






一、链表
1.单链表
1)头插法
#include<iostream>
using namespace std;
struct node{
int data;
node *next;
};
struct node *creatList(){ // 采用头插法的方式创建指针
node *head,*s;
s=new node;
head=NULL;
cout<<"请输入数据,以-1为结束标志"<<endl;
do{
cin>>s->data;
if(s->data==-1)
break;
s->next=head;
head=s;
s=new node;
}while(true);
return head;
}
int main(){
node *r;
r=creatList();
while(r){ // 打印输出
cout<<r->data<<" ";
r=r->next;
}
return 0;
}
2)尾插法
#include<iostream>
using namespace std;
struct node{
int data;
node *next;
};
struct node *creatList(){ // 采用尾插法的方式创建指针
node *head,*s,*r;
head=r=s=new node;
cout<<"请输入数据,以-1为结束标志:"<<endl;
do{
cin>>s->data;
if(s->data==-1)
break;
r->next=s;
r=s;
s=new node;
}while(true);
r->next=NULL;
return head;
}
int main(){
node *r;
r=creatList();
while(r){ // 打印输出
cout<<r->data<<" ";
r=r->next;
}
return 0;
}
2.双向循环链表
#include<iostream>
using namespace std;
struct node{
int data;
node *next; // 指向下一个地址
node *prior; // 指向前一个地址
};
struct node *creatList(){ // 采用尾插法的方式创建指针
node *head,*s,*r;
head=r=s=new node;
cout<<"请输入数据,以-1为结束标志:"<<endl;
do{
cin>>s->data;
if(s->data==-1)
break;
r->next=s;
s->prior=r;
r=s;
s=new node;
}while(true);
r->next=head;
head->prior=r;
return head;
}
int main(){
static int count; // 默认赋值0
node *r;
r=creatList();
while(r){ // 打印输出
cout<<r->data<<" ";
r=r->next;
if(++count==10)
break;
}
return 0;
}
3.如何进行插入、删除、查找
习题
- 编程实现将给定的一组整数采用选择排序法按由小到大的顺序排序。要求:1)编写函数create()构造一个单链表,假设结点只有一个整数数据域。2)编写函数sort()采用选择排序方法对已知链表进行排序。3)在主函数中完成数据的输入与结果的输出。
#include<iostream>
using namespace std;
struct node{
int num;
node *next;
};
node *create(){ // 采用尾插法创建
node *head,*p,*q; // p为工作指针
head=q=p=new node;
do{ // 输入0为结束条件
cin>>p->num;
if(p->num==0)
break;
q->next=p;
q=p;
p=new node;
}while(true);
q->next=NULL;
return head;
}
void sort(node *head){ // 选择排序 升序
node *i,*j;
int t;
for(i=head;i->next!=NULL;i=i->next){
node *p=i;
for(j=i->next;j!=NULL;j=j->next)
if(j->num<p->num)
p=j;
if(p!=i){
t=p->num;
p->num=i->num;
i->num=t;
}
}
}
int main(){
node *head;
head=create();
sort(head);
while(head){
cout<<head->num<<" ";
head=head->next;
}
return 0;
}
- 已知用两个单链表分别存储的两个字符串,均按递增次序排列。编程实现两个单链表归并为一个按数据域值递减次序排列的单链表。要求:1)单链表中每个结点只存放一个字符。2)利用原链表中的节点空间存储归并后的单链表,不另外生成新链表。3)单链表的建立用函数(creat)实现。4)两个链表归并过程用函数(sub)实现。5)输出结果用函数(output)实现。6)主函数调用这三个函数完成程序功能。
