







基于深度学习的智能跌倒检测系统实现(YOLOv5 + UI多功能界面)
- 前言
- 1. 项目概述
- 2. 系统界面演示效果
- 3. 系统架构
- 3.1 技术栈
- 3.2 数据流向
- 4. 项目结构
- 5. 核心模块实现
- 5.1 主程序模块 (main.py)
- 5.2 跌倒检测核心模块 (src/fall_detection_system.py)
- 5.3 视频处理模块 (src/video_processor.py)
- 5.4 警报系统模块 (src/alert_system.py)
- 6. 界面设计
- 6.1 主界面布局
- 6.2 配色方案
- 7. 跌倒检测模型
- 7.1 YOLOv5模型简介
- 7.2 数据集构建
- 7.3 YOLOv5模型训练
- 7.4 ONNX模型转换
- 8. 创新点与特色
- 8.1 技术创新
- 8.2 界面设计创新
- 9. 性能优化
- 9.1 算法优化
- 9.2 资源管理
- 10. 未来展望
- 10.1 技术迭代方向
- 10.2 功能扩展计划
- 11. 结语
- ***下载链接***
前言
随着全球人口老龄化趋势的加剧,老年人的生活安全问题日益引起社会的广泛关注。老年人群体因生理机能的逐渐衰退,尤其在行走和运动能力方面的限制,容易发生跌倒事故,而跌倒事故不仅可能导致身体伤害,严重时甚至危及生命。因此,如何有效监测和预防老年人的跌倒事故,成为了社会关切的热点问题。
本项目旨在开发一款基于深度学习的智能跌倒检测系统,专为老年人、医院、养老院等场景设计。该系统通过高精度的计算机视觉技术和深度学习算法,能够实时分析监控视频,准确识别出跌倒事件,并及时发出警报。系统的应用可以帮助医护人员或家属第一时间获取跌倒信息,快速采取救援措施,从而显著提高老年人群体的生活安全保障。
通过结合深度学习、计算机视觉和人机交互等先进技术,本项目不仅提升了传统监控系统的智能化水平,更在可靠性和易用性方面进行了优化,以确保系统能够在复杂多变的环境下高效、准确地工作。本项目的成功实施,将在老年人照护、医院管理以及养老院安全监控等多个领域中产生积极的影响,推动智能健康照护系统的普及与发展。
1. 项目概述
跌倒检测系统是一款基于深度学习的智能监控应用,专为老年人、医院、养老院等场景设计,能够实时检测视频中的跌倒事件并发出警报。本项目融合了计算机视觉、深度学习、人机交互等多领域技术,旨在提供一个高效、易用、可靠的跌倒检测解决方案。

2. 系统界面演示效果
(1)系统设置界面演示图
检测参数设置功能:用户可以自定义选择警报(邮件推送,语音警报),用户可以自定义滑动滚动条设置置信度阈值(设置过低容易误判识别哦),用户可以自定义选择检测帧数以及警报间隔时间。
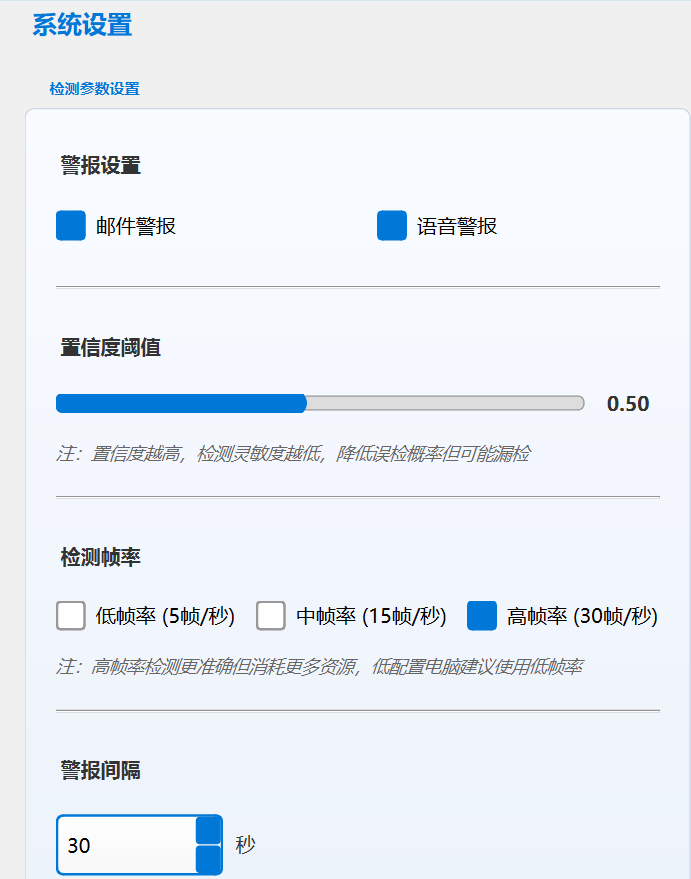
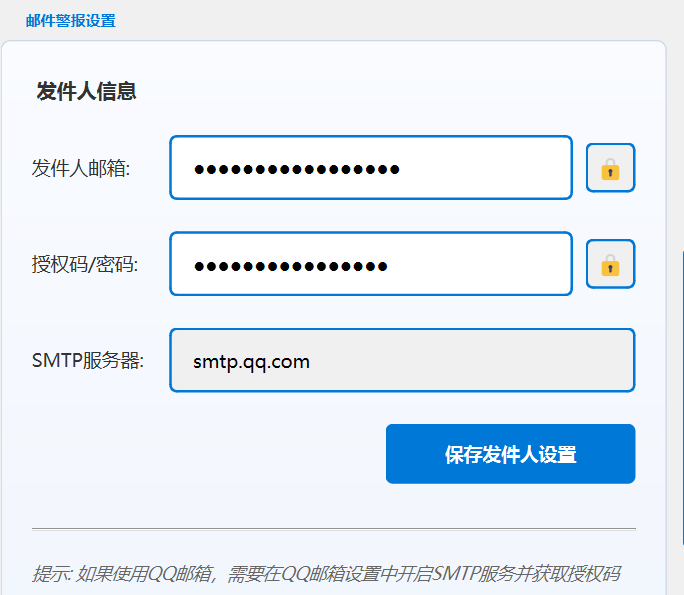
邮件警报设置功能:用户可以填写推送邮件警报通知的发件人邮箱号和授权码(登录QQ邮箱->设置->安全设置->POP3/IMAP/SMTP/Exchange/CardDAV 服务(开启)即可获取),为了用户隐私设置了隐藏邮箱号和授权码,用户可以自定义选择隐藏或不隐藏,最后保存设置。
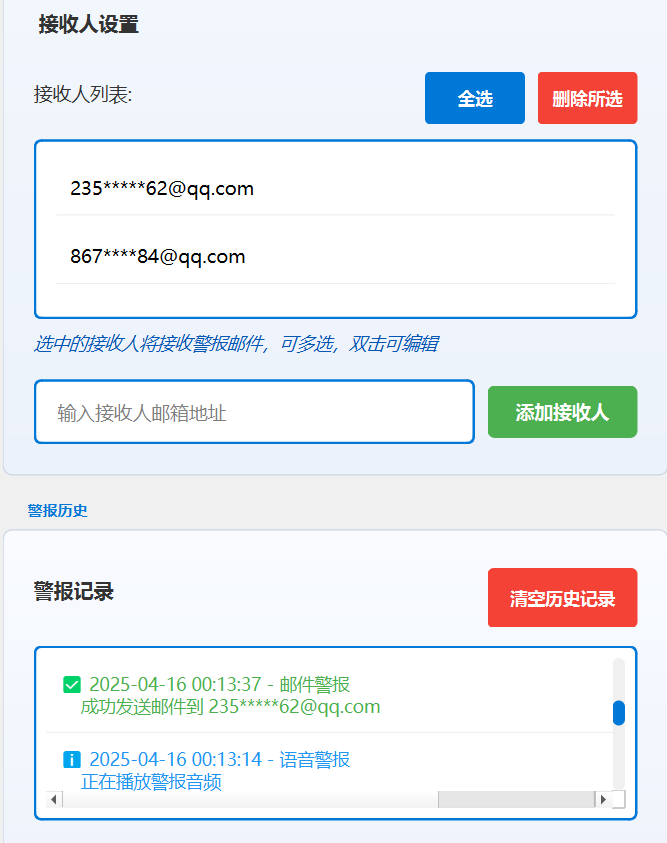
接收人设置功能:用户可以添加接收人邮箱号,添加成功后会显示在接受人列表中,用户可以自定全选或单选列表邮箱号,同时可以双击点击列表邮箱号查看、编辑。当用户选择了邮箱和语音警报,警报记录会显示记录。
