









 超级会员免费看
超级会员免费看
问题分析:
在存在两个训练好的pt(模型文件)时,例如a.pt分类为:人,b.pt 分类为:猫,
如何在不混合数据集重新训练的情况下,对a.pt和b.pt中的人和猫共同检测?
解决办法:融合检测两个pt,优化性能,避免检测速度上的损失
1,融合pose.pt(姿态检测)+helmet.pt(安全帽佩戴检测)效果图
实时检测优化后FPS可达20+

2,原理介绍
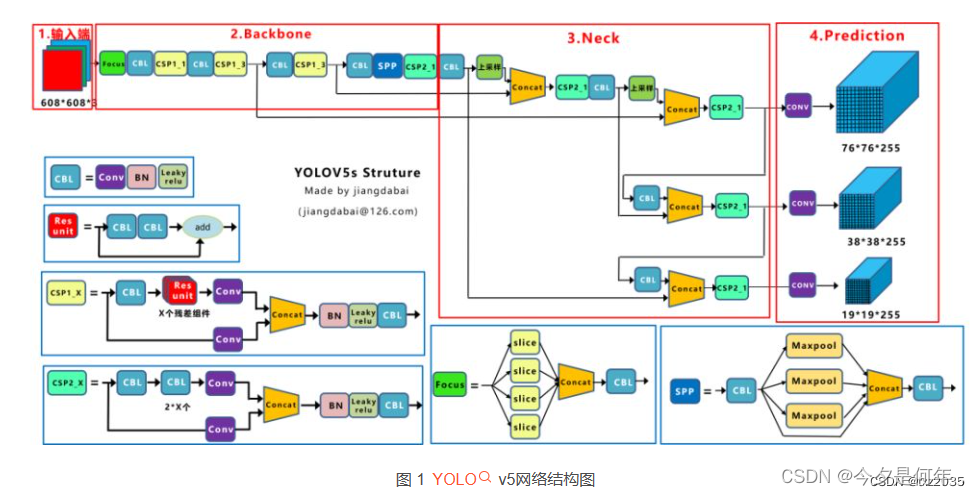
YOLOv5是目前应用广泛的目标检测算法之一,其主要结构分为两个部分:骨干网络和检测头。
输入(Input): YOLOv5的输入是一张RGB图像,它可以具有不同的分辨率,但通常为416x416或512x512像素。这些图像被预处理和缩放为神经网络的输入大小。在训练过程中,可以使用数据增强技术对图像进行随机裁剪、缩放和翻转等操作,以增加数据的丰富性和多样性。
Bac

 订阅专栏 解锁全文
订阅专栏 解锁全文
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









