









目录
96 找出整数数组中占比超过 1 / N 的数(应该是一半吧)
【✍️ 入营考核】AI 加码,青训营 X 豆包MarsCode 技术训练营👏 欢迎各位同学报名“AI 加码,青训营 X - 掘金 (juejin.cn)
要求:
简单题不少于10道题
中等题目不少于4道题
困难题目不少于1道题
介绍:
本次24青训营,入营和之前的考核模型有所不同,之前是做题,几十个选择题,两道算法题,一道简答题,现在则是在ai的辅助下进行刷题考核,这么做的原因无非是推广自己家的智能编码助手,还有就是此次代码考核在在线平台上,就能得到大量的数据,然后使用这些数据去强化编码助手,最后就是ai助手有点傻,一个是你把他给你的代码,都过不了示例,然后他容易顺着你代码的想法,往后推理,如果你一开始的想法不对,就会进入死角。
下面是我的刷题笔记,都是通过了示例,但是具体能不过AC,未知。
简单题目
已完成 10
2 计算x到y的最小步数
# 问题描述
AB 实验同学每天都很苦恼如何可以更好地进行 AB 实验,每一步的流程很重要,我们目标为了缩短所需的步数。
我们假设每一步对应到每一个位置。从一个整数位置 `x` 走到另外一个整数位置 `y`,每一步的长度是正整数,每步的值等于上一步的值 `-1`, `+0`,`+1`。求 `x` 到 `y` 最少走几步。并且第一步必须是 `1`,最后一步必须是 `1`,从 `x` 到 `y` 最少需要多少步。
## 样例说明
- 整数位置 `x` 为 `12`,另外一个整数位置 `y` 为 `6`,我们需要从 `x` 走到 `y`,最小的步数为:`1`,`2`,`2`,`1`,所以我们需要走 `4` 步。
- 整数位置 `x` 为 `34`,另外一个整数位置 `y` 为 `45`,我们需要从 `x` 走到 `y`,最小的步数为:`1`,`2`,`3`,`2`,`2`,`1`,所以我们需要走 `6` 步。
- 整数位置 `x` 为 `50`,另外一个整数位置 `y` 为 `30`,我们需要从 `x` 走到 `y`,最小的步数为:`1`,`2`,`3`,`4`,`4`,`3`,`2`,`1`,所以我们需要走 `8` 步。
## 输入格式
输入包含 `2` 个整数 `x`,`y`。(`0<=x<=y<2^31`)
## 输出格式
对于每一组数据,输出一行,仅包含一个整数,从 `x` 到 `y` 所需最小步数。
## 输入样例
```
12 6
34 45
50 30
```
## 输出样例
```
4
6
8
```问题分析:
从x走到y,其实就是从步伐大小从1开始走,最后一步也必须为1,每一步之间呢,可以+1,0,和-1,如果说想要最小步数,这个步伐肯定要迈的大,我的代码呢,遵循一个原则,就是第一步肯定为1,接下来每一步有三种选择,假设步伐为x,一个是x + 1,一个是x,一个是x - 1,在优先级上x + 1 > x > x - 1,在是否合规上采取走下一步的时候,必须保证剩余的距离,可以降到 1 ,也就是说先 x + 1,但是剩下的距离必须大于等于 x~1的和,如果不可以那就尝试 x,剩下的距离大于等于 x - 1 ~ 1 的he,x - 1也是如此,直至走到y。
代码如下:
#include <iostream>
using namespace std;
#include <cmath>
int sum(int x){
if(x <= 0){
return 0;
}
int res = 0;
for(int i = 1; i <= x; i ++){
res = res + i;
}
return res;
}
// 计算从x到y的最少步数
int minSteps(int x, int y) {
if(x > y){
swap(x,y);
}
int l = 0, r = y - x;
int step = 0;
int stepdistance = 0;
while(l < r){
if(step == 0){
stepdistance = 1;
step = 1;
l = l + stepdistance;
continue;
}
int step1 = stepdistance + 1;
int step2 = stepdistance;
int step3 = stepdistance - 1;
if(l + step1 < r){
int m = l + step1;
int s = sum(step1 - 1);
if((r - m) >= s){
l = m;
step ++;
stepdistance = step1;
continue;
}
}
if( l + step2 <= r){
int m = l + step2;
int s = sum(step2 - 1);
if((r - m) >= s){
l = m;
step ++;
stepdistance = step2;
continue;
}
}
if( l + step3 <= r){
int m = l + step3;
int s = sum(step3 - 1);
if((r - m) >= s ){
l = m;
step ++;
stepdistance = step3;
continue;
}
}
}
return step;
}
int main() {
std::cout << (minSteps(6, 7) == 1) << std::endl;
std::cout << (minSteps(12, 6) == 4) << std::endl;
std::cout << (minSteps(34, 45) == 6) << std::endl;
std::cout << (minSteps(50, 30) == 8) << std::endl;
return 0;
}运行结果:
4 环状 DNA 序列整理
# 问题描述
环状 DNA 又称超螺旋,即一段碱基序列呈现环状,在分析时,需要将相同序列的环状 DNA 分到相同组内,现需将环状碱基序列按照最小表示法进行排序。
一段长度为 `n` 的碱基序列,按照顺时针方向,碱基序列可以从任意位置起开始该序列顺序,因此长度为 `n` 的碱基序列有 `n` 种表示法。例如:长度为 6 的碱基序列 `CGAGTC`,有 `CGAGTC`、`GAGTCC`、`AGTCCG` 等表示法。在这些表示法中,字典序最小的称为“最小表示”。
输入一个长度为 `n`(`n <= 100`)的环状碱基序列(只包含 `A`、`C`、`G`、`T` 这 4 种碱基)的一种表示法,输出该环状碱基序列的最小表示。
例如:
`ATCA` 的最小表示是 `AATC`
`CGAGTC` 的最小表示是 `AGTCCG`
## 输入描述
一段 DNA 碱基序列
## 输出描述
DNA 碱基序列的最小表示
**备注**:
`n <= 100`
DNA 由大写英文字母 `A`、`G`、`C`、`T` 组成
**示例 1**
输入:`ATCA`
输出:`AATC`
**示例 2**
输入:`CGAGTC`
输出:`AGTCCG`问题分析:
通过循环将所有的可能存储起来,然后循环比较得出最小的DNA碱基序列
代码如下:
#include <iostream>
using namespace std;
#include <string>
#include <vector>
std::string solution(std::string dna_sequence) {
// Please write your code here
vector<string> representations;
for(int i = 0; i < dna_sequence.size();i++){
string representation = dna_sequence.substr(i) + dna_sequence.substr(0,i);
representations.push_back(representation);
}
string minRepresentation = representations[0];
for(auto representation : representations){
if( representation < minRepresentation){
minRepresentation = representation;
}
}
return minRepresentation;
}
int main() {
// You can add more test cases here
std::cout << (solution("ATCA") == "AATC") << std::endl;
std::cout << (solution("CGAGTC") == "AGTCCG") << std::endl;