#include<iostream>
using namespace std;
struct node{
char c;
node *next;
};
node *create(char *s){ // 采用尾插法创建
node *head,*p,*q; // p是活动指针
head=p=q=new node;
while(*s){ // 以字符串为结束条件
p->c=*s;
q->next=p;
q=p;
s++;
p=new node;
}
q->next=NULL;
return head;
}
void sub(node *head1,node *head2){ // 实现归并
node *r=head1;
node *i,*j;
char t;
while(r->next!=NULL)
r=r->next; // 找到最后数
r->next=head2; // 将head1和head2连接起来
for(i=head1;i->next!=NULL;i=i->next){ // 降序排序
node *p=i;
for(j=i->next;j!=NULL;j=j->next)
if(j->c>p->c)
p=j;
if(p!=i){
t=p->c;
p->c=i->c;
i->c=t;
}
}
}
void output(node *head){ // 输出
while(head!=NULL){
cout<<head->c<<" ";
head=head->next;
}
}
int main(){
node *head1,*head2;
char *s1=new char,*s2=new char;
cin>>s1>>s2;
head1=create(s1);
head2=create(s2);
sub(head1,head2);
output(head1);
return 0;
}
- n个人围成一圈,一次从1-n编号。从编号为1的人开始1至k报数,凡报数为k的人退出圈子,请编写程序输出最后留下的一个人原来的编号。
#include<iostream>
using namespace std;
struct node{
int number;
node *next;
};
void output(node *head,int n);
node *create(int n){ // 采用尾插法创建
int i=1;
node *head,*p,*q; // p是活动指针
head=p=q=new node;
while(i<=n){
p->number=i++;
q->next=p;
q=p;
p=new node;
}
q->next=head; // 组成循环链表
return head;
}
node *tackle(int k,int n,node *head){
int count=0;
while(n>1){
if(++count==k-1){ // 下一个报数的人退出圈子
count=0;
head->next=head->next->next;
n--;
}
head=head->next;
}
return head;
}
int main(){
int n,k;
node *head,*output;
cin>>n>>k;
head=create(n);
output=tackle(k,n,head);
cout<<output->number<<endl;
return 0;
}
二、栈和队列
1.栈
#include <iostream>
#include <stack>
using namespace std;
int main() {
stack<int> s;
s.push(1); // 入栈
s.push(2);
s.push(3);
cout<<s.top()<<endl; // 查看栈顶元素
s.pop() // 删除栈顶元素
cout<<s.size()<<endl; // 统计个数
if(s.empty()) // 判空
cout<<"Empty"<<endl;
else
cout<<"Not Empty"<<endl;
return 0;
}
2.队列
头函数 #include"queue"
| 方法 | 功能 |
|---|---|
| push | 入队 |
| pop | 出队 |
| front | 获取队头元素 |
| back | 获取队尾元素 |
| empty | 判断队空 |
| size | 返回队个数 |
三、字符串
1.string类型
#include<cstdio>
#include<string>
using namespace std;
int main(){
string str = "abced";
for(int i=0;i<str.length();i++){
printf("%c ",str[i]);
}
return 0;
}
最好用的就是’+‘、’-'和比较运算
#include<iostream>
#include<string>
using namespace std;
int main(){
string str1 = "lichuachua",str2="aixuexi",str3,str4;
