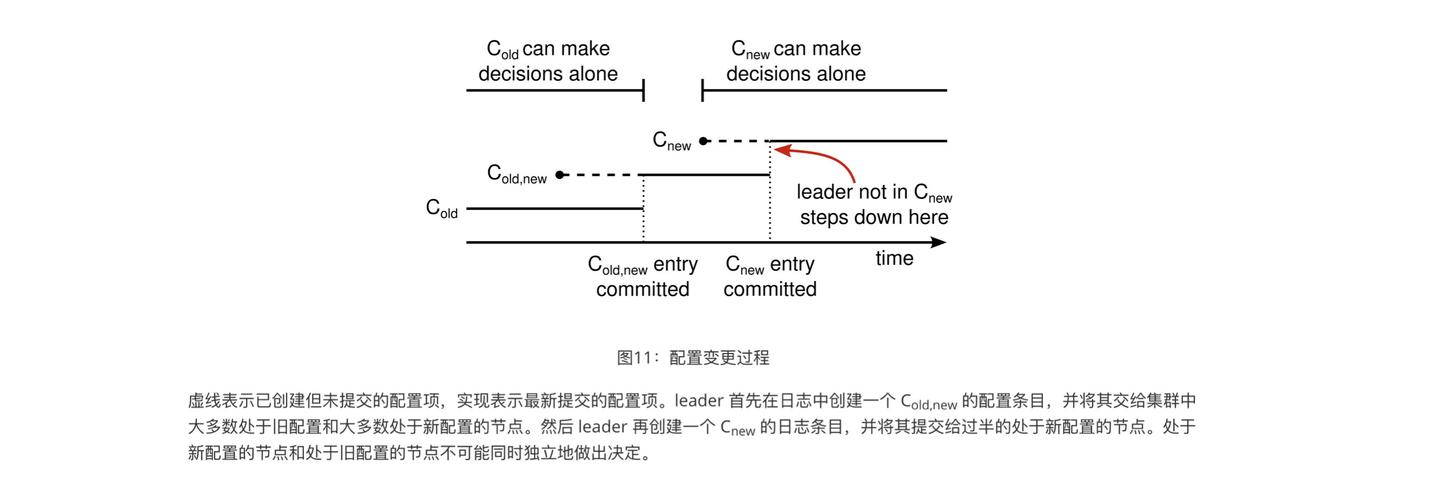
不在Cnew 配置里面的老成员的干扰
Cold里面被下线的机器,因为Cnew里面不包含它,无法收到leader 的广播,因此会处于candidator状态参选,假如发给当前的leader,会导致leader回退到 follower,然后选出一个新的leader
为了避免这个问题,在收到 leader 的 心跳后 的最小选举时间内,收到 RequestVote 会忽略 —— 这也相当于leader 有一个租期(最小选举时间)
对于这个问题,我感觉可以通过不是Cnew 里面的机器的 请求 就直接忽略就可以了
为什么leader不能提交之前任期的日志
因为leader不能保证之前任期的日志 会比follower相同index的任期要更大, 用 index=1 ,term=1 的日志去替换 index=1,term=2 的日志是不被允许的
但是假如 leader要同步新的日志,该日志的 index 和 term 都更大,在同步的过程中将之前任期的日志替换掉是被允许的
同时 为了尽快完成之前日志的同步和覆盖保证一致性,每个leader就任时都会发一个 no-op 日志,来被动同步 —— 我理解这样也会导致每个leader 的就任都是有痕迹的,方便租期的更新
其他内容
日志压缩
将log转换为 checkpoint,实际上进行 compaction 操作
时序
需要保证以下的情况:
广播时间(broadcastTime) << 选举超时时间(electionTimeout) << 平均故障间隔时间(MTBF)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