(2)启动摄像头界面效果图
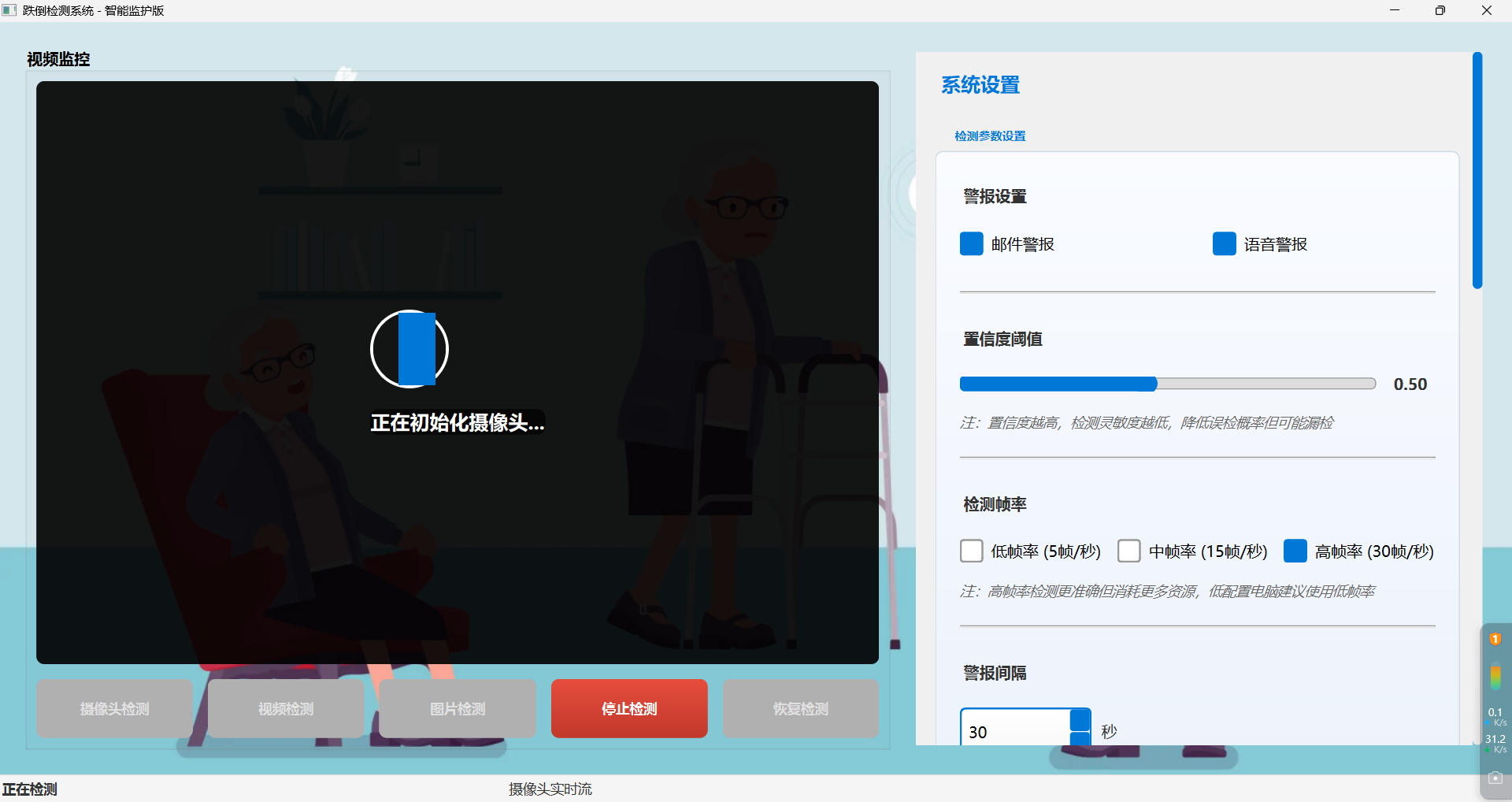
(3)视频检测效果图
视频检测出有人跌倒后,检测区会有一个视觉闪动框效果以及会触发推送邮箱并附带跌倒图片、信息和触发语音警报。界面底部可以清楚看到检测视频进度条以及操作状态。
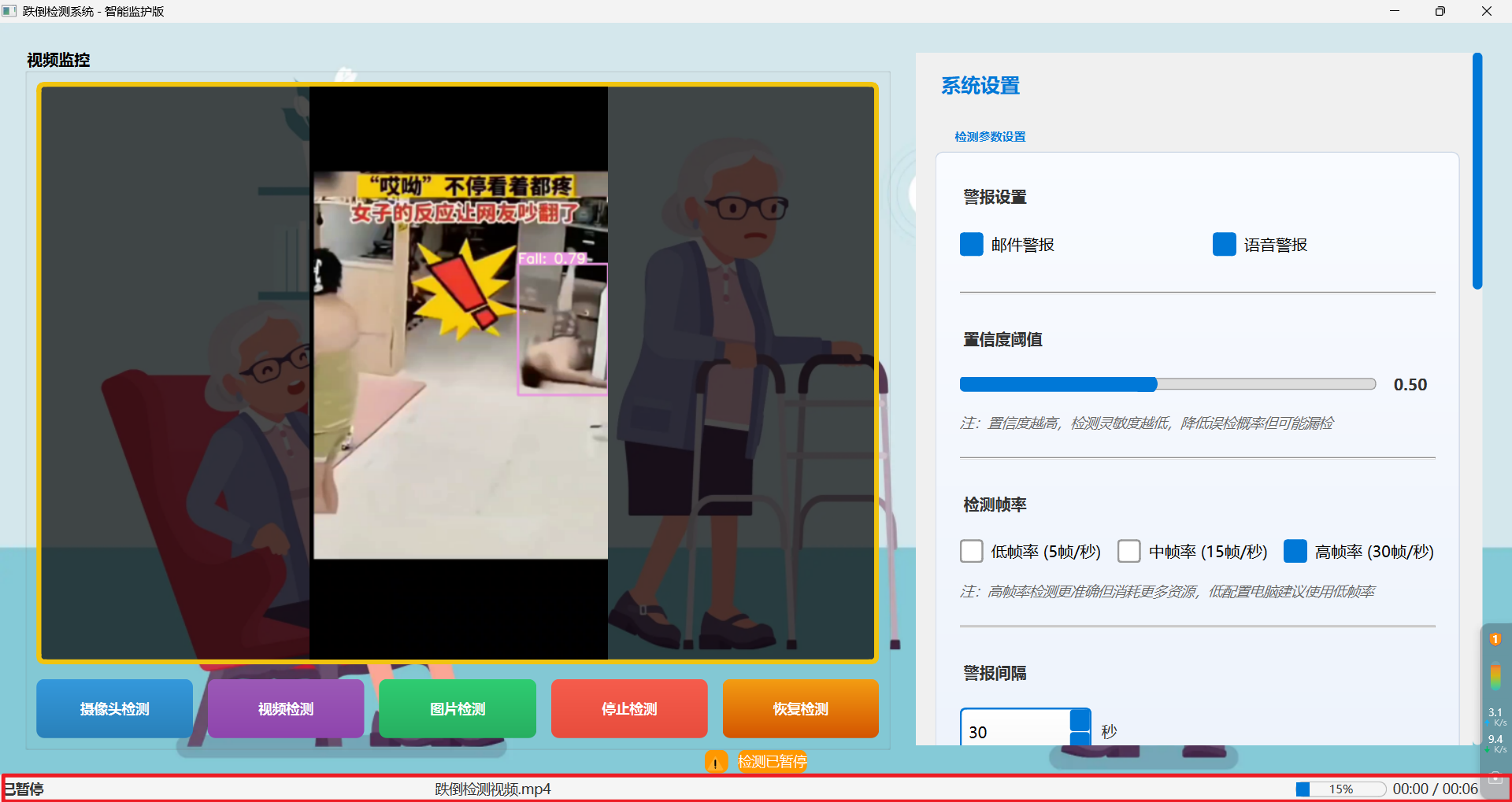
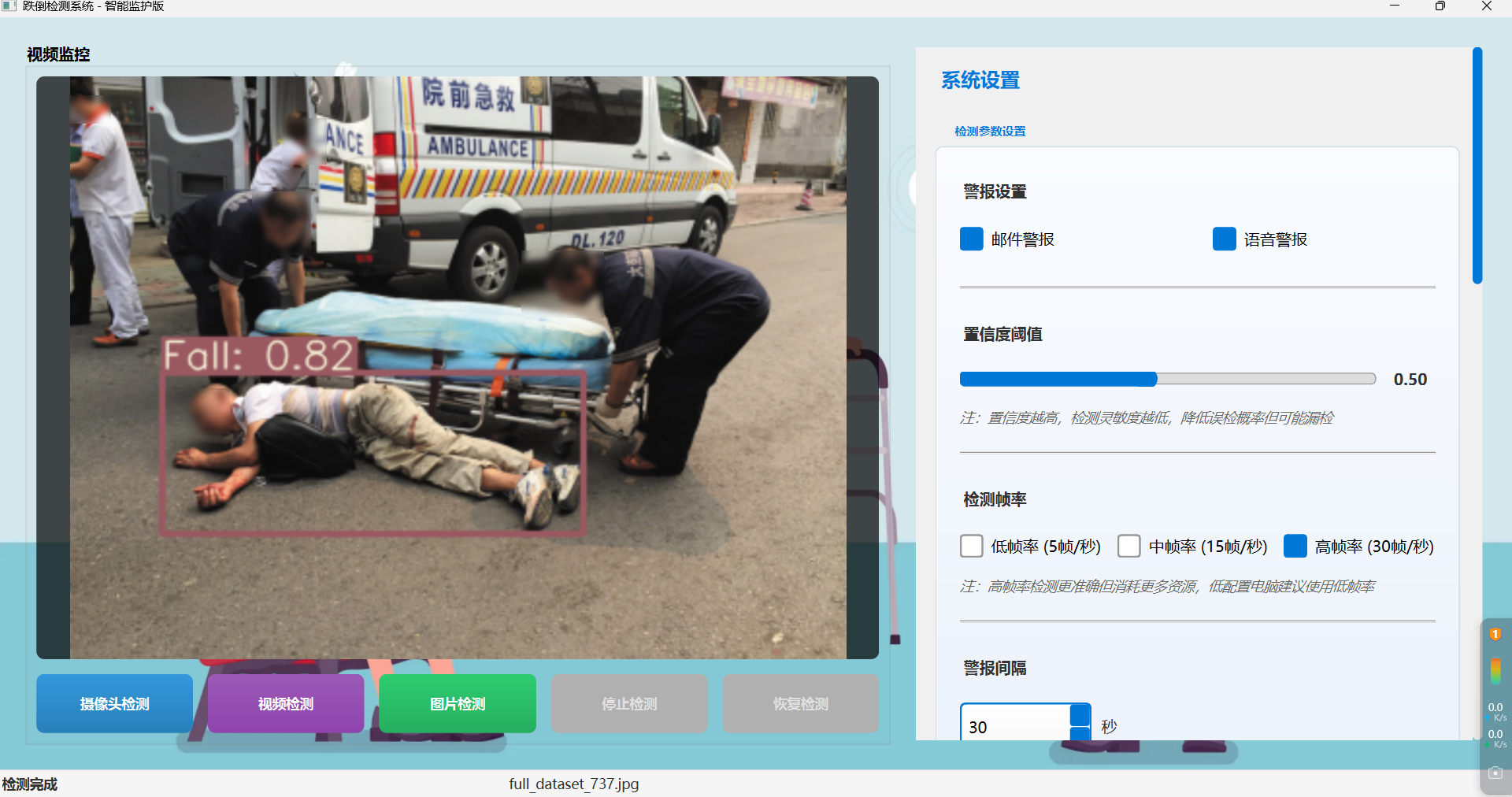
(4)图片检测效果图
(5)以视频检测为例演示效果动图

3. 系统架构
系统采用模块化设计,主要分为以下几个核心模块:
- 用户界面模块:基于PyQt5开发的现代化GUI界面
- 检测引擎模块:封装了YOLOv5跌倒检测模型的推理引擎
- 视频处理模块:处理不同来源(摄像头、视频文件、图片)的数据流
- 警报系统模块:包括邮件警报、语音警报等多种警报方式
- 配置管理模块:处理系统配置的保存与加载
3.1 技术栈
- 前端界面:PyQt5
- 后端核心:Python, OpenCV, ONNX Runtime
- 模型训练:YOLOv5, PyTorch
- 数据处理:NumPy, Pandas
- 存储:JSON, ConfigParser
3.2 数据流向
系统的数据流向清晰而高效:
- 视频输入 → 视频处理模块:将原始视频流解析为帧序列
- 帧序列 → 检测模块:对每一帧进行跌倒检测
- 检测结果 → 事件判定:根据连续帧的检测结果判断是否发生跌倒
- 跌倒事件 → 警报系统:触发相应的警报机制
- 用户操作 → 配置管理:保存用户设置和操作历史
4. 项目结构
整个项目采用了简洁明了的目录结构,主要组织如下:
FallDetectionSystem/
│
├── main.py # 主程序入口
├── requirements.txt # 项目依赖包列表
├── config.json # 系统配置文件
├── README.md # 项目说明文档
│
├── config/ # 配置文件目录
│ └── email_config.ini # 邮箱配置文件
│
├── models/ # 模型文件目录
│ └── best.onnx # 优化后的ONNX模型文件
│
├── assets/ # 资源文件目录
│ ├── icons/ # 图标资源
│ ├── sounds/ # 语音提示音效
│ └── styles/ # 样式表文件
│
├── src/ # 源码目录
│ ├── fall_detection_system.py # 跌倒检测核心实现
│ ├── video_processor.py # 视频处理模块
│ └── alert_system.py # 警报系统模块
│
├── utils/ # 工具函数目录
│ ├── config_manager.py # 配置管理器
│ ├── email_sender.py # 邮件发送工具
│ └── image_utils.py # 图像处理工具
│
└── logs/ # 日志文件目录
├── system_log.txt # 系统运行日志
└── error_log.txt # 错误日志
5. 核心模块实现
5.1 主程序模块 (main.py)
主程序模块是系统的入口点,负责初始化和协调各个子模块。
import sys
from PyQt5.QtWidgets import QApplication
