







Java是如何构造出链表的?
在JVM里有栈区和堆区,栈区主要存引用,也就是一个指向实际对象的的地址(类似于指针),而堆区存的才是创建的对象。
public class Course{
Score score;
}
这里的Score就是指向堆的引用。
假如我这样定义?
public class Course{
int val;
Course next;
}
这时候next就指向下一个同为Course的对象了


这里通过栈中的引用(也就是地址)就可以找到val(1),然后val(1)结点又存了指向val(2)的地址,而val(3)又存了指向val(4)的地址,所以就构造出了一个链条访问结构。
在Java中有两种定义链表的方法
- Java规范定义链表:
public class ListNode {
private int val;
private ListNode next;
public int getVal() {
return val;
}
public void setVal(int val) {
this.val = val;
}
public ListNode getNext() {
return next;
}
public void setNext(ListNode next) {
this.next = next;
}
}
- LeetCode中的定义
public class ListNode {
public int val;
public ListNode next;
public ListNode(int x) {
val = x;
next = null;
}
}
链表增加元素,首部、中间和尾部分别会有什么问题,该如何处理?
在链表的表头插入
要记得将head重新指向表头,用newNode.next=head即可。

在链表中间插入
我们需要在目标结点的钱一个结点停下来,也就是使用cur.next的值而不是cur的值来判断(链表最常用的策略)
例如下图,若想在7的前面插入,则cur.next=node(7)时就应该停下来,操作new.next=cur.next(图中虚线),然后cur.next=new,顺序一定不能颠倒,一旦颠倒执行了cur.next=new,原来cur.next的指向就丢失了

链表尾部插入结点
直接将尾结点指向新节点即可
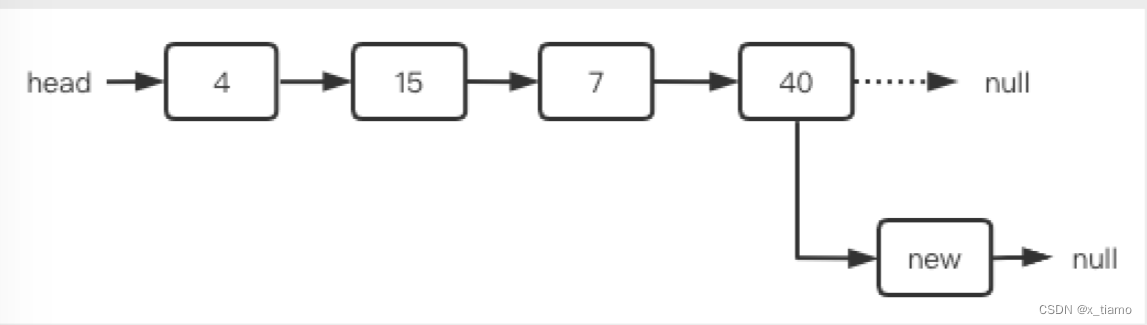
链表删除元素,首部、中间和尾部分别会有什么问题,该如何处理?
没有执行的结点最终会被JVM回收掉
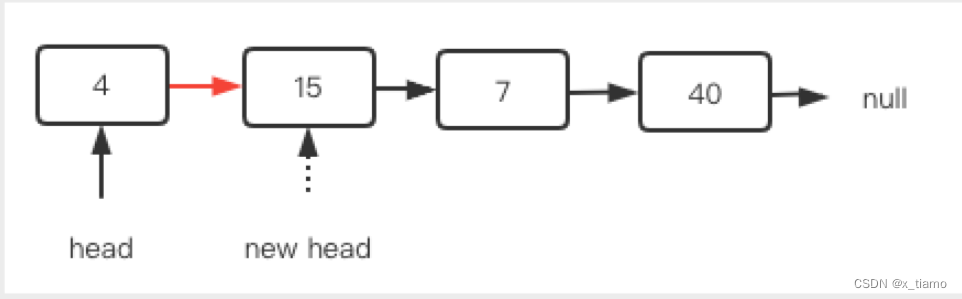
删除头结点
一般只要执行head = head.next即可
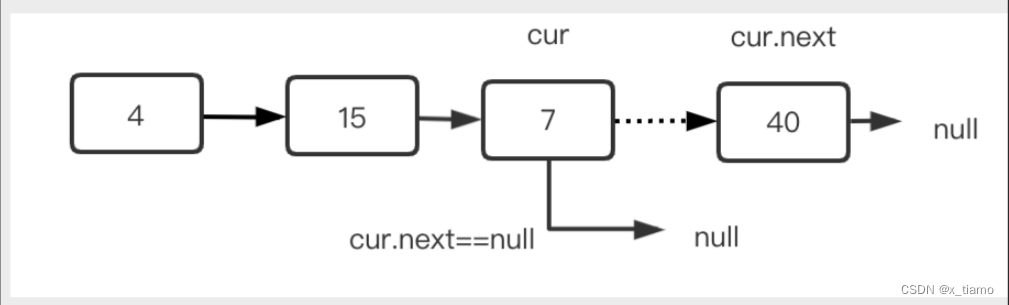
删除中间结点
先定位到cur.next是否是要删除的结点,如果是,只要执行cur.next = cur.next.next

删除尾结点
执行cur.next = null即可
双向链表是如何构造的?
双向列表是一种特殊的列表,它包含一个链表和两个指针,分别指向链表的头部和尾部。这个链表中的每个节点都有一个前驱节点和一个后继节点
- 节点类
class DoubleNode {
// 指向前驱节点
DoubleNode prev;
// 具体存储的数据
int val;
// 指向后继节点
DoubleNode next;
public DoubleNode(int val) {
this.val = val;
}
}
- 链表类
public class DoubleLinkedList {
// 实际存储元素个数
int size;
// 双向链表的头节点
private DoubleNode first;
// 双向链表的尾节点
private DoubleNode last;
}















 91
91











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









