







RAG检索增强生成
RAG练手文本读取,TFIDF文本嵌入和向量索引、多路召回未写,编码模型未进去–待写
1.初识RAG
大模型的局限性(LLM)
大型语言模型在自然语言处理领域展示了显著的能力,但它们也存在一系列固有的缺点。首先,虽然这些模型在掌握大量信息方面非常有效,但它们的结构和参数数量使得对其进行修改、微调或重新训练变得异常困难,且相关成本相当可观。
其次,大型语言模型的应用往往依赖于构建适当的提示(prompt)来引导模型生成所需的文本。这种方法通过将信息嵌入到提示中,从而引导模型按照特定的方向生成文本。然而,这种基于提示的方法可能使模型过于依赖先前见过的模式,而无法真正理解问题的本质。

知识库问答(KBQA)
Knowledge Base Question Answering,一种早期的对话系统方法,旨在利用结构化的知识库进行自然语言问题的回答。这种方法基于一个存储在图数据库中的知识库,通常以三元组的形式表示为 <主题,关系,对象> ,其中每个三元组都附带相关的属性信息。
有两种主流方法用于处理自然语言问题
- 主题识别与实体链接:该方法从识别问题中的主题开始,将其链接到知识库中的实体(称为主题实体)。通过主题实体,系统能够在知识库中查找相关的信息并回答问题。
- 多跳查询:基于图数据库的优势,KBQA能够进行多跳查询,即通过多个关系跨越多个实体来获取更深层次的信息。这种灵活性使得系统能够更全面地理解和回答用户的复杂问题。
微调模型(SFP)
能够通过有监督学习的方式,通过对任务相关数据的反复迭代调整,使得模型更好地适应特定领域的知识和要求。
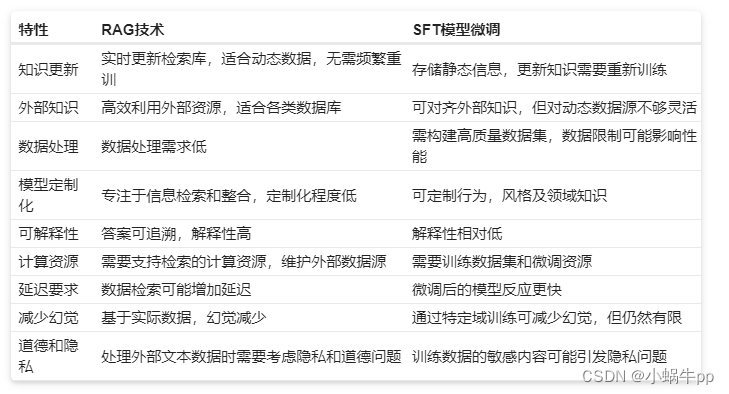
RAG能够从外部知识库中检索最新、准确的信息,从而提高了答案的质量和时效性。其优势在于可以利用最新的外部信息,从而更好地适应当前事件和知识。

检索增强生成(RAG)
RAG技术结合了大型语言模型的强大生成能力和检索系统的精确性。它允许模型在生成文本时,从外部知识库中检索相关信息,从而提高生成内容的准确性、相关性和时效性。这种方法不仅增强了模型的回答能力,还减少了生成错误信息的风险。

RAG被构建为一个应用于大型语言模型的框架,其目标是通过结合 大模型的生成能力 和 外部知识库的检索机制,提升自然语言处理任务的效果。
比较
- 与传统的知识库问答(KBQA)相比,RAG技术在知识检索方面更加灵活,不仅能够从结构化的知识库中检索信息,还能够应对非结构化的自然语言文本。
- RAG技术通过检索外部知识库,避免了幻觉问题的困扰。相较于单纯依赖大型语言模型对海量文本数据的学习,RAG允许模型在生成文本时从事实丰富的外部知识库中检索相关信息。
##2. RAG实现流程