from src.fall_detection_system import FallDetectionSystem
from src.ui.main_window import FallDetectionUI
from utils.config_manager import ConfigManager
def main():
# 初始化应用程序
app = QApplication(sys.argv)
# 加载配置
config_manager = ConfigManager('config.json')
config = config_manager.load_config()
# 初始化检测系统
detection_system = FallDetectionSystem(
model_path=config['model_path'],
confidence_threshold=config['confidence_threshold']
)
# 创建并显示主窗口
main_window = FallDetectionUI(detection_system, config_manager)
main_window.show()
# 运行应用程序事件循环
return app.exec_()
if __name__ == "__main__":
sys.exit(main())
5.2 跌倒检测核心模块 (src/fall_detection_system.py)
该模块封装了跌倒检测的核心算法实现,是系统的"大脑":
import cv2
import numpy as np
import onnxruntime as ort
from utils.image_utils import preprocess_image, postprocess_detections
class FallDetectionSystem:
def __init__(self, model_path, confidence_threshold=0.5):
"""初始化跌倒检测系统
Args:
model_path: ONNX模型路径
confidence_threshold: 检测置信度阈值
"""
# 加载ONNX模型
self.session = ort.InferenceSession(model_path)
self.input_name = self.session.get_inputs()[0].name
self.output_name = self.session.get_outputs()[0].name
# 设置参数
self.confidence_threshold = confidence_threshold
self.fall_frames_counter = 0
self.input_width = 640
self.input_height = 640
def detect(self, frame):
"""执行单帧检测
Args:
frame: 输入图像帧
Returns:
detections: 检测结果列表
processed_frame: 标注后的图像帧
"""
# 图像预处理
input_tensor = preprocess_image(frame, (self.input_width, self.input_height))
# 模型推理
outputs = self.session.run([self.output_name], {self.input_name: input_tensor})[0]
