









实验二 递归下降语法分析器的构建
一、实验要求
运用递归下降法,针对给定的上下文无关文法,给出实验方案。预估实验中可能出现的问题。
二、实验方案
(一)实验规划步骤
- 1.分析文法,消除左递归,将给定文法转换为EBNF文法范式避免重复;
- 2.计算First集合和Follow集合;
- 3.根据得出的LL(1)来进行函数(如lexp()、atom()、list()等)的编程;
- 4.根据递归下降语法分析的理论设计相应代码(具体要求返回输入串的语法树);
- 5.上机调试,修复bug并完善实验设计;
- 6.调试完成,完成实验。
(二)实验输入输出设计
1.输入设计:
严格来说,需要输入待分析的字符串,经过词法分析将其转化为Token序列,再经过本算法得到分析树。但是本次实验的输入较为简单,且侧重点在于掌握递归下降法,故我仅对输入串进行了简单的判断,生成Token序列。
根据实验中两个题目的要求,对应设计两个输入字符串,分别为:(a(b(2))(c))和(((a+9.9)*(2+c))+1)*6。进行简单的字母、数字、括号(第二个题目还包括了操作符+和×)判断,形成一个Token序列,字母、数字、括号、操作符有其对应的标识符号。
2.输出设计:
输出解析得到的语法分析树。
为了方便起见,我的语法树将采用缩进格式显示,即深度为1的节点不缩进,深度为2的节点缩进2个空格,深度为3的节点缩进3个空格,以此类推。
并且,为了完善题目代码和提高交互效果,我的输出还额外增设了Error判断,能够指出输入错误字符串的问题以及其出错的具体位置。
三、预估问题
1.实验代码设计出现bug,即关于树的数据结构代码不够完善存在问题。
2.设计的LL(1)分析表存在细节错误,导致Token解析失败,无法输出完整的语法分析树。
为了避免以上问题的发生,需要我在预习实验阶段完成对代码的框架构思,并检查基础的LL(1)分析表是否正确。同时我需要在编码时,加入错误提示代码,将出错的结点进行输出以便同时完成对预计问题1、2的修正。
理论基础(评价依据 理论知识非常清楚)
(一)消除左递归
1. 简单直接左递归