str3 = str1+str2; // 可以直接+
cout<<str3<<endl<<endl;
if(str1>str2) // 直接比较
cout<<"str1>str2"<<endl<<endl;
else
cout<<"str1<=str2"<<endl<<endl;
cout<<str2.length()<<" "<<str2.size()<<endl<<endl; // 返回长度
str2.insert(1, "****"); // 指定插入
cout<<str2<<endl<<endl;
str4=str1.substr(1,5); // 返回子串
cout<<str4<<endl<<endl;
string a = "Thank you for your smile";
string b = "you";
string c = "me";
cout<<a.find(b)<<endl; // 查找
cout<<a.find(c)<<endl;
cout<<a.find(b,10)<<endl<<endl; // 指定查找开始位置
string x = "maybe you will turn around";
string y = "will not";
string z = "surely";
cout<<x.replace(10,4,y)<<endl; // 替换
cout<<x.replace(x.begin(),x.begin()+2,z)<<endl;
return 0;
}
2.BF比较算法
基本思想: 将正文串T的第一个字符与模式串P的第一个字符进行匹配,若相等,则继续比较T的第二个字符和P的第二个字符;若不相等,则比较T的第二个字符和P的第一个字符,重复上述过程,直到T或P中的所有字符比较完成。若P的字符全部比较完毕,则匹配成功,返回本躺匹配的起始位置;否则匹配失败,返回0。
以T:ababcababac;P:ababa为例
#include<iostream>
#include<string>
using namespace std;
int main(){
string t="ababcababac",p="ababa";
int i,j,begin=-1;
for(i=0;i<t.length();i++){
begin=i;
for(j=0;j<p.length();j++){
if(t[begin]!=p[j])
break;
begin++;
}
if(j==p.length()) // 找到子串
break;
}
cout<<i<<endl;
return 0;
}
}
3.KMP算法
BF算法虽然简单,但是较为暴力、费时。由于匹配算法在很多应用中需高频使用,为了提高效率提出了KMP算法。
1)基础
基本思想: 每一趟匹配过程中出现字符不匹配时,不回溯i指针,而是利用已经得到的前期匹配结果将模式串向右移动尽可能远的距离后,继续下一趟比较。
以T:abcdefghi;P:abcde0为例,先看BF,再看KMP。
我们发现P的首字母’a’和后面所有字符都不相同,在BF第一趟比较时已经发现T和P前5个字符一模一样,明显字符串P中的’a’不可能和T的第2-5个字符相等,所以BF第2-5趟比较完全没有必要。可以直接从第六躺开始比较。
再回想一下上面BF比较的例子,由于P中的前四个字符和T中的前四个字符相对应,且有P[0] = P[2],P[1] = P[3],显然可以确定T[2] = P[0],T[3] = P[1],所以第二趟比较是多余的,可以直接进行第三趟比较。这样的话就避免了回溯,提高了时间效率。
这时候我们就考虑当P和T不匹配时,下一次P应该从T的哪个位置开始比较,也就是P应该怎么移动呢?我们引入一个next[j] = k,next[j]表示当模式串P中第j个字符与正文串T中相应字符失配时,下一次匹配时模式串需要重新和正文串中该字符进行比较的字符的位置。当j=0时,我们设k=-1,其他情况k=0。
next函数可以理解为基于模式串的 前缀 和 后缀 进行求值的,即next[j]的值为P[0]~P[j-1]最大相同前后缀长度
以T:abcdabeabcdabcdabde;P:abcdabd为例,next[j]如下

#include<iostream>
using namespace std;
void setNext(int next[],char *p){ // next初值
int j=0,k=-1;
next[j]=-1;
while(p[j]){
if(k==-1||p[j]==p[k]){ // 通过j=-1的方式达到移动i的目的
j++;
k++;
next[j]=k; // 先给后面的数付初值0
}
else
k=next[k];
}
}
int kmp(char *t,char *p,int next[]){ // kmp算法
int i=0,j=0;
int x=strlen(t),y=strlen(p);
while(i<x&&j<y){
if(j==-1||t[i]==p[j]){ // 当第一个字符不匹配以及字符相同的时候进行++操作
i++;
j++;
}
else
j=next[j];
}
return j==strlen(p)?i-j:-1;