std::cout << (solution("TCATGGAGTGCTCCTGGAGGCTGAGTCCATCTCCAGTAG") == "AGGCTGAGTCCATCTCCAGTAGTCATGGAGTGCTCCTGG") << std::endl;
return 0;
}运行结果:
13 Base32 解码和编码
# 问题描述
你需要实现一个 Base32 的编码和解码函数。
相比于 Base32,你可能更熟悉 Base64,Base64 是非常常见的用字符串形式表示二进制数据的方式,在邮件附件、Web 中的图片中都有广泛的应用。
Base32 是 Base64 的变种,与 Base64 不同的地方在于 Base64 以 6 bit 为一组作为索引,而 Base32 以 5 bit 为一组作为索引,每一组用一个 ASCII 字符表示。Base 64 总共需要 64 个字符表示,而 Base32 则只需要 32 个字符表示。
Base32 的编码流程如下:
- 对二进制数据进行预处理:如果二进制数据的 bit 数目不不是 5 的倍数的话,在末尾补 0 直至为 5 的倍数
- 以 5 bit 为一组进行分组
- 将每一组的 5 bit 二进制转换为索引(0 - 31)
- 在索引 - 字符转换表中查询索引对应的字符
- 根据原始二进制数据的 bit 数目除以 40 后的余数,确定末尾需要补 0 的数目
- 如果原始二进制数据 bit 数目除以 40 后的余数是 0 的话,不需要补 +
- 如果原始二进制数据 bit 数目除以 40 后的余数是 8 的话,补 6 个 +
- 如果原始二进制数据 bit 数目除以 40 后的余数是 16 的话,补 4 个 +
- 如果原始二进制数据 bit 数目除以 40 后的余数是 24 的话,补 3 个 +
- 如果原始二进制数据 bit 数目除以 40 后的余数是 32 的话,补 1 个 +
Base32 的索引 - 字符转换表见下方。
索引:0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
字符:9 8 7 6 5 4 3 2 1 0 m n b v c x z a s d f g h j k l p o i u y t
**示例**
**编码**
- 输入:字符串 `foo`
- 字符 `f` 的 ASCII 编号为 102,字符 `o` 的 ASCII 编号为 111
- 将字符串 `foo` 以 ASCII 编号形式表达为 102 111 111 的序列
- 将 102 111 111 的序列转换为二进制表示,即 01100110 01101111 01101111,将二进制字符串以 40 个为一组进行分割
- 最后一组的二进制字符串长度为 24,不是 5 的倍数,因此在最后补 0,直至其能被 5 整除(在此例子中,补 1 个即可),二进制字符串表示为: 01100110 01101111 01101111 0
- 每 5 bit 为一组,表示为:01100 11001 10111 10110 11110
- 将每一组转换为十进制的索引,表示为:12 25 23 22 30,对应字符 `b` `l` `j` `h` `y`
- 由于最终输出字符串长度不是 8 的倍数,在输出最后补充 3 个 `+`
- 查询索引 - 字符转换表后,可以得出最终的输出为:`bljhy+++`
`Input data: foo`
`Input in Unicode: 102 111 111`
`Unicode in binary (8-bit): 01100110 01101111 01101111 0`
`Unicode in binary (5-bit): 01100 11001 10111 10110 11110`
`Decimal: 12 25 23 22 30`
`Pad: + + +`
`Output: b l j h y + + +`
**解码**
- 输入:`bljhy+++`
- 查询索引 - 字符转换表后,可知原始的二进制数据组为:01100 11001 10111 10110 11110
- 由末尾 3 个 `+` 可知在编码时原始二进制数据最后一组的个数为 24 个,由此可知最后一组数据为:01100110 01101111 01101111
- 将二进制数据转换为 ASCII 编号后可知,原始字符串的 Unicode 序列为:102 111 111
- 将 Unicode 序列转换为字符串,即可得出原始字符串,为:`foo`
**输入示例**
`foo`
`b0zj5+++`
- 第一行为需要编码的原始字符串:`rawStr`
- 第二行为需要解码的 Base32 字符串:`encodedStr`
**输出示例**
`bljhy+++`
`bar`
**解释**:
- 第一行编码后的输出为 `bljhy+++`
- 第二行解码后的输出为 `bar`
**数据范围**
`rawStr[n]` 为 ASCII 的可显示字符,`rawStr.length < 2048`
`encodedStr` 为使用此算法编码后的 Base32 字符序列,`encodedStr.length < 4096`问题分析:
这个题目不是很难,但是很繁琐,可能是我的实现问题的原因,我写了很多函数,
各个函数的作用:
`decimalToBinary8Bits` 用于将十进制数转换为 8 位二进制字符串,
`binaryToDecimal` 用于将二进制字符串按 5 位一组转换为十进制数并存入向量,
`decimalArrayToBinary` 用于将十进制数向量转换为二进制字符串,
`binaryToChar` 用于将二进制字符串按 8 位一组转换为 ASCII 码对应的字符。
`jiema` 函数用于解码操作,通过判断输入字符串末尾的 `+` 个数来确定原始二进制数据的长度,然后进行解码处理。但这个函数中的条件判断较多,可能会增加理解和维护的难度。
`solution` 函数是主要的处理函数,它对输入的原始字符串进行预处理,转换为二进制字符串并根据余数进行补零,然后进行编码和解码操作。
代码如下:
#include <iostream>
#include <string>
#include <vector>
#include <array>
using namespace std;
std::array<char, 32> base32 = {'9', '8', '7', '6', '5', '4', '3', '2', '1', '0', 'm', 'n', 'b', 'v', 'c', 'x', 'z', 'a', 's', 'd', 'f', 'g', 'h', 'j', 'k', 'l', 'p', 'o', 'i', 'u', 'y', 't'};
std::string decimalToBinary8Bits(int num) {
std::string binary;
for (int i = 7; i >= 0; i--) {
if (num & (1 << i)) {
binary += '1';
} else {
binary += '0';
}
}
return binary;
}
std::vector<int> binaryToDecimal(const std::string& binaryStr) {
std::vector<int> decimalNums;
for (size_t i = 0; i < binaryStr.size(); i += 5) {
std::string group = binaryStr.substr(i, 5);
int decimal = 0;
for (char c : group) {
decimal = decimal * 2 + (c - '0');
}
decimalNums.push_back(decimal);
}
return decimalNums;
}
std::string decimalArrayToBinary(const std::vector<int>& arr) {
std::string result;
for (const auto& num : arr) {
std::string binary;
int n = num;
for (int i = 4; i >= 0; i--) {
if (n & (1 << i)) {
binary += '1';
} else {
binary += '0';
}
}
result += binary;
}
return result;
}
std::string binaryToChar(const std::string& binaryStr) {
std::string result;
for (size_t i = 0; i < binaryStr.size(); i += 8) {
std::string group = binaryStr.substr(i, 8);
