






一:分布式核心概念
1.1.分布式
分布式是研究如何把一个大的项目拆分成一个个小项目,然后把这些小项目分给多个计算机进行处理,最后把这些计算结果综合起来得到最终的结果。
分布式主要有三个方向:
- 分布式计算
- 分布式存储
- 分布式系统
1.2.分布式系统
简介:
分布式系统一定是由多个节点组成的系统。其中,节点指的是计算机服务器,而且这些节点一般不是孤立的,而是互通的。
同一个业务模块分拆多个子业务,部署在不同的服务器上,解决高并发的问题,提供可扩展性以及高可用性,业务中使用分布式的场景主要有分布式存储以及分布式计算。分布式存储中可以将数据分片到多个节点上,不仅可以提高性能(可扩展性),同时也可以使用多个节点对同一份数据进行备份
因为将业务进行了拆分,所以衍生出了分布式调用,核心的实现技术为:rest和rpc
分布式环境的特点:
- 分布性:服务部署空间具有多样性
- 并发性:同一个分布式系统中的多个节点,可以同时访问一个共享资源。数据库、分布式存储
- 无序性:进程之间的消息通信,会出现顺序不一致问题
1.3.分布式SOA架构
SOA:即面向服务的系统架构,是一个组件模型,SOA架构主要有三种实体:service provider (服务提供者)、 service requestor (服务使用者)和 service register (服务注册中心)。这三种实体又有三种服务处理功能:Publish(发布)、Find(查找)与 Bind(捆绑)
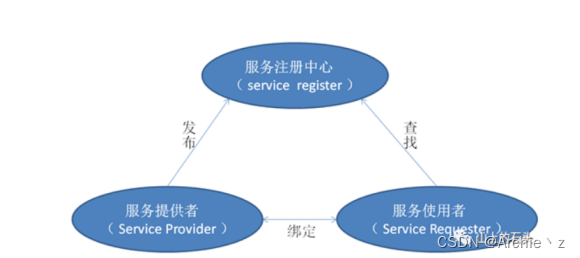
SOA的好处
- 能够使构建在不同的系统中的服务使用一种统一的方式进行交互
- 能够帮助系统架构设计者以更迅速、更可靠、更具重用性地构建整个业务系统
能够松耦合地 - 集成各个独立的信息系统,打破传统系统边界,实现系统间互联互通与服务共享。
1.4.微服务架构
它提倡将单一应用程序划分成一组小的服务,服务之间互相协调、互相配合,为用户提供最终价值。每个服务运行在其独立的进程中,服务与服务间采用轻量级的通信机制互相沟通(通常是基于HTTP的RESTful API)。每个服务都围绕着具体业务进行构建,并且能够独立地部署到生产环境、类生产环境等。
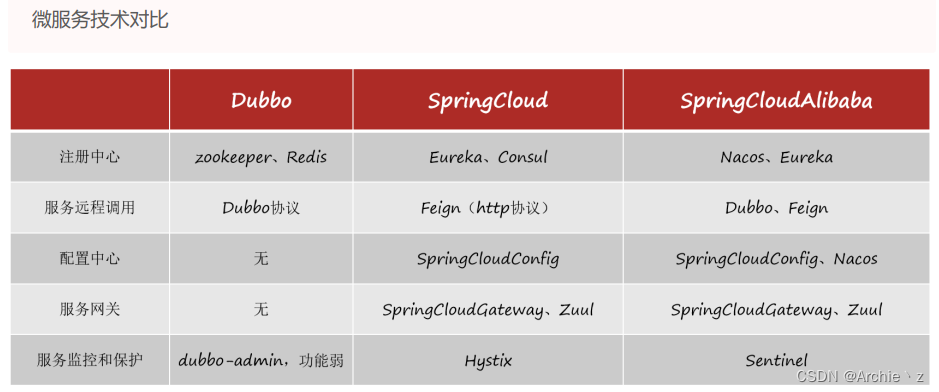
1.5.微服务技术对比
- 服务集群: 主要解决高并发的,每一个服务都可能会搭建集群,每一个集群都可能有若干服务器,解决并发问题之余还是提高服务的容错率。