}
int main(){
char *t="abcdabeabcdabcdabde",*p="abcdabd";
int i,j,next[20];
setNext(next,p);
cout<<kmp(t,p,next)<<endl;
return 0;
}
2)优化
这个算法还是有缺点的,例如正文串T:aaaabcaaaaad,模式串P:aaaaad,按照上述方法就会得到以下next函数。
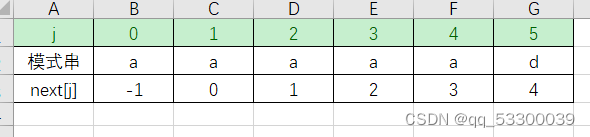
由于模式串中第1、2、3、4、5个字符都相等,所以不需要再将第5个字符和T字符串中的’b’进行比较了,直接右移5位,将i=5,j=0进行比较。也就是说,按前面定义到的next[j]=k,若模式串中Pj=Pk,则当正文串中字符Ti和Pj比较不等式,就不再需要和Pk进行比较了,而是直接和Pnext[k]进行比较,即此时的next[j]=next[k]。所以next函数可以修改为
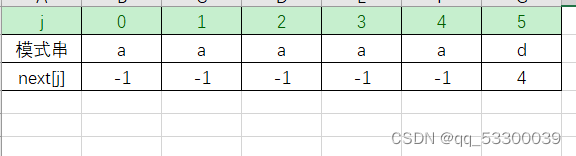
#include<iostream>
using namespace std;
void setNext(int next[],char *p){ // next初值
int i=0,j=-1;
next[i]=-1;
while(p[i]){
if(j==-1||p[i]==p[j]){ // 通过j=-1的方式达到移动i的目的
i++;
j++;
if(p[i]!=p[j])
next[i]=j;
else
next[i]=next[j];
}
else
j=next[j];
}
}
int kmp(char *t,char *p,int next[]){ // kmp算法
int i=0,j=0;
int x=strlen(t),y=strlen(p);
while(i<x&&j<y){
if(j==-1||t[i]==p[j]){
i++;
j++;
}
else
j=next[j];
}
return j==strlen(p)?i-j:-1;
}
int main(){
char *t="aaaabcaaaaad",*p="aaaaad";
int i,j,next[20];
setNext(next,p);
cout<<kmp(t,p,next)<<endl;
return 0;
}
四、排序
1.插入排序
基本思想: 每次将一个待排序的记录,按其关键字大小插入到前面已经排好序的子文件中的适当位置,直到全部记录插入完成为止。
1)直接插入排序
#include<iostream>
using namespace std;
int main(){
int a[8],i,j,n;
for(i=0;i<8;i++){ // 升序
cin>>n;
for(j=i-1;j>=0&&a[j]>n;j--)
a[j+1]=a[j];
a[j+1]=n;
}
for(i=0;i<8;i++)
cout<<a[i]<<" ";
cout<<endl;
return 0;
}
2)希尔排序
基本思想: 先将整个待排序记录序列分割成若干子序列分别进行直接插入排序,待整个序列中的记录“基本有序时”,再对全体记录进行一次直接插入排序。
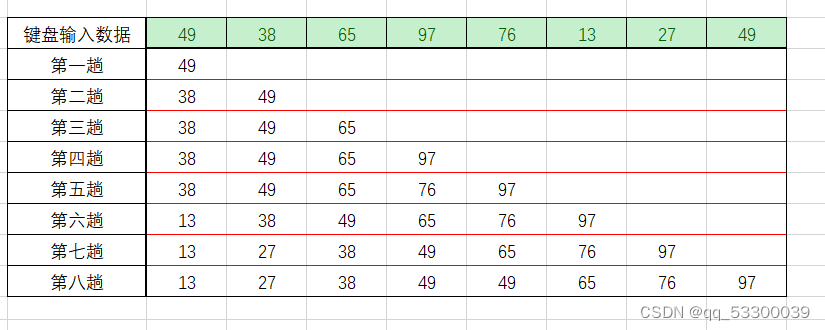
首先,我们需要有一个增量数组,要求最后一个增量必须是1,应尽量避免增量序列的值互为倍数。假设当前增量数组d[3]={5,3,1},首先第一次会将距离为5的元素分为一组,一共分为5组,下面同理进行排序。

#include<iostream>
using namespace std;
int main(){
int a[10]={49,38,65,97,76,13,27,49,55,4},incremental[3]={5,3,1};
int i,j,k,t,b;
for(i=0;i<3;i++){ // 希尔排序
b=incremental[i]; //增量
for(j=b;j<10;j++){
t=a[j]; // 保存插入数据
for(k=j-b;k>=0&&a[k]>t;k-=b)
a[k+b]=a[k];
a[k+b]=t;
}
for(j=0;j<10;j++)
cout<<a[j]<<" ";
cout<<endl;
}
cout<<endl;
for(i=0;i<10;i++)
cout<<a[i]<<" ";
cout<<endl;
return 0;
}
增量函数,也可以通过数组长度/2,反正自行定义,怎么方便怎么来
2.交换排序
基本思想: 两两比较待排序记录的关键字,发现两个记录的次序相反时即进行交换,知道没有反序的记录为止。
1)冒泡排序
2)快速排序
基本思想: 在a[left…right]中选一个记录,通常选第一个a[low]作为判断元素pivot,用这个判断元素将原数组划分为左右两个子区间a[left…pivot-1],a[pivot+1…right],按照排序要求如升序,所有比pivot小的放在左区间,比pivot大的放在右区间。再从左右两个区间中选取一个新的pivot按照同样规则排序,知道所有元素有序为止。

#include<iostream>
