






论文地址
https://arxiv.dosf.top/abs/2211.11256![]() https://arxiv.dosf.top/abs/2211.11256
https://arxiv.dosf.top/abs/2211.11256
代码地址
摘要
多模态情感分析(MSA)和会话中的情感识别(ERC)是计算机理解人类行为的关键研究课题。从心理学的角度来看,情绪是在短时间内表达情感或感受,而情绪则是在较长时间内形成和保持的。然而,大多数现有的作品分别研究情感和情绪,并没有充分利用两者背后的互补知识。在本文中,我们提出了一个多模态情感知识共享框架(UniMSE),统一了MSA和ERC任务的功能,标签和模型。我们在句法和语义层面进行模态融合,并在模态和样本之间引入对比学习,以更好地捕捉情感和情绪之间的差异和一致性。在MOSI、MOSEI、MELD和IEMOCAP四个公共基准数据集上的实验结果表明,该方法与现有方法相比具有一致的性能改进.
动机
MSA的目标是预测情感强度或极性,ERC的目标是预测预定义的情感类别。
大多数现有的作品将MSA和ERC视为单独的任务,忽略了情感和情绪之间的相似性和互补性。
将情感和情绪一起分析可以更好地理解人类行为。
贡献
提出了一个多模态情感知识共享框架,统一MSA和ERC(UniMSE)任务。
提取和统一音频和视频特征,并将MSA和ERC标签形式化为通用标签(UL),以统一情感和情绪。
我们通过将声学和视觉信号注入 T5 模型来融合多级文本信息的多模态表示。同时,我们利用模态间对比学习来获得有区别的多模态表示。
据他们所知,他们是第一个以生成方式解决MSA和ERC的
方法
T5 backbone
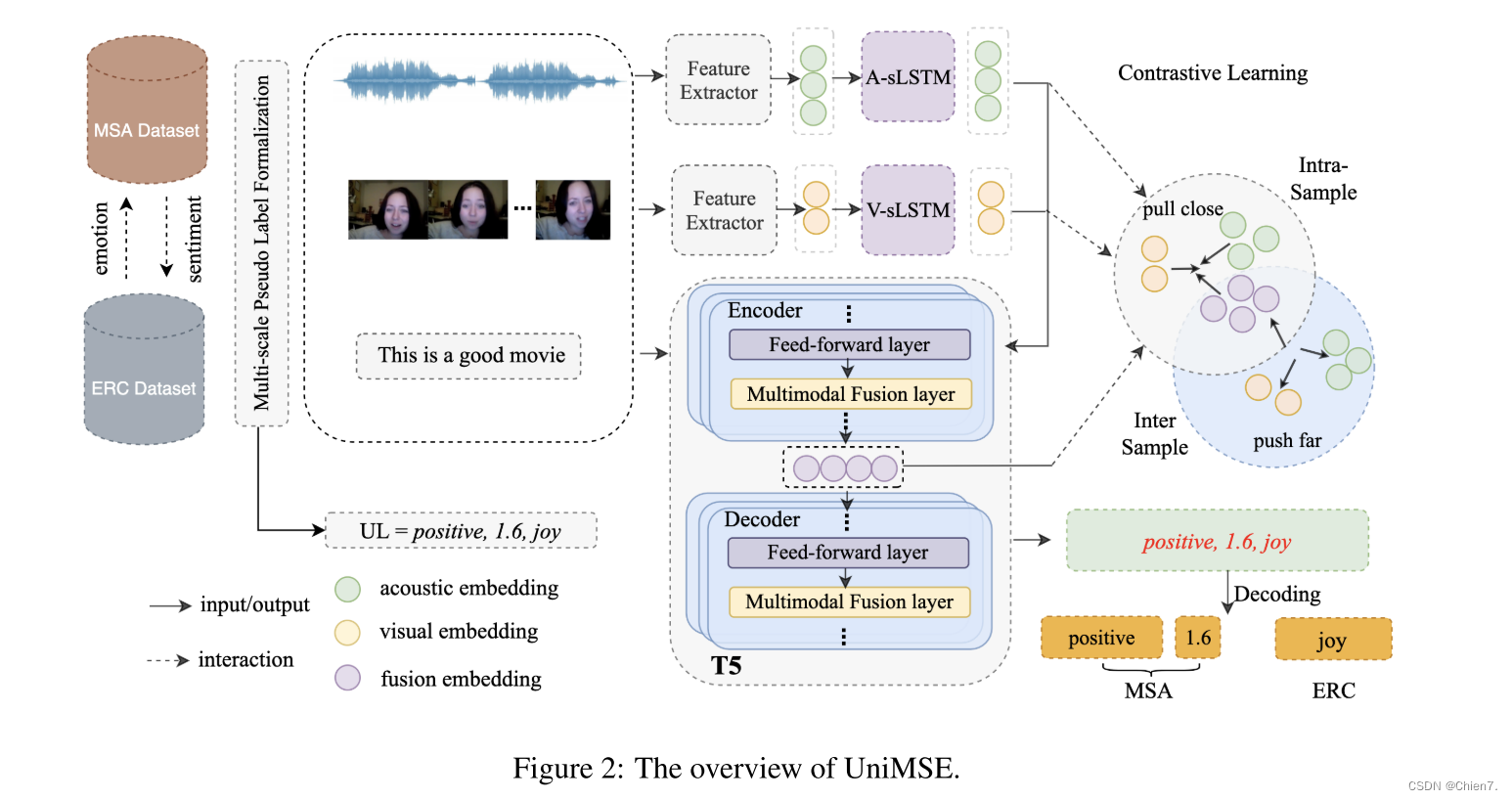
1 将MSA个ERC任务的标签处理为通用标签(UL)
2 提取音频和视频特征,分别输入到两个单独的LSTM中获得利用上下文信息,文本模态使用T5作为编码器来学习序列的上下文信息,而与先前工作不同之处在于,多模态融合层嵌入到了T5之中
3 模态间对比学习来区分样本之间多模态融合表示(对比学习的作用是缩小同一样本模态之间的差距,拉开不同样本的模态表示的距离)
任务形式化
输入形式化:用于处理对话文本和模态特征
标签形式化:将MSA和ERC的标签转换为通用标签来统一MSA和ERC任务
输入形式化
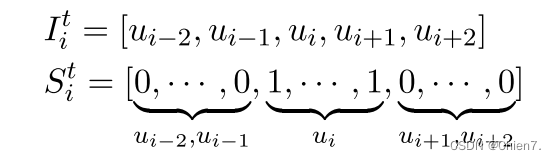
