






目录
一、理论学习
1.1ShuffleNet v1
为了提高通道间的关联性,作者提出了channel shuffle的思想。在ShuffleNet Unit中普通卷积全部被替换为GConv和DWConv,channel shuffle是将组卷积后每组的第一个通道放在一组,对与其他通道也是同样的处理。它弥补了组卷积中不同组之间的信息无法得到交流的缺陷。
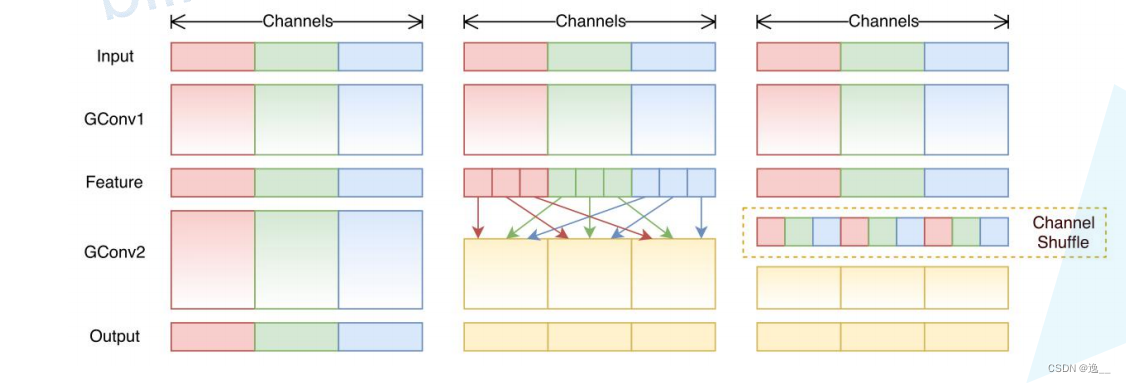
ShuffleNet中的Unit如下图所示,(b)对应stride=1的情形,(c)对应stride=2的情形。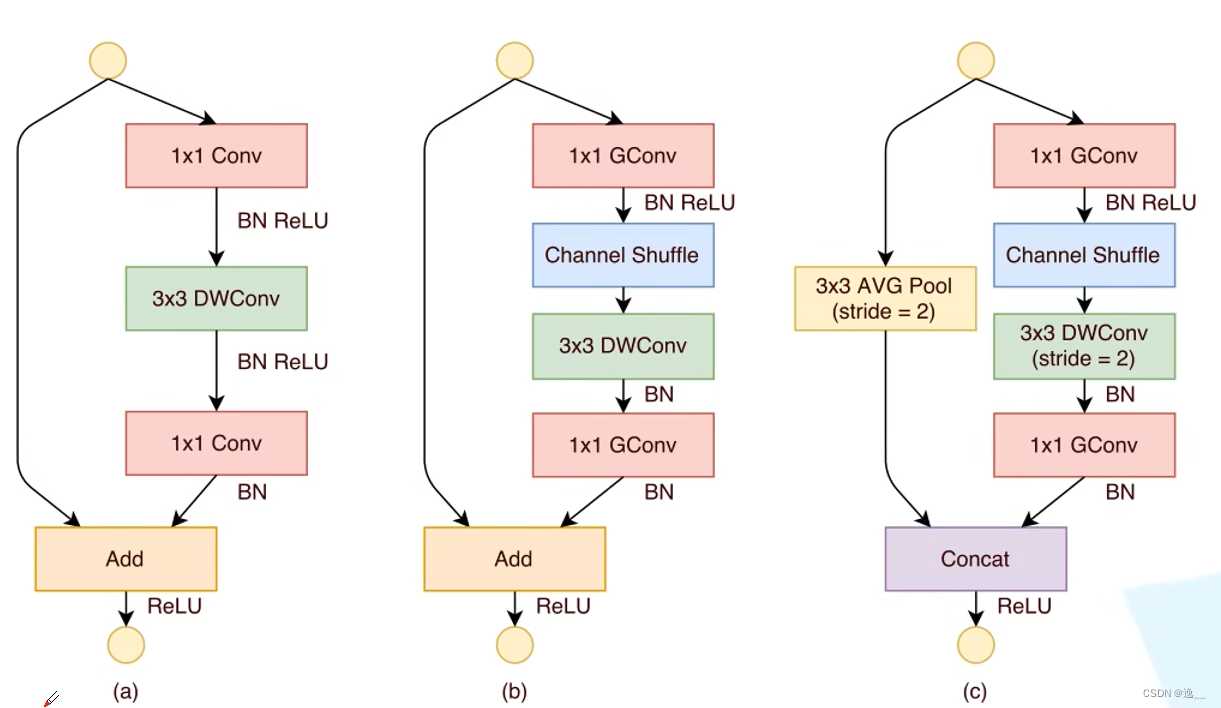
ShuffleNet网络结构如下:Stage中是将对应步长的Unit进行堆叠,每个Stage会将上一个Stage输出通道翻倍。