using namespace std;
int partition(int a[],int i,int j){ // 返回划分后的判断位置
int pivot=a[i];
while(i<j){
while(i<j&&a[j]>=pivot) // 从右往左找第一个小于关键字的下标
j--;
if(i<j)
a[i++]=a[j];
while(i<j&&a[i]<=pivot) // 从左往右找第一个大于关键字的下标
i++;
if(i<j)
a[j--]=a[i];
}
a[i]=pivot;
return i;
}
void quicksort(int a[],int left,int right){
int pivot;
if(left<right){ // 区间长度>1才排序
pivot=partition(a,left,right);
quicksort(a,left,pivot-1);
quicksort(a,pivot+1,right);
}
}
int main(){
int a[10]={49,38,65,97,76,13,27,49,55,4};
quicksort(a,0,9);
for(int i=0;i<10;i++)
cout<<a[i]<<" ";
cout<<endl;
return 0;
}
#include<iostream>
#include<stack>
#define MAX 100
using namespace std;
struct Data{
int key;
}a[MAX];
void InterData(int n){
int i;
cout<<"请输入数据:";
for(i=1;i<=n;i++)
cin>>a[i].key;
}
void Display(int n){ //输出
int i;
for(i=1;i<=n;i++)
cout<<a[i].key<<" ";
cout<<endl;
}
void QuickSort1(Data a[],int n){ //快速排序(非递归)
int i,j,t,left,right;
stack<int>s1; //存左边
stack<int>s2; //存右边
s1.push(1);
s2.push(n);
while(!s1.empty()){
left=i=s1.top();
s1.pop();
right=j=s2.top();
s2.pop();
a[0].key=a[i].key; //a[0]做为暂存储单元
while(i<j){
while(a[j].key>=a[0].key&&i<j)
j--;
while(a[i].key<=a[0].key&&i<j)
i++;
if(i!=j){
t=a[i].key;
a[i].key=a[j].key;
a[j].key=t;
}
}
a[left].key=a[i].key;
a[i].key=a[0].key;
if(left<right){
s1.push(i+1);
s2.push(right); //右区间
s1.push(left);
s2.push(i-1); //左区间
}
}
}
int main(){
int n;
cout<<"请输入数据个数:";cin>>n;
InterData(n);
QuickSort1(a,n);
cout<<"非递归:";
Display(n);
return 0;
}
3.选择排序
1)直接选择排序
2)堆排序
4.归并排序
基本思想: 把待排序的文件分成若干子文件,先将每个子文件内的记录排序,再将已排序的子文件合并,得到完全排序的文件。

5.使用sort排序
需要使用头函数#include<algorithm.h>
sort(数组名,数组名+元素个数,排序函数);
#include<iostream>
#include<algorithm>
using namespace std;
int main(){
int a[10]={49,38,65,97,76,13,27,49,55,4},i;
sort(a,a+10); // 默认情况,升序
for(i=0;i<10;i++)
cout<<a[i]<<" ";
cout<<endl;
return 0;
}
#include<iostream>
#include<algorithm>
using namespace std;
bool compare(int a,int b){ // 排序规则
return a>b;
}
int main(){
int a[10]={49,38,65,97,76,13,27,49,55,4},i;
sort(a,a+10,compare); // 降序
for(i=0;i<10;i++)
cout<<a[i]<<" ";
cout<<endl;
return 0;
}
五、查找
1.静态查找
1)顺序表查找
从表的一端开始,逐个与关键字进行比较,如果某个数据元素的关键字与给定的关键字相等,则查找完成,并返回该数据元素在顺序表中的位置;若整个表查找完成,仍未找到与给定的关键字相等的元素,则查找失败,给出未找到的信息并返回0
2)有序表查找
包含顺序查找和二分查找,这里介绍一下二分查找。