前两轮话语 当前话语ui 后两轮话语 连接 -> 原始文本 St作用来区分话语
通过 librosa 3 将原始声学输入处理为数值序列向量,以提取梅尔频谱图作为音频特征。
标签形式化
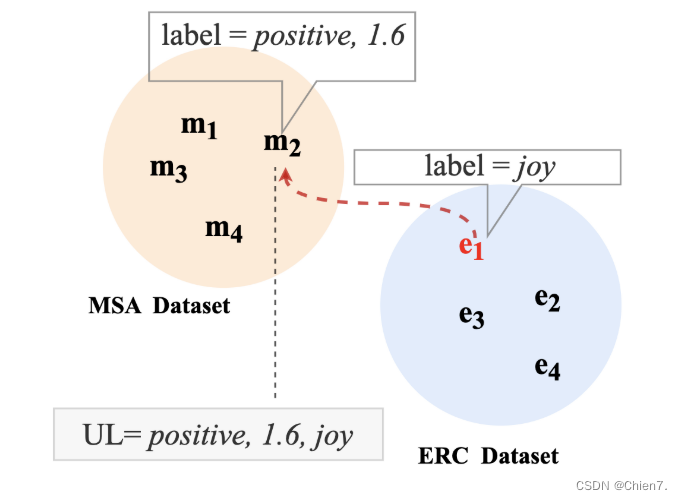
其实就是ERC中每种情绪对应到MSA的情感分数上(根据语义相似度)
之前的工作证明 文本模态比其他模态更具指示性,故采用文本相似度作为样本
预训练模态融合
将多模态融合层嵌入到预训练模型T5,音频和视觉表示可以参与文本编码,与多层次的文本信息融合,由浅Transformer层编码的低级文本语法特征和由深层Transformer层编码的高级文本语义特征与音频和视频特征融合成多模态表示。
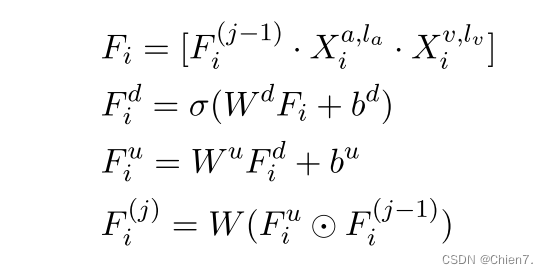
其中![]() 和
和![]() 别代表 Xai和Xvi 最后一次时间步的隐藏状态(Xai和Xvi是音频和视觉数据通过各自LSTM后得到的特征)[
别代表 Xai和Xvi 最后一次时间步的隐藏状态(Xai和Xvi是音频和视觉数据通过各自LSTM后得到的特征)[]表示特征dim的串联操作,
