







 研究者提出CM-BERT,通过融合文本和音频模态的交互,改进BERT模型进行情感分析。实验结果在CMU-MOSI和CMU-MOSEI数据集上显示,CM-BERT显著优于纯文本BERT,且掩蔽多模态注意力机制有效调整词权重。
研究者提出CM-BERT,通过融合文本和音频模态的交互,改进BERT模型进行情感分析。实验结果在CMU-MOSI和CMU-MOSEI数据集上显示,CM-BERT显著优于纯文本BERT,且掩蔽多模态注意力机制有效调整词权重。
论文地址
代码地址
https://github.com/thuiar/Cross-Modal-BERT https://github.com/thuiar/Cross-Modal-BERT
https://github.com/thuiar/Cross-Modal-BERT
摘要
多模态情感分析是一个新兴的研究领域,旨在使机器能够识别,解释和表达情感。通过跨模态交互,可以更全面地获得说话人的情感特征。Bidirectional Encoder Representations from Transformers(BERT)是一种高效的预训练语言表示模型。微调它已经在11个自然语言处理任务(如问答和自然语言推理)上获得了新的最先进的结果。然而,以往的BERT算法大多是基于文本数据进行微调,如何通过引入多模态信息来学习更好的表示仍然值得探索。在本文中,我们提出了跨模态BERT(CM-BERT),它依赖于文本和音频模态的交互来微调预训练的BERT模型。作为CM-BERT的核心单元,掩蔽多模态注意力通过结合文本和音频模态信息来动态调整词的权重。我们在公共多模态情感分析数据集CMU-MOSI和CMU-MOSEI上评估了我们的方法。实验结果表明,与以前的基线和BERT的纯文本微调相比,它在所有指标上都有显着提高。此外,我们可视化掩蔽多模态注意,并证明它可以合理地调整权重的话,通过引入音频模态信息。
动机
1 Bert作为有效的预训练语言模型,微调预训练Bert策略常常是基于文本模态设计的,如何将其从单模态扩展到多模态并得到更好的表示?
成果
1 作者提出了跨模态Bert(CM-BERT),是一种引入了音频模态信息来帮助文本模态微调Bert的模型
2 设计了新的掩蔽多模态注意,通过文本和音频模态之间的交互来动态调整词的权重
方法
模态数据
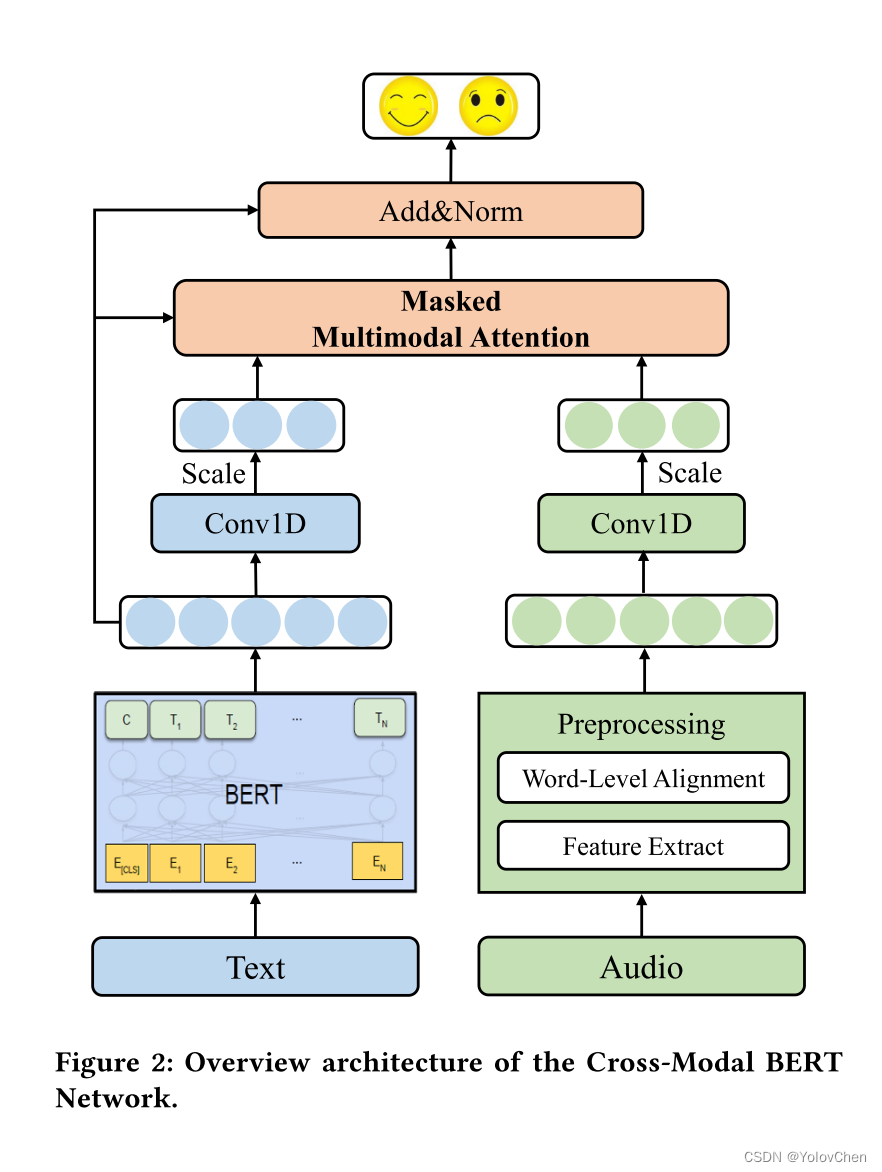
文本序列 T = [T1,T2,T3,...,Tn]. -----Bert------> Xt = [ E[cls], E1,E2,...,En]
音频序列(已单词级与文本特征对齐) Xa = [ A[cls], A1,A2,...,An] 其中 A[cls]是填充的零向量
