






学习目标:
第一周 循环神经网络(Recurrent Neural Networks)
学习内容:
目录
第一周 循环神经网络(Recurrent Neural Networks)
1.3 循环神经网络模型(Recurrent Neural Network Model)
1.4 通过时间的反向传播(Backpropagation through time)
1.5 不同类型的循环神经网络(Different types of RNNs)
1.6 语言模型和序列生成(Language model and sequence generation)
1.7 对新序列采样(Sampling novel sequences)
1.8 循环神经网络的梯度消失(Vanishing gradients with RNNs)
1.9 GRU单元(Gated Recurrent Unit(GRU))
1.10 长短期记忆(LSTM(long short term memory)unit)
学习时间:
11.7-11.11
学习产出:
1.1 常见的序列模型
序列模型:处理对象一般为时间序列。与CNN处理对象不同的地方在于:CNN处理空间对象,但是RNN主要体现在一维时间上,或者说序列。
下面是常见的一些序列模型:
1、输入音频片段(序列),输出语音的含义,即文字片段。输入和输出数据都是序列模型,因为 X是一个按时播放的音频片段,输出 Y是一系列单词。多对多
2、音乐生成问题:输入空集或某些元素,输出一段音频(音乐)。输入可能没有或者为几个音符,输出为一段音频。一对多
3、情感分类问题,输入为一段文字序列,输入为心情指数。多对对
4、DNA匹配问题,输入DNA序列,输出序列匹配的蛋白质,多对多
5、机器翻译,输入法文,输出英文。多对多,大概率序列长度不一样。
