







物联网与大数据技术(Hadoop篇)
一.Hadoop简介
1.Hadoop介绍
Hadoop是由Apache旗下的开源的分布式计算平台,它可以运行在计算机集群之上,提供可靠的、可扩展的分布计算功能。
Hadoop的核心是分布式文件系统(HDFS)和并行编程框架MapReduce。
2.Hadoop诞生的关键论文
谷歌的三篇论文促进了Hadoop相关技术的发展,因此Doug Cutting开发了Hadoop,被成为“Hadoop之父”。
- 《The Google File System》
Hadoop的HDFS就是基于谷歌的GFS
- 《MapReduce:Simplified Data Process on Large Clusters》
MapReduce是一个分布式计算模型,是典型的“分治思想”。
- 《Bigtable:A Distributed Storage System for Structured Data》
Bigtable是一个管理 大规模结构化数据 而设计的分布式存储系统,可以扩展到PB级数据和上千台服务器。
值得注意的是,Bigtable不是关系型数据库,但是却沿用了很多关系型数据库的术语。
二.Hadoop发展史
- 2002年-2004年,以三大论文的发布向世界推送了其云计算的核心组成部分GFS、MapReduce以及Bigtable。
- 2006年1月,Doug Cutting 加入Yahoo,领导Hadoop的开发。Doug以他儿子的玩具飞象作为了Hadoop的图标,如下。