论文给出了ShuffleNet v1网络涉及到的一些计算量(FLOPs)。并与ResNet和ResNext进行对比.假设输入矩阵的高为h,宽为w,通道数为c,block内部输出通道数为m。

1.2ShuffleNet v2
计算复杂度不能只看FLOPs,Memory Access Cost(MAC)在组卷积操作中占用了大部分时间;另一个因素是并行度,并行度高的模型速度会快于并行度低的模型(在相同的FLOPs)。论文提出了四条设计高速网络的准则,并依此提出新的Block设计。
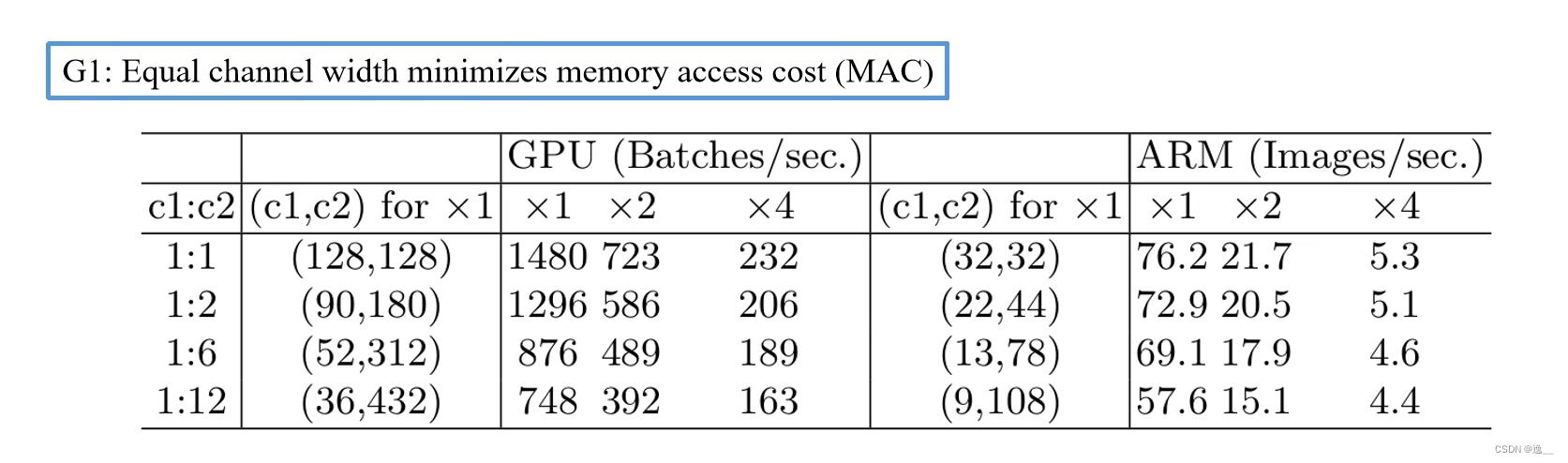
1、当输入通道数与输出通道数相同时MAC最小。
在FLOPs相同的情况下,当输入通道c1与输出通道c2为1:1时运算速度最快。
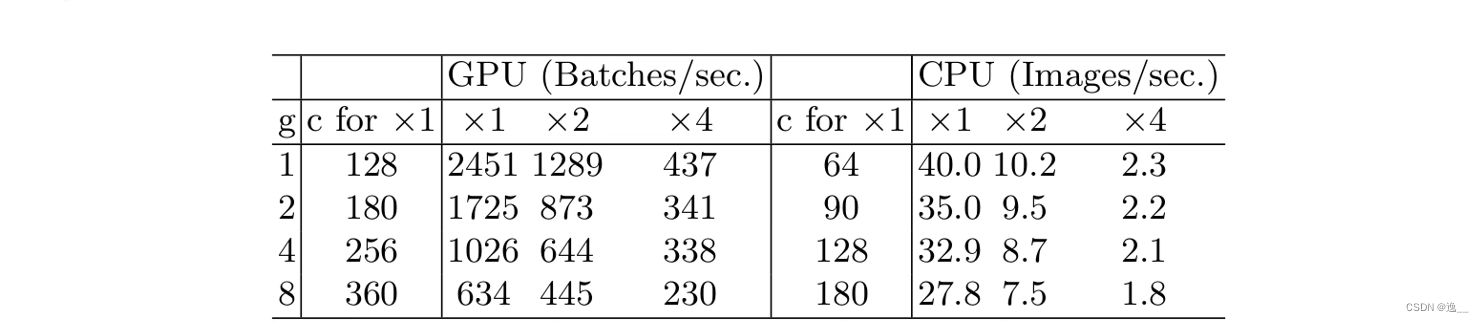
2、组卷积的组数也会影响MAC

从表格中可以看到组数越大,每秒钟处理的Batch数量越少,速度也就越慢。