6、视频行为识别,输入视频帧片段,输出状态。
7、人名识别,输入句子,输出人名。多对多。教学使用的样例
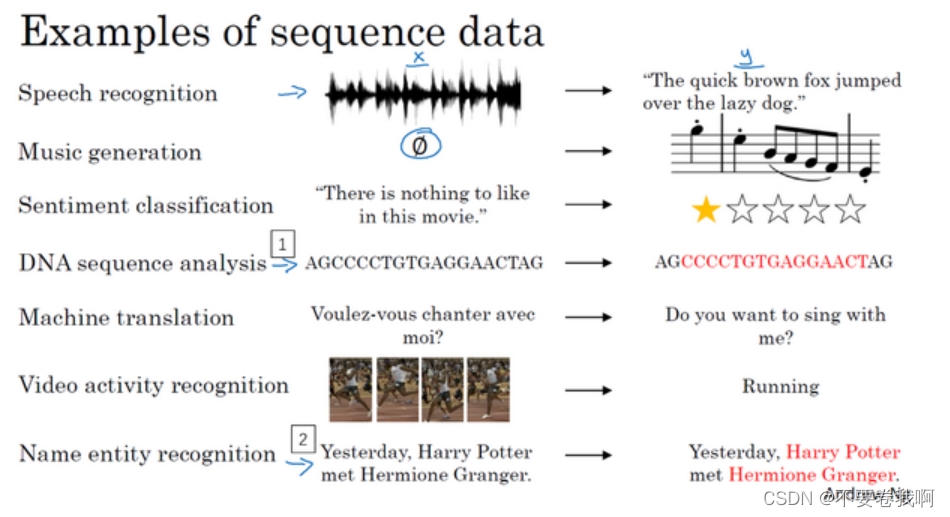
总结:序列模型问题有很多不同的情况,虽然都是处理序列,但是由于序列的输入,输出数量的不一致,可以分成很多种情况,例如多对多(等长),多对多(不等长),一对多等。
1.2 数学符号(Notation)
使用第七个例子中的人名识别作为演示样例,输入为一段文字,输出其中的人名。

问题提取:对于输入句子的每一个单词进行分析,判断它是否为人名。
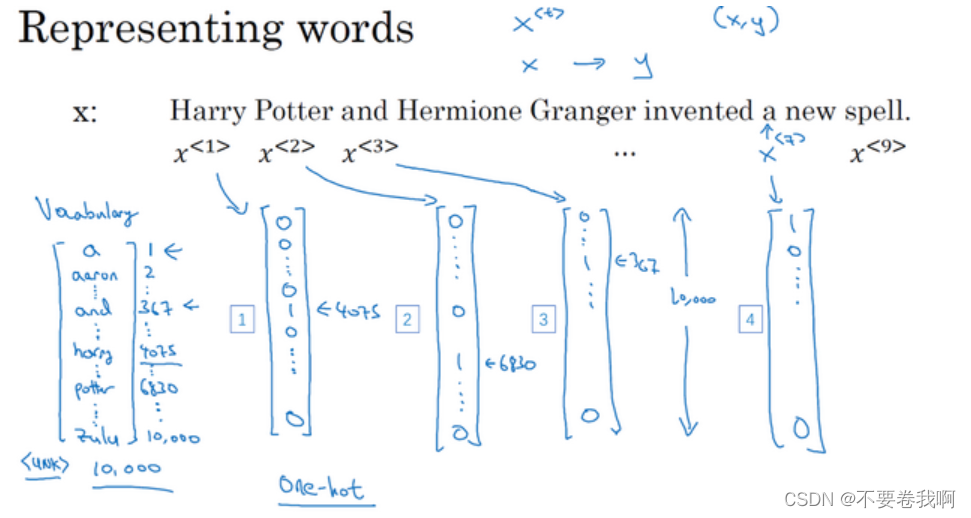
数学表示,将每个单词使用一个类似图中的列向量去表示,例如:4075行的位置为1,表示在左边字典中,4075行位置单词为Harry,因此,该向量表示Harry。这样就可以将单词转化为数据进行存储,计算。
同时,对于输出y,图中9个单词,对每个单词有对应输出,0表示不是人名,1表示是人名。
最后你有可能碰见不认识的单词,可以在字典最后使用UNK进行表示。
1.3 循环神经网络模型(Recurrent Neural Network Model)
在1.2中建立好了数学模型,因此现在我们应该想办法搭建输入x与输出y之间的神经网络,以求计算出一个网络可以分析出人名。
首先想到的肯定是直接使用一般的全连接网络。
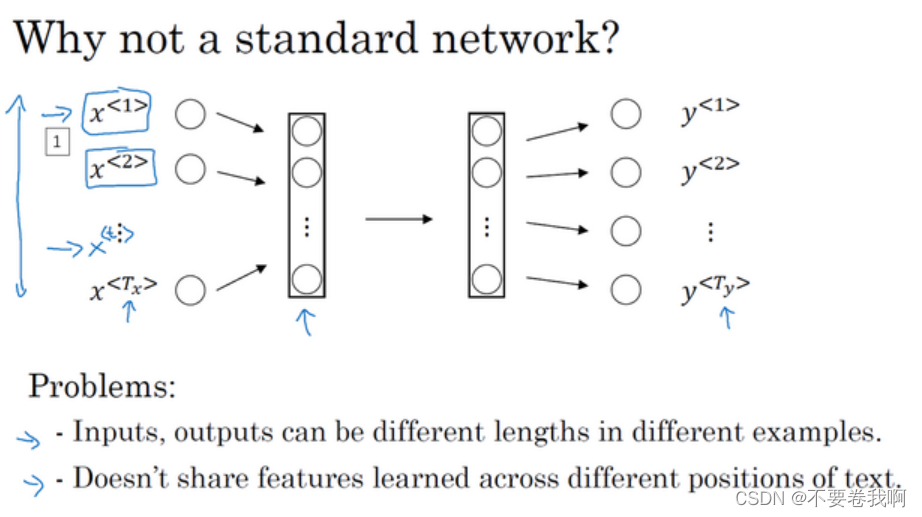
使用一般网络的缺点:输入和输出的长度都有可能变化,输入的句子长度一般都不相同,对应的输出也就不同。
句子中不同位置的单词特征不会产生相互影响,也就是说,前面的单词大意不能给后面提供很好的特征参考,例如前面已经出现某个人名Harry,那么我们希望后面的单词可以有记忆,也就是说,当后面单词再次碰见Harry时,可以很容易的计算出他是一个人名。