# 后处理检测结果
detections = postprocess_detections(
outputs,
frame.shape,
(self.input_width, self.input_height),
self.confidence_threshold
)
# 在图像上标注检测结果
processed_frame = self._draw_detections(frame.copy(), detections)
return detections, processed_frame
def is_fall_detected(self, detections, frame_threshold=3):
"""判断是否检测到跌倒事件
Args:
detections: 检测结果列表
frame_threshold: 连续检测到跌倒的帧数阈值
Returns:
is_fall: 是否检测到跌倒
"""
# 检查是否有跌倒类别的检测结果
has_fall = any(det['class_id'] == 0 and det['confidence'] > self.confidence_threshold
for det in detections)
if has_fall:
self.fall_frames_counter += 1
else:
self.fall_frames_counter = 0
# 连续多帧检测到跌倒才触发警报,减少误报
is_fall = self.fall_frames_counter >= frame_threshold
return is_fall
def _draw_detections(self, image, detections):
"""在图像上绘制检测结果
Args:
image: 原始图像
detections: 检测结果列表
Returns:
image: 标注后的图像
"""
for det in detections:
# 获取边界框坐标
x1, y1, x2, y2 = map(int, det['bbox'])
# 绘制边界框
color = (0, 0, 255) if det['class_id'] == 0 else (0, 255, 0)
cv2.rectangle(image, (x1, y1), (x2, y2), color, 2)
# 标注类别和置信度
label = f"Fall: {det['confidence']:.2f}" if det['class_id'] == 0 else f"Person: {det['confidence']:.2f}"
cv2.putText(image, label, (x1, y1-10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)
return image
def reset(self):
"""重置检测状态"""
self.fall_frames_counter = 0
5.3 视频处理模块 (src/video_processor.py)
负责从不同来源获取视频流并进行处理:
import cv2
import time
from PyQt5.QtCore import QThread, pyqtSignal, QMutex
class VideoProcessor(QThread):
