







 本文主要涉及两个任务。首先,介绍如何根据给定的规则为大学学生分配学号,规则包括学生层次、入学年份、学院、专业、班级和排名。然后,分析两个不同的大学排行榜,对比前m名大学的异同,提供四种不同类型的排名结果展示。
本文主要涉及两个任务。首先,介绍如何根据给定的规则为大学学生分配学号,规则包括学生层次、入学年份、学院、专业、班级和排名。然后,分析两个不同的大学排行榜,对比前m名大学的异同,提供四种不同类型的排名结果展示。
目录
分配学号
描述
文件“schoolCode.csv”和“MajorCode.csv”中的数据是每个学院的编号和专业的编号,“studentList.csv”文件中有若干学生信息,学生出现的顺序是他在班级中排名顺序,每行中的数据用逗号分隔,各数据依顺代表:
学生姓名,学生性别,学院,专业名称,行政班(专业加班级号,例如经济1901),入学年级。
假如本科的学生层次编号为012,请为“studentList.csv”中的数据增加学号,学号创建规则是:
学生层次+入学年份后两位+学院代码+专业代码+班级号+班中排名。
例如:012171985170110 表示本科生、2017年入学、文法学院、 编辑出版专业、1701班、排名为10的同学
输入格式说明
第一行输入学生姓名
第二行输入班级
输出格式说明
第一行输出该学生的学号、学生姓名、学生性别、学院、专业名称、行政班、入学年级信息,各项之间空格分隔
其后分行输出该班级所有同学的学号、学生姓名、学生性别、学院、专业名称、行政班、入学年级信息,各项之间空格分隔
示例 1
输入:
段宁
金融gj1701
输出:
012142172140101 段宁 女 国际学院 金融 金融gj1401 2014
012172172170101 罗愚 女 国际学院 金融 金融gj1701 2017
012172172170102 卢佳 女 国际学院 金融 金融gj1701 2017
012172172170103 张郁 女 国际学院 金融 金融gj1701 2017
def read_file(filename):
with open(filename, 'r', encoding='utf-8') as file:
file_to_list = [line.strip().split(',') for line in file]
return file_to_list
def student_id(ls_student, ls_school, ls_major):
dic_school = {x[0]: x[1] for x in ls_school}
dic_major = {x[0]: x[1] for x in ls_major}
detail = []
for student in ls_student:
student_number = '012'
student_number += student[5][2:] + dic_school[student[2]] + dic_major[student[3]] + student[4][-4:]
student_number += '{0:0>2}'.format([x[0] for x in ls_student if student[4] == x[4]].index(student[0]) + 1)
detail.append([student_number] + student)
return detail
def student_info(stu_name, ls_student):
student_detail = [info for info in ls_student if info[1] == stu_name][0]
return student_detail
def classmate(stu_class, ls_student):
classmate_of_student = [info for info in ls_student if info[5] == stu_class]
return classmate_of_student
if __name__ == '__main__':
stuName = input()
stuClass = input()
student_list = read_file('studentList.csv')[1:]
school_code = read_file('schoolCode.csv')
major_code = read_file('MajorCode.csv')
studentDetail = student_id(student_list, school_code, major_code)
print(*student_info(stuName, studentDetail))
ls_classmate = classmate(stuClass, studentDetail)
for classmate in ls_classmate:
print(*classmate)大学排行榜分析
描述
大学排名没有绝对的公正与权威,附件(alumni.txt, soft.txt)中为按照不同评价体系给出的国内大学前100名排行,对比两个排行榜单前m的学校的上榜情况,分析不同排行榜排名的差异。
根据输入,输出以下内容:
第一行输入1,第二行输入m,输出在alumni.txt和soft.txt榜单中均在前m个记录的大学,按照学校名称升序。
第一行输入2,第二行输入m,输出在alumni.txt或者soft.txt榜单中前m个记录的所有大学,按照学校名称升序。
第一行输入3,第二行输入m,输出出现在榜单alumni.txt中前m个记录但未出现在榜单soft.txt前m个记录中的大学,按照学校名称升序。
第一行输入4,第二行输入m,输出没有同时出现在榜单alumni.txt前m个记录和榜单soft.txt前m个记录的大学,按照学校名称升序。
第一行输入其他数据,则直接输出‘Wrong Option’
示例 1
输入:
1
10
输出:
两榜单中均名列前10的学校:
['上海交通大学', '**大学', '**大学', '**大学', '**大学', '**大学', '**大学', '**大学', '**大学', '**大学']
示例 2
输入:
2
10
输出:
两榜单名列前10的所有学校:
['上海交通大学', '**大学', '**大学', '**大学', '**大学', '**大学', '**大学', '**大学', '**大学', '**大学',..........]
示例 3
输入:
3
10
输出:
alumni中名列前10,soft中未进前10的学校:
['中国人民大学', .............................]
示例 4
输入:
4
10
输出:
不同时出现在两个榜单前10的学校:
['中国人民大学', .............................]
def read_file(file,m):
"""读文件中的学校名到列表中,返回排名前m学校集合"""
with open(file, "r", encoding="utf-8") as data:
university_list = [line.strip().split()[1] for line in data]
return set(university_list[:m])
def either_in_top(alumni, soft):
"""接收两个排行榜前m高校名字集合,
获得在这两个排行榜中均名列前m的学校名,按照学校名称排序,
返回排序后的列表
"""
either_set = alumni & soft
return sorted(list(either_set))
def all_in_top(alumni, soft):
"""接收两个排行榜前m高校名字集合,
获得在两个榜单中名列前m的所有学校名,按照学校名称排序,
返回排序后的列表
"""
all_in_set = alumni | soft
return sorted(list(all_in_set))
def only_alumni(alumni, soft):
"""接收两个排行榜前10高校名字集合,
获得在alumni榜单中名列前10但soft榜单中未进前10的学校名,
按照学校名称排序,返回排序后的列表
"""
only_alumni_set = alumni - soft
return sorted(list(only_alumni_set))
def only_once(alumni, soft):
"""接收两个排行榜前10高校名字集合,
获得在alumni和soft榜单中名列前10,但不同时出现在两个榜单的学校名,
按照学校名称排序,返回排序后的列表
"""
only_once_set = alumni ^ soft
return sorted(list(only_once_set))
if __name__ == '__main__':
n=input()
if n in '1234':
m=int(input())
alumni_set = read_file('./alumni.txt',m)
soft_set = read_file('./soft.txt',m)
if n=='1':
either_rank = either_in_top(alumni_set, soft_set)
print(f'两榜单中均名列前{m}的学校:')
print(either_rank)
elif n=='2':
all_rank = all_in_top(alumni_set, soft_set)
print(f'两榜单名列前{m}的所有学校:')
print(all_rank)
elif n=='3':
only_in_alumni_rank = only_alumni(alumni_set, soft_set)
print(f'alumni中名列前{m},soft中未进前{m}的学校:')
print(only_in_alumni_rank)
elif n=='4':
alumni_soft_rank = only_once(alumni_set, soft_set)
print(f'不同时出现在两个榜单前{m}的学校:')
print(alumni_soft_rank)
else:
print('Wrong Option')strip()
strip()方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列
注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符
>>> str = "123abcrunoob321"
>>> print (str.strip('12'))
3abcrunoob3对集合做交集、并集、差集运算
>>> set1={1,2,3}
>>> set2={3,4,5}
>>> set1 & set2 #交集
{3}
>>> set1 | set2 #并集
{1,2,3,4,5}
>>> set1 - set2 #差集
{1,2}
>>> set2 - set1
{4,5}
>>> set1 ^ set2 #对称差集
{1,2,4,5}习题
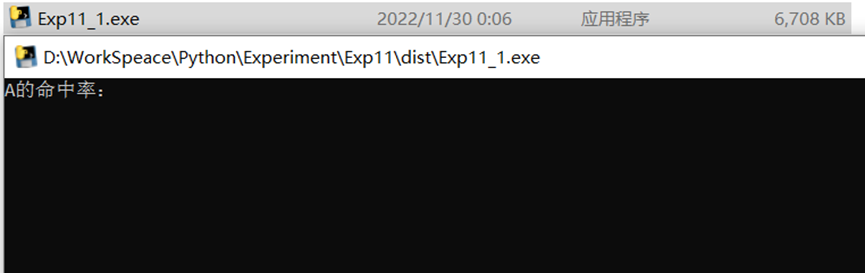
1.编写5名选手参与的篮球投篮模拟比赛,每场比赛中,每个选手投篮10个,命中多者获胜(可多人同时获胜),模拟1000次比赛,输出比赛结果分析报告。并打包成可执行的独立exe文件。
import random
def getInputs():
p={}
for i in 'ABCDE':
p[i]=eval(input(f"{i}的命中率:"))
n=eval(input("模拟次数:"))
return p,n
def oneGame(x):
hit=0
for i in range(10):
if random.random()<=x:
hit+=1
return hit
def simGames():
player={'A':0,'B':0,'C':0,'D':0,'E':0}
p,n=getInputs()
for n in range(n):
player = {i[0]:oneGame(p[i]) for i in player.keys()}
max_score=max(player.items(),key=lambda i:i[1])[1]
winner=[i for i in player.keys() if player[i]==max_score]
print('获胜的选手为:'+','.join(i for i in winner),end='')
simGames()安装pyinstaller库
输入如下命令:
![]()
生成可执行文件:
2.对政务报告进行词云分析,对无关的词进行删除,生成五角星词云。