三.Hadoop特点
简称“四高一低”
- 高容错性
Hadoop文件系统对数据进行了备份,且具有纠错和恢复机制。当服务器故障导致数据出错可以恢复,并继续运行。 - 高扩展性
利用了计算机集群存储和计算,计算机集群可以任意增加计算机,极大地提高了算力。 - 高效性
- 高可靠性
- 低成本
可以运行在廉价的商用服务器上
四.Hadoop结构组成
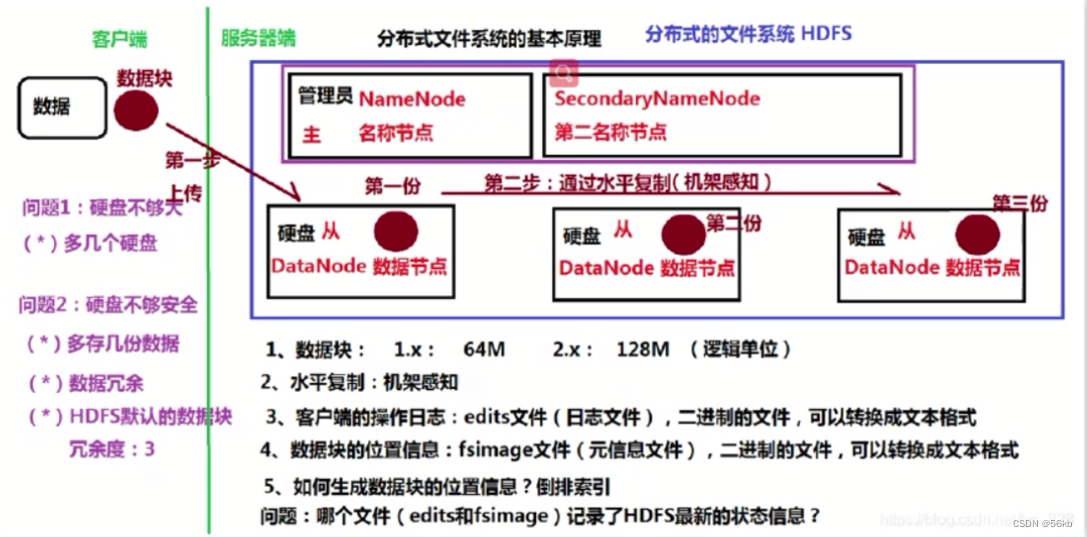
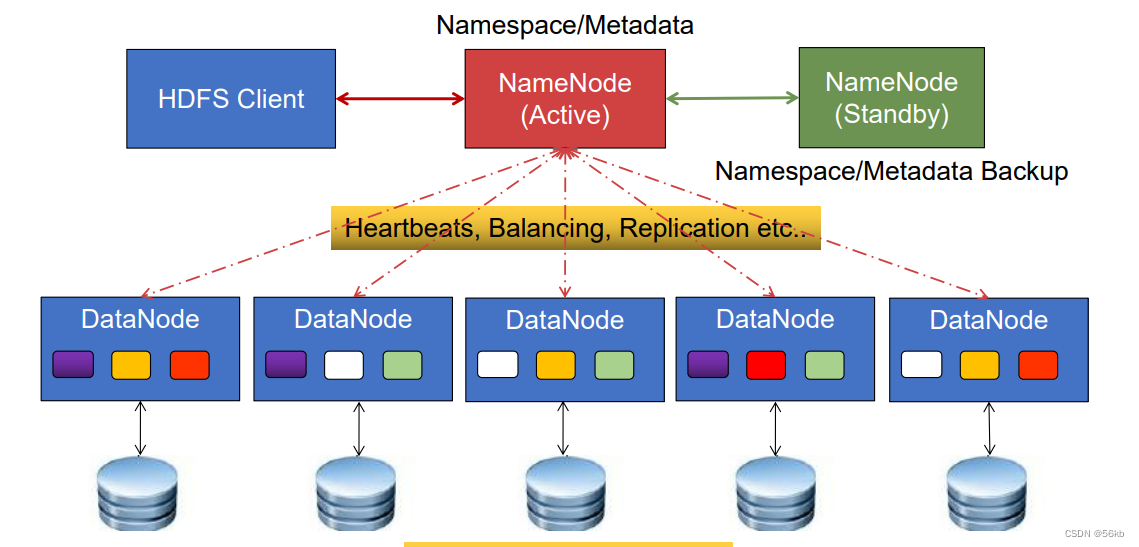
1.HDFS
- HDFS(Hadoop Distributed File System 分布式文件系统)对外部客户机而言,就像一个传统的分级文件系统,可以创建、删除、移动或重命名文件
等。 - HDFS体系结构
组成有Client、NameNode(Active、Stanby状态)、DataNode
- HDFS写入数据的流程
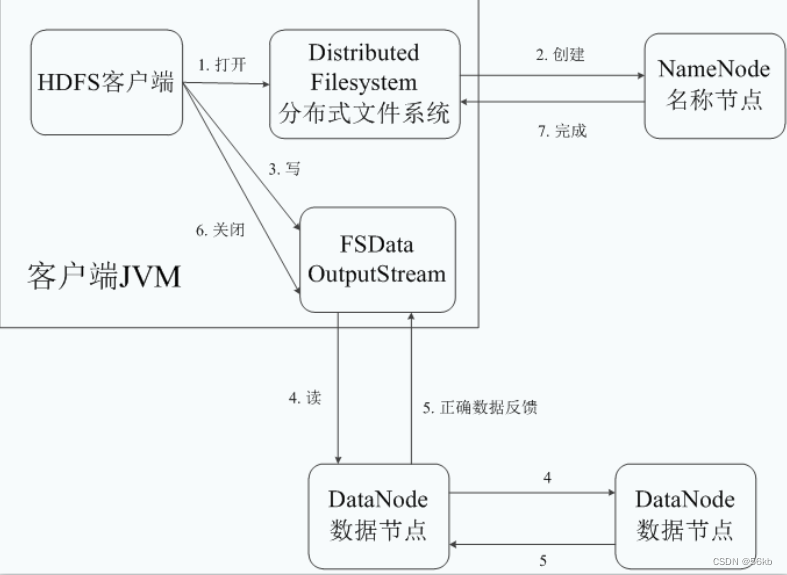
- HDFS读取数据的流程
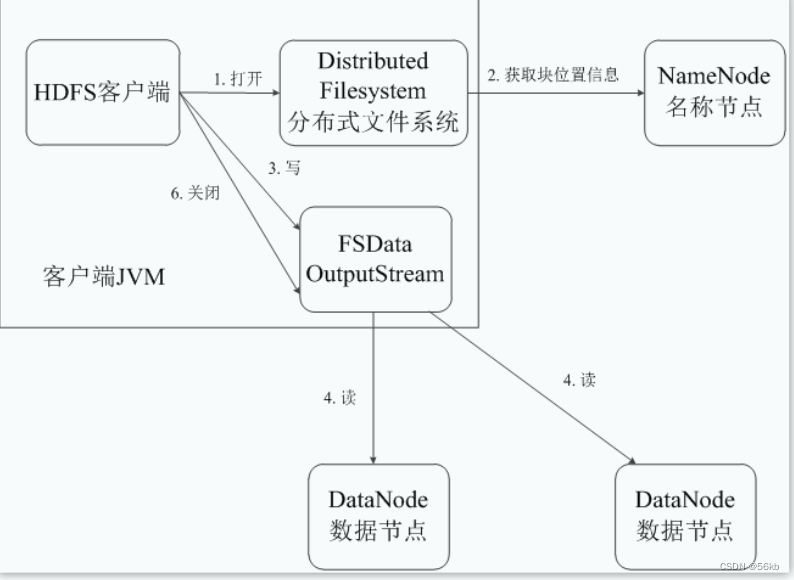
- HDFS的三个最常见的故障是:
- 名字节点故障
- 数据节点故障
- 网络断开
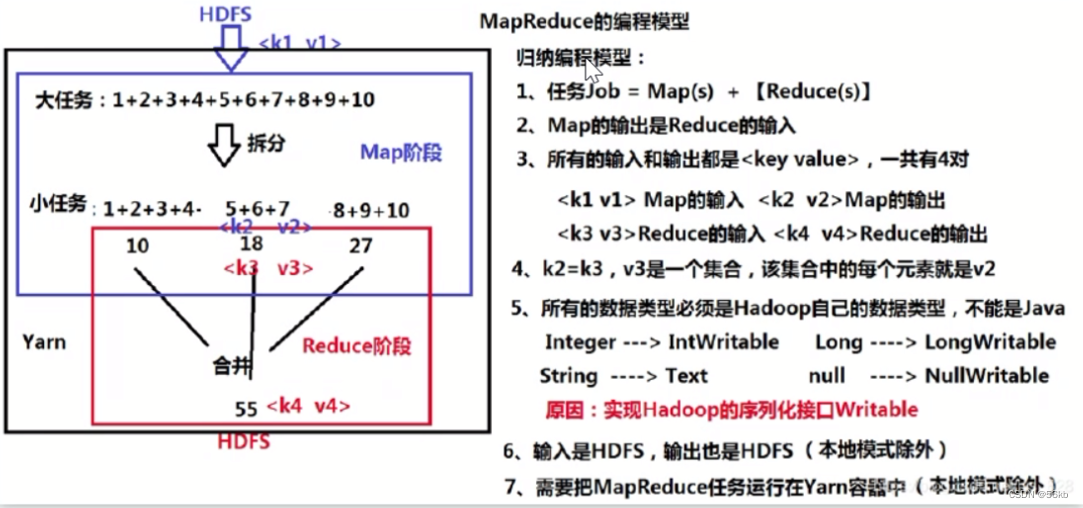