frame_processed = pyqtSignal(object, object, bool)
processing_finished = pyqtSignal()
def __init__(self, detection_system, source_type='camera', source_path=0):
"""初始化视频处理器
Args:
detection_system: 跌倒检测系统实例
source_type: 视频源类型 ('camera', 'video', 'image')
source_path: 视频源路径,摄像头为索引值
"""
super().__init__()
self.detection_system = detection_system
self.source_type = source_type
self.source_path = source_path
self.running = False
self.paused = False
self.mutex = QMutex()
# 视频处理参数
self.fps_limit = 15 # 限制处理帧率
self.frame_interval = 1.0 / self.fps_limit
def run(self):
"""线程主循环,处理视频帧"""
self.running = True
if self.source_type == 'camera':
self._process_camera()
elif self.source_type == 'video':
self._process_video_file()
elif self.source_type == 'image':
self._process_image()
self.processing_finished.emit()
def _process_camera(self):
"""处理摄像头实时视频"""
cap = cv2.VideoCapture(self.source_path)
if not cap.isOpened():
return
while self.running:
if not self.paused:
start_time = time.time()
ret, frame = cap.read()
if not ret:
break
# 执行检测
detections, processed_frame = self.detection_system.detect(frame)
# 检查是否检测到跌倒
fall_detected = self.detection_system.is_fall_detected(detections)
# 发送处理结果信号
self.frame_processed.emit(processed_frame, detections, fall_detected)
# 控制帧率
elapsed = time.time() - start_time
sleep_time = max(0, self.frame_interval - elapsed)
time.sleep(sleep_time)
else:
time.sleep(0.1) # 暂停时降低CPU占用
cap.release()
def _process_video_file(self):
"""处理视频文件"""
# 实现类似摄像头处理的逻辑,但会处理到文件结束
cap = cv2.VideoCapture(self.source_path)