3、网络的碎片化程度越高,速度越慢
碎片化设计虽然提高了模型准确率,但降低了速度。没有最大化利用CPU的强大的并行运算能力。

4、Element-Wise操作影响模型速度

Element-Wise操作(RELU、按元素求和,偏置bias等)的FLOPs很小,但是MAC很大。
由上述4个准则设计的新Block:下图左边两个Block对应v1版本,右边为v2版本。在c中,为了降低碎片化程度,左边的分支不作任何处理。右边分支卷积层的输入通道与输出通道保持一致,满足第一个准则,两个1×1卷积不在分组,一是为了满足第二个准则,而是在spilt操作中可以看做已经分为了两个组。concat是将输出进行拼接。
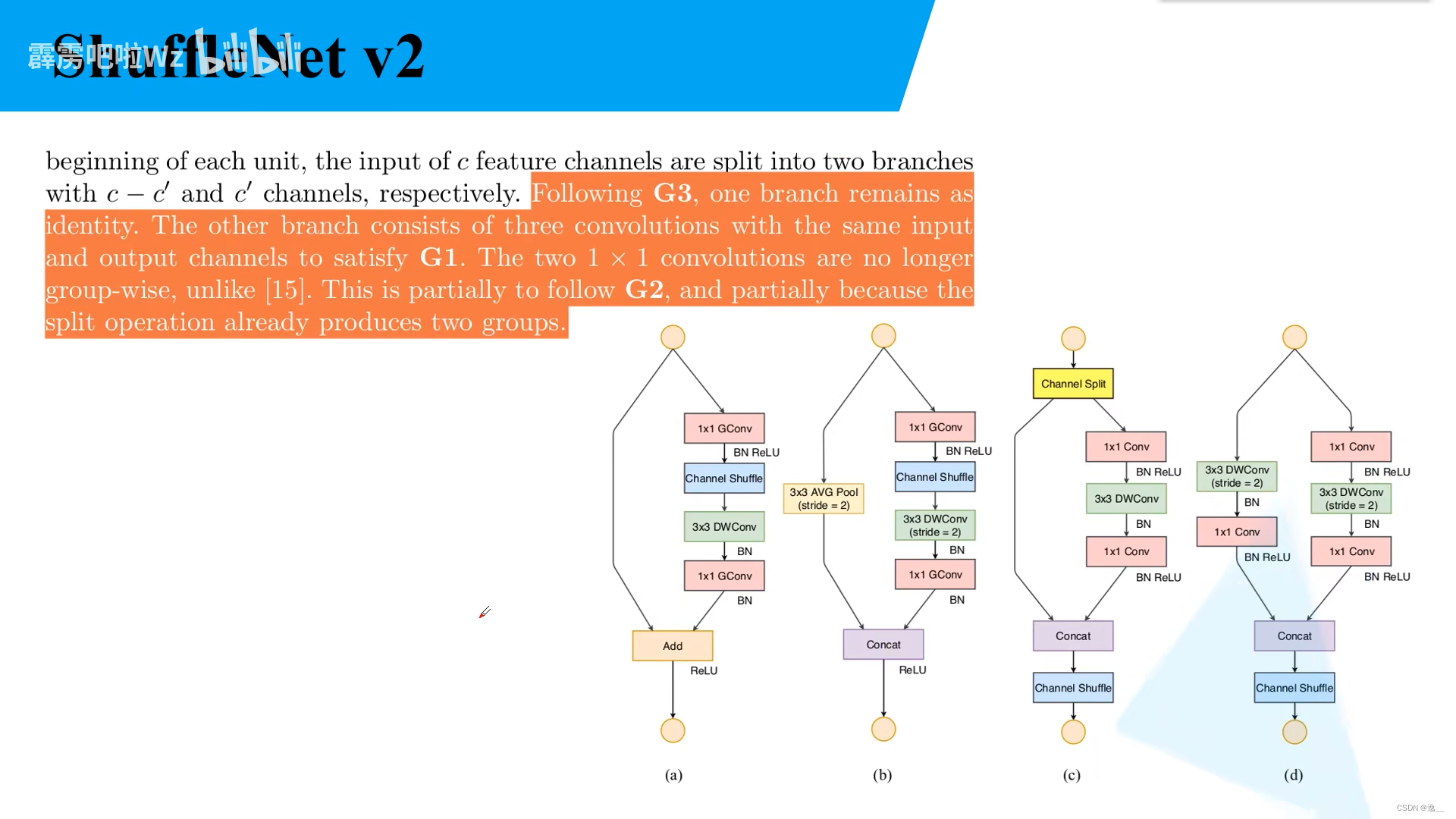
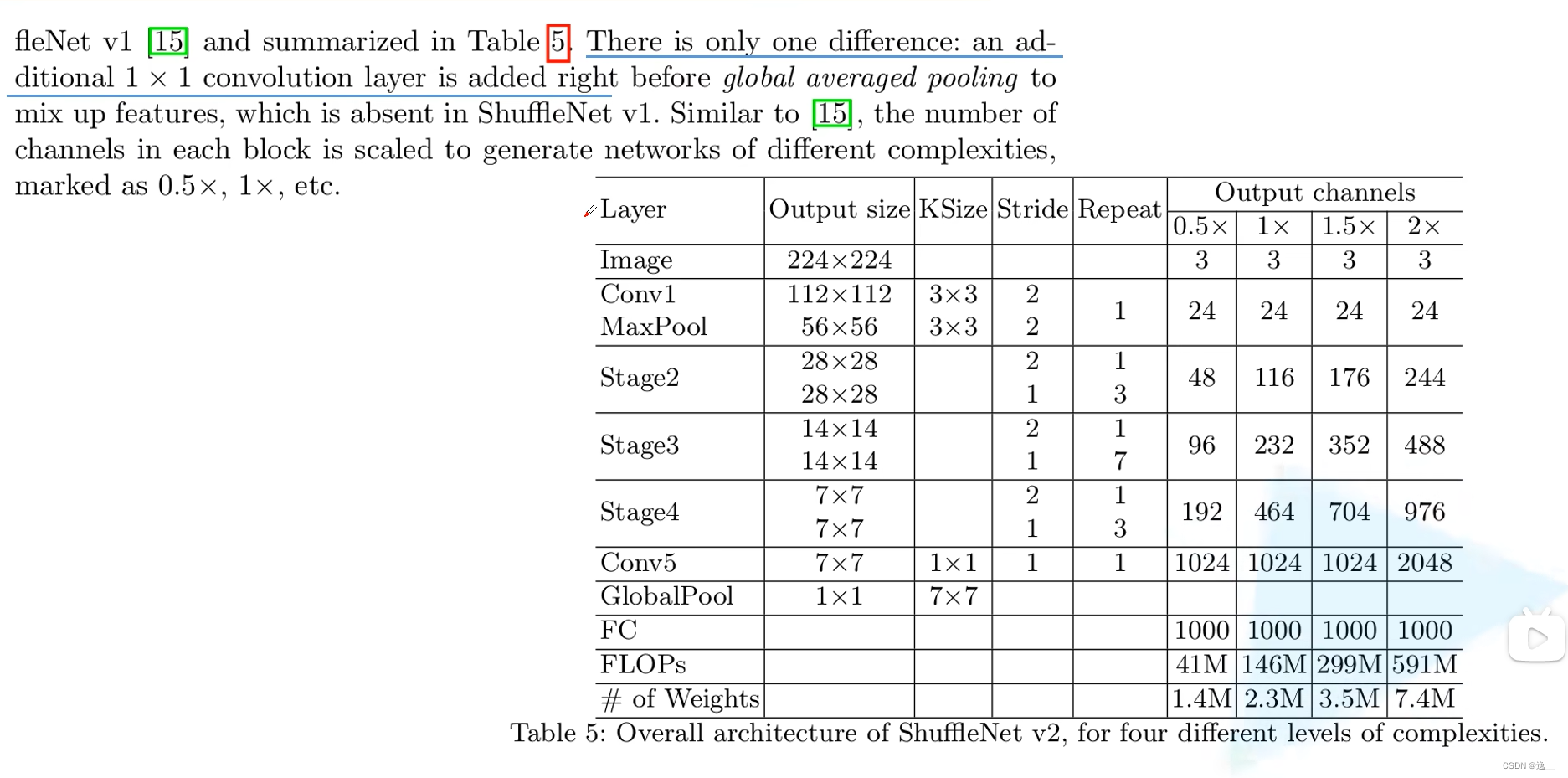
ShuffleNet v2的网络结构如下表格,它的结构与v1类似,只是在Stage4后面加了一个卷积层。