2. 普遍的直接左递归

3. 一般的左递归

(二)First集合

(三)Follow集合

(四)LL (1)文法

(五)LL(1)分析表的构造方法

四、内容和步骤
1、针对4.8习题输入和输出的设计及代码
(一)文法

(二)题目要求
- 1.消除左递归;
- 2.为得出的文法的非终结符构造First集合和Follow集合;
- 3.说明所得的文法是LL(1)文法;
- 4.为所得的文法构造LL(1)分析表;
- 5.假设有输入串:(a(b(2))(c)),请写出相对应的LL(1)分析程序的动作。
-
2、针对现场给定语法的设计和处理
-
【考虑简单算术表达式文法G:
E→E + T | T
T→T * F | F
F→(E) | id
试设计递归下降分析程序,以对任意输入的符号串进行语法分析。】
(一)文法
E→E + T | T
T→T * F | F
F→(E) | id
(二)题目要求
考虑简单算术表达式文法G:试设计递归下降分析程序,以对任意输入的符号串进行语法分析。
-
-
3. 实验具体步骤
(1)针对4.8习题的实验步骤:
-
① 步骤一:消除左递归(主要针对第四条文法,其存在左递归)
-
lexp→atom | list
atom→number | identifier
list → (lexp-seq)
lexp-seq → lexp lexp-seq’
lexp-seq’ → lexp lexp-seq’|ε
-
② 步骤二:计算First集合
-
表1 根据题给文法计算First集合
文法规则
第一遍
第二遍
lexp → atom
First(lexp) = { number, identifier }
lexp → list
First(lexp) = { number, identifier, ( }
atom → number
First(atom)={number}
atom → identifier
First(atom)={number,identifier}
list → (lexp-seq)
First(list) = { ( }
lexp-seq→lexp lexp-seq’
First(lexp-seq) = { number, identifier, ( }
lexp-seq’→lexp lexp-seq’
First(lexp-seq’)= { number, identifier, ( ,ε}
lexp-seq’→ε
First(lexp-seq’) = {ε}
First(lexp) = { number, identifier, ( }
First(atom) = { number, identifier }
First(list) = { ( }
First(lexp-seq) = { number, identifier, ( }
First(lexp-seq’) = { number, identifier, ( ,ε}
-
③ 步骤三:计算Follow集合
-
表2 根据题给文法计算Follow集合
文法规则
第一遍
第二遍
lexp → atom
Follow(atom)={$, number, identifier, (, ) }
lexp → list
Follow(list)={ $, number, identifier, (, ) }
list → (lexp-seq)
Follow(lexp-seq) = { ) }
lexp-seq→lexp lexp-seq’
Follow(lexp)={$, number, identifier, (}
Follow(lexp-seq’)={ ) }
Follow(lexp)={ $, number, identifier, (, ) }
lexp-seq’→lexp lexp-seq’
Follow(lexp)={$, number, identifier,( , ) }
Follow(lexp-seq’)={ ) }
Follow(lexp) = { $, number, identifier, (, ) }
Follow(atom) = { $, number, identifier, (, ) }
Follow(list) = { $, number, identifier, (, ) }
Follow(lexp-seq) = { ) }
Follow(lexp-seq’) = { ) }
-
④ 步骤四:构造LL(1)分析表,根据表进行函数编程(详细代码见下)
-
表3 构造LL(1)分析表
M[N,T]
number
identifier
(
)
$
lexp
lexp→atom
lexp→atom
lexp→list
atom
atom→number
atom→identifier
list
list→(lexp-seq)
lexp-seq
lexp-seq→lexp lexp-seq’
lexp-seq→lexp lexp-seq’
lexp-seq→lexp lexp-seq’