Xt的维度大于Xa 防止点积时维度过大,分别进行特征缩放
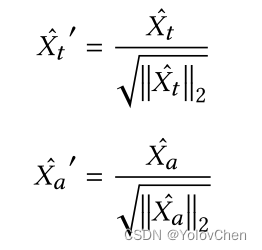
模型结构
过程
1、获得 Xt‘ 和 Xa’
2、输入到掩蔽多模态注意力机制中。这个机制能够通过结合不同模态中单词的表现来调整单词的权重,使得不同模态的信息能够充分交互,从而提取更加丰富和准确的特征表示。这一步的输出是XAtt
3、通过线性层和归一化层,得到最后一个线性层的输出 Yl = [L[CLS],L1,L2,...,Ln],以第一个token:L[cls](课代表) 得到分类结果 # 这里的课代表可以理解为课代表收了后面所有token的作业后综合起来
掩蔽多模态注意结构:
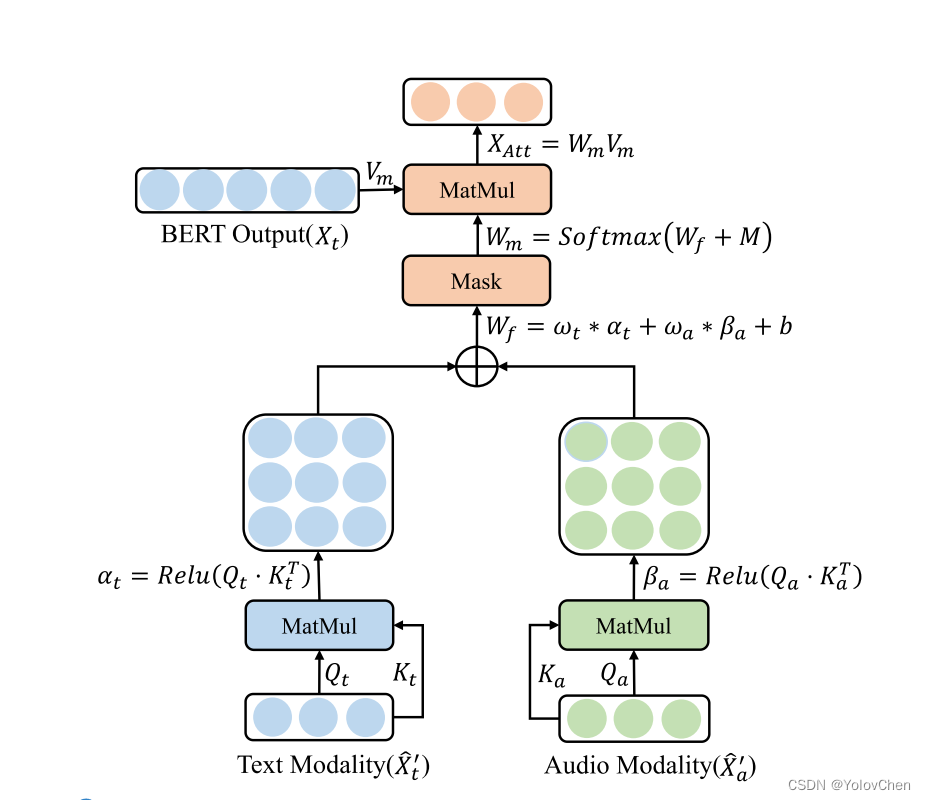
其中 Vm是Bert最后一个编码器层的输出Xt
为了减少填充序列的影响,0代表toke的实际位置,−∞表示填充位置,
这样做的目的是在应用softmax函数计算注意力得分时,填充位置的得分会变为0。这确保了模型的注意力只会集中在有效的数据上,而不是无意义的填充部分。
实验
数据集
CMU-MOSI 和 CMU-MOSEI
特征提取
音频:COVAREP