表示元素相加
模态间对比学习
对比学习的原理:在特征空间中,anchor与其正样本应该被拉近,与其负样本之间的距离被拉远
进行模态间对比学习,增强模态之间的交互并放大样本表示融合之间的差异,处理每种模态表示使其长度一致,将声学表示Xai 视觉表示Xvi 和融合表示F(j)通过一个一维卷积
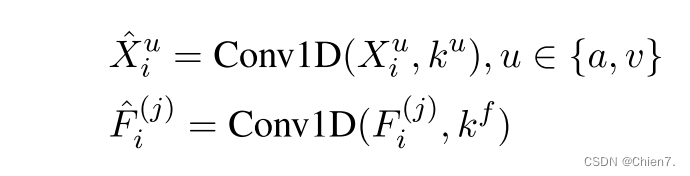
其中Fi(j)是在包含预训练模态融合的j个Transformer层之后得到的,ku是模态u的卷积核大小,kf是融合模态的卷积核大小
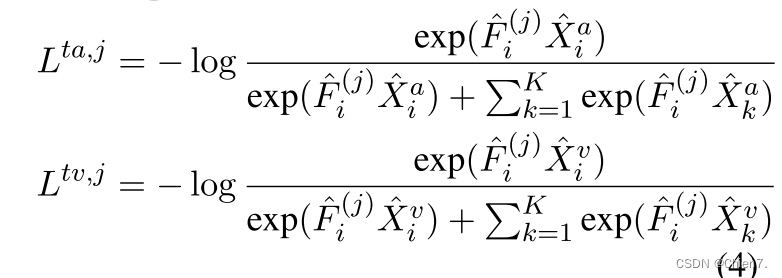
自监督的对比损失公式,每个锚点的随机采样对由两个正对和2k个负对组成(文本音频、文本视觉)j还是代表编码器第j个Transformer层
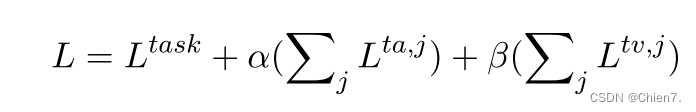
总体损失函数,Ltask表示生成人任务损失
实验
数据集:CMU-MOSI、CMU-MOSEI、IEMOCAP、MELD
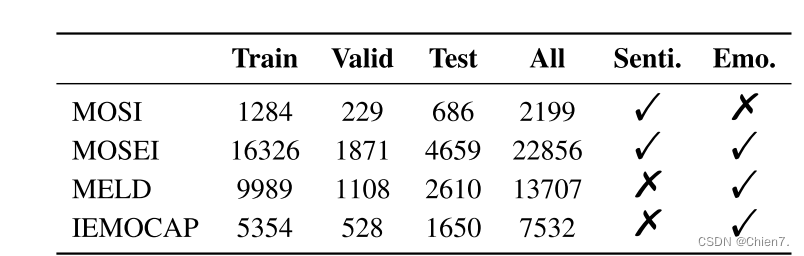
打勾的是对应任务数据集中有标注 叉就是没标注