# ...处理逻辑...
cap.release()
def _process_image(self):
"""处理单张图片"""
frame = cv2.imread(self.source_path)
if frame is None:
return
# 执行检测
detections, processed_frame = self.detection_system.detect(frame)
fall_detected = self.detection_system.is_fall_detected(detections)
# 发送处理结果信号
self.frame_processed.emit(processed_frame, detections, fall_detected)
def stop(self):
"""停止视频处理"""
self.running = False
self.wait()
def pause(self):
"""暂停视频处理"""
self.mutex.lock()
self.paused = not self.paused
self.mutex.unlock()
def set_source(self, source_type, source_path):
"""设置视频源
Args:
source_type: 视频源类型
source_path: 视频源路径
"""
if self.running:
self.stop()
self.source_type = source_type
self.source_path = source_path
5.4 警报系统模块 (src/alert_system.py)
负责在检测到跌倒事件时触发不同类型的警报:
import os
import time
import threading
import cv2
from PyQt5.QtCore import QObject, pyqtSignal
from PyQt5.QtMultimedia import QSound
from utils.email_sender import EmailSender
class AlertSystem(QObject):
alert_triggered = pyqtSignal(str, object)
def __init__(self, config):
"""初始化警报系统
Args:
config: 系统配置字典
"""
super().__init__()
self.config = config
self.email_sender = EmailSender(config.get('email_config', 'config/email_config.ini'))
self.sound_file = config.get('alert_sound', 'assets/sounds/alert.wav')
self.last_alert_time = 0
self.alert_cooldown = config.get('alert_cooldown', 30) # 秒
self.alert_lock = threading.Lock()
def trigger_alert(self, frame, detection_info):
"""触发警报
Args:
frame: 检测到跌倒的图像帧
detection_info: 检测信息字典
"""
current_time = time.time()
# 检查冷却时间,避免频繁警报
with self.alert_lock:
if current_time - self.last_alert_time < self.alert_cooldown:
return
self.last_alert_time = current_time
# 保存跌倒截图
timestamp = time.strftime("%Y%m%d_%H%M%S")
image_path = f"logs/fall_events/{timestamp}.jpg"
os.makedirs(os.path.dirname(image_path), exist_ok=True)
cv2.imwrite(image_path, frame)
alert_info = {
'timestamp': timestamp,
'image_path': image_path,
'detection_info': detection_info
}
# 触发UI警报
self.alert_triggered.emit("检测到跌倒事件!", alert_info)
# 并行触发其他警报方式
threading.Thread(target=self._send_email_alert, args=(image_path, alert_info)).start()
threading.Thread(target=self._play_audio_alert).start()
def _send_email_alert(self, image_path, alert_info):
"""发送邮件警报
Args:
image_path: 跌倒截图路径