单词级对齐特征:P2FA 获取每个单词在音频中的确切开始和结束时间,为了使音频特征序列和文本序列长度保持一致,使用0向量填充
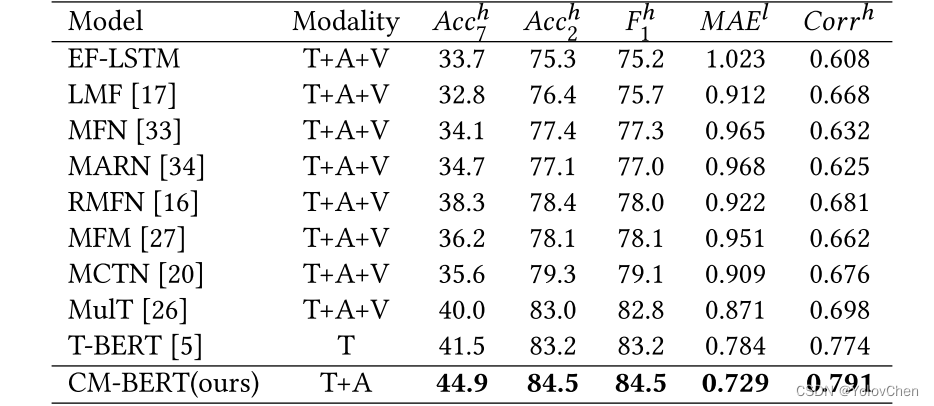
实验结果
选取了5个随机种子,5次运行的平均结果作为最终的实验结果。
注意力可视化:
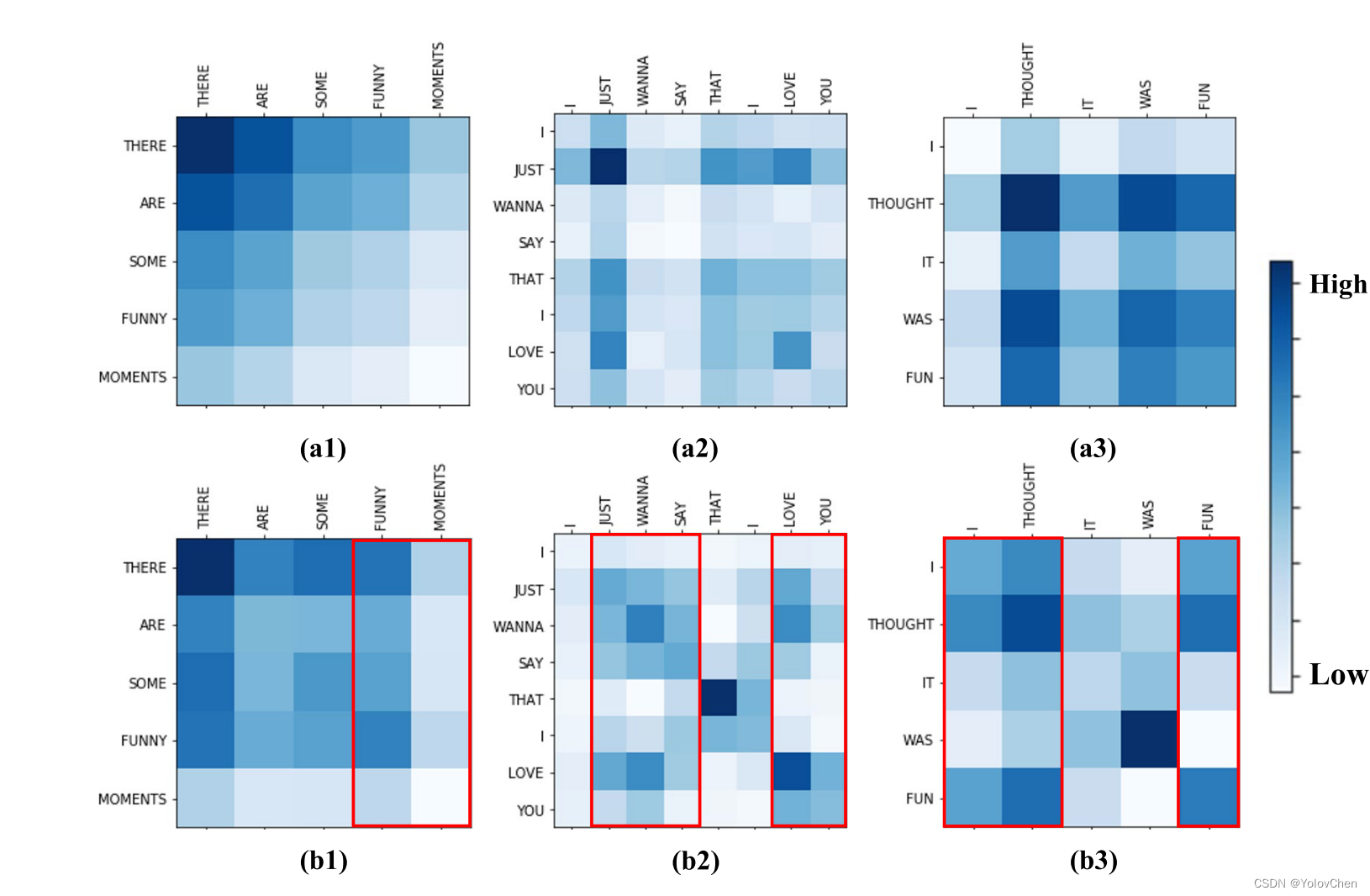
a系列是文本注意力矩阵 b系列是多模态注意力矩阵
"There are some funny monments" 文本注意力矩阵中,are的注意力分数较高,但这没有意义,可以发现,引入音频信息后,are的注意力得分降低了
"I just wanna say tahe i love you" 掩蔽多模态注意力矩阵中 提高了 love you 的权重,降低了just 和 that的权重
从中可以看出掩蔽多模态注意能够合理的调整词的权重。
展望
如何对齐模态?如何用预训练模型从未对齐的多模态数据中学习到更好的表示?
问题
Q1:采用1D卷积的目的?
A1:解决文本和音频特征在维度上时间不一致的问题
Q2:如果Bert先在实验数据集上先预训练一遍,性能是否能够提升?
A2:论文复现和改进敬请期待!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