int decimal = 0;
for (char c : group) {
decimal = decimal * 2 + (c - '0');
}
result += static_cast<char>(decimal);
}
return result;
}
string jiema(string encodedStr){
int i = 0;
for(i = encodedStr.size() - 1; i > 0 && encodedStr[i] == '+'; i --);
string newstr = encodedStr.substr(0,i + 1);
vector<int> st2;
for(int i = 0; i < newstr.size(); i ++){
for(int j = 0; j < base32.size(); j ++){
if(newstr[i] == base32[j]){
st2.push_back(j);
}
}
}
string newnewstr = decimalArrayToBinary(st2);
string res2 = "";
if(newnewstr.size() % 40 == 10){
string newstrs = newnewstr.substr(0,newnewstr.size() - 2);
res2 = binaryToChar(newstrs);
}else if(newnewstr.size() % 40 == 20){
string newstrs = newnewstr.substr(0,newnewstr.size() - 4);
res2 = binaryToChar(newstrs);
}else if(newnewstr.size() % 40 == 25){
string newstrs = newnewstr.substr(0,newnewstr.size() - 1);
res2 = binaryToChar(newstrs);
}else if(newnewstr.size() % 40 == 35){
string newstrs = newnewstr.substr(0,newnewstr.size() - 3);
res2 = binaryToChar(newstrs);
}
return res2;
}
std::string solution(std::string rawStr, std::string encodedStr) {
// Please write your code here
vector<int> st;
string str1 = "";
for(int i = 0; i < rawStr.size();i++){
str1 += decimalToBinary8Bits(static_cast<int>(rawStr[i]));
}
int r = str1.size() % 40;
if(r == 8){
str1 += "00";
}else if(r == 16){
str1 += "0000";
}else if(r == 24){
str1 += "0";
}else if(r == 32){
str1 += "000";
}
st = binaryToDecimal(str1);
string res1 = "";
for(int i = 0; i < st.size() ; i ++){
res1 += base32[st[i]];
}
while( res1.size() % 8 != 0){
res1 += "+";
}
string res2 = "";
for(int i = 0; i < encodedStr.size(); i += 8){
res2 += jiema(encodedStr.substr(i,i + 8));
}
//cout << res1 << endl;
//cout << res2 << endl;
return res1 + ":" + res2;
}
int main() {
// You can add more test cases here
std::cout << (solution("foo", "b0zj5+++") == "bljhy+++:bar") << std::endl;
std::cout << (solution("The encoding process represents 40-bit groups of input bits as output strings of 8 encoded characters. Proceeding from left to right, a 40-bit input group is formed by concatenating 5 8bit input groups. These 40 bits are then treated as 8 concatenated 5-bit groups, each of which is translated into a single character in the base 32 alphabet. When a bit stream is encoded via the base 32 encoding, the bit stream must be presumed to be ordered with the most-significant- bit first. That is, the first bit in the stream will be the high- order bit in the first 8bit byte, the eighth bit will be the low- order bit in the first 8bit byte, and so on.", "bljhy+++b0zj5+++") == "maf3m164vlahyl60vlds9i6svuahmiod58l3mi6sbglhmodfcbz61b8vb0fj1162c0jjmi6d58jhb160vlk2mu89b0fj1il9b4ls9oogcak2mu89cvp25pncbuls9oo359i79lncbvjh1ln558ahzknsb4aj1lnscbj7917zc0jh3ln4bafhill9bll3yo09vashbu89cajs9id0buf21n89b5z61b8vb0fj1160vlk2mu89bul3yunz58fj3163vul3pln558a2s166vuj33knfbgj37u60vlds9v0928a3su89v4j29unf58dj5oogc8lsi17fv8sj3l093zk79kd0cals9knsbfz21p64vkz21id4b4p3ml89b4ls9c89bvjhiko8cashiknfbgs79v0vb0fj1162c0jjmi6d4zz3mkn6v9z3yla9cuf3sko158fj316fc0zhiiobb4p3ml89v4j21ol9b5z23pncbuh3m166v8zj5kn6casj5160vkz21p6458a37io459ld5168vak3zkn7bgp7i189muf3moa9b5z35pnf58lj1id4b4hs9pnd58shikoxbash116hv4zs9u61bfz35kndbfz63ba9bgj33oo5v4j3cn89caf3m167v4p79iofc0sh7o09vgpj3u89b0ss9i6sbgljmon4bzz21ol9b0ss9oosbasj5ln558ohsu6158p3zl09vgjj3u8vcvfhcod0blfh3kncczhs9kd0czz3bpnscvp7i17fv8zj1160cbh79u61bfz3bpnscvp79kd0czz3soa9caf3m16dcal3mknv58ohso6b58a3m16fv8ss9p60buf7p16xc0s3mia9b0fj1160vkz21p6458d3siddczz6zkd0czz35ynfbfh79u61bfz3mpn2v8p3z167v4p79uo0vah79kd458p3zl09vajjcn09vul31lns58a3su89v4j79u61bfz3bpnscvp79c67v4p79kdlcassk168vls79iox58jhinz+:foobar") << std::endl;
return 0;
}运行结果:
28 打点计时器
# 问题描述
小明想发明一台打点计数器,这个计数器有这样的一个功能:
- 它可以接收一个递增的数据范围(形如[3, 9]),其中第一个数字代表起始,第二个数字代表结束
- 这个数据范围中包含几个数字,打点计数器就会打几个点
- 在传入的多组数据范围中,如果出现了范围的重复,机器则不会重复打点
你可以帮助小明算一算,在不同的情况下,计数器会打出几个点么?