上面的缺点使得我们需要一种更适应它的网络出现,也就有了循环神经网络解决该问题。
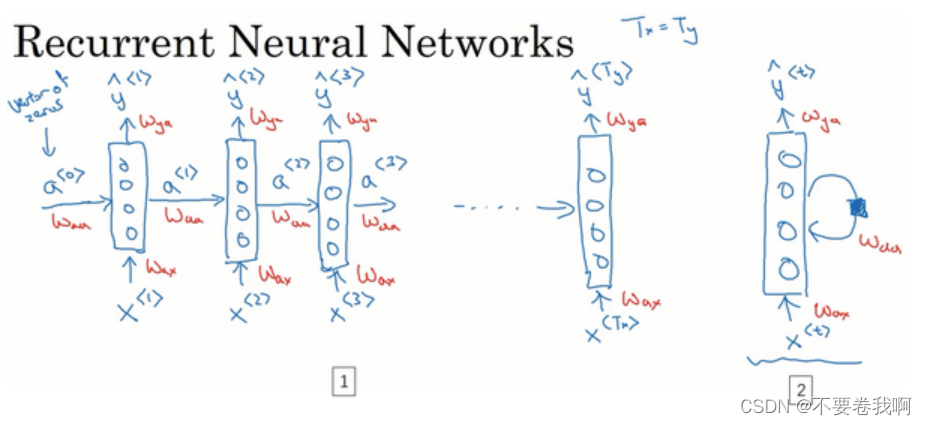
如上图的循环神经网络。左右两图都是一个神经网路,只不过表示的方法不同。
首先分析竖直的神经网络:很容易理解,就是说 y 的取值与 x 是有关系的,这也是很容易提取的,判断该单词是否为人名,那么这个单词肯定要为这个小网络的输入。但是在前面一般网络的缺点中我们知道,希望在当前单词的分析中,我们可以拥有该单词前面的单词特征。
即:横向看过去,a值包含了前面的单词提取出的特征,将他输入到当前的单词,也就可以使得当前的分析可以考虑前面的句子成分,即 Harry 在历史中已经出现的情况下,本次分析如果还是 Harry ,那么就很容易计算出它是人名了。
注意:到这里我们的RNN已经可以考虑前向的历史信息了,但是很多句子成分可能是倒装的,所以我们希望网络可以自行去考虑后面的未来信息。这在后面会提到(双向循环神经网络(BRNN)),大致来说就是我们希望本次考虑可以瞻前顾后去理解整个句子最终算出它是否是人名。
设计好了网络,我们要观察这个网络的具体计算过程,即网络的详细过程。
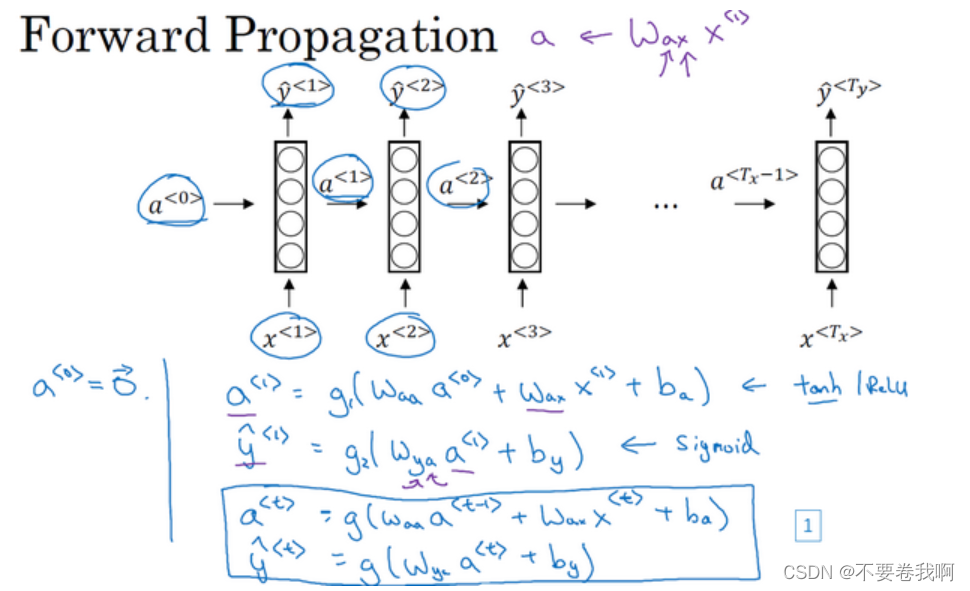
如图给出了RNN的详细计算过程。四个公式。w、b 参数很好理解,这是一般都存在的,所以我们在这里只说明 g函数 的选取。
对于计算 a 的 g函数 选取:我们不需要考虑输出形式,所以它是RNN的隐藏单元输出,根据以前学习的知识,激活函数经常是tanh,不过有时候也会用ReLU。
对于计算 y 的 g函数 选取:这取决于输出的形式。例如这里的人名计算希望输出为0或1,所以一般使用sigmod。其它问题就很有可能有其他函数的选择。