2.MapReduce
- MapReduce介绍MapReduce是Hadoop系统的核心组件,由Google的MapReduce系统经过演变而来,主要解决海量大数据计算的,也是众多分布式计算模型中比较流行的一种,可以单独使用,一般配合HDFS一起使用。MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。
- 体系结构
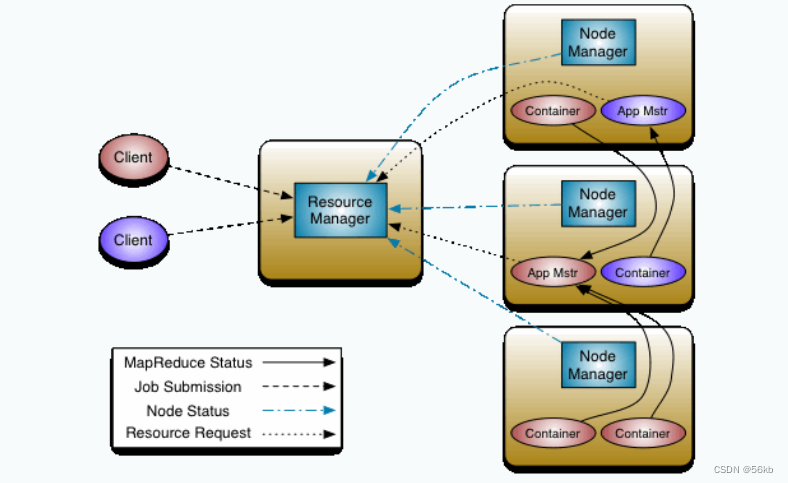
- 体系结构的组成
- MapReduce主要包含四个组成部分,分别为Client、ResourceManager(JobTracker)、NodeManager(TaskTracker), MRAppMaster。
- Client:用户可通过Client提供一些接口查看作业的运行状态
- ResourceManager:向Workers分发应用和配置,负责
资源监控和作业调度,向Client提供状态和诊断信息。 - NodeManager:会
周期性地通过Heartbeat将本节点上资源(CPU, 内存,磁盘,网络)的使用情况和任务的运行进度汇报给ResourceManager,同时接收ResourceManager发送过来的命令并执行相应的操作(如启动新任务、杀死任务等)。 - MRAppMaster: 按应用分配,用于和ResourceManager协商资源,和NodeManager执行并监督任务。