## 输入格式
一个二维数组
## 输出格式
一个整数,表达在输入是这个数组的情况下,计数器打出的点数
**输入样例(1)**
[
[1,4],
[7, 10],
[3, 5]
]
**输出样例(1)**
7
**输入样例(2)**
[
[1,2],
[6, 10],
[11, 15]
]
**输出样例(2)**
9
**数据范围**
- 数字范围 [-10^9, 10^9],数组长度 < 2^16问题分析:
本题目采用集合来处理,因为集合具有互异性,所以在打点过程中重复区域的会被去掉,遍历每段区间,区间遍历每个点,存进集合中,最后返回集合的大小就是打点的数量
代码如下:
#include <iostream>
#include <vector>
#include <set>
using namespace std;
int solution(std::vector<std::vector<int>> inputArray) {
// Please write your code here
set<int> myset;
for(auto x : inputArray){
for(int i = x[0];i < x[1]; i++){
myset.insert(i);
}
}
return myset.size();
}
int main() {
// You can add more test cases here
std::vector<std::vector<int>> testArray1 = {{1, 4}, {7, 10}, {3, 5}};
std::vector<std::vector<int>> testArray2 = {{1, 2}, {6, 10}, {11, 15}};
std::cout << (solution(testArray1) == 7) << std::endl;
std::cout << (solution(testArray2) == 9) << std::endl;
return 0;
}运行结果:
64 兔生兔
# 问题描述
- 如果一对兔子每月生一对兔子;一对新生兔,从第二个月起就开始生兔子;假定每对兔子都是一雌一雄,试问一对兔子,第 `n` 个月能繁殖成多少对兔子?(举例,第1个月是1对兔子,第2个月是2对兔子)
## 输入格式
- 数字
## 输出格式
- 数字
## 输入样例
- 5
## 输出样例
- 8
## 数据范围
- `[1, 75]`
## 测试数据集
- 样例1
- 输入:`5`
- 输出:`8`
- 样例2
- 输入:`1`
- 输出:`1`
- 样例3
- 输入:`15`
- 输出:`987`
- 样例4
- 输入:`50`
- 输出:`20365011074`问题分析:
- 函数定义:
-
int solution(int n):这个函数接受一个整数n作为输入,并返回第n个月兔子的对数。
- 基本情况处理:
-
- 如果
n是 1 或 2,函数直接返回 1 或 2,这是斐波那契数列的前两个数(或在这个问题中,第一个月和第二个月的兔子对数)。
- 如果
- 动态规划数组:
-
vector<int> dp(n + 1):创建了一个大小为n + 1的动态规划数组dp,用于存储从第 1 个月到第n个月的兔子对数。dp[1] = 1和dp[2] = 2:初始化前两个月的兔子对数。
- 递推公式:
-
for (int i = 3; i <= n; i++):从第 3 个月开始,使用递推公式dp[i] = dp[i - 1] + dp[i - 2]计算每个月的兔子对数。这个公式基于斐波那契数列的定义,即每个数都是前两个数的和。
- 返回结果:
-
return dp[n]:返回第n个月的兔子对数
代码如下:
#include <iostream>
using namespace std;
#include <vector>
int solution(int n) {
// 使用动态规划来保存前两个月的兔子对数
if (n == 1) return 1; // 第一个月
if (n == 2) return 2; // 第二个月
vector<int> dp(n + 1); // dp[i] 表示第 i 个月的兔子对数
dp[1] = 1; // 第一个月
dp[2] = 2; // 第二个月
// 计算每个月的兔子对数
for (int i = 3; i <= n; i++) {
dp[i] = dp[i - 1] + dp[i - 2]; // 递推公式
}
return dp[n]; // 返回第 n 个月的兔子对数
}
int main() {
// 验证输出结果是否符合预期
cout << (solution(5) == 8) << endl;
cout << (solution(1) == 1) << endl;
cout << (solution(15) == 987) << endl;
//cout << (solution(50) == 20365011074) << endl;
return 0;
}运行结果:
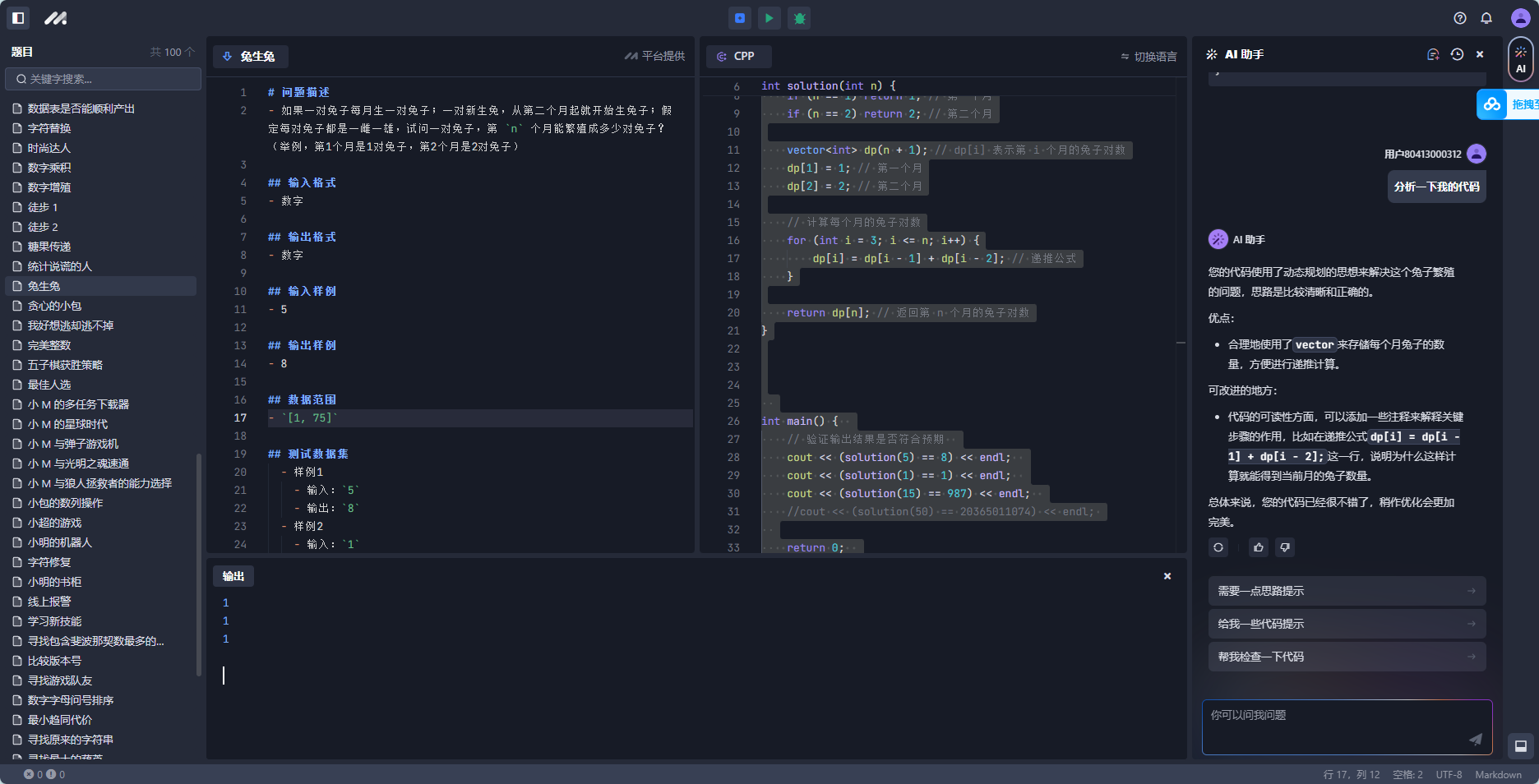
67 完美整数
# 问题描述
一个整数如果由相同数字构成,可以称为完美整数;比如说1、11、333就是完美整数,12、19、101就是不完美的整数。
现在想知道,在区间 `[x, y]` 中有多少个整数是完美整数。
## 输入格式
每个样例有一行,是整数 `x` 和 `y`;(1 ≤ x ≤ y ≤ 10^9)
## 输出格式
每一个样例一行,是整数 `m`,表示区间 `[x, y]` 中有 m 个整数是完美整数。
## 输入样例1
1 10
## 输出样例1
9
## 输入样例2
2 22
## 输出样例2
10
## 数据范围
1 ≤ t ≤ 1000
1 ≤ x ≤ y ≤ 10^9问题分析:
其实生成了10^9之内的所有完美整数,然后对这些完美整数进行排序,然后计算完美整数的左右区间,通过区间得到完美整数的数量
