







UUID
UUID:Universally Unique ldentifier 通用 唯一 标识符
对于所有的UUID它可以保证在空间和时间上的唯一性。它是通过MAC地址,时间戳,命名空间,随机数,伪随机数来保证生成ID的唯一性,有着固定的大小(128bit)。它的唯一性和一致性特点使得可以无需注册过程就能够产生一个新的UUID。UUID可以被用作多种用途,既可以用来短时间内标记一个对象,也可以可靠的辨别网络中的持久性对象。
MySQL中的UUID组成 = [时间低位+时间中位+时间高位](16字节)- 时钟序列(4字节) - MAC地址(12字节)

UUID() 返回一个值 符合 RFC 4122 中所述的 UUID 版本 1,表示为五个十六进制数字的字符串格式,中间用了 “-” 连接。
- 前三个数字字符串是从低处生成的, 时间戳的中间和高部分。高部分也 包括 UUID 版本号。
- 第四个数字字符串保留了时间唯一性,以防万一 时间戳值失去单调性(例如,由于 到夏令时)。
- 第五个数字字符串是 IEEE 802 节点编号,它提供 空间独特性。如果 后者不可用(例如,因为主机 设备没有以太网卡,或者不知
1.优点
- 保证了全局唯一性
- 更加安全
2. 缺点
- 存在隐私安全的问题,因为UUID包含了MAC地址,也就是机械的物理地址。
- 无序,随机生成与插入,聚集索引频繁页分裂,大量随机IO,内存碎片化,特别是随着数据量越来越多,插入性能会越差。
- 占用36字节,比较浪费空间。
雪花id
雪花 ID(Snowflake ID)是一个用于分布式系统中生成唯一 ID 的算法,由 Twitter 公司提出。它的设计目标是在分布式环境下高效地生成全局唯一的 ID,具有一定的有序性。
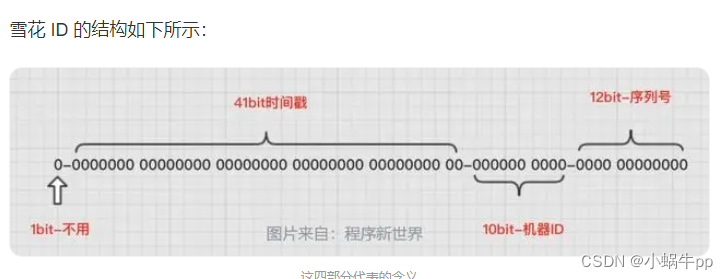
- 符号位:最高位是符号位,始终为 0,1 表示负数,0 表示正数,ID 都是正整数,所以固定为 0。
- 时间戳部分:由 41 位组成,精确到毫秒级。可以使用该 41 位表示的时间戳来表示的时间可以使用 69 年。可以根据时间进行排序。
- 节点 ID 部分:由 10 位组成,用于表示机器节点的唯一标识符。在同一毫秒内,不同的节点生成的 ID 会有所不同。
- 序列号部分:由 12 位组成,用于标识同一毫秒内生成的不同 ID 序列。在同一毫秒内,可以生成 4096 个不同的 ID。
1.优点
-
唯一性:雪花算法生成的ID是全局唯一的,可以在分布式系统中生成不重复的ID。ID由机器ID、时间戳和序列号组成,结合了这些因素以确保唯一性。
-
可排序性:雪花算法生成的ID包含时间戳,因此ID之间的时间顺序是有意义的。这对于按时间排序的数据非常有用,可以方便地根据ID获取生成的顺序信息。
-
高性能:雪花算法生成ID的过程是基于位运算和位移操作的,计算速度很快,并且生成ID的成本很低。
-
独立性:每个节点(进程或机器)的雪花算法生成ID的过程是相互独立的,不需要依赖于中央系统或数据库。这意味着系统可以水平扩展,并且不会成为单点故障。
2.缺点
虽然雪花算法是一种被广泛采用的分布式唯一 ID 生成算法,但它也存在以下几个问题:
- 时间回拨问题:雪花算法生成的 ID 依赖于系统的时间戳,要求系统的时钟必须是单调递增的。如果系统的时钟发生回拨,可能导致生成的 ID 重复。时间回拨是指系统的时钟在某个时间点之后突然往回走(人为设置),即出现了时间上的逆流情况。
- 时钟回拨带来的可用性和性能问题:由于时间依赖性,当系统时钟发生回拨时,雪花算法需要进行额外的处理,如等待系统时钟追上上一次生成 ID 的时间戳或抛出异常。这种处理会对算法的可用性和性能产生一定影响。
——————百度 UidGenerator 框架中解决了时间回拨的问题
- 节点 ID 依赖问题:雪花算法需要为每个节点分配唯一的节点 ID 来保证生成的 ID 的全局唯一性。节点 ID 的分配需要有一定的管理和调度,特别是在动态扩容或缩容时,节点 ID 的管理可能较为复杂。
自增id
1.优点
- 主键页以近乎顺序的方式填写,提升了页的利用率
- 索引更加紧凑,性能更好查询时数据访问更快
- 节省空间
- 连续增长的值能避免 b+ 树频繁合并和分裂
- 简单易懂,几乎所有数据库都支持自增类型,只是实现上各自有所不同而已
2.缺点
-
可靠性不高存在自增ID回溯的问题,这个问题直到最新版本的MySQL 8.0才修复。
-
安全性不高 ID不够随机,对外暴露的接口可以非常容易猜测对应的信息。比如:/User/1/这样的接口,可以非常容易猜测用户ID的值为多少,总用户数量有多少(泄露发号数量的信息),也可以非常容易地通过接口进行数据的爬取,因此不太安全。
-
性能差 自增ID的性能较差,需要在数据库服务器端生成。对于高并发的负载,innodb在按主键进行插入的时候会造成明显的锁争用,主键的上界会成为争抢的热点,因为所有的插入都发生在这里,并发插入会导致间隙锁竞争。
-
交互多 业务还需要额外执行一次类似 last_insert_id() 的函数才能知道刚才插入的自增值,这需要多一次的网络交互。在海量并发的系统中,多1条SQL,就多一次性能上的开销。
-
局部唯一性 最重要的一点,自增ID是局部唯一,只在当前数据库实例中唯一,而不是全局唯一,在任意服务器间都是唯一的。对于目前分布式系统来说,这简直就是噩梦。
-
不利于数据迁移与扩展
不适合以自增ID主键作为主键的情况
- 数据量多需要分库分表,可能会造成ID重复
- 经常会遇到数据迁移的情况
- 新数据需要和老数据进行合并
数据库自增 ID 只适用于单机环境,但如果是分布式环境,是将数据库进行分库、分表或数据库分片等操作时,那么数据库自增 ID 就有问题了。
例如,数据库分片之后,会在同一张业务表的分片数据库中产生相同 ID(数据库自增 ID 是由每个数据库单独记录和增加的),这样就会导致,同一个业务表的竟然有相同的 ID,而且相同 ID 背后存储的数据又完全不同,这样业务查询的时候就出问题了。
————————————————————————————————————————————-
————————————————————————————————————————————-
使用 UUID 替代雪花 ID 行不行?
如果单从唯一性来考虑的话,那么 UUID 和雪花 ID 的效果是一致的,二者都能保证分布式系统下的数据唯一性,但是即使这样,也不建议使用 UUID 替代雪花 ID,因为这样做的问题有以下两个:
- 可读性问题:UUID 内容很长,但没有业务含义,就是一堆看不懂的“字母”。
- 性能问题:UUID 是字符串类型,而字符串类型在数据库的查询中效率很低。















 416
416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