- 注册中心: 主要微服务管理工作。
- 配置中心: 为了保证大家更新系统性的配置的时候不用每一个服务器都更改。
- 服务网关: 请求拦截以及负载均衡。
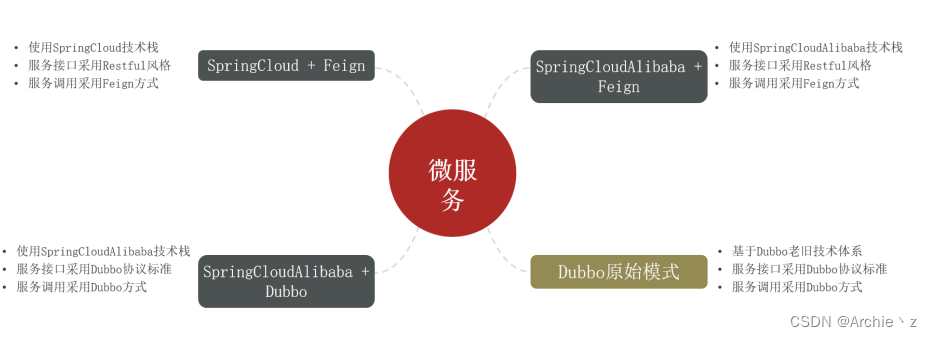
二:系统架构演变
2.1.单体架构
单体架构:将业务的所有功能集中在一个项目中开发,打成一个包部署。
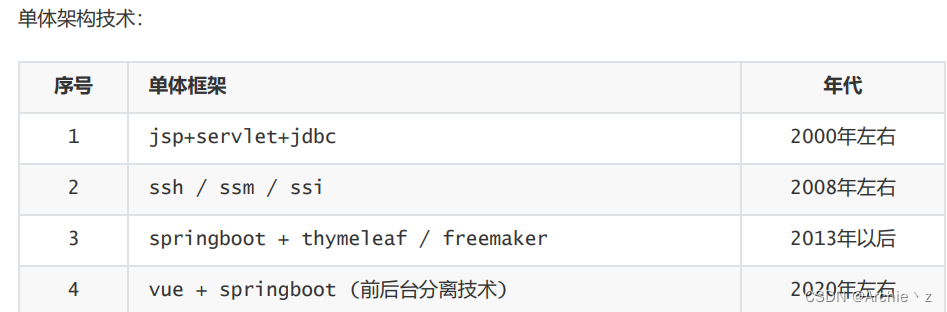 单体架构的优点
单体架构的优点
- 学习成本低
- 部署维护成本低
- 中小型项目选择较多
单体架构缺点:
- 耦合度高
- 技术的耦合度高
- 代码耦合度高
- 开发难度也大
- 维护较困难(任何一点出错,导致项目直接挂掉)
- 扩展能力差(因为都在一个项目中,增加任何技术都需要考虑是否兼容)
2.2.垂直拆分架构
垂直拆分:为了应对访问量逐渐加大,服务器压力加大,单一架构无法满足需求,所以将访问量较大的业务模块拆分出去,形成一个单独的项目,初步做到并发分流。
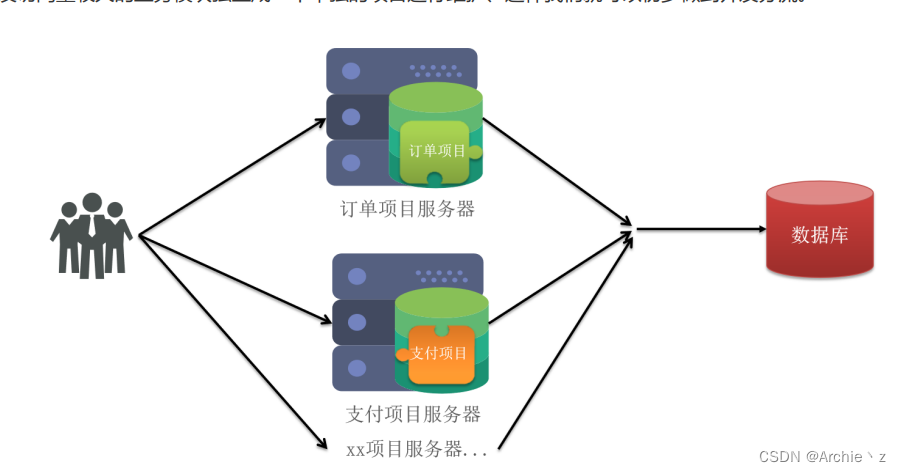
优点:
- 系统拆分实现了流量分担,解决了一部分并发问题,也可以单独打包部署了。
- 可以针对不同模块进行优化(起停)
- 方便水平扩展,负载均衡,容错率提高
缺点:
- 系统间相互独立,会有很多重复开发工作,影响开发效率。
- 各个模块之间涉及到使用对方数据的情况下需要远程调用。
- 每一个项目都是一个完整的框架(例如SSM)、版本升级、更新信息等都需要做很多重复的工作才能达到统一,只要一个环节沟通不畅就会导致项目出现问题。
- 为了解决并发问题、失去了敏捷开发思想、企业收益也大打折扣。
2.3.分布式架构
分布式架构:根据业务功能对系统进行拆分,每个业务模块作为独立项目开发,称为一个服务。同时逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求,用于提高业务复用。
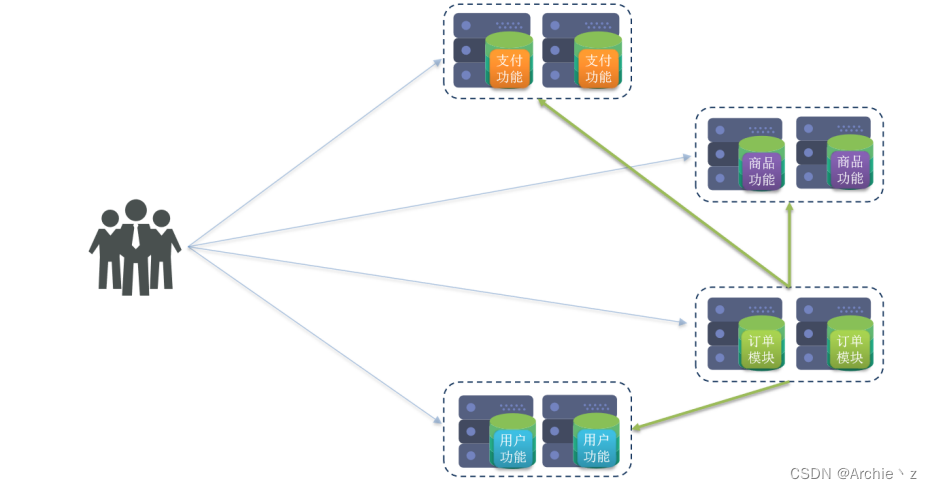
2.4.微服务架构
微服务架构特征:
- 单一职责:微服务拆分粒度更小,每一个服务都对应唯一的业务能力,做到单一职责,避免重复业务开发
- 面向服务:微服务对外暴露业务接口
- 自治:团队独立、技术独立、数据独立、部署独立
- 隔离性强:服务调用做好隔离、容错、降级,避免出现级联问题
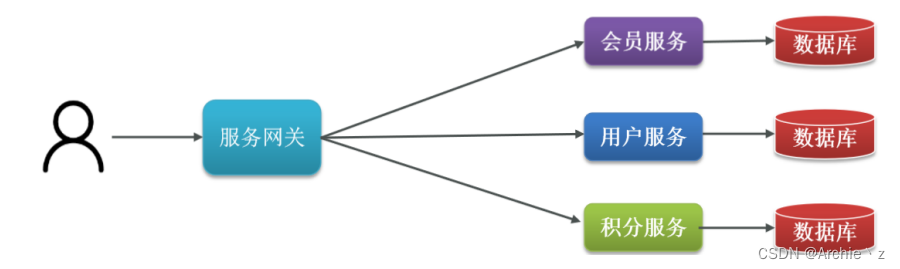
2.5.总结
单体架构特点?