代码如下:
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
// 生成所有不超过 10^9 的完美整数
vector<long long> generatePerfectNumbers() {
vector<long long> perfectNumbers;
for (int digit = 1; digit <= 9; ++digit) { // 从 1 到 9
long long perfectNumber = digit;
while (perfectNumber <= 1000000000) { // 直接通过循环累加构建完美整数
perfectNumbers.push_back(perfectNumber);
perfectNumber = perfectNumber * 10 + digit;
}
}
return perfectNumbers;
}
vector<long long> perfectNumbers = generatePerfectNumbers();
int solution(long long x, long long y) {
auto left = lower_bound(perfectNumbers.begin(), perfectNumbers.end(), x); // 找到第一个大于等于 x 的位置
auto right = upper_bound(perfectNumbers.begin(), perfectNumbers.end(), y); // 找到第一个大于 y 的位置
// 计算区间内完美整数的个数
return right - left;
}
int main() {
sort(perfectNumbers.begin(), perfectNumbers.end());
std::cout << (solution(1, 10) == 9) << std::endl;
std::cout << (solution(2, 22) == 10) << std::endl;
return 0;
}运行结果:
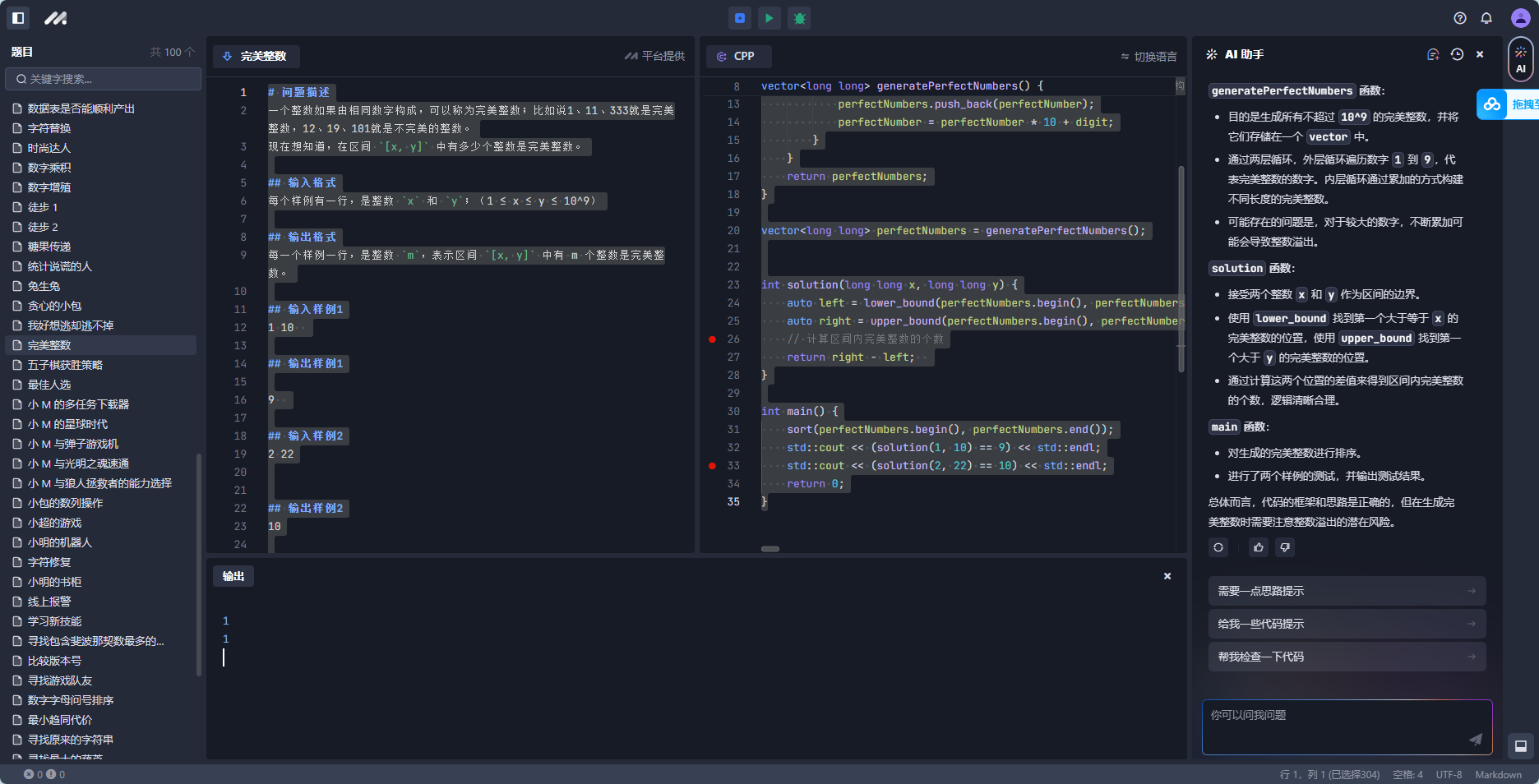
96 找出整数数组中占比超过 1 / N 的数(应该是一半吧)
## 问题描述
- 给定一个长度为n的整型数组,已知其中一个数字的出现次数超过数组长度的一半,找出这个元素
## 输入格式
- 一个长度为n的数组,其中某个元素的出现次数大于n/2
## 输出格式
- 一个整数
## 输入样例
- [1,3,8,2,3,1,3,3,3]
## 输出样例
- 3
## 数据范围
- 任意长度为n整数数组,其中某个元素的出现次数大于n/2问题分析:
其实就是找出出现次数超过一半的数,首先通过快排将数组拍成有序的,然后取有序的中间那个数就可以,因为是大于一半的,就算是极限情况从头或者从尾开始,中间那个数也是出现一半以上的,更不用说其他在中间的情况了
代码如下:
#include <cstdlib>
#include <iostream>
#include <vector>
using namespace std;
// 正确的快速排序函数
void quickSort(int l, int r, vector<int>& num) {
if (l >= r) return;
int mid = num[(l + r) / 2]; // 修改基准元素的选取
int i = l - 1, j = r + 1;
while (i < j) {
do i++; while (num[i] < mid);
do j--; while (num[j] > mid);
if (i < j) swap(num[i], num[j]);
}
quickSort(l, j, num);
quickSort(j + 1, r, num);
}
// 修改后的求解函数,返回出现次数超过一半的元素
int solution(vector<int> list) {
quickSort(0, list.size() - 1, list);
return list[(list.size() - 1) / 2];
}
int main() {
// Add your test cases here
cout << (solution({1, 3, 8, 2, 3, 1, 3, 3, 3}) == 3) << endl;
return 0;
}运行结果:
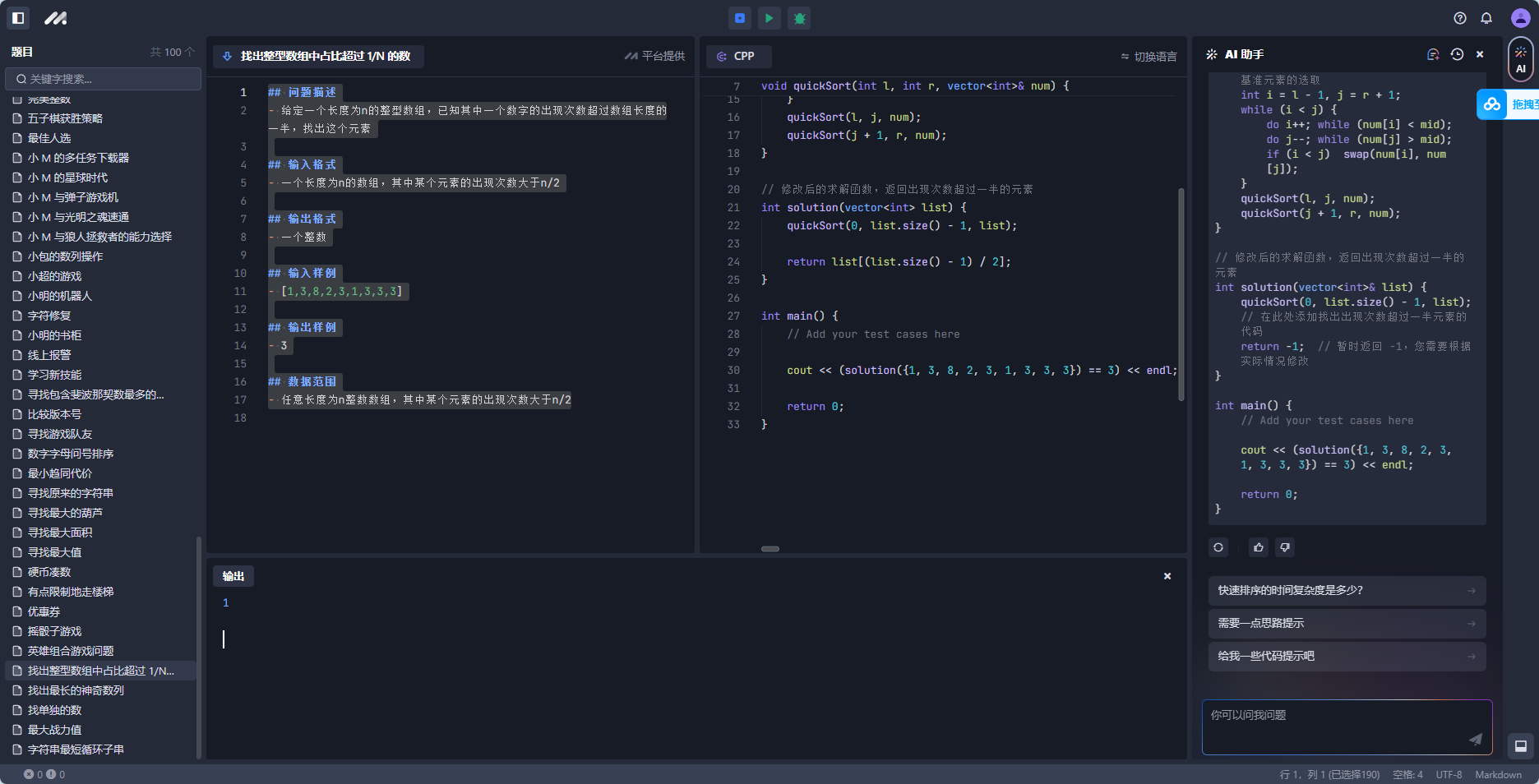
97 找出最长的神奇数列
# 问题描述
小明是一个中学生,今天他刚刚学习了数列。他在纸上写了一个长度为 `n` 的正整数序列,$a_0,a_1,\ldots,a_{n-1}$。这个数列里面只有 1 和 0,我们将 1 和 0 没有重复跟随并且至少由 3 个数组成的数列的数列称之为「神奇数列」。比如 `10101` 是一个神奇数列,`1011` 不是一个神奇数列。他想知道这个序列里面最长的「神奇数列」是哪个,你可以帮帮他吗?
## 输入格式
- 一行连续的数 `s`,只有 `0` 和 `1`
## 输出格式
- 一行数
## 输入样例
0101011101
## 输出样例
010101
## 数据范围
- $1 < s.length \leq 5 \times 10^4$问题分析:
通过遍历字符串,如果相邻的不同,就长度增加,如果相同了,就把相同之前的不同的一个串尝试更新的最长神奇数列,首先要长度大于3,其次要和之前的生气数列比较,最后返回字符串
代码如下:
#include <iostream>
#include <string>
using namespace std;
std::string solution(const std::string& inp) {
string maxlist; // 用于存储最长的神奇数列
int maxLength = 0; // 最长神奇数列的长度