基本思想: 在要查找元素集合的范围内,依次与表的中间位置元素进行比较,如果找到与关键字相等的元素,则说明查找成功,否则利用中间位置将表分成两段。如果查找关键字小于中间位置的元素值,则进一步与前一个表中的中间位置比较,否则与后一个子表的中间位置元素比较。重复以上操作,直到找到与关键字相等的元素。
#include<iostream>
#include<algorithm>
using namespace std;
int main(){
int a[10]={49,38,65,97,76,13,27,49,55,4},i;
int left=0,right=9,mid,n;
sort(a,a+10);
for(i=0;i<10;i++)
cout<<a[i]<<" ";
cout<<endl;
cin>>n;
while(left<=right){
mid=(left+right)/2;
if(a[mid]==n)
break;
else if(a[mid]<n)
left=mid+1;
else
right=mid-1;
}
if(left<=right)
cout<<mid<<endl;
else
cout<<"没找到"<<endl;
return 0;
}
3)分块索引查找
基本思想: 将查找表分为若干子块,要求所有这些块分块有序,即后一块中所有元素的关键码均大于前一块的最大元素;而每个块内的元素可以是无序的(块内无序)。另外要为这些块建立一个索引表。索引表中的每个元素均含有各块的最大关键字max_key以及该块在数据表中的起始位置(也就是各块中第一个元素的地址)。

在索引表内可以用二分查找or顺序查找,但是在原数据里只能进行顺序查找,因为是无序的。
六、遍历算法
链接:link
1.深度优先 DFS
基本思想: 选取一个节点开始,沿着一条路一直走到底,然后从这条路尽头的节点回退到上一个节点,再从另一条路开始走到底…,不断递归重复此过程,直到所有的顶点都遍历完成。
2.广度优先 BFS
基本思想: 从图的一个未遍历的节点出发,先遍历这个节点的相邻节点,再依次遍历每个相邻节点的相邻节点
3.全排列
需要头函数#inlcude"algorithm",方法名为next_permutation(开始地址,结束地址),跟sort()方法很相似。
缺点:不适合大数据
#include<iostream>
#include<algorithm>
using namespace std;
int main(){
int a[4]={1,2,3,4},count=0;
do{
count++;
for(int i=0;i<4;i++)
cout<<a[i]<<" ";
cout<<endl;
}while(next_permutation(a,a+4));
cout<<count<<endl;
return 0;
}
4.习题
1)李白喝酒问题
链接:link
思考如何利用全排列的方法解决?
#include<iostream>
#include<algorithm>
using namespace std;
int main(){
int i,count=0,wine;
char a[]="aaaaabbbbbbbbbb";
do{
wine=2;
for(i=0;i<strlen(a);i++){
if(a[i]=='a') // 遇店酒*2
wine*=2;
else if(a[i]=='b') // 遇花酒-1
wine-=1;
}
if(wine==0){
count++;
for(i=0;a[i];i++)
cout<<a[i];
cout<<endl;
}
}while(next_permutation(a,a+14));
cout<<count<<endl;
return 0;
}
2)方块分割
链接:link
#include<iostream>
#define N 6
using namespace std;
bool visited[N][N]; //辅助数组
int dirx[4]={0,-1,1,0},diry[4]={-1,0,0,1}; //四个方向(左、下、上、右)
void DFS(int x,int y,int &sum){
if(x==0||y ==0||x ==N||y == N){
sum++;
return ;
}
for(int i=0;i<4;i++){
int tx=x+dirx[i];
int ty=y+diry[i];
if(visited[tx][ty]!=true){
visited[tx][ty]=visited[N-tx][N-ty]=true;
DFS(tx,ty,sum); //回溯
visited[tx][ty]=visited[N-tx][N-ty]=false;
}
}
}
int main(){
int sum=0;
visited[N/2][N/2]=true;
DFS(N/2,N/2,sum);
cout<<sum/4<<endl;
return 0;
}
3)迷宫问题
链接:link














 105
105











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