import wordcloud
import jieba
from imageio.v2 import imread
with open('新时代中国特色社会主义.txt','r',encoding='utf-8') as f:
wc = wordcloud.WordCloud(mask=imread('red_star.png'),background_color='white',
font_path='msyh.ttc',width=1000,height=700)
wc.generate(' '.join(jieba.lcut(f.read())))
wc.to_file('report.png')ps:记得图片和文本的路径改为自己的
wordcloud的使用
import wordcloud # 导入wordcloud库
...
wc = wordcloud.WordCloud(参数1,参数2,...,参数n) # 创建并配置wordcloud对象
wc.generate(文本) # 加载wordcloud文本
wc.to_file('XXX.png') #生成图片WordCloud参数详解
font_path (string):字体路径,如:font_path='msyh.ttc'
width(int,default=400) :输出的画布宽度,默认为400像素
height(int,default=200):输出的画布高度,默认为200像素
mask(nd-array or None ,default=None): 如果参数为空,则使用二维遮罩绘制词云。如果 mask非空,设置的宽高值将被忽略,遮罩形状被 mask 取代
使用mask需使用imread()函数读取图片,imread()函数可以从许多地方导入,如cv2库,imageio库等
mask=imread('XXX.png')background_color(color value,default=”black”):背景颜色,如background_color='white',背景颜色为白色
wordcloud中的generate()
import wordcloud
txt ="life is short,you need python"
w=wordcloud.WordCloud(background_color="white")
w.generate(txt)
w.to_file("pywcloud.png")通过以上简单的案例说明generate()函数是使用空格来区分词语的,所以在生成中文的wordcloud应先使用jieba库并将词语间使用空格连接
with open('XXX.txt','r',encoding='utf-8') as f:
wc = wordcloud.WordCloud(...)
wc.generate(' '.join(jieba.lcut(f.read())))
wc.to_file('XXX.png')

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