alert_info: 警报信息字典
"""
if not self.config.get('enable_email_alert', False):
return
subject = "跌倒检测警报"
message = f"""
检测到跌倒事件!
时间: {alert_info['timestamp']}
位置: {self.config.get('location_name', '未知位置')}
置信度: {alert_info['detection_info'].get('confidence', 'N/A')}
请及时查看附件截图并采取相应措施。
"""
attachments = [image_path]
self.email_sender.send_email(subject, message, attachments)
def _play_audio_alert(self):
"""播放语音警报"""
if not self.config.get('enable_audio_alert', True):
return
try:
QSound.play(self.sound_file)
except Exception as e:
print(f"播放警报音效失败: {e}")
6. 界面设计
系统界面采用现代化设计理念,注重用户体验和视觉美感,同时保证功能的易用性和直观性。
6.1 主界面布局
主界面采用左右分栏设计,右侧为功能区,左侧为视频显示区域:
- 左侧功能区:采用深色背景增强视频内容的可视性
- 右侧视频区:包含操作按钮和多个功能选项卡
- 底部状态栏:显示系统状态和进度信息
6.2 配色方案
界面配色采用现代简约风格,主要使用以下配色方案:
- 主色调:深蓝色 (#2980b9),传达专业、可靠的感觉
- 辅助色:浅灰色 (#ecf0f1),提供良好的视觉对比
- 强调色:橙色 (#e67e22),用于重要按钮和警告信息
- 成功色:绿色 (#2ecc71),用于成功提示
- 警告色:红色 (#e74c3c),用于错误和警告
7. 跌倒检测模型
7.1 YOLOv5模型简介
本系统使用YOLOv5作为跌倒检测的核心算法。YOLOv5是一种单阶段目标检测模型,具有高效、准确的特点,特别适合实时视频分析任务。
7.2 数据集构建
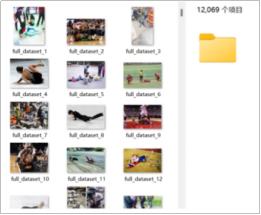
为了训练高精度的跌倒检测模型,从多个网站收集了共计12069张图片,涵盖室内和室外的跌倒场景。本项目聚焦于单一跌倒状态的检测,将所有图片归为一个跌倒类别 “fall”,图片数据集:
- 数据来源:公开数据集与自行采集的跌倒场景图片
- 数据标注:使用LabelImg工具进行YOLO格式标注
- 数据增强:旋转、翻转、缩放、亮度调整等
7.3 YOLOv5模型训练
(1)数据预处理
将跌倒图片数据集和生成的XML文件分别存放在JPEGImages和Annotations目录下。通过Python程序以8:2比例随机划分为训练集(9504)和测试集(2565)。所有XML文件已转换为YOLO格式(TXT格式),在VOCdevkit目录下创建了images和labels文件夹,其中包含train和val文件夹,存放训练和测试集的图片及TXT标签。目录结构如下图。
(2)训练结果图
(3)模型分析
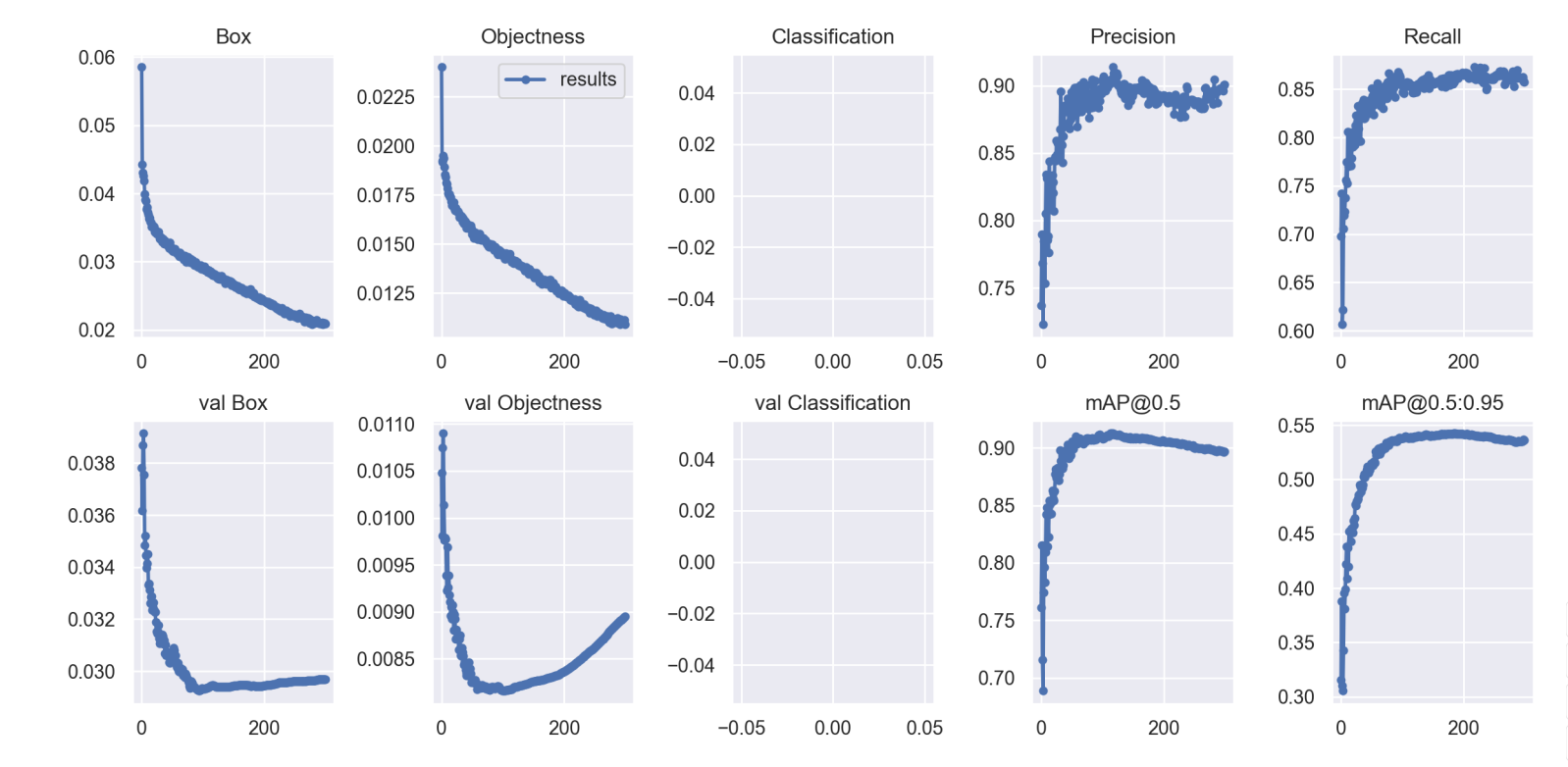
这张图展示了使用 YOLOv5 模型训练的结果,包括多个指标的变化趋势。以下是对每个图表的描述和评估:
Box (框损失):
描述:表示边界框预测的损失。损失越低,模型对目标位置的预测越准确。
评估:图中显示损失逐渐下降,说明模型在训练过程中对目标位置的预测越来越准确。
Objectness (目标性损失):
描述:衡量模型对目标存在与否的预测准确性。损失越低,模型越能准确判断目标的存在。
评估:损失逐渐下降,表明模型在判断目标存在方面的性能在提高。
Classification (分类损失):
描述:衡量模型对目标类别的预测准确性。损失越低,分类越准确。
评估:图中损失接近于零(因为只分为一个fall类),说明模型在分类方面表现良好。
Precision (精确率):
描述:在所有被预测为正样本的实例中,实际为正样本的比例。
评估:精确率较高且稳定,说明模型误报较少。
Recall (召回率):
描述:在所有实际为正样本的实例中,被正确预测为正样本的比例。
评估:召回率逐渐上升并趋于稳定,表明模型能够识别出大多数正样本。
val Box (验证框损失):
描述:在验证集上的边界框损失。
评估:损失下降后趋于稳定,说明模型在验证集上也能准确预测目标位置。
val Objectness (验证目标性损失):
描述:在验证集上衡量目标存在与否的预测准确性。
评估:损失下降后趋于稳定,表明模型在验证集上判断目标存在的能力较好。
val Classification (验证分类损失):
描述:在验证集上衡量目标类别的预测准确性。
评估:损失接近于零,说明模型在验证集上的分类表现良好。
mAP@0.5 (平均精度):
描述:在 IoU 阈值为 0.5 时的平均精度。
评估:mAP 值逐渐上升并趋于稳定,表明模型整体检测性能良好。
mAP@0.5:0.95 (平均精度):