int n = inp.size(); // 输入字符串的长度
// 当前神奇数列的起始位置和长度
int start = 0;
int currentLength = 1;
for (int i = 1; i < n; i++) {
if (inp[i] != inp[i - 1]) { // 当前字符与前一个字符不同
currentLength++; // 更新当前神奇数列的长度
} else {
// 如果当前长度大于等于3,检查是否需要更新最长的神奇数列
if (currentLength >= 3) {
string candidate = inp.substr(start, currentLength);
if (currentLength > maxLength) {
maxLength = currentLength;
maxlist = candidate; // 更新最长神奇数列
}
}
// 重置当前神奇数列
start = i;
currentLength = 1; // 重新计数
}
}
// 处理最后一段神奇数列
if (currentLength >= 3) {
string candidate = inp.substr(start, currentLength);
if (currentLength > maxLength) {
maxlist = candidate; // 更新最长神奇数列
}
}
return maxlist; // 返回最长的神奇数列
}
int main() {
// Add your test cases here
std::cout << (solution("0101011101") == "010101") << std::endl;
return 0;
}运行结果:
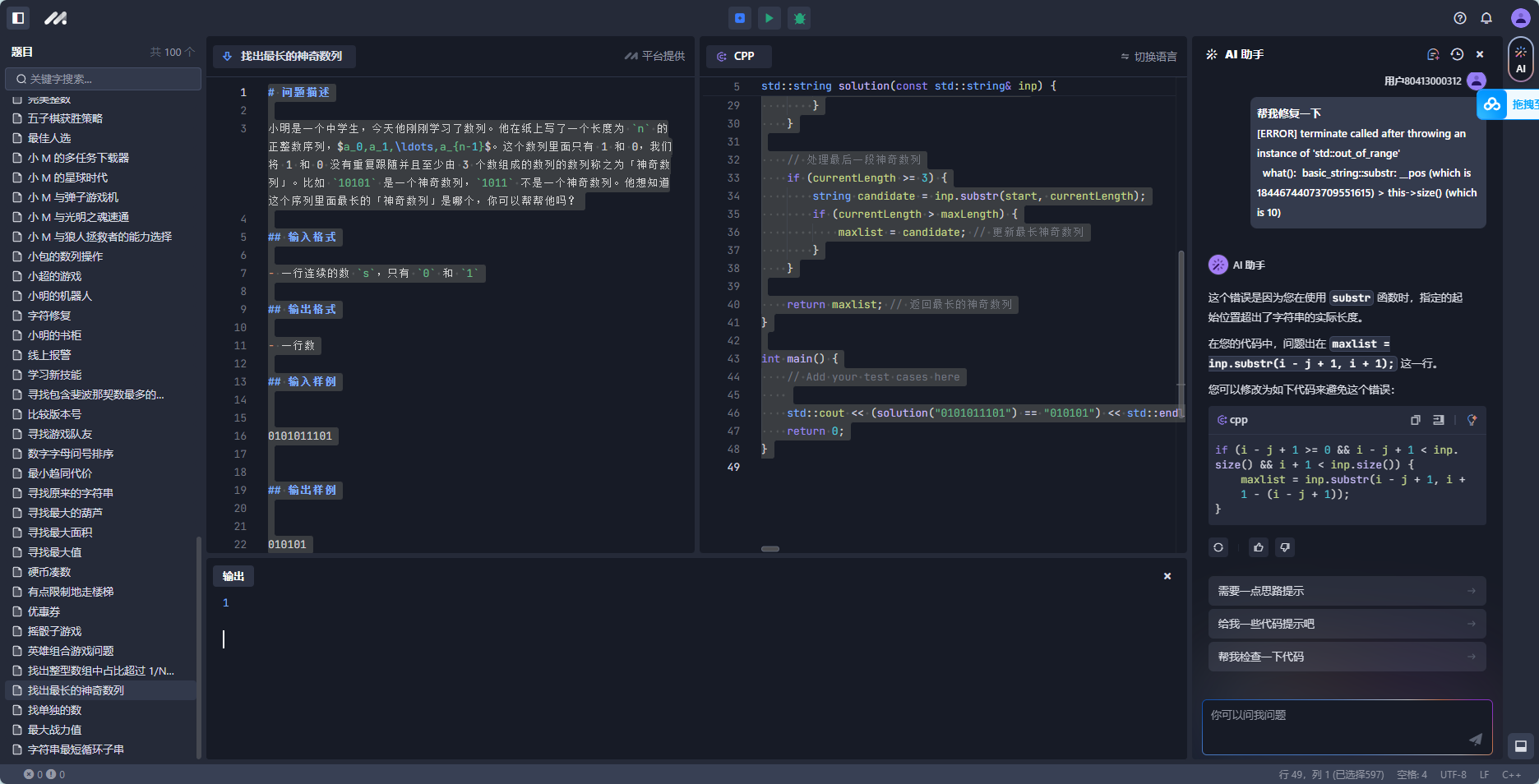
98 找单独的数
# 问题描述
有一堆数字,除了一个数字,其它的数字都是成对出现。班上的每个同学拿一个数字,正好将这些数字全部拿完,问如何快速找到拿了单独数字的同学?
## 输入格式
- 空格分隔输入所有的数字
## 输出格式
- 单独的那个数字
## 输入样例(1)
```
1 1 2 2 3 3 4 5 5
```
## 输出样例(1)
4
## 输入样例(2)
```
0 1 0 1 2
```
## 输出样例(2)
2问题分析:
这个应该是100个题目中最简单的一个了,通过异或会把相同的数字抵消掉,剩下的就是那个单独的数字。
代码如下:
#include <iostream>
#include <vector>
int solution(std::vector<int> inp) {
// Edit your code here
int res = 0;
for(int i = 0; i < inp.size(); i ++){
res ^= inp[i];
}
return res;
}
int main() {
// Add your test cases here
std::cout << (solution({1, 1, 2, 2, 3, 3, 4, 5, 5}) == 4) << std::endl;
std::cout << (solution({0, 1, 0, 1, 2}) == 2) << std::endl;
return 0;
}100 字符串最短循环子串
# 问题描述
- 输入一个字符串,判断其是否完全循环,若是循环的,输出最短的循环子串,否则输出空`""`
- 如输入 `abababab`,输出 `ab`;输入 `ab` 则输出 `""`
## 输入格式
- 合法字符串 如 `abcabcabcabc` `aaa`
## 输出格式
- 最短的循环子串 `"abc"` `"a"`
## 输入样例
- `"abcabcabcabc"`
## 输出样例
- `"abc"`
## 数据范围
测试数据集问题分析:
首先将每一种可能的字符串切出来,然后通过循环比较,字串通过取余循环,来判断是否为循环字串,如果j走到了最后,那么当前的字串就是他的循环字串,因为是从小的串开始,如果j走到了最后那么就不会切更大的字串直接跳出循环,保证了是最小的字串,如果i走到最后还没有找到,那么结果就是“”。
代码如下:
#include <iostream>
#include <string>
using namespace std;
std::string solution(const std::string &inp) {
// Edit your code here
string str = "";
int i = 0, j = 0 , k = 0;
for(i = 0; i < inp.size(); i ++){
str = inp.substr(0,i + 1);//切串
for(j = i + 1 , k = 0; j < inp.size() ; j ++ , k ++){
if(inp[j] != str[k %(i + 1)]){ //比较
break;
}
}
if(j == inp.size()){
break;
}
}
if(i == inp.size()){
return "";
}
return str;
}
int main() {
// Add your test cases here
std::cout << (solution("abcabcabcabc") == "abc") << std::endl;
return 0;
}运行结果:
中等题目
已完成 4
5 简单四则运算
# 问题描述
实现一个基本的计算器来计算一个简单的字符串表达式的值。注意事项如下:
- 输入是一个字符串表达式(可以假设所给定的表达式都是有效的)
- 字符串表达式可以包含的运算符号为:左括号 `(`, 右括号 `)`, 加号 `+`, 减号 `-`
- 可以包含的数字为:非负整数(< 10)
- 字符串中不包含空格
- 处理除法 case 的时候,可以直接省略小数部分结果,只保留整数部分参与后续运算