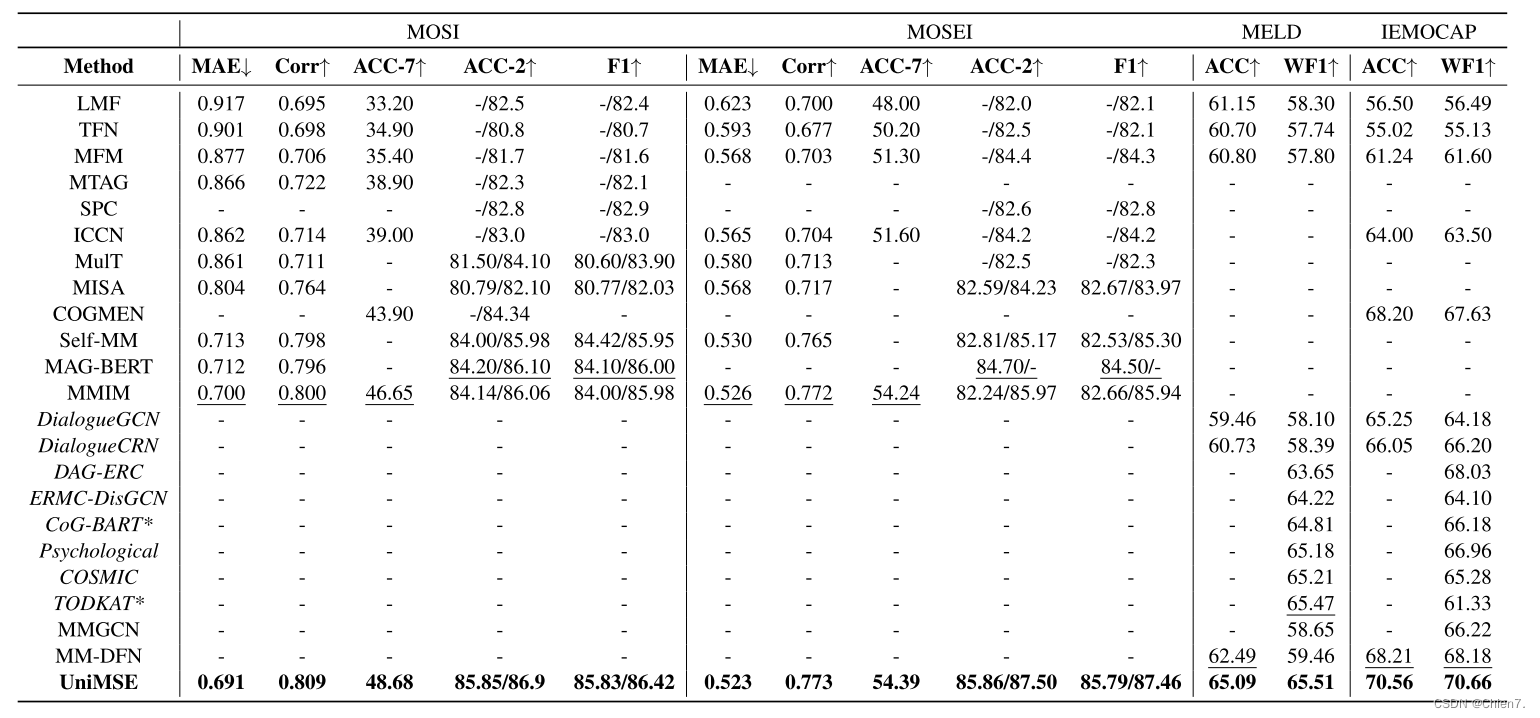
实验结果
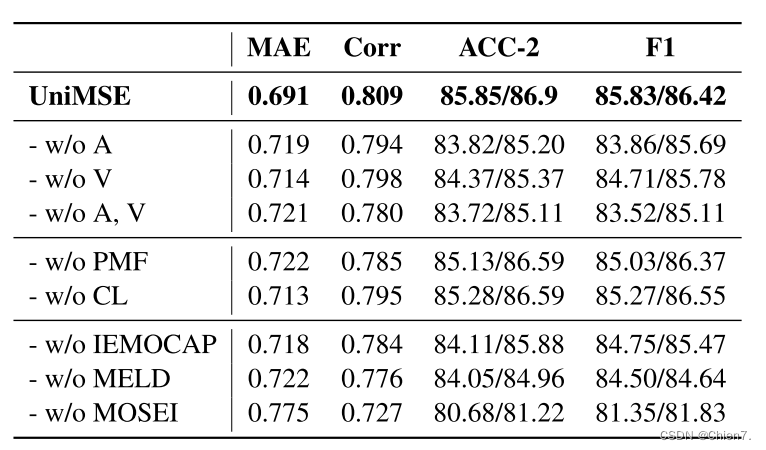
消融实验,去音频、去视觉、去音频和视觉、去预训练模态融合、去对比学习、数据集中去数据
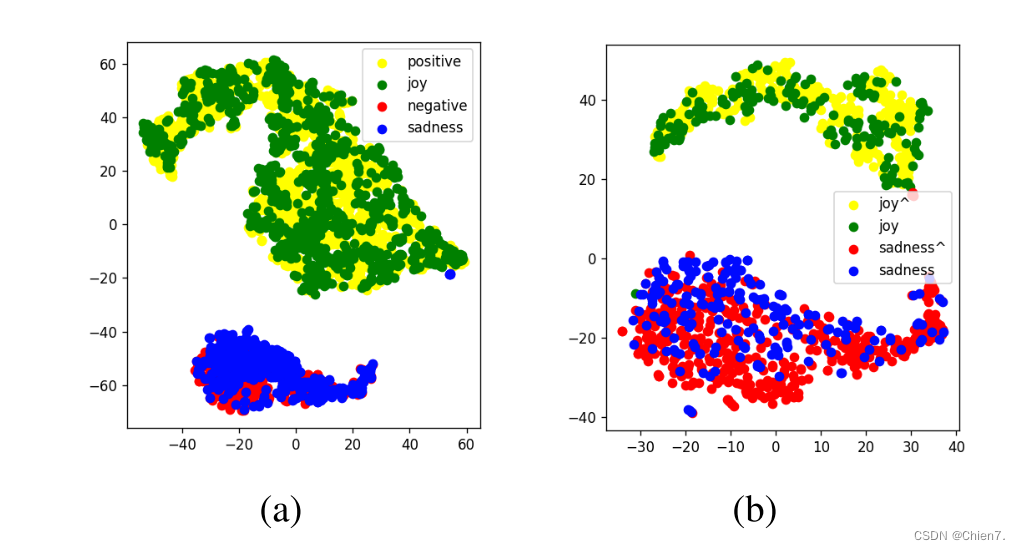
可视化最后一个Transformer层的多模态融合表示,证明嵌入空间中情感和情绪的相关性
实验结果表明,UniMSE在跨样本表示学习上的优越性且证明了情绪和情感之间的互补性,对齐输入特征和输出标签,成为SOTA
展望
通用标签的生成只考虑文本模态,而未考虑听觉和视觉模态
问题
Q1:如果在T5编码器和解码器的每个Transfomer中嵌入一个多模态融合层会更好吗?
A1:这样做会干扰文本序列的编码并且会有更多的参数,可能会导致过拟合。故论文中,使用前几个Transfomer层对文本进行编码,其余的注入视觉和音频模态。















 1162
1162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