1.3EfficientNet
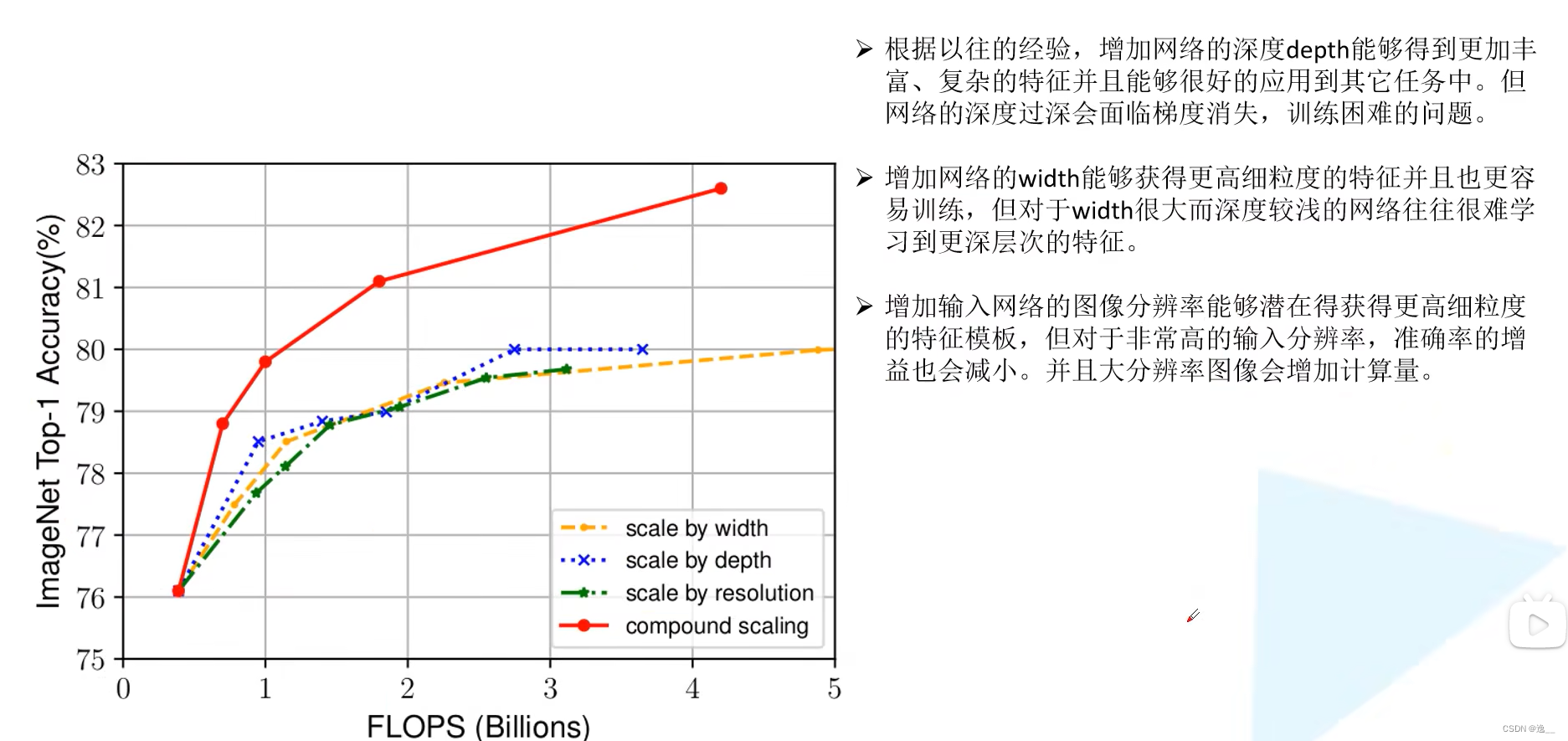
在图像分类领域的网络中,基本都是通过调整网络输入分辨率R,网络深度和宽度来提升网络性能,本篇论文的主要是用NAS(Neural Architecture Search)技术来搜索这三个参数的合理化配置论文给出了增加网络深度,宽度以及提高输入图像分辨率对网络准确率的影响,在相同计算量情况下,同时增加这三个方面可以有效提高模型的准确率。
 通过NAS技术搜索得到的EfficientNetB0结构如下图所示,B1-B7在此基础上修改了Resolution、Channels和Layers。每个卷积后都包含了BN和Swish激活函数。最后一列表示MBConv在该Stage重复多少次。