这张ppt是为了简化上面的算式,将Waa与Wax进行简单的拼接,a与x也进行拼接,不影响矩阵的计算情况,而简化了算式。
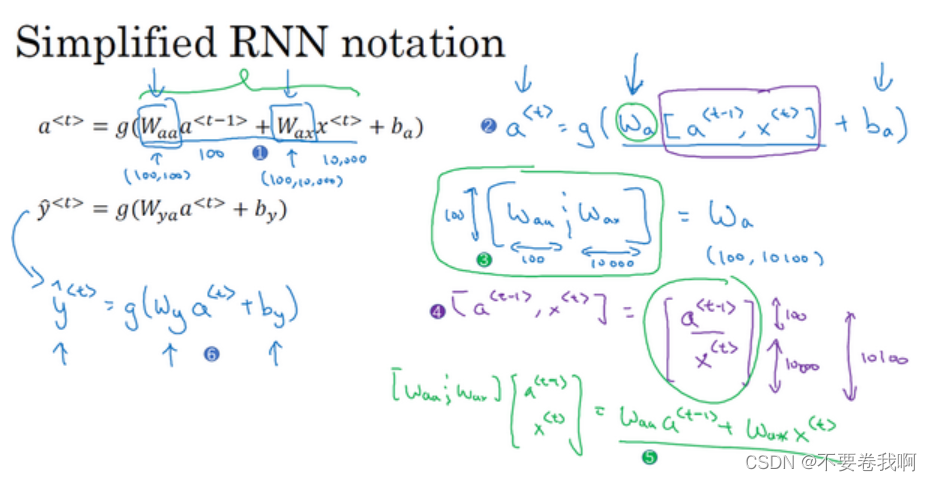
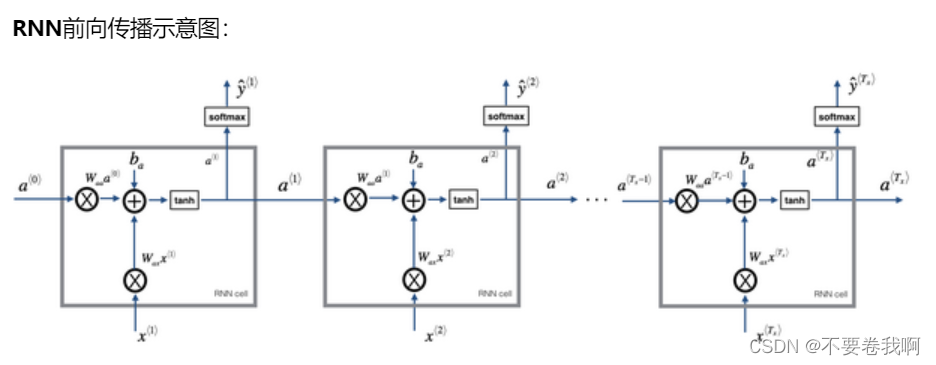
OK这就是前向传播的图例示意。可以很容易观察到,yt 的输出是包含历史信息y1~y(t-1)的,同时也是与xt有关的,即本次计算对应的单词。
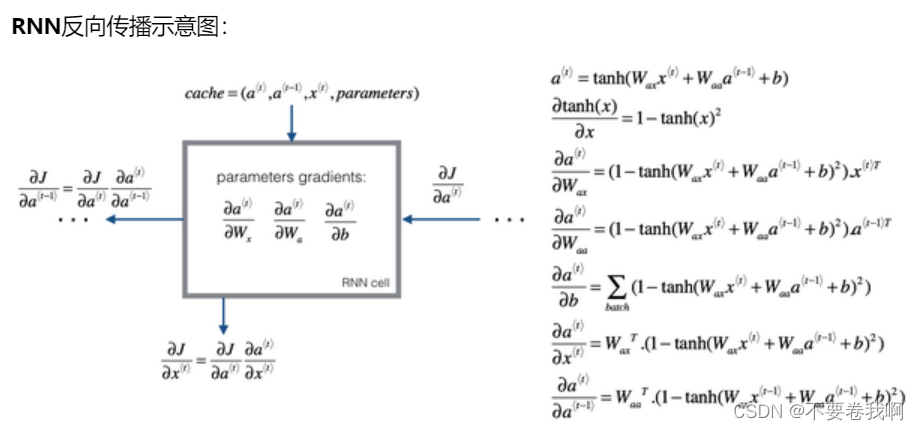
1.4 通过时间的反向传播(Backpropagation through time)
反向传播的计算还必须先提供损失函数:
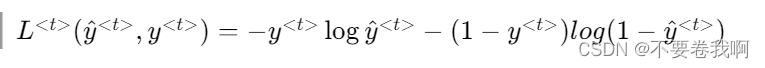
最终的代价函数为:
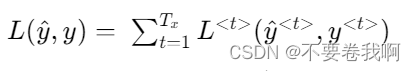
反向传播过程与前向计算过程完全相反,进行梯度下降即可。
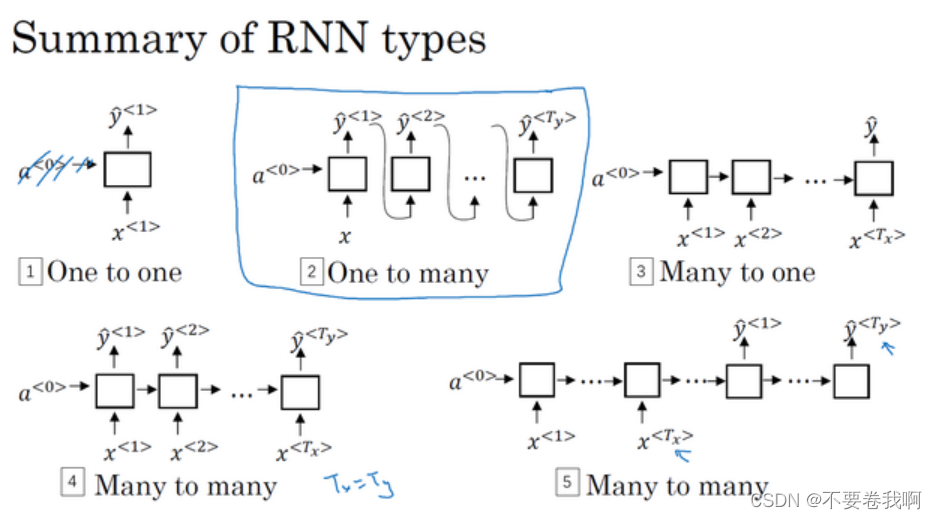
1.5 不同类型的循环神经网络(Different types of RNNs)
在1.1中我们发现了,根据序列模型的输入或者输出是可能不一样的,所以也就出现了各种不一样的循环神经网络,例如一对一,一对多,多对一,多对多(输入输出等长、输入输出不等长)等。
1.6 语言模型和序列生成(Language model and sequence generation)
在自然语言处理中,构建语言模型是最基础的也是最重要的工作之一,并且能用RNN很好地实现。
1、什么是语言模型

如上图,例如一个语音识别系统,识别出句子可能出现上面的两种情况。两个句子可能听起来是很类似的,那么我们就希望有一种语音识别系统可以计算出两个句子的可能性并且输出大概率正确的句子。
2、问题解决