- 请不要使用内置的库函数 `eval`
## 输入格式
如:`3+4*5/(3+2)`
## 数据约束
见题目描述
## 输出格式
计算之后的数字
**输入样例**:
- `1+1`
- `3+4*5/(3+2)`
- `4+2*5-2/1`
- `(1+(4+5+2)-3)+(6+8)`
**输出样例**:
- `2`
- `7`
- `12`
- `23`问题分析:
其实这是一道数据结构的题目,如果仔细学过数据结构或者考研考过,这是栈的应用,通过符号的优先级来确定入栈还是出栈,最后留在栈里的就是结果。
代码如下:
#include <iostream>
#include <stack>
#include <string>
#include <cctype>
using namespace std;
int precedence(char op) {
if (op == '+' || op == '-') {
return 1;
}
if (op == '*' || op == '/') {
return 2;
}
return 0;
}
int applyOp(int a, int b, char op) {
switch (op) {
case '+': return a + b;
case '-': return a - b;
case '*': return a * b;
case '/': return a / b; // 直接取整数部分结果
}
return 0;
}
int evaluate(const string& tokens) {
stack<int> values;
stack<char> ops;
for (size_t i = 0; i < tokens.length(); ++i) {
// 跳过空格
if (isspace(tokens[i])) {
continue;
}
// 当前字符是数字,则解析完整的数字
if (isdigit(tokens[i])) {
int val = 0;
while (i < tokens.length() && isdigit(tokens[i])) {
val = (val * 10) + (tokens[i] - '0');
++i;
}
--i; // 补偿最后多加的一次递增
values.push(val);
}
// 当前字符是左括号,直接压入运算符栈
else if (tokens[i] == '(') {
ops.push(tokens[i]);
}
// 当前字符是右括号,处理栈中的运算符直到遇到左括号
else if (tokens[i] == ')') {
while (!ops.empty() && ops.top() != '(') {
int val2 = values.top();
values.pop();
int val1 = values.top();
values.pop();
char op = ops.top();
ops.pop();
values.push(applyOp(val1, val2, op));
}
// 弹出左括号
if (!ops.empty()) {
ops.pop();
}
}
// 当前字符是运算符
else {
while (!ops.empty() && precedence(ops.top()) >= precedence(tokens[i])) {
int val2 = values.top();
values.pop();
int val1 = values.top();
values.pop();
char op = ops.top();
ops.pop();
values.push(applyOp(val1, val2, op));
}
ops.push(tokens[i]);
}
}
// 处理栈中剩余的运算符
while (!ops.empty()) {
int val2 = values.top();
values.pop();
int val1 = values.top();
values.pop();
char op = ops.top();
ops.pop();
values.push(applyOp(val1, val2, op));
}
// 栈中应该只剩下一个值,即表达式的计算结果
return values.top();
}
int main() {
// You can add more test cases here
std::cout << (evaluate("1+1") == 2) << std::endl;
std::cout << (evaluate("3+4*5/(3+2)") == 7) << std::endl;
std::cout << (evaluate("4+2*5-2/1") == 12) << std::endl;
std::cout << (evaluate("(1+(4+5+2)-3)+(6+8)") == 23) << std::endl;
return 0;
}运行结果:
7 字符串有多少种可能性
# 问题描述
给定一个数字,我们按照如下规则把它翻译为字符串:0 翻译成 “a” ,1 翻译成 “b”,……,11 翻译成 “l”,……,25 翻译成 “z”。一个数字可能有多个翻译。请编程实现一个函数,用来计算一个数字有多少种不同的翻译方法。
## 输入格式
一个 `int` 型的数字,`0 <= num <= 2` 的 31 次方
## 输出格式
也是一个 `int` 型数字,代表字符串的总共可能性
**输入样例**
输入: 12258
**输出样例**
输出: 5
解释: 12258 有 5 种不同的翻译,分别是 "bccfi", "bwfi", "bczi", "mcfi" 和 "mzi"问题分析:
要解决这个问题,即计算一个数字的不同翻译方法,实际上可以通过动态规划来实现。我们需要将输入数字看作一串字符,然后根据规则将其翻译成相应的字符串。