简单方便,高度耦合,扩展性差,适合中小型项目。例如:学生管理系统
布式架构特点? 低耦合高内聚
松耦合,扩展性好,但架构复杂,难度大。适合大型互联网项目,例如:京东、淘宝
微服务:
一种良好的分布式架构方案
优点:拆分粒度更小、服务更独立、耦合度更低
缺点:架构非常复杂,运维、监控、部署难度提高(不用担心) – 运维 docker
三:springCloud
Spring Cloud 是基于 Spring 框架的微服务开发工具包,它提供了一系列工具和技术,用于开发
和管理分布式系统中的微服务。Spring Cloud 可以帮助开发人员快速搭建、配置、连接和管理微服务,简化了分布式系统的开发和部署。
四:服务拆分
4.1.拆分思想和原则
- 单一职责:不同微服务,不要重复开发相同业务(业务拆分)
- 数据独立:不要访问其它微服务的数据库
- 面向服务:将自己的业务暴露为接口,供其它微服务调用

4.2.操作步骤
1、创建数据库,导入需要的数据
2、创建父类工程
因为这个项目我们是父工程, 将来这个项目下面会有很多子工程,所以我们需要将当前工程打包方式改为pom
<!-- 父工程需要指定打包方式为pom -->
<packaging>pom</packaging>
同时还要进行版本的管理
- SpringBoot父启动器
- 统一管理jar包版本
- 实际导入的依赖
- maven插件
<!-- 1 SpringBoot的默认默认引用的父类 -->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.12.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<!-- 2.版本控制声明依赖包版本号及公共配置 -->
<properties>
<!-- 文件拷贝时的编码 -->
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<!-- 编译时的编码 -->
<maven.compiler.encoding>UTF-8</maven.compiler.encoding>
<java.version>1.8</java.version>
<spring-cloud.version>Hoxton.SR12</spring-cloud.version>
<!-- MyBatis-plus系列 -->
<mybatis-plus.version>3.4.1</mybatis-plus.version>
<mybatis-plus-generator.version>3.4.1</mybatis-plus-generator.version>
<velocity-engine-core>2.2</velocity-engine-core>
<!-- 数据库驱动版本 -->
<mysql.version>8.0.16</mysql.version>
<!-- 工具包 -->
<hutool.version>5.7.10</hutool.version>
<!-- 分页工具 -->
<pagehelper.version>1.3.0</pagehelper.version>
</properties>
<!-- 2引入声明的依赖(引入但并不使用) 提前引入的目的是子项目再次使用可以不是书写版本号 -->
<dependencyManagement>
<dependencies>
<!-- SpringCloud -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<!--Maven 父子项目结构和 Java 继承一样,都是单继承,一个子项目只能制定一个父pom。很多时候,我们需要打破这种 单继承,就使用type+import -->
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- mybatis-plus -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<!-- 代码生成工具 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>${mybatis-plus-generator.version}</version>