3.Task执行过程
- Map Task先将对应的split 迭代解析成一个个key/value 对,依次调用用户自定义的map() 函数进行处理,最终将临时结果存放到本地磁盘上, 其中临时数据被分成若干个partition,每个partition被一个Reduce Task 处理。
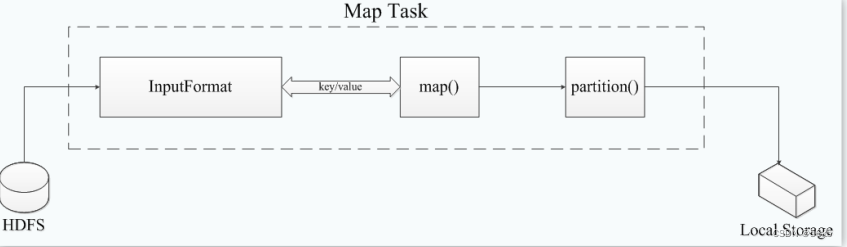
- Reduce Task执行过程分为三个阶段
- Shuffle阶段:从远程节点上读取Map Task中间结
果。 - Sort阶段:按照key对key/value 对进行排序。
- Reduce阶段:依次读取< key,value list>,调用用
户自定义的reduce() 函数处理,并将最终结果存到
HDFS上。
- Shuffle阶段:从远程节点上读取Map Task中间结
五.Hadoop环境搭建
1.配置Linux环境
- 首先,安装VMware虚拟机
- 在虚拟机中安装Linux环境(CentOs 7)
linux命令如下:

2.JDK安装和测试
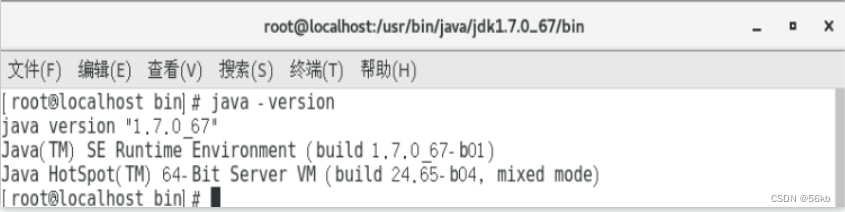
- 执行“java –version”进行JDK测试,结果如下:
3.Hadoop安装和配置
----步骤如下:----
- 解压hadoop压缩包
- 配置Hadoop环境变量
- 配置Yarn环境变量
- 配置核心组件文件
- 配置文件系统 6.