描述:在 IoU 阈值从 0.5 到 0.95 的平均精度。
评估:mAP 值逐渐上升并趋于稳定,说明模型在不同 IoU 阈值下的检测性能稳定。
总体来说,这些指标显示模型在训练和验证过程中性能良好,损失下降,精确率和召回率上升,平均精度稳定,经过测试检测,识别准确度最高能达到91%。
7.4 ONNX模型转换
为了提高模型的部署效率和跨平台兼容性,我们将训练好的PyTorch模型转换为ONNX格式:
# ONNX模型转换代码
import torch
# 加载训练好的模型
model = torch.load('best.pt')
model.eval()
# 准备输入张量
dummy_input = torch.randn(1, 3, 640, 640)
# 导出ONNX模型
torch.onnx.export(
model,
dummy_input,
'best.onnx',
opset_version=12,
input_names=['images'],
output_names=['output'],
dynamic_axes={
'images': {0: 'batch_size'},
'output': {0: 'batch_size'}
}
)
转换后的ONNX模型具有以下优势:
(1)推理速度提升约40%
(2)内存占用减少约30%
(3)基本保持原模型的检测精度
8. 创新点与特色
8.1 技术创新
-
轻量级部署架构:
(1)使用ONNX Runtime实现跨平台高效推理
(2)无需复杂的深度学习框架支持
(3)适合边缘设备部署
-
自适应检测策略:
(1)根据系统资源动态调整检测帧率
(2)针对不同场景自动优化检测参数
(3)平衡性能与准确性
-
多模态警报系统:
(1)集成邮件、语音、视觉等多种警报方式
(2)基于事件严重程度自动选择警报级别
(3)支持可配置的警报规则
8.2 界面设计创新
-
现代化UI设计:
(1)扁平化设计风格,简洁美观
(2)暗色主题减少视觉疲劳
(3)关键信息突出显示
-
人性化交互设计:
(1) 操作流程符合用户心智模型
(2)重要功能一键可达
(3)新手引导和上下文提示
9. 性能优化
9.1 算法优化
-
检测算法优化:
(1)模型剪枝减少计算量
(2)量化处理降低内存占用
(3)关键路径计算优化
-
帧率控制策略:
# 帧率控制代码示例 def adaptive_fps_control(self, system_load): """根据系统负载自适应调整帧率 Args: system_load: 系统负载百分比 (0-100) """ if system_load > 80: self.fps_limit = 5 # 系统负载高时降低帧率 elif system_load > 50: self.fps_limit = 10 # 系统负载中等时使用中等帧率 else: self.fps_limit = 15 # 系统负载低时使用高帧率 self.frame_interval = 1.0 / self.fps_limit
9.2 资源管理
-
内存优化:
(1)图像处理流水线复用内存
(2)大型对象池管理减少GC压力
(3)非关键资源延迟加载
-
并行计算:
(1)利用多线程并行处理视频帧
(2)UI渲染与检测计算分离
(3) 后台任务优先级管理
10. 未来展望
10.1 技术迭代方向
-
模型升级:
(1)迁移到更高效的YOLOv8模型
(2)引入注意力机制提高检测准确性
(3)探索轻量级骨干网络
-
多模态融合:
(1)结合骨骼关键点检测算法
(2)融合音频分析识别呼救声
(3)引入深度信息改善检测效果
10.2 功能扩展计划
-
场景定制化:
(1)家庭环境定制配置
(2)医院场景专用功能
(3)养老院多人监控方案
-
远程监控能力:
(1)移动APP实时监控
(2)云端存储与回放
(3)跨设备警报推送
11. 结语
本项目通过结合先进的深度学习技术和精心设计的用户界面,为跌倒检测领域提供了一套完整的解决方案。系统不仅在技术上实现了高精度、实时的跌倒检测,还在用户体验方面提供了直观、友好的交互界面,为保障老年人和特殊人群的安全提供了有力工具。
下载链接
1.由于我将使用YOLOv5训练得到的模型转换为ONNX格式,因此我将训练代码和检测代码进行了分离。为了更好地管理项目,我创建FallDetectionSystem项目,里面包含了界面设计代码、图片、语音警报音频以及测试视频等资源。这些资源将帮助提升系统的用户体验,并为进一步的开发和调试提供支持。
2.若您想获得博文中涉及的实现完整全部程序文件(包括训练代码、数据集、警报音频、测试图片、视频, UI文件等,如下图),这里已打包上传至博主的面包多平台,见可参考博客与视频以及系统说明书,已将所有涉及的文件同时打包到里面,点击即可运行,完整文件截图如下:
参考系统演示视频:【传统监控 vs AI检测!YOLOv5如何实现跌倒实时报警?实战项目揭秘!-哔哩哔哩】 https://b23.tv/PwH2xp3
完整项目资源获取链接:https://mbd.pub/o/bread/aJeXk59s



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