</dependency>
<!-- 代码生成模板 -->
<dependency>
<groupId>org.apache.velocity</groupId>
<artifactId>velocity-engine-core</artifactId>
<version>${velocity-engine-core}</version>
</dependency>
<!-- 数据连接驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
<!-- hutool -->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>${hutool.version}</version>
到此父类工程我们创建完成!
4.3 创建子工程-用户
</dependency>
</dependencies>
</dependencyManagement>
<!--3 直接继承的依赖,所以子项目默认继承 -->
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>2.7.11</version>
</dependency>
<!-- 单元测试 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
</dependencies>
3、创建子工程-用户
pom文件所需要的依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- 数据连接驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!-- mybatis-plus -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
</dependency>
<!-- 代码生成工具 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
</dependency>
<!-- 代码生成模板 -->
<dependency>
<groupId>org.apache.velocity</groupId>
<artifactId>velocity-engine-core</artifactId>
</dependency>
</dependencies>
创建application.yaml
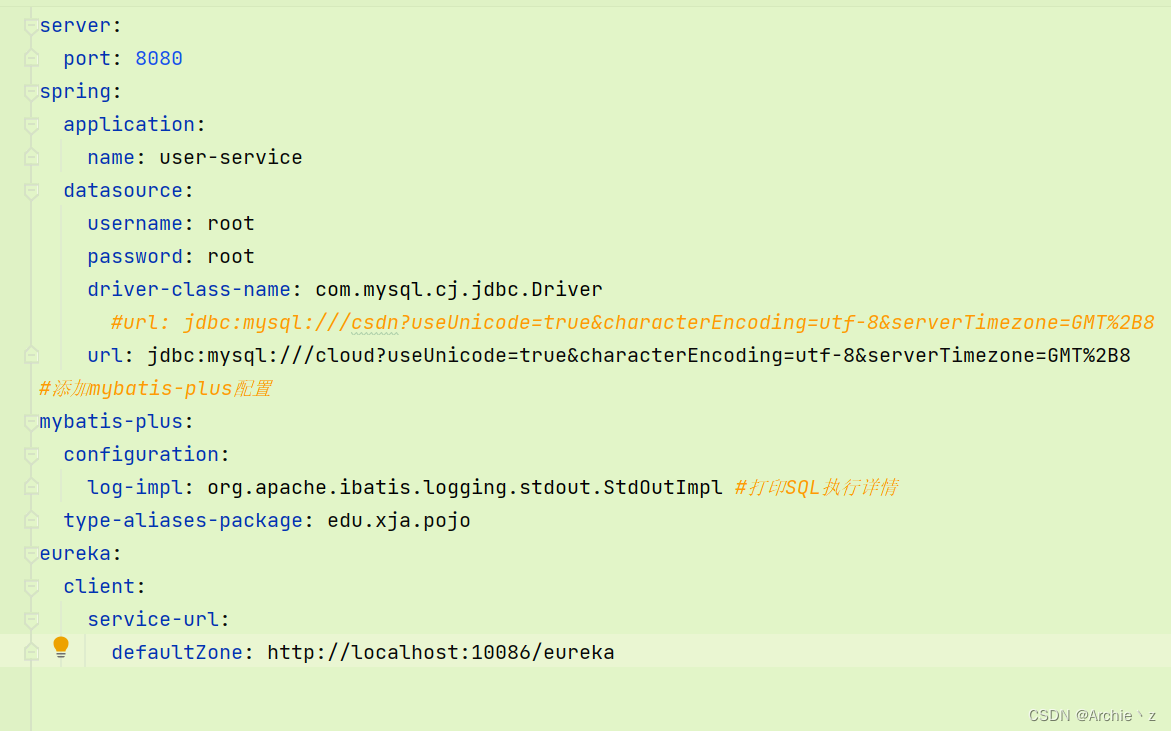
使用mybatis-plus进行自动创建
编写Controller层,进行测试

order同理
五、Springcloud1 NetflixOSS
1、Eureka原理
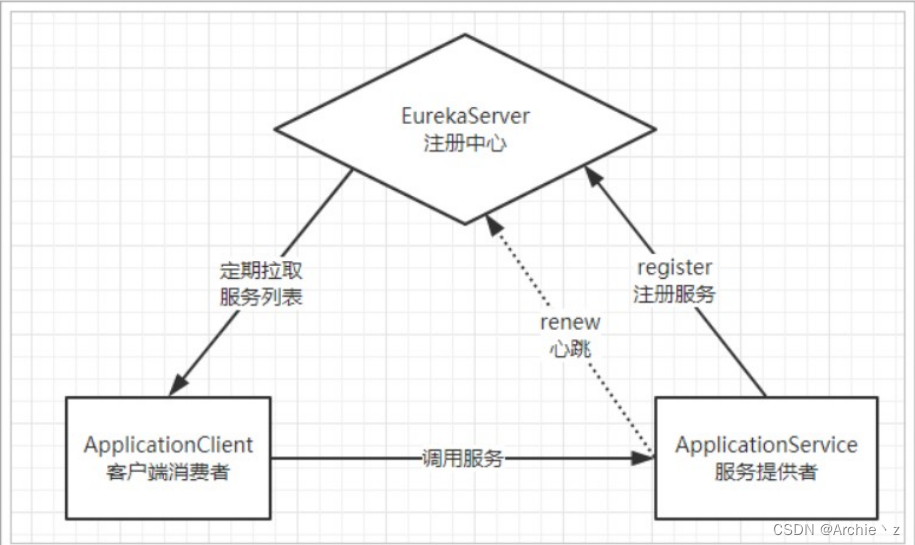
- Eureka:就是服务注册中心(可以是一个集群),对外暴露自己的注册地址
- 提供者:启动后向Eureka注册自己信息
- 消费者:向Eureka订阅服务,Eureka会将对应服务的所有提供者地址列表发送给消费者,并且定期更新
- 心跳(续约):提供者定期通过http方式向Eureka刷新自己的状态
2、案例编写
2.1.新建一个子项目eureka-server,添加依赖
<!-- 引入Eureka依赖 -->
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
</dependencies>
2.2.指定端口号
server:
port: 10086
2.3.编写启动类
@EnableEurekaServer //启动Eureka服务
@SpringBootApplication
public class EurekaApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaApplication.class);
}
}
2.4.补全yaml配置,不然回报错
server:
port: 10086 #呼叫中心
eureka:
client:
service-url: # EurekaServer的地址,现在是自己的地址,如果是集群,需要加上其它Server的地址
defaultZone: http://127.0.0.1:10086/eureka
spring:
application:
name: eureka-server # 应用名称,会在Eureka中显示
2.5.(提供者)启动user-service并注册到Eureka
注册服务,就是在服务上添加Eureka的客户端依赖,客户端代码会自动把服务注册EurekaServer中。
2.5.1.在user-service中添加Eureka客户端依赖
<!-- Eureka客户端 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
2.5.2.在user-service的启动类上添加@EnableDiscoveryClient注解来开启Eureka库换功能
2.5.3.配置yaml文件
spring
application:
name: user-service # 应用名称
eureka:
client:
service-url: # EurekaServer的地址
defaultZone: http://127.0.0.1:10086/eureka
2.5.4.启动测试

2.6.消费者从Eureka获取服务
2.6.1.在order-service中导入Eureka客户端依赖
<!-- Eureka客户端 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
2.6.2.在启动类添加注解@EnableDiscoveryClient 来开启Eureka客户端功能
2.6.3.编写yaml配置
spring
application:
name: order-service # 应用名称
eureka:
client:
service-url: # EurekaServer的地址
defaultZone: http://127.0.0.1:10086/eureka
2.6.4.修改控制层RestTemplate代码
@GetMapping("/{id}")
public Order findById(@PathVariable Long id){
Order order = orderService.getById(id);
//根据restTemplate提供的方法,来根据给定的id进行查询 User.class声明返回的对象
//从eureka注册中心进行拉取user-service
List<ServiceInstance> instances = discoveryClient.getInstances("user-service");
ServiceInstance serviceInstance = instances.get(0);
String url = "http://"+serviceInstance.getHost()+":"+serviceInstance.getPort();
User user = restTemplate.getForObject(url+order.getUserId(), User.class);
order.setUser(user);
return order;
}
2.6.5.进行测试

三、Eureka基础架构
三个核心角色
- 服务注册中心
Eureka的服务端应用,提供服务注册和发现功能,就是刚刚我们建立的eureka-server - 服务提供者
提供服务的应用,可以是SpringBoot应用,也可以是其它任意技术实现,只要对外提供的是Rest风格服务即可。即user-service - 服务消费者
消费应用从注册中心获取服务列表,从而得知每个服务方的信息,知道去哪里调用服务方。即order-service
服务同步及高可用
多个Eureka Server之间也会互相注册为服务,当服务提供者注册到Eureka Server集群中的某个节点时,该节点会把服务的信息同步给集群中的每个节点,从而实现数据同步。

搭建集群
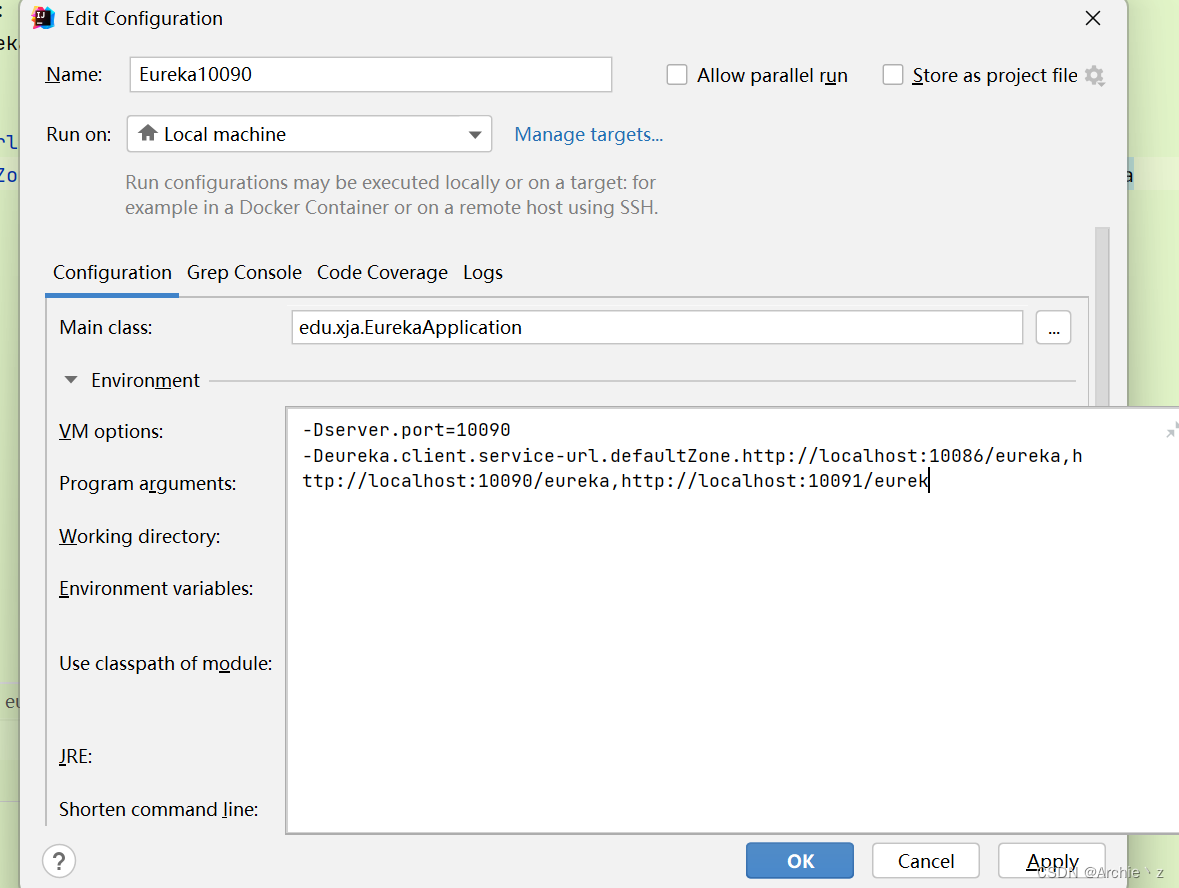
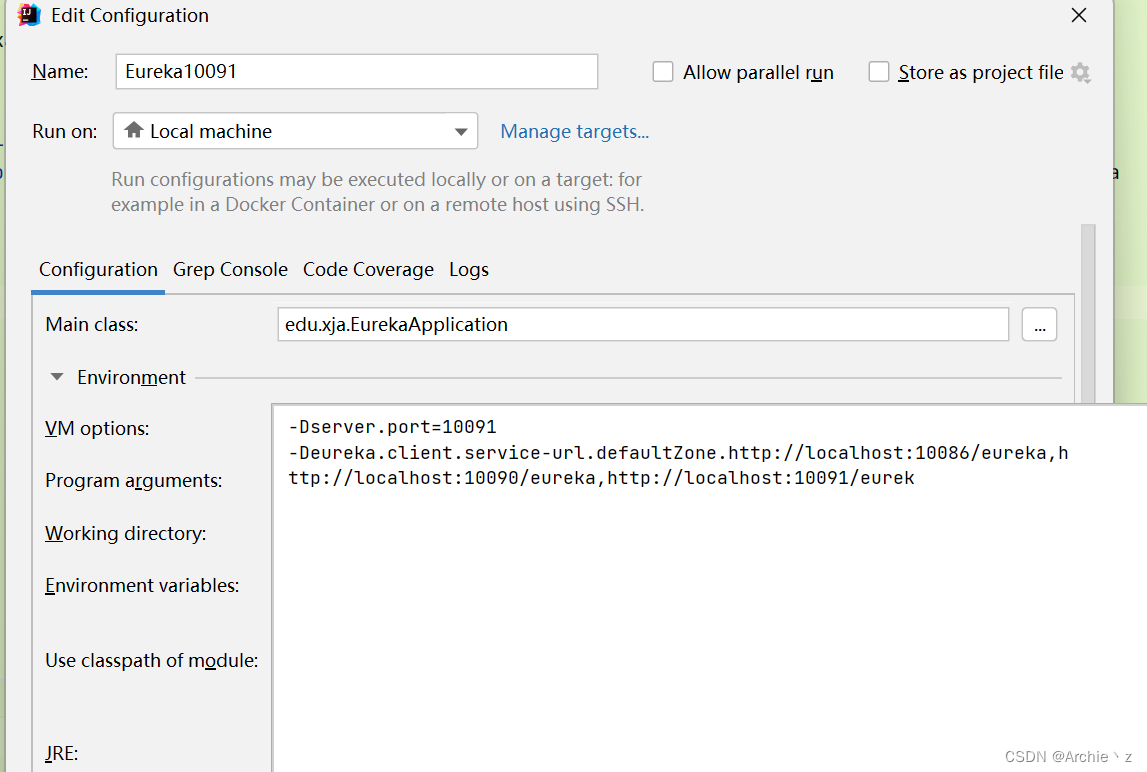