- 配置yarn-site.xml
- 配置MapReduce计算框架文件
- 配置Master的slaves文件
六.Hadoop关键组件
1.Hadoop生态
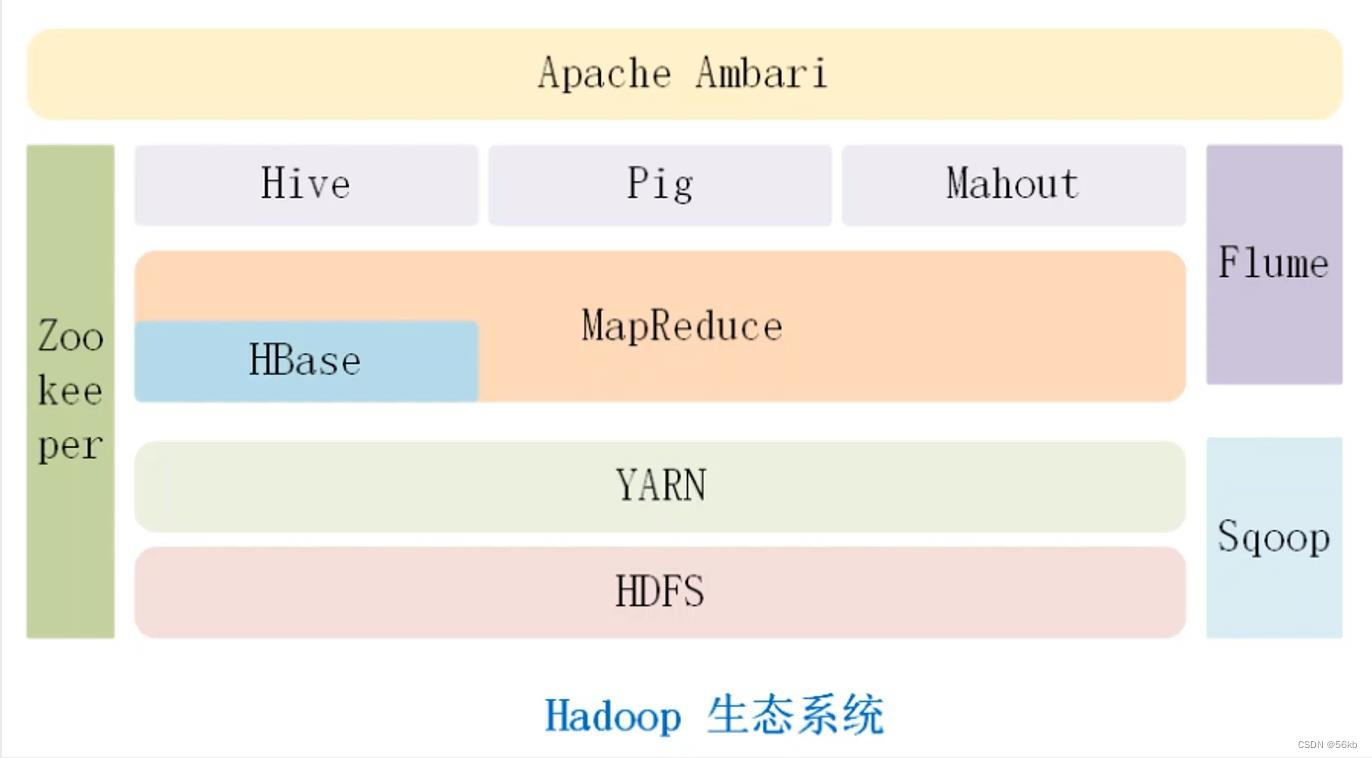
Hadoop体系结构最底层的是HDFS,它存储了Hadoop 集群中所有存储节点上的文件。HDFS的上一层是MapReduce引擎(计算模型),由 JobTrackers TaskTrackers 组成。除此之外,Hadoop体系结构还包括数据仓库Hive、数据流处理Pig、数据挖掘库Mahout和实时分布式数据库Hbase等。
2.组件介绍
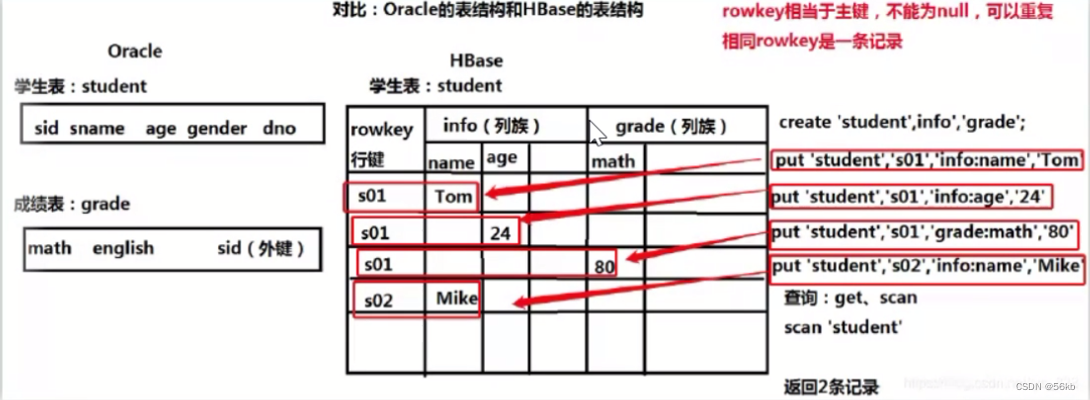
-
HBase
- HBase 是Hadoop Database的简称,是一个高可靠性、高性能、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
- Hbase利用Hadoop中的HDFS作为其文件存储系统,利用Hadoop的MapReduce来处理Hbase中的海量数据,利用ZooKeeper作为协调工具。

-
Hive
- Hive是基于Hadoop的一个
数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行,Hive在Hadoop之上提供了数据查询功能,主要解决非关系型数据查询问题。
- Hive是基于Hadoop的一个
-
Redis
- Redis是一种速度非常快的非关系数据库,支持存
储的 value 类型相对更多,并且支持各种不同方式
的排序,为了保存效率,数据都是缓存在内存中。
- Redis是一种速度非常快的非关系数据库,支持存
-
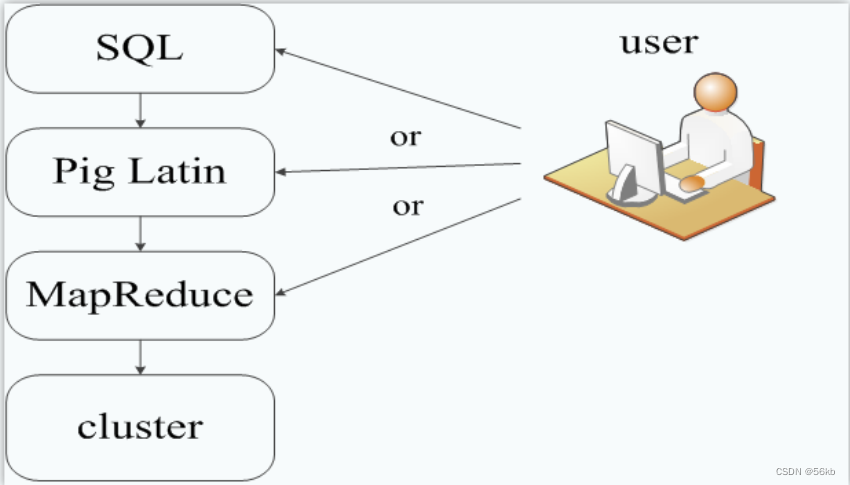
Pig
