







通过直接删除的方式处理异常值虽然是最直接的方法,但是会减少数据样本,因此,在数据集小的情况下减少数据样本会对结果产生影响;在含有较多异常值的数据集中,大量删除异常值也会对结果产生影响。因此,在异常值没有可研究性的情况下,应该对这些异常值进行修补处理。
修补异常值的方式主要有两种,即修改异常值和替换异常值,这两种方式具体介绍如下。
1,修改异常值
修改异常值有两种策略:一是利用数据集中的代表属性,如众数或均值等,或是定义一个数据替代异常值;二是通过回归模型、决策树模型、贝叶斯定理等预测异常值,并利用最邻近值替代异常值。前者是人为替代异常值,不能完全代表异常值本身的真实含义,后者是将对应的变量当作目标变量,把其他的输入变量作为自变量,为每个需要进行异常值赋值的字段分别建立预测模型,从而二利用最邻近值替代异常值,剋有近似代表异常值本身的含义。
2,替换异常值
替换异常值是将异常值换成缺失值,然后按照缺失值数据处理的方法进行处理。
现有一份500人的身高调查数据表interpo_data,对其进行修补异常值处理。
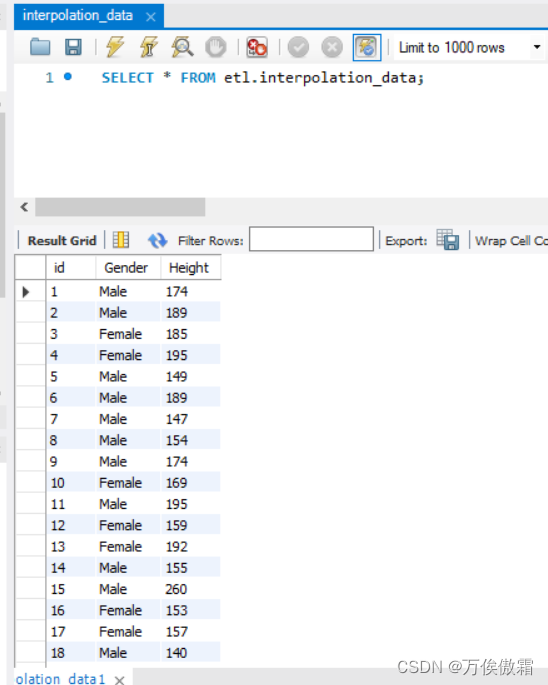
数据表中的身高数据可通过箱型图的四分位数计算得出5个统计量,即下限为114,下四分位是156,中位数为170,上四分位为184,上限是226,因此可确定非异常值的取值范围为[114,226].
一,创建转换
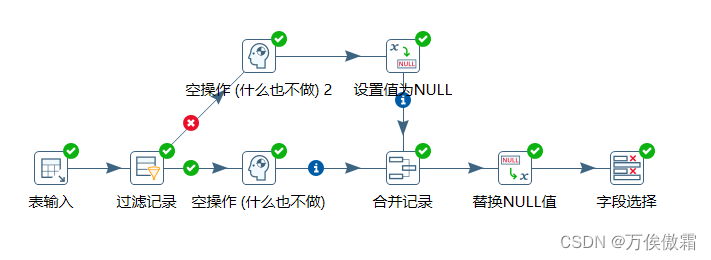
二,表输入配置

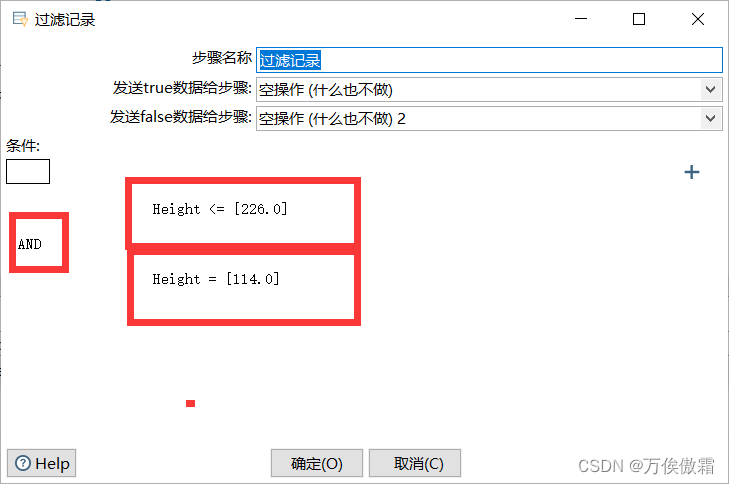
三,过滤记录的配置
设置正常值范围。
四,配置设置值为null
从数据源可以发现一个异常值为Height=260,设置为空。

五,合并记录
id为唯一且不变的,将其设置为关键字。

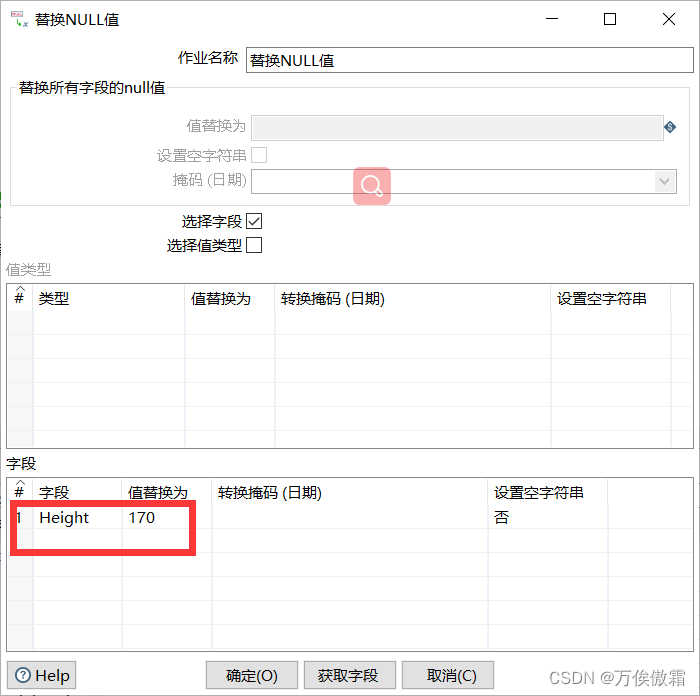
六,替换null值
将Height中空值替换为170(170为均值)。
七,字段选择
移除因合并记录多出的字段flagfield。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