1、先修改原来的Erueka-server,修改注册地址为10087(让其不在注册自己)
server:
port: 10086 #呼叫中心
eureka:
client:
service-url: # EurekaServer的地址,现在是自己的地址,如果是集群,需要加上其它Server的地址
defaultZone:http://localhost:10086/eureka,http://localhost:10090/eureka,http://localhost:10091/eureka
2、启动端口号为10086的Eureka-server,copy两个不同实例,进行修改
3、全部启动,进行测试

Erueka客户端
服务注册
服务提供者要向EurekaServer注册服务,并且完成服务续约等工作。在启动时,会检测配置属性中的
eureka.client.register-with-erueka=true
(默认为true),则会向EurekaServer发起一个Rest请求,并携带自己的元数据信息。
服务续约
在注册服务完成以后,服务提供者会定时向EurekaServer发起Rest请求告诉
EurekaServer:“我还活着”。这个我们称为服务的续约(renew),可以在yaml文件中修改
eureka:
instance:
//服务失效时间,默认值90秒
lease-expiration-duration-in-seconds: 90
//服务续约(renew)的间隔,默认为30秒
lease-renewal-interval-in-seconds: 30
也就是说,默认情况下每30秒服务会向注册中心发送一次心跳,证明自己还活着。如果超过90秒没有发送心跳,EurekaServer就会认为该服务宕机
失效剔除
服务提供方有时候可能因为内存溢出、网络故障等原因导致服务无法正常工作。Eureka Server需要将这样的服务剔除出服务列表。因此它会开启一个定时任务,每隔60秒对所有失效的服务(超过90秒未响应)进行剔除。
自我保护

当看到这个警告时,说明触发了了Eureka的自我保护机制。当一个服务未按时进行心跳续约时,Eureka会统计最近15分钟心跳失败的服务实例的比例是否超过了85%。在生产环境下,因为网络延迟等原因,心跳失败实例的比例很有可能超标,但是此时就把服务剔除列表并不妥当,因为服务可能没有宕机。Eureka就会把当前实例的注册信息保护起来,不予剔除。
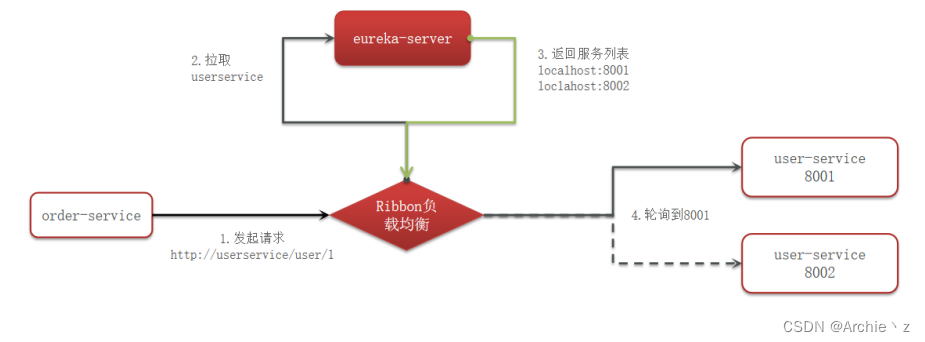
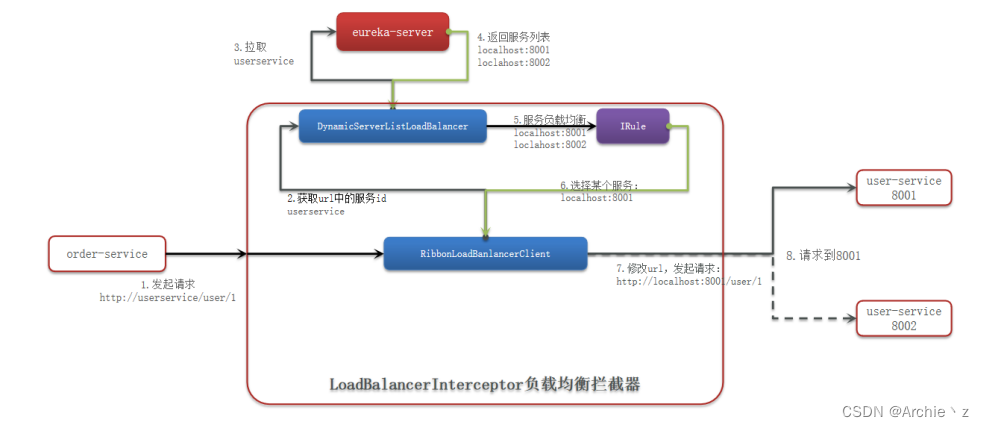
负载均衡Ribbon

负载均衡原理
实例
1、首先我们启动两个user-service实例,一个8000,一个8001。
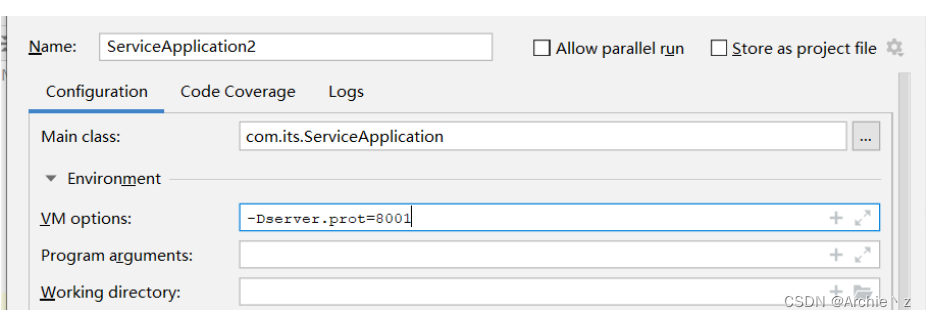
2、开启负载均衡
因为Eureka中已经集成了Ribbon,所以我们无需引入新的依赖。直接修改代码:
@Bean
@LoadBalanced //平衡 均衡
public RestTemplate restTemplate(){
return new RestTemplate();
}
@GetMapping("/{id}")
public Order findById(@PathVariable Long id){
Order order = orderService.getById(id);
//根据restTemplate提供的方法,来根据给定的id进行查询 User.class声明返回的对象
//从eureka注册中心进行拉取user-service
User user = restTemplate.getForObject("http://user-service/user/"+order.getUserId(), User.class);
order.setUser(user);
return order;
}
负载均衡策略
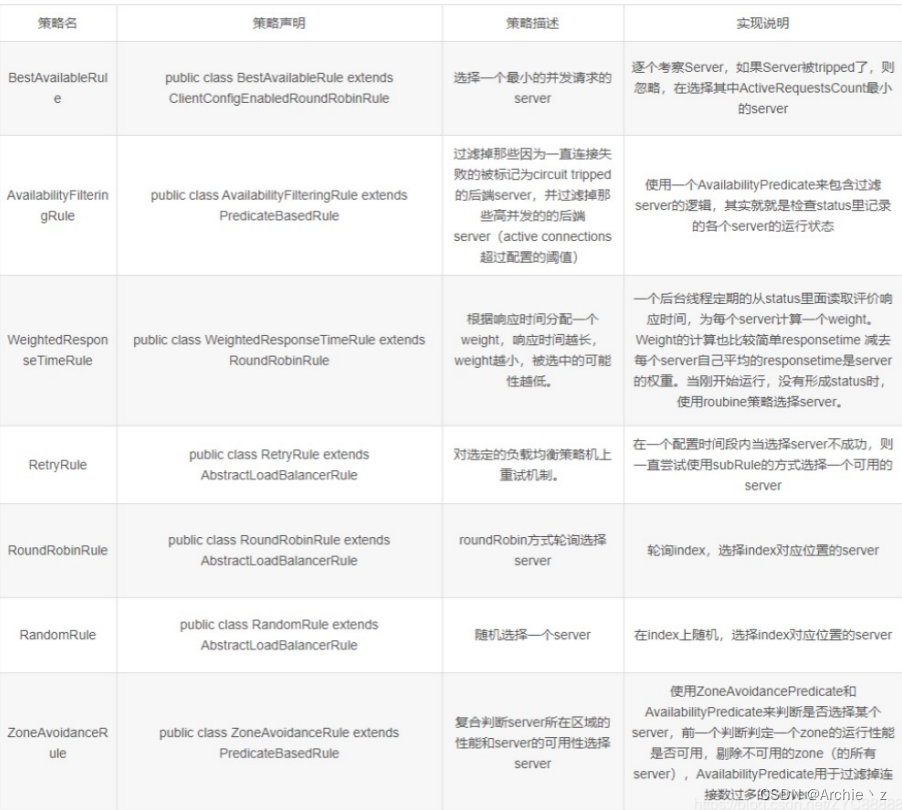
可以在yaml文件中进行配置
user-service:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule
Hystrix熔断器

雪崩问题
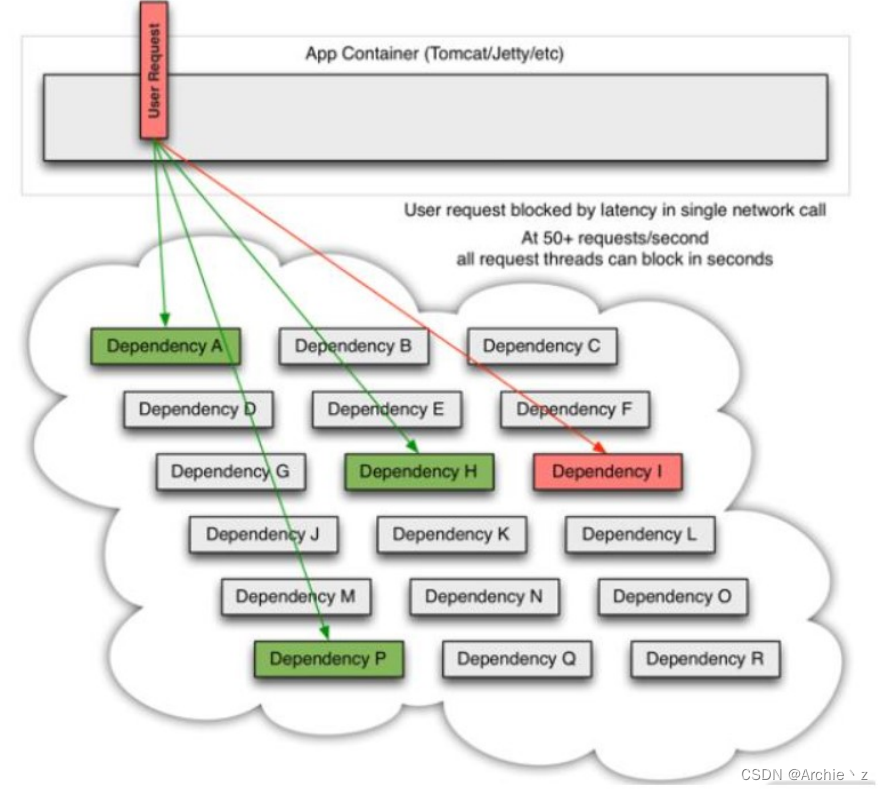
比如说一个业务,需要调用A、B、C、D四个服务,如果D服务发生异常,请求阻塞,这个线程就不会释放,如果越来越多的请求到来,就会造成线程阻塞。当请求耗尽之后,会消耗其他服务器线程从而导致其它服务器都不可用,就形成了雪崩效应。
hystrix解决雪崩问题
-
服务降级
-
服务熔断
服务降级
Hystrix 为每个依赖服务调用分配一个小的线程池,如果线程池已满调用将被立即拒绝,默认不采用排队。 用户的请求将不再直接访问服务,而是通过线程池中的空闲线程来访问服务,如果线程池已满 ,或者请求超时 ,则会进行降级处理。
服务降级:优先保证核心服务,而非核心服务不可用或弱可用。
用户的请求故障时,不会被阻塞,,至少可以看到一个执行结果。
服务降级虽然会导致请求失败,但是不会导致阻塞,而且最多会影响这个依赖服务对应的线程池中的资源,对其它服务没有响应。
触发 Hystrix 服务降级的情况:
- 线程池已满
- 请求超时
- 服务爆炸(宕机)
实例
1、在Order-service导入Hystix依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
2、开启服务降级
@SpringBootApplication
@EnableEurekaServer
@EnableCircuitBreaker
public class OrderServiceApplication {
public static void main(String[] args) {
SpringApplication.run(OrderServiceApplication.class);
}
//初始化RestTemplate
@Bean
@LoadBalanced
public RestTemplate restTemplate(){
return new RestTemplate();
}
}
3、编写错误返回消息
在原来的请求方法上添加@HystrixCommand注解来定义错误返回方法,在下方进行编写方法
@HystrixCommand(fallbackMethod = "studentsFallBack") //降级处理方法
/**
* 降级的处理方法,要求方法的返回值,参数都要一致
*/
public Order studentsFallBack(@PathVariable Long id){
return new Order();
}
服务熔断
熔断原理
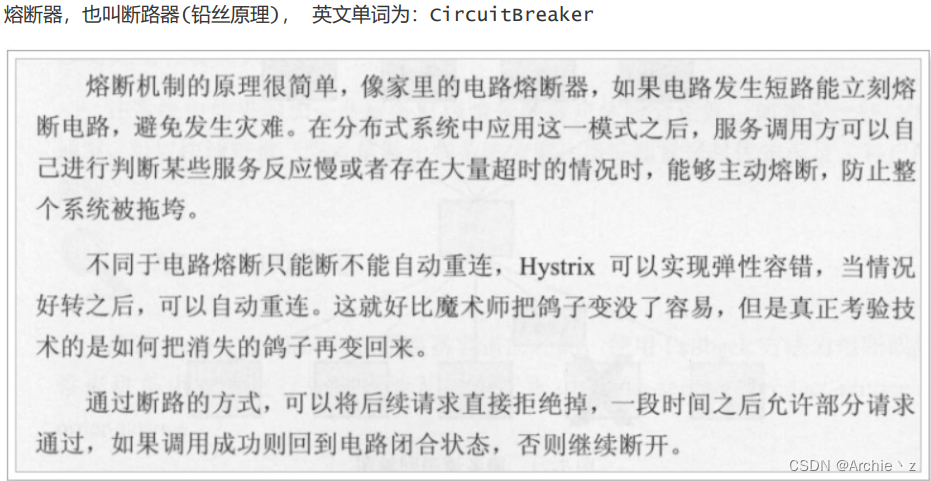
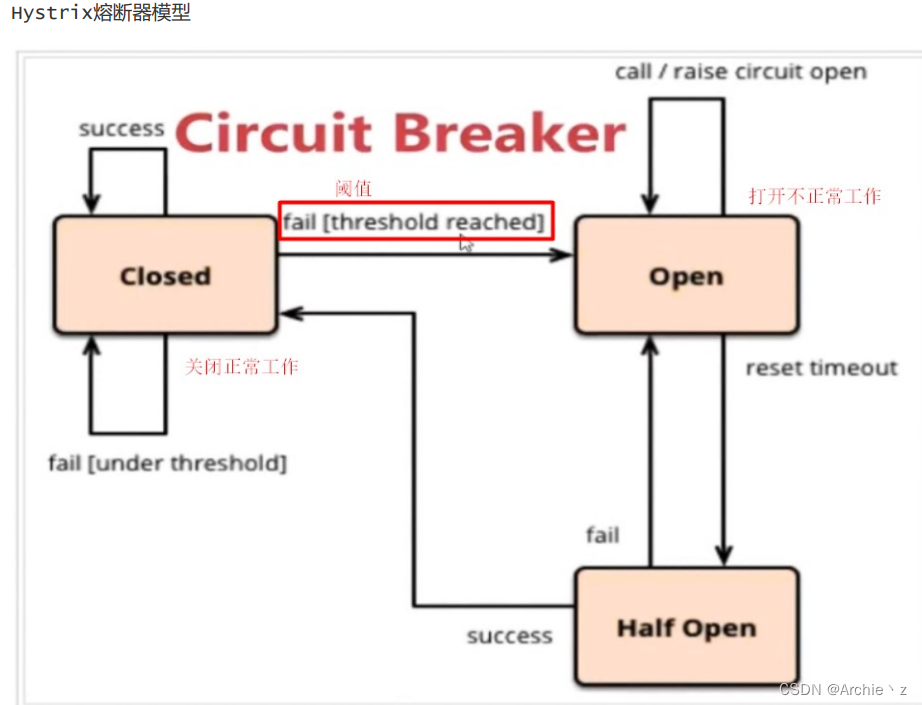
工作原理:阈值默认是最近20次请求内,有50%的请求发生降级处理(超时),触发打开熔断器!,此时进入5秒的休眠期,5秒后进入Half open(半开状态)。并且放一定的请求通过,测试请求是否正常,如果请求依然失败,直接进入打开状态(5秒循环),如果请求成功,关闭熔断器。
熔断器有三个状态:
- open状态说明打开熔断,也就是服务调用方执行本地降级策略,不进行远程调用。
- closed状态说明关闭了熔断,这时候服务调用方直接发起远程调用。
- half-open状态,则是一个中间状态,当熔断器处于这种状态时候,直接发起远程调用。
实例
1、修改配置控制层,自定义异常
@GetMapping("/{id}")
//降级处理方法
@HystrixCommand(fallbackMethod = "ErrorFindById",
//服务熔断
commandProperties={
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold",value = "10"),//熔断器请求量阈值 默认为20
@HystrixProperty(name = "circuitBreaker.sleepWindowInMilliseconds",value = "10000"),//熔断器休眠时间窗 默认5s