表格中每个MBConv后会跟一个数字1或6,这里的1或6就是倍率因子n即MBConv中第一个1x1的卷积层会将输入特征矩阵的channels扩充为n倍,其中k3x3或k5x5表示MBConv中Depthwise Conv所采用的卷积核大小。Channels表示通过该Stage后输出特征矩阵的Channels。
通过NAS技术搜索得到的EfficientNetB0结构如下图所示,B1-B7在此基础上修改了Resolution、Channels和Layers。每个卷积后都包含了BN和Swish激活函数。最后一列表示MBConv在该Stage重复多少次。表格中每个MBConv后会跟一个数字1或6,这里的1或6就是倍率因子n即MBConv中第一个1x1的卷积层会将输入特征矩阵的channels扩充为n倍,其中k3x3或k5x5表示MBConv中Depthwise Conv所采用的卷积核大小。Channels表示通过该Stage后输出特征矩阵的Channels。

MBConv类似MobileNetV3网络中的倒残差结构,区别在于EfficientNet的MBConv使用了Swish激活函数,而且在每个MBConv中加入了Squeeze-and-Excitation(SE)模块,如下图所示下图转自博文
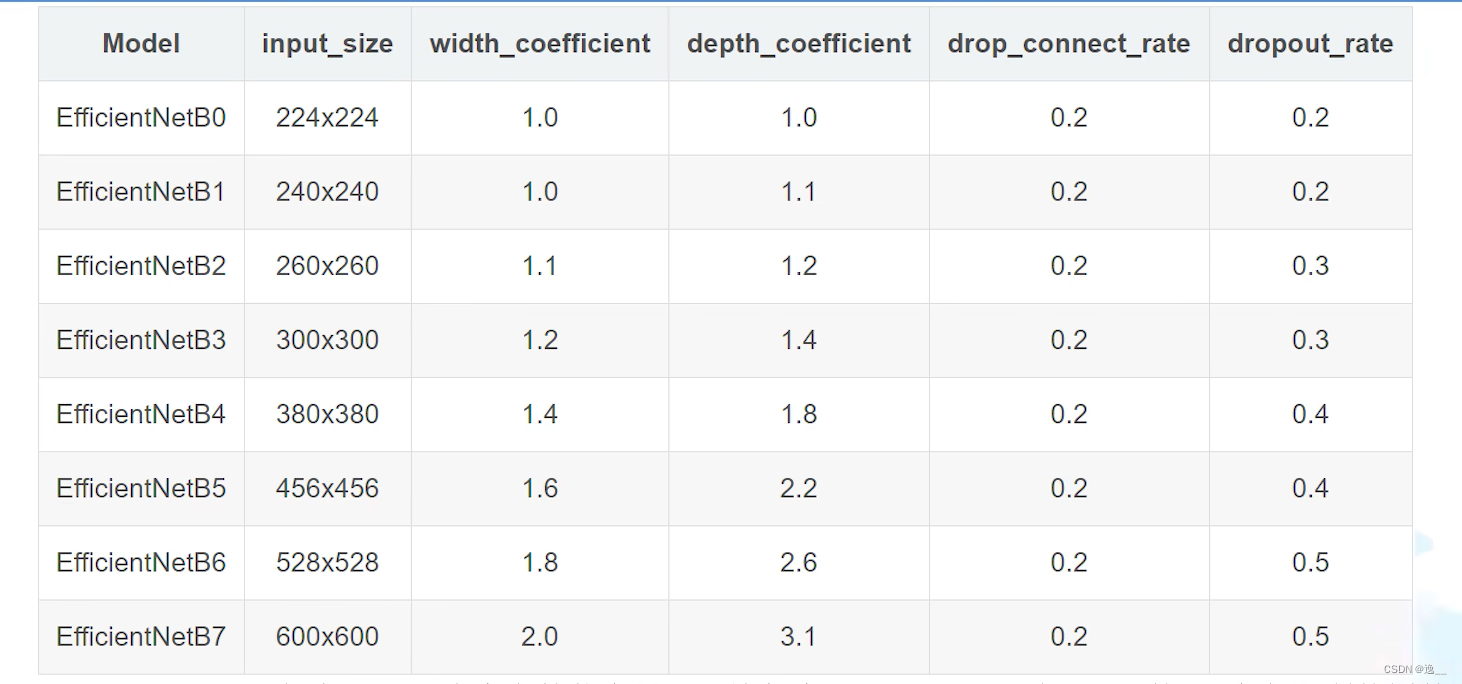
B0-B7的配置见下表。
width_coefficient代表channel维度上的倍率因子,比如在 EfficientNetB0中Stage1的3x3卷积层所使用的卷积核个数是32,那么在B6中就是32 × 1.8 = 57.6 。接着取整到离它最近的8的整数倍即56,其它Stage同理。
depth_coefficient代表depth维度上的倍率因子(仅针对Stage2到Stage8),比如在EfficientNetB0中Stage7的=4那么在B6中就是4 × 2.6 = 10.4 4 \times 2.6=10.44×2.6=10.4接着向上取整即11.