在RAG技术流程中,涉及多个关键模块,每个模块承担着特定的任务,协同工作以实现准确的知识检索和生成自然语言回答。 - 意图理解 意图理解模块负责准确把握用户提出的问题,确定用户的意图和主题。处理用户提问的模糊性和不规范性,为后续流程提供清晰的任务目标。
- 文档解析 文档解析模块用于处理来自不同来源的文档,包括PDF、PPT、Neo4j等格式。该模块负责将文档内容转化为可处理的结构化形式,为知识检索提供合适的输入。
- 文档索引 文档索引模块将解析后的文档分割成短的Chunk,并构建向量索引。或通过全文索引进行文本检索,使得系统能够更快速地找到与用户问题相关的文档片段。
- 向量嵌入 向量嵌入模块负责将文档索引中的内容映射为向量表示,以便后续的相似度计算。这有助于模型更好地理解文档之间的关系,提高知识检索的准确性。
- 知识检索 知识检索模块根据用户提问和向量嵌入计算的相似度检索或文本检索打分。这一步骤需要解决问题和文档之间的语义关联,确保检索的准确性。
- 重排序 重排序模块在知识检索后对文档库进行重排序,以避免“Lost in the Middle”现象,确保最相关的文档片段在前面。
- 大模型回答 大模型回答模块利用大型语言模型生成最终的回答。该模块结合检索到的上下文,以生成连贯、准确的文本回答。
- 其他功能模块 可根据具体应用需求引入其他功能模块,如查询搜索引擎、融合多个回答等。模块化设计使得系统更加灵活,能够根据不同场景选择合适的功能模块组合。
2.GLM API使用
1.引入key
智谱:`7bf001734ef2fd7f7a55bf51dadd7cbb.BMAsoKRDFTmTEPwj`
import time
import jwt
import requests
# 实际KEY,过期时间
def generate_token(apikey: str, exp_seconds: int):
try:
id, secret = apikey.split(".")
except Exception as e:
raise Exception("invalid apikey", e)
payload = {
"api_key": id,
"exp": int(round(time.time() * 1000)) + exp_seconds * 1000,
"timestamp": int(round(time.time() * 1000)),
}
return jwt.encode(
payload,
secret,
algorithm="HS256",
headers={"alg": "HS256", "sign_type": "SIGN"},
)
url = "https://open.bigmodel.cn/api/paas/v4/chat/completions"
headers = {
'Content-Type': 'application/json',
'Authorization': generate_token("填入Key", 1000)
}
data = {
"model": "glm-3-turbo",
"messages": [{"role": "user", "content": """你好"""}]
}
response = requests.post(url, headers=headers, json=data)
print("Status Code", response.status_code)
print("JSON Response ", response.json())
2.读取数据
链接:https://pan.baidu.com/s/1j_2QVRGwXlrruMFQuTjgbw?pwd=ysz2 提取码:ysz2
import json
import pdfplumber
questions = json.load(open("questions.json"))
print(questions[0])
pdf = pdfplumber.open("初赛训练数据集.pdf")
len(pdf.pages) # 页数
pdf.pages[0].extract_text() # 读取第一页内容
#读取所有页内容
pdf_content = []
for page_idx in range(len(pdf.pages)):
pdf_content.append({
'page': 'page_' + str(page_idx + 1),
'content': pdf.pages[page_idx].extract_text()
})
3.文本索引与答案检索
文本检索流程,其核心是构建倒排索引以实现高效的文本检索:
- 步骤1(文本预处理):对原始文本进行清理和规范化(去除停用词、标点符号等噪声)并将文本统一转为小写。接着,采用词干化或词形还原等技术,将单词转换为基本形式,以减少词汇的多样性,为后续建立索引做准备。
- 步骤2(文本索引):构建倒排索引是文本检索的关键步骤。通过对文档集合进行分词,得到每个文档的词项列表,并为每个词项构建倒排列表,记录包含该词项的文档及其位置信息。这种结构使得在查询时能够快速找到包含查询词的文档,为文本检索奠定基础。
- 步骤3(文本检索):接下来是查询处理阶段,用户查询经过预处理后,与建立的倒排索引进行匹配。计算查询中每个词项的权重,并利用检索算法(如TFIDF或BM25)对文档进行排序,将相关性较高的文档排在前面。
文本检索和语义检索的区别和联系的表格形式:

TFIDF(Term Frequency-Inverse Document Frequency)
是一种用于信息检索和文本挖掘的常用权重计算方法,旨在衡量一个词项对于一个文档集合中某个文档的重要性。该方法结合了两个方面的信息:
- 词项在文档中的频率(TF)
- 在整个文档集合中的逆文档频率(IDF)。
BM25Okapi
是BM25算法的一种变体,它在信息检索中用于评估文档与查询之间的相关性。以下是BM25Okapi的原理和打分方式的概述:
BM25Okapi的主要参数:
k 1 k_1 k1:控制词项频率对分数的影响,通常设置为1.5。
b b b:控制文档长度对分数的影响,通常设置为0.75。
e p s i l o n epsilon epsilon:用于防止逆文档频率(IDF)为负值的情况,通常设置为0.25。
打分的计算过程:
BM25Okapi的打分过程基于以下三个因素:
词项在文档中的频率(TF)
文档的长度(doc_len)
逆文档频率(IDF)
4.文本编码模型
目前,大多数语义检索系统采用预训练模型进行文本编码,其中最为常见的是
- 基于BERT(Bidirectional Encoder Representations from Transformers)的模型,
- 使用GPT(Generative Pre-trained Transformer)
5.多路召回逻辑
是在文本检索中常用的一种策略,其目的是通过多个召回路径(或方法)综合获取候选文档,以提高检索的全面性和准确性。单一的召回方法可能由于模型特性或数据特点而存在局限性,多路召回逻辑引入了多个召回路径,每个路径采用不同的召回方法。
------实现方法1:将BM25的检索结果 和 语义检索结果 按照排名进行加权
------实现方法2:按照段落、句子、页不同的角度进行语义编码进行检索,综合得到检索结果。















 428
428











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