@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage",value = "50")//为熔断器服务错误(降级或者超时) 百分比 默认50
})
public Order findById(@PathVariable Long id){
Order order = orderService.getById(id);
// //自定义异常,判断熔断机制
// if(id==103){
// throw new RuntimeException("error");
// }
//根据restTemplate提供的方法,来根据给定的id进行查询 User.class声明返回的对象
//从eureka注册中心进行拉取user-service
// List<ServiceInstance> instances = discoveryClient.getInstances("user-service");
// ServiceInstance serviceInstance = instances.get(0);
//
// String url = "http://"+serviceInstance.getHost()+":"+serviceInstance.getPort();
// User user = restTemplate.getForObject("http://user-service/user/"+order.getUserId(), User.class);
User user = feignUser.findById(order.getUserId());
order.setUser(user);
return order;
}
2、进行测试
当访问orderId不是103时,可以正常返回数据,访问103时,不会返回正常数据,并且多次提交请求后,其他请求也不会返回正常数据,需要等待熔断器休眠时间过后,重新提交正确的orderId进行访问。
Feign (解决请求路径)
feign 主要也是在消费者项目中进行伪装

实例
1、在order-service(消费者)的pom文件中导入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
2、在启动类添加注解
@SpringBootApplication
@EnableEurekaServer
@EnableCircuitBreaker
@EnableFeignClients//开启Feign
public class OrderServiceApplication {
public static void main(String[] args) {
SpringApplication.run(OrderServiceApplication.class);
}
//初始化RestTemplate
@Bean
@LoadBalanced
public RestTemplate restTemplate(){
return new RestTemplate();
}
}
3、新建子项目FeignApi,编写请求地址的接口与实现类
接口部分

实现类部分
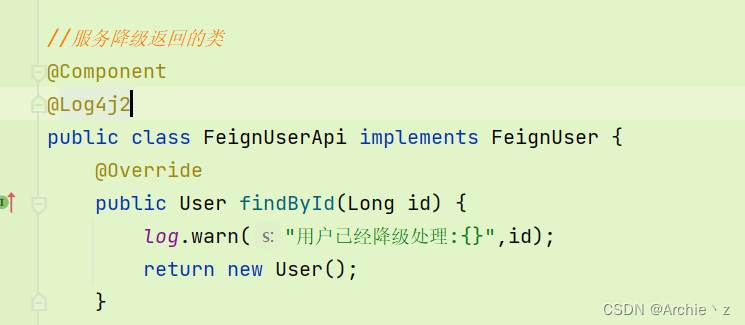
4、进行调用
@RestController
@RequestMapping("/order")
public class OrderController {
@Autowired
private OrderService orderService;
@Autowired
private FeignUser feignUser;
@GetMapping("/{id}")
public Order findById(@PathVariable Long id){
Order order = orderService.getById(id);
User user = feignUser.findById(order.getUserId());
order.setUser(user);
return order;
}
















 4986
4986











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