- Apache Pig是一个高级过程语言,适合于使用Hadoop和MapReduce平台来查询大型半结构化数据集。通过对分布式数据集进行类似SQL的查询,Pig可以简化Hadoop的使用
- Pig在数据处理中的位置如下
-
Mahout
- Mahout简单来说就是一个提供可扩展的
机器学习领域经典的算法库,旨在帮助开发人员更加方便快捷地创建智能应用程序。 - Mahout实现了聚类、分类、频繁项集挖掘等项目。通过使用Apache Hadoop库,Mahout可以有效地扩展到Hadoop集群或者扩展到云中。
- Mahout简单来说就是一个提供可扩展的
-
ZooKeeper
- ZooKeeper是一种为分布式应用所设计的高性能的
分步式协调管理组件,并提供数据同步服务,这样所有提出请求的客户端就可以得到一致的数据。 - 典型应用场景是数据发布/订阅、分步式协调/通知、集群管理等。
- 主要有配置管理、名字服务、分布式锁和
集群管理。配置管理指的是在一个地方修改了配置,那么对这个地方的配置感兴趣的所有的都可以获得变更,省去了手动拷贝配置的繁琐,还很好的保证了数据的可靠和一致性,同时它可以通过名字来获取资源或者服务的地址等信息,可以监控集群中机器的变化,实现了类似于心跳机制的功能。 - Zookeeper的工作架构
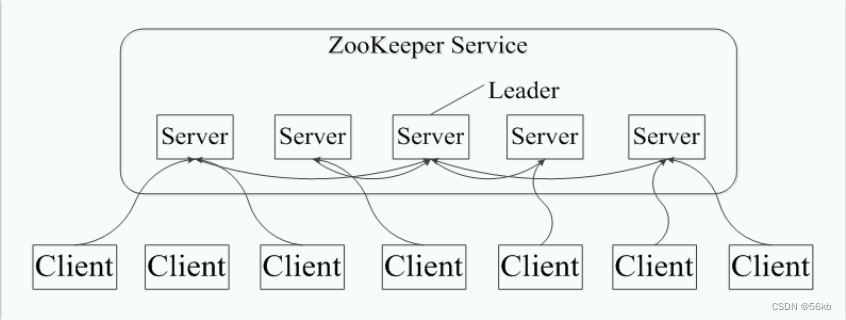
- ZooKeeper是一种为分布式应用所设计的高性能的
-
Kafka
- Kafka是一个高吞吐量的分步式、
基于发布/订阅的消息系统,可以处理消费者规模的网站中所有动作流数据。 - Kafka的设计理念之一就是同时提供离线处理和实时处理, 以及将数据实时备份到另一个数据中心。
- Kafka可以有许多的生产者和消费者分享多个主题,将消息以topic为单位进行归纳;Kafka发布消息的程序称producer,也叫生产者,预订topics并消费消息的程序称为consumer,也叫消费者;当Kafka以集群的方式运行时,可以由一个服务或者多个服务组成,每个服务叫做一个broker,运行过程中producer通过网络将消息发送到Kafka集群,集群向消费者提供消息。
- Kafka是一个高吞吐量的分步式、
-
Flume
- Flume是Cloudera提供的一个高可用的,高可靠的,分布式的
海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方的能力。
- Flume是Cloudera提供的一个高可用的,高可靠的,分布式的
-
Sqoop
- Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如MySQL 、Oracle 、Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。Sqoop专为大数据批量传输设计,能够分割数据集并创建Hadoop任务来处理每个区块。
- Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如MySQL 、Oracle 、Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。Sqoop专为大数据批量传输设计,能够分割数据集并创建Hadoop任务来处理每个区块。
-
Ambari
- Ambari是Hortonworks开源的Hadoop平台的
管理软件,具备Hadoop组件的安装、管理、运维等基本功能,提供Web UI进行可视化的集群管理,简化了大数据平台的安装、使用难度。Ambari通过HDP将Hadoop的组件进行集成,通过栈的形式提供Service的组合使用。
- Ambari是Hortonworks开源的Hadoop平台的
















 4009
4009











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