drop_connect_rate是在MBConv中Dropout层使用的droprate(并不是每一次都×0.2,而是从0递增到了0.2).
dropout_rate是最后一个全连接层的dropout。
二、代码学习
2.1使用VGG进行猫狗大战
数据下载和预处理
将数据下载到同目录下,地址为链接,命名为cat_dog,需要将train、valid下的图片手动划分到cat、dog两个文件夹下。由于使用VGG的模型,因此需要对数据进行预处理以满足VGG模型的输入格式。
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
vgg_format = transforms.Compose([
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
])
data_dir = './cat_dog/'
dsets = {x: datasets.ImageFolder(os.path.join(data_dir, x), vgg_format)
for x in ['train', 'valid']}
dset_sizes = {x: len(dsets[x]) for x in ['train', 'valid']}
dset_classes = dsets['train'].classes
print(dsets['train'].classes)
print(dsets['train'].class_to_idx)
print(dsets['train'].imgs[:5])
print('dset_sizes: ', dset_sizes)
loader_train = torch.utils.data.DataLoader(dsets['train'], batch_size=64, shuffle=True, num_workers=0)
loader_valid = torch.utils.data.DataLoader(dsets['valid'], batch_size=64, shuffle=False, num_workers=0)输出如下:
['cat', 'dog']
{'cat': 0, 'dog': 1}
[('./cat_dog/train\\cat\\cat_0.jpg', 0), ('./cat_dog/train\\cat\\cat_1.jpg', 0), ('./cat_dog/train\\cat\\cat_10.jpg', 0), ('./cat_dog/train\\cat\\cat_100.jpg', 0), ('./cat_dog/train\\cat\\cat_1000.jpg', 0)]
dset_sizes: {'train': 20000, 'valid': 2000}
模型训练
下载VGG16模型,设置 required_grad=False,反向传播训练梯度时,前面层的权重就不会自动更新。训练中,只会更新最后一层的参数。原始模型的最后一个全连接层有1000个输出,对应1000个类别,而猫狗大战问题中只有两类,需要对模型的全连接层进行修改。
model_vgg = models.vgg16(pretrained=True)
print(model_vgg)
model_vgg_new = model_vgg;
for param in model_vgg_new.parameters():
param.requires_grad = False
model_vgg_new.classifier._modules['6'] = nn.Linear(4096, 2)
model_vgg_new.classifier._modules['7'] = torch.nn.LogSoftmax(dim = 1)
model_vgg_new = model_vgg_new.to(device)
print(model_vgg_new.classifier)
criterion = nn.NLLLoss()
# 学习率
lr = 0.001
# 随机梯度下降
optimizer_vgg = torch.optim.SGD(model_vgg_new.classifier[6].parameters(), lr=lr)
'''
第二步:训练模型
'''
def train_model(model, dataloader, size, epochs=1, optimizer=None):
model.train()
for epoch in range(epochs):
running_loss = 0.0
running_corrects = 0
count = 0
for inputs, classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs, classes)
optimizer = optimizer
optimizer.zero_grad()
loss.backward()
optimizer.step()
_, preds = torch.max(outputs.data, 1)
# statistics
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
count += len(inputs)
print('Training: No. ', count, ' process ... total: ', size)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print('Loss: {:.4f} Acc: {:.4f}'.format(
epoch_loss, epoch_acc))
# 模型训练
train_model(model_vgg_new, loader_train, size=dset_sizes['train'], epochs=1,
optimizer=optimizer_vgg)print(model)得到如下输出
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
这便是VGG16的网络模型。
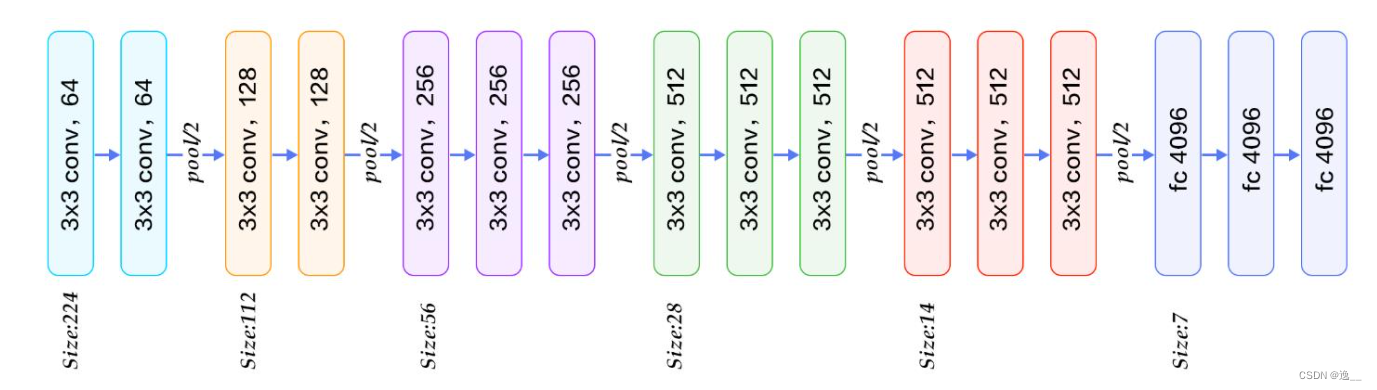
修改过后输出classifier模块:
Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=2, bias=True)
(7): LogSoftmax(dim=1)
)
训练结果:由于batchsize为64所以number以64递增。

测试部分:
def test_model(model, dataloader, size):
model.eval()
predictions = np.zeros(size)
all_classes = np.zeros(size)
all_proba = np.zeros((size, 2))
i = 0
running_loss = 0.0
running_corrects = 0
for inputs, classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs, classes)
_, preds = torch.max(outputs.data, 1)
# statistics
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
predictions[i:i + len(classes)] = preds.to('cpu').numpy()
all_classes[i:i + len(classes)] = classes.to('cpu').numpy()
all_proba[i:i + len(classes), :] = outputs.data.to('cpu').numpy()
i += len(classes)
print('Testing: No. ', i, ' process ... total: ', size)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print('Loss: {:.4f} Acc: {:.4f}'.format(
epoch_loss, epoch_acc))
return predictions, all_proba, all_classes
predictions, all_proba, all_classes = test_model(model_vgg_new,loader_valid,size=dset_sizes['valid'])测试结果:
 上述代码是在验证集上的测试,对于测试集,采用与第三周相同的测试代码,并生成了.csv文件,上传之后得分如下:
上述代码是在验证集上的测试,对于测试集,采用与第三周相同的测试代码,并生成了.csv文件,上传之后得分如下:
resfile = open('Vggtest.csv', 'w')
for i in range(0, 2000):
# 加载当前的图片
img_path = './cat_dog/test/' + str(i) + '.jpg'
img = Image.open(img_path)
img = vgg_format(img)
img = torch.unsqueeze(img, dim=0)
with torch.no_grad():
# predict class
output = torch.squeeze(testmodel(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print(img_path, ":", predict_cla.item())
resfile.write(str(i) + ',' + str(predict_cla.item()) + '\n')
resfile.close()
2.2 AI艺术鉴赏
参考排行第一名的代码,采用迁移学习的思想,使用预训练好的EfficientNetV3模型,修改全连接层输出数量为49,因为共49个类。网络结构:
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.base = EfficientNet.from_pretrained('efficientnet-b3')
self._avg_pooling = nn.AdaptiveAvgPool2d(1)
self._max_pooling = nn.AdaptiveMaxPool2d(1)
num_ftrs = self.base._fc.in_features
self.reduce_layer = nn.Conv2d(num_ftrs*2,512,1)#b3 num_ftrs=1536
self._dropout = nn.Dropout(0.3)
self._fc = nn.Linear(512,49)
def forward(self,x):
x = self.base.extract_features(x)
x1 = self._avg_pooling(x)
x2 = self._max_pooling(x)
x = torch.cat([x1,x2],dim=1)
x = self.reduce_layer(x)
x = x.flatten(start_dim=1)
x = self._dropout(x)
x = self._fc(x)
return x三、问题
对于第二个代码练习,同样可以使用VGG网络进行训练和测试,需要在数据处理以及全连接层出进行修改,但AI鉴赏的训练数据集类别是以表格给出,没有规律且类别较多(49),需要一些额外的代码进行分类。通过下述代码可将训练数据按照类别划分到对应文件夹下。
data_jpg = np.array(glob.glob('train/*.jpg'))
for line in data_jpg:
name = int(line.split('.')[0].split('\\')[num])
fnames.append(name)
label.append(file['label'][name])
src_path = os.path.join('./train/',str(name)+".jpg")
dst_path = os.path.join('./trainPro/',str(file['label'][name]))
shutil.copy(src_path,dst_path)













 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