你首先需要一个训练集,包含一个很大的英文文本语料库(corpus)或者其它的语言,你想用于构建模型的语言的语料库。语料库是自然语言处理的一个专有名词,意思就是很长的或者说数量众多的英文句子组成的文本。

数学标记:对每个单词设置一个映射到字典的列向量。与1.2类似。但是不一样的是,可能在每个句子后面加一个EOS标记用来表示句子的结尾,同时遇见Mau类似的不确定单词,标记成UNK。
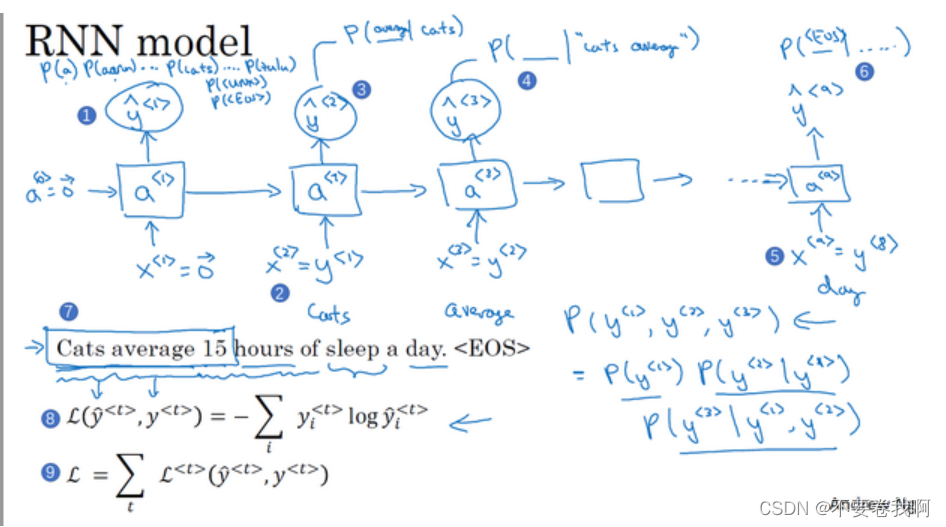
为了最终计算出句子的概率,输入x为对应位置的单词。输出 yt 表示一个softmax的输出,一般表示 xt 这个输入为10002个对应单词情况的概率。这样就可以计算出第一个单词概率最大的某个单词作为输出,即Cats(假设模型很强可以计算出该结果)。
那么第二个输入,使用了将原来的输出Cats结果概率作为输入,来计算第二个输出为average的概率,也就是说,其实输出y2的意思是,当前面单词为Cats的情况下,当前的输出为average的概率。
emmm以此类推,最终输出的概率就是整个句子为目标句子的概率。
其实也还没看懂,可能需要再看一遍······
1.7 对新序列采样(Sampling novel sequences)
与1.6原理类似,将前一个输出最为后一个单元的输入,就可以实现随机采样某个单词,从而设计出某些意想不到的结果。如果你的RNN使用莎士比亚的文章风格进行训练的,某个输入就可以输出一篇文章,该文章可能是类似莎士比亚语气风格的文章。
1.8 循环神经网络的梯度消失(Vanishing gradients with RNNs)
梯度的爆炸和消失在前面的学习中经常提到,这里可以进行说明,RNN的梯度爆炸可以通过设置一个阈值,当某个单元的计算结果大于阈值时,我们就可以调整网络。
但是梯度消失的情况有时候很难去解决。引起原因如下:
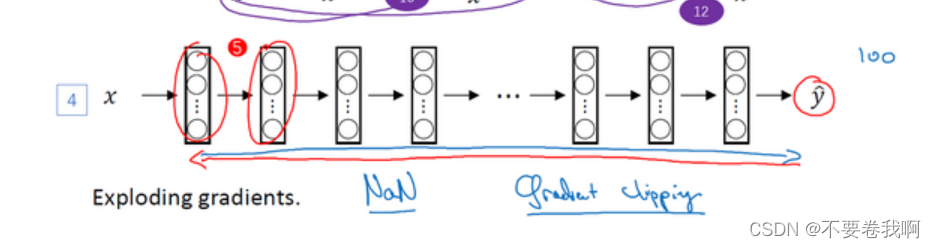
由于RNN的单元数过多,在反向计算时,最终的y可能很难对开始的几个神经网络单元进行反向计算调整,或者说导数递归到左边的两个单元时,影响已经可以忽略不计了,从而导致了梯度消失存在,并且自己没办法调整前面的参数,从而一直存在。
我们迫切需要一种方法,可以让反向计算影响各个单元,而不是无法影响某些单元。1.9与1.10就提出了两种解决方法。
1.9 GRU单元(Gated Recurrent Unit(GRU))
我们将输出的a改成另一种形式a,当然这里的c其实与以前的a时同一输出,只不过中间经过的计算不同。

如图是GRU的计算过程,其中 c 与 a 只不过是名字不同,但都是RNN的横向输出。
引入门的概念,c是受参数![]() 影响的,
影响的,![]() 的输出在1附近,那么c大概率被更新,如果
的输出在1附近,那么c大概率被更新,如果![]() 为0,那么c大概率与c(t-1)是相同的,这样就可以实现对各个单元的不同控制影响,在反向计算时,y就可以根据c进行反向传播,实现对不同单元的影响。
为0,那么c大概率与c(t-1)是相同的,这样就可以实现对各个单元的不同控制影响,在反向计算时,y就可以根据c进行反向传播,实现对不同单元的影响。
1.10 长短期记忆(LSTM(long short term memory)unit)

LSTM比GRU更复杂,或者说GRU是LSTM的简化版本。
GRU虽然简单但也可以产生效果。
LSTM比GRU更优。
这周有spring框架的课,所以学的比较少。















 182
182











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









