







SQL 可以帮我们进行数据处理,总的来说可以分成 OLTP 和 OLAP 两种方式。
OLTP 称之为联机事务处理,我们之前讲解的对数据进行增删改查,SQL 查询优化,事务处理等就属于 OLTP 的范畴。它对实时性要求高,需要将用户的数据有效地存储到数据库中,同时有时候针对互联网应用的需求,我们还需要设置数据库的主从架构保证数据库的高并发和高可用性。
OLAP 称之为联机分析处理,它是对已经存储在数据库中的数据进行分析,帮我们得出报表,指导业务。它对数据的实时性要求不高,但数据量往往很大,存储在数据库(数据仓库)中的数据可能还存在数据质量的问题,比如数据重复、数据中有缺失值,或者单位不统一等,因此在进行数据分析之前,首要任务就是对收集的数据进行清洗,从而保证数据质量。
对于数据分析工作来说,好的数据质量才是至关重要的,它决定了后期数据分析和挖掘的结果上限。数据挖掘模型选择得再好,也只能最大化地将数据特征挖掘出来。
高质量的数据清洗,才有高质量的数据。今天我们就来看下,如何用 SQL 对数据进行清洗。
- 想要进行数据清洗有怎样的准则呢?
- 如何使用 SQL 对数据进行清洗?
- 如何对清洗之后的数据进行可视化?
数据清洗的准则
我在《数据分析实战 45 讲》里专门讲到过数据清洗的原则,这里为了方便你理解,我用一个数据集实例讲一遍。
一般而言,数据集或多或少地会存在数据质量问题。这里我们使用泰坦尼克号乘客生存预测数据集,你可以从GitHub上下载这个数据集。
数据集格式为 csv,一共有两种文件:train.csv 是训练数据集,包含特征信息和存活与否的标签;test.csv 是测试数据集,只包含特征信息。
数据集中包括了以下字段,具体的含义如下:
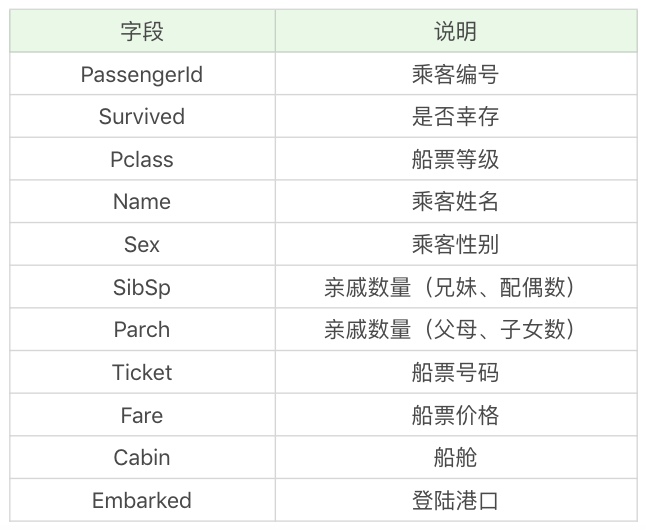
训练集给出了 891 名乘客幸存与否的结果,以及相关的乘客信息。通过训练集,我们可以对数据进行建模形成一个分类器,从而对测试集中的乘客生存情况进行预测。不过今天我们并不讲解数据分析的模型,而是来看下在数据分析之前,如何对数据进行清洗。
首先,我们可以通过 Navicat 将 CSV 文件导入到 MySQL 数据库中,然后浏览下数据集中的前几行,可以发现数据中存在缺失值的情况还是很明显的。
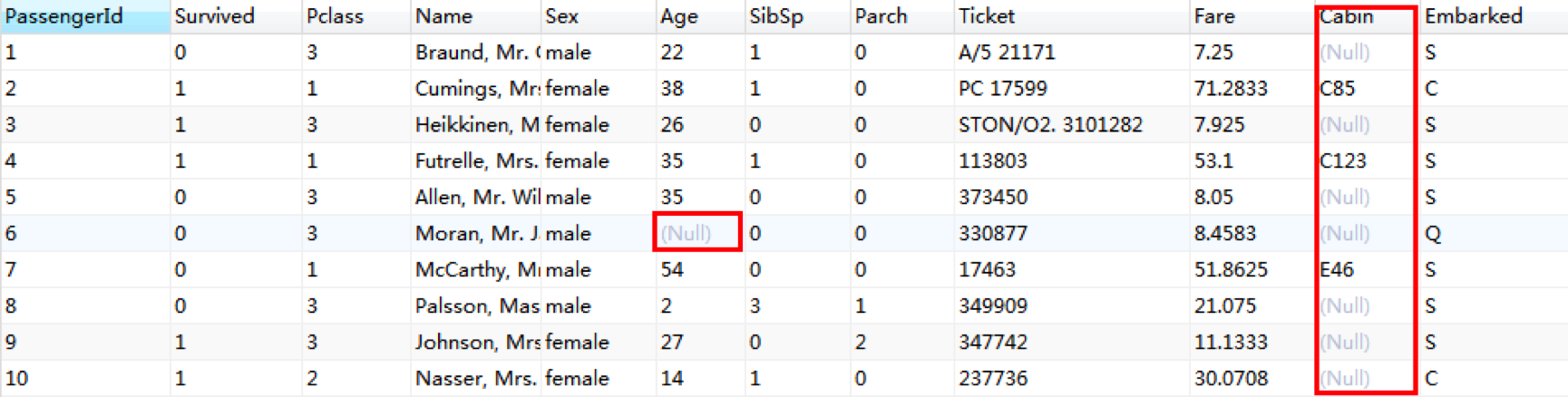
数据存在数据缺失值是非常常见的情况,此外我们还需要考虑数据集中某个字段是否存在单位标识不统一,数值是否合法,以及数据是否唯一等情况。要考虑的情况非常多,这里我将数据清洗中需要考虑的规则总结为 4 个关键点,统一起来称之为“完全合一”准则,你可以点这里看一下。
“完全合一”是个通用的准则,针对具体的数据集存在的问题,我们还需要对症下药,采取适合的解决办法,甚至为了后续分析方便,有时我们还需要将字符类型的字段替换成数值类型,比如我们想做一个 Steam 游戏用户的数据分析,统计数据存储在两张表上,一个是 user_game 数据表,记录了用户购买的各种 Steam 游戏,其中数据表中的 game_title 字段表示玩家购买的游戏名称,它们都采用英文字符的方式。另一个是 game 数据表,记录了游戏的 id、游戏名称等。因为这两张表存在关联关系,实际上在 user_game 数据表中的 game_title 对应了 game 数据表中的 name,这里我们就可以用 game 数据表中的 id 替换掉原有的 game_title。替换之后,我们在进行数据清洗和质量评估的时候也会更清晰,比如如果还存在某个 game_title 没有被替换的情况,就证明这款游戏在 game 数据表中缺少记录。
使用 SQL 对预测数据集进行清洗
了解了数据清洗的原则之后,下面我们就用 SQL 对泰坦尼克号数据集中的训练集进行数据清洗,也就是 train.csv 文件。我们先将这个文件导入到 titanic_train 数据表中:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1265
1265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