lexp-seq’
lexp-seq’→lexp lexp-seq’
lexp-seq’→lexp lexp-seq’
lexp-seq’→lexp lexp-seq’
lexp-seq’→ε
函数代码:void atom()函数、void list()函数、void lexp()函数、void lexp_seq1()函数
⑤ 步骤五:完善整体递归下降分析相应代码(包括错误处理、匹配文法、主函数设计)
void error(char ch)
char judge(char ch)
void match(char option, char ch)
int main()
{
pos = 0; //初始化字符起始位置0
nbsp = 0;
flag = true;
cin >> str; //输入示例
str += '$'; //自加终止符
lexp_seq1(); //入口函数
return 0;
}⑥ 步骤六:上机调试修复BUG并完善实验设计
-
(2)针对现场给定文法的实验步骤:
-
① 步骤一:将上述文法G转换为对应的EBNF
-
E→T{ +T }
T→F{ *F }
F→(E) | id
-
② 步骤二:根据以上文法计算出以下First集合
-
First(E) = { (, id }
First(T) = { (, id }
First(F) = { (, id }
-
③ 步骤三:根据以上文法计算出一下Follow集合
-
Follow(E) = { $, ) }
Follow(T) = { +, $, ) }
Follow(F) = { *, +, $, ) }
-
④ 步骤四:根据得出的LL(1)来进行函数编程(详细代码见下)
-
表4 构造LL(1)分析表
M[N,T]
id
(
)
+
*
$
E
E→T{ +T }
E→T{ +T }
T
T→F{ *F }
T→F{ *F }
F
F→id
F→(E)
public void E() // E->T{+T}
public void T() // T->F{*F}
public void F() // F->(E)|id
⑤ 步骤五:完善整体递归下降分析相应代码(包括错误处理、获取单个字符、检测语法检验结果正确性、判断表达式是否为空、主函数设计)
-
public void Error(string reason) //错误处理 public void GetElement() //获取单个字符 public bool IsError() //判断语法检验结果是否正确 public bool IsEmpty() //判断表达式是否为空 static void Main(string[] args){ string str = Console.ReadLine(); str += '$'; Parse parser = new Parse(); parser.Expression = str; parser.GetElement(); //获取第一个字符 if (parser.IsEmpty()){ Console.WriteLine("表达式为空!"); } else { //表达式不为空的情况 parser.E(); //文法分析 if (!parser.IsError()){ //正确 Console.WriteLine("输入的表达式正确!"); } else{ Console.WriteLine("输入的表达式错误!"); Console.WriteLine("错误原因:{0}", parser.ErrReason); Console.WriteLine("错误位置:{0}", parser.ErrPos); } } }⑥ 步骤六:上机调试修复BUG并完善实验设计
-
五、代码
-
(1)针对4.8习题的代码(以C++语言实现)
-
#include<iostream> #include<string> using namespace std; string str; //字符串 int pos; //定义位置 bool flag; //判断符 void lExp_seq1(); int nbsp; int main(){ pos = 0; //初始化字符起始位置0 nbsp = 0; flag = true; cin >> str; //输入示例 str += '$'; //自加终止符 lExp_seq1(); //入口函数 return 0; } //字母、数字判断 char judge(char ch){ if(ch >= '0' && ch <= '9'){ return 'n'; //n代表number }else if((ch >= 'A' && ch <= 'Z') || (ch >= 'a' && ch <= 'z')){ return 'a'; //a代表字母 } else{ return ch; } } //错误处理 void error(char ch){ if(flag){ cout << endl << "error:" << ch << ",position:" << pos; flag = false; //终止进行 } } //匹配节点成功 void match(char option, char ch){ if(option == 'r'){ --nbsp; } for(int i = 0; i < nbsp; i++){ cout << " "; } if(option == 'l'){ ++nbsp; } if(option == 'l'){ cout << "LeftBracket:" << ch << endl; }else if(option == 'r'){ cout << "RightBracket:" << ch << endl; }else if(option == 'n'){ cout << "Number:" << ch << endl; }else if(option == 'a'){ cout << "Letter:" << ch << endl; } pos++; } void atom(){ if(!flag) return; //跳出递归 char ch = judge(str[pos]); //判断示例字符串的类型 if(ch == 'n') match('n', str[pos]); //数字 else if(ch=='a') match('a', str[pos]); //字母 else if(ch=='$') cout << "accept END" << endl; //终止$ else error(ch); } void list(){ if(!flag) return; //跳出递归 match('l', '('); //匹配左括号 lExp_seq1(); //出现左括号的情况下重新进入入口函数继续递归 if(str[pos] == ')') match('r',')'); else if(str[pos] == '$'){ return; } else{ error(str[pos]); } } //进入atom和list两个终止符 void lExp(){ if(!flag) return; char ch= judge(str[pos]); if(ch == 'n' || ch == 'a'){ atom(); //atom判断 } else if(ch == '('){ list(); //list判断 } else if(ch == '$' ) cout << "accept END" << endl; else error(ch); } void lExp_seq(){ } // 入口函数lExp-seq' void lExp_seq1(){ if(!flag) return; char ch = judge(str[pos]); if(ch == 'n' || ch == 'a' || ch == '(') { lExp(); lExp_seq1(); } else if(ch == ')') match('r', ')'); else if(ch == '$') cout << "accept END" << endl; else error(ch); }(2)针对现场给定语法的代码(以C#语言实现)
-
using System; namespace ETF { class Program { class Parse { char element; //表达式字符 int pos = 0; //记录获取位置 bool flag = false; //false正确 ,true错误表达 String expression; //字符串表达式 public String Expression //表达式字符串属性 { get { return expression; } set { expression = value; } } String errReason; //错误原因 public String ErrReason //错误属性 { get { return errReason; } } int errPos; //错误位置 public int ErrPos //错误位置属性 { get { return errPos; } } public void GetElement() //获取单个字符 { element = expression.ToCharArray()[pos]; if (element != '$') { pos++; } } public void E() // E->T{+T} { T(); while (element == '+') { Console.WriteLine("获得操作符:{0}", element); GetElement(); T(); } } public void T() // T->F{*F} { F(); while (element == '*') { Console.WriteLine("获得操作符:{0}", element); GetElement(); F(); } } public void F() // F->(E)|id { if (element == '(') //左括号情况 { Console.WriteLine("获得左括号:{0}", element); GetElement(); E(); if (element == ')') // 判断完左括号后要判断是否存在右括号 { Console.WriteLine("获得右括号:{0}", element); GetElement(); } else { Error("缺少右括号)"); } } else if (element >= '0' && element <= '9') //数字情况number { int f = 0; //判断小数点个数 for (; (element >= '0' && element <= '9') || element == '.';) { if (element >= '0' && element <= '9') { Console.WriteLine("获得数字:{0}", element); GetElement(); } if (element == '.') { Console.WriteLine("获得小数点:{0}", element); GetElement(); f++; } if (f >= 2) { Error("小数点过多(大于2)"); return; } if (element >= 'a' && element <= 'z') { Error("运算数字后面不能带字母"); return; } if (element == '(') { Error("运算数字后面不能直接带上左括号"); return; } } } else if (element >= 'a' && element <= 'z') // 字母情况 { for (; (element >= 'a' && element <= 'z');) { Console.WriteLine("获得字母:{0}", element); GetElement(); } if (element == '(') { Error("标识符后面不能直接带左括号"); } } else { Error("缺少运算数!运算符重复"); } } public void Error(string reason) //错误处理 { if (flag == false) { flag = true; errReason = reason; errPos = pos; } } public bool IsError() //判断语法检验结果是否正确 { return flag; } public bool IsEmpty() //判断表达式是否为空 { return expression.ToCharArray()[0] == '$'; } } static void Main(string[] args) { string str = Console.ReadLine(); str += '$'; Parse parser = new Parse(); parser.Expression = str; parser.GetElement(); //获取第一个字符 if (parser.IsEmpty()) { Console.WriteLine("表达式为空!"); } else //表达式不为空的情况 { parser.E(); //文法分析 if (!parser.IsError()) //正确 { Console.WriteLine("输入的表达式正确!"); } else { Console.WriteLine("输入的表达式错误!"); Console.WriteLine("错误原因:{0}", parser.ErrReason); Console.WriteLine("错误位置:{0}", parser.ErrPos); } } } } }
六、实验结果
(1)针对4.8习题的代码
-
给定输入串 (a(b(2))(c)) :
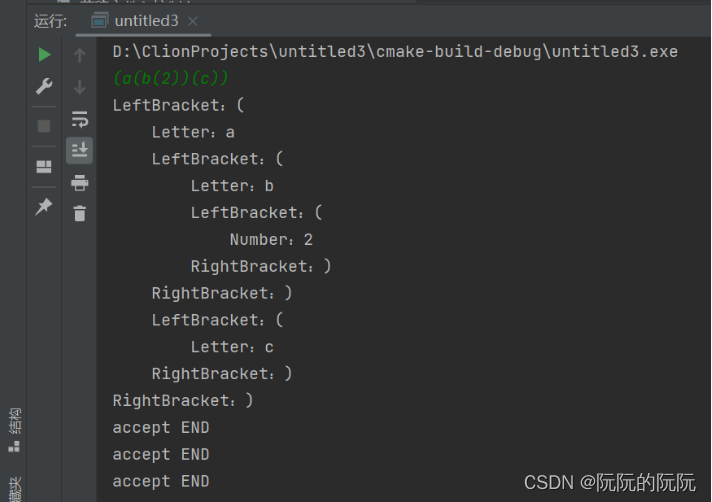
对于字母错误的输入串进行解析判断:
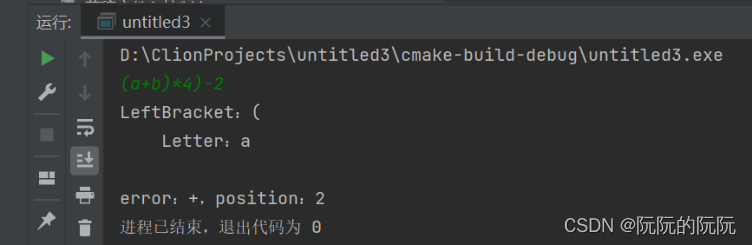
对于括号输入错误进行解析判断:
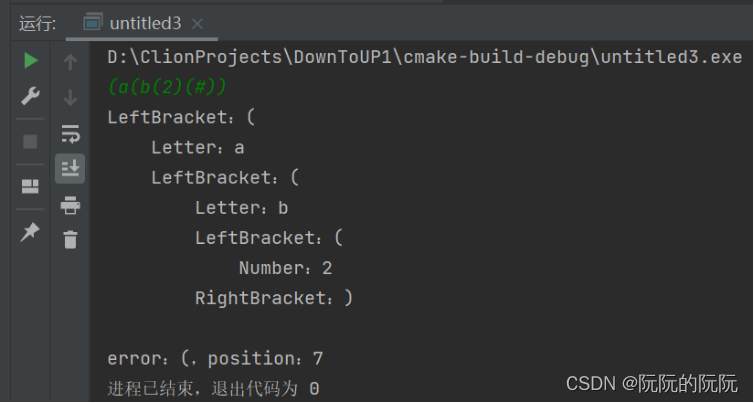
(2)针对4.8习题的代码
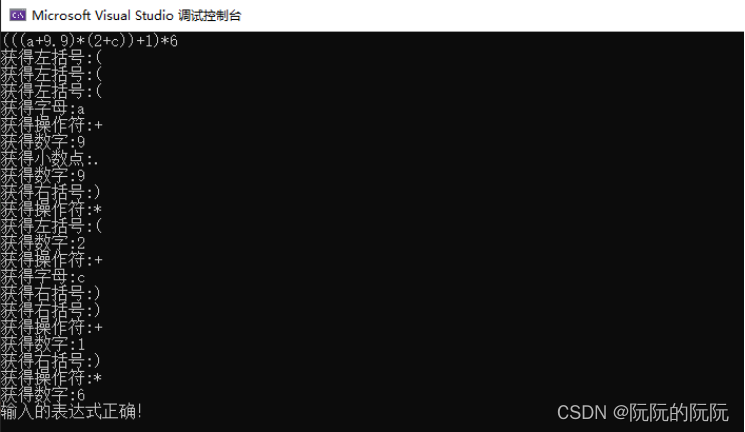
给定输入串:(((a+9.9)*(2+c))+1)*6:
对于给定输入串缺少右括号进行解析判断:
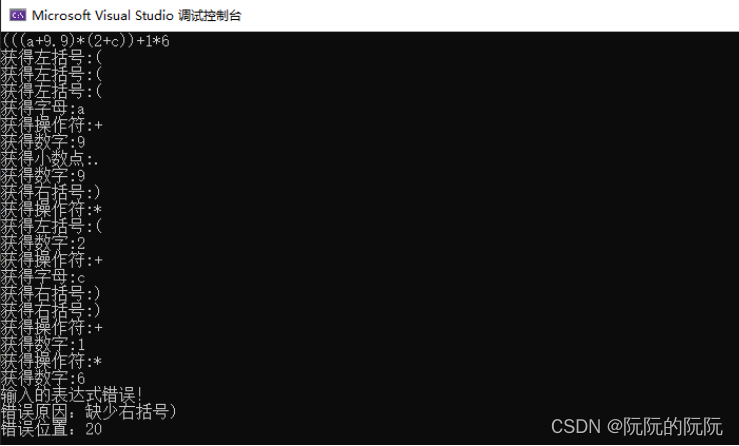
对于给定输入串小数点错误进行解析判断:

对于给定输入串不区分字母和数字进行解析判断:

对于给定输入串中数字与括号之间缺少运算符的判断:
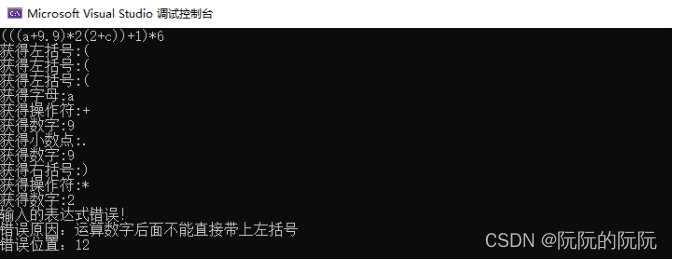
对于给定输入串中字母与括号之间缺少运算符的判断:

对于给定输入串中运算符重复的解析判断:
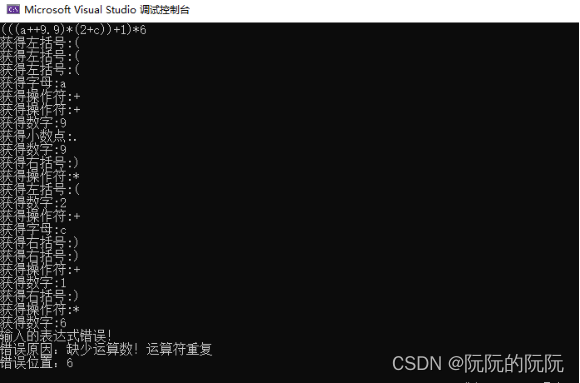
七、实验结论
(1)实验结论
对于4.8题目给定的文法:由于其存在二义性,故我首先对其进行了消除左递归,而后计算First集合与Follow集合,再根据这两个集合设计编写了相应的函数如lexp()、atom()、list()等,之后完善了整体代码,加入了错误Error()函数判断等。在命令行窗口中,输入我们指定的字符串进行文法分析,将字母、数字、$作为终结符;对应地设计了缩进函数,可以得到其对应地的语法树,对于给定输入串正确解析所示。同时为了完善设计,在实验结果测试中,对两种错误情况也做了测试,分别是输入错误的终结符或者是输入错误括号,实验结果都能正确显示错误原因并给出错误位置,如对于字母错误的输入串进行解析判断、对于括号输入错误进行解析判断所示。
对于现场给定的普通文法G,首先进行EBNF范式转换,而后计算First集合与Follow集合,设计出对应的E()、T()、F()函数,内部进行while循环递归下降分析。将输入字符串的数字、运算符、字母、$作为终结符,可以简单得到语法分析结果。如图 5对于给定输入串正确解析所示,同时为了完善实验设计,针对多种Error情况,我也进行了一定的分支判断,如输入串中缺少右括号、数字中小数点过多、字母和数字混合、字母或者数字与括号之间缺少操作符连接、操作符重复出现的判断。
最终两个实验结果都完美呈现,成功完成了实验,并且符合实验要求。
(2)分析和总结
1)对输入设计的结论
两个题目的输入分别是:(a(b(2))(c))和(((a+9.9)*(2+c))+1)*6。其中4.8题目直接由题目指定,后者是我根据代码设计自行给定的能够测试多种情况的字符串,包括了括号、小数点、操作符、数字和字母等。
2)对输出设计的结论
输出在正确情况下是返回带有缩进或者一定提示的语法树,在错误测试情况下输出的是出现错误之前的部分语法树,以及对应的错误原因和错误位置。
3)对递归下降法的算法的结论
对于递归下降算法,定义语法分析程序时,每一个非终结符都被定义为一个对象方法或者函数过程,在内部通过递归实现。最终生成的语法树的每一个子树都是以根节点的非终结符所推导出来的短语,如由exp到1+1。对于每一个非终结符我们都可以去构造函数来匹配对应树的叶子节点,如题4.8中,根据左括号设计了list()函数匹配。
这样构造出来的语法树可以看到,在选择一个语法规则的时候进行匹配,如果遇到终结符可以直接匹配上,遇到的是非终结符则还需要调用对应非终结符的对象方法或者函数过程进行继续递归向下分析,直至遇到终结符。
(3)对预估问题的结论
没有出现预估问题的错误情况,说明First集合、Follow集合、对应函数编写都正确。

















 1875
1875











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