解决思路
动态规划:
我们定义一个动态规划数组 dp,其中 dp[i] 表示在前 i 个字符的翻译方案数量。
对于一个长度为 n 的字符串,我们考虑以下两种情况:
只将当前字符翻译成对应的字母。
将当前字符和前一个字符结合起来翻译(需要确保这两个字符组成的数字合法,且在 0 到 25 之间)。
状态转移方程:
dp[i] = dp[i - 1] 如果当前字符可以单独翻译(即非零)。
dp[i] += dp[i - 2] 如果前两个字符可以合并翻译(即它们组合成的数字在 10 到 25 之间)。
代码如下:
#include <iostream>
#include <string>
using namespace std;
int translateNum(int num) {
string str = to_string(num); // 将数字转成字符串
int n = str.length();
if (n == 0) return 0;
if (n == 1) return 1; // 单字符的情况
// 动态规划数组
int dp[n + 1];
dp[0] = 1; // 空字符串一种方式
dp[1] = 1; // 一个字符也有一种方式
for (int i = 2; i <= n; ++i) {
// 只翻译当前字符
dp[i] = dp[i - 1];
// 结合前一个字符一起翻译
int twoDigit = stoi(str.substr(i - 2, 2)); // 当前字符及前一个字符形成的数
if (twoDigit >= 10 && twoDigit <= 25) {
dp[i] += dp[i - 2]; // 如果能够组合翻译
}
}
return dp[n]; // 返回总的翻译方式
}
int main() {
// You can add more test cases here
std::cout << (translateNum(12258) == 5) << std::endl;
std::cout << (translateNum(1400112) == 6) << std::endl;
std::cout << (translateNum(2110101) == 10) << std::endl;
return 0;
}运行结果:
50 迷人的子序列
# 问题描述
当一个数列,最大值和最小值的差低于某一阈值时,称这个数列是迷人数列。
现给定一个由 `n` 个整数构成的数列和阈值 `k`,问存在多少个连续子序列是迷人的。
## 输入格式
第一行包含 2 个数字 `n, k` (`1 <= n <= 100000`, `0 < k <= 10^9`)
第二行包含 `n` 个整数:`a[1], a[2],..., a[n]` (`0 <= a[i] <= 10^9`)
## 输出格式
输出迷人连续子序列的数目
**输入样例**
4 2
3 1 2 4
**输出样例**
5
**数据范围**
共 10 组数据。2 组数据 `n` 小于 1000;其余数据 `n` 等于 100000。问题分析:
- 定义迷人数列:一个连续的子序列是迷人的,如果这个子序列的最大值和最小值的差小于阈值
k。 - 窗口的管理:我们可以利用两个指针(
left和right)来维护一个有效的窗口,扩展右指针以包含更多的元素,并调整左指针以确保窗口中的最大值和最小值的差小于k。
算法步骤:
初始化:
使用两个指针 left 和 right,并定义一个 multiset 或 unordered_map 来保持当前窗口内的元素,这样可以在 O(log n) 复杂度内找到最大值和最小值。
扩展窗口:
通过移动右指针 right 来增大窗口,同时添加新元素到容器中。
收缩窗口:
当窗口内的最大值和最小值的差大于等于 k 时,移动左指针 left 以缩小窗口。
计数迷人子序列:
每次右指针增加,当窗口有效时,所有从 left 到 right 的子序列都满足条件,可以直接计算数量。
代码如下:
#include <iostream>
#include <vector>
#include <set>
using namespace std;
int countCharmingSubarrays(int n, int k, const vector<int>& nums) {
multiset<int> currentSet;
int left = 0, count = 0;
for (int right = 0; right < n; ++right) {
currentSet.insert(nums[right]); // 将当前元素插入
// 检查当前窗口是否满足迷人子序列条件
while (*currentSet.rbegin() - *currentSet.begin() >= k) {
currentSet.erase(currentSet.find(nums[left])); // 移除左边的元素
left++; // 收缩窗口
}
// 所有从左边到当前右边的子序列都是迷人的
count += right - left + 1;
}
return count;
}
int main() {
// You can add more test cases here
std::vector<int> sequence1 = {3, 1, 2, 4};
std::vector<int> sequence2 = {0, 3, 4, 5, 2, 1, 6, 7, 8, 9};
std::vector<int> sequence3 = {1, 3, 5, 5, 3, 1};
std::cout << (countCharmingSubarrays(4, 2, sequence1) == 5) << std::endl;
std::cout << (countCharmingSubarrays(10, 5, sequence2) == 28) << std::endl;
std::cout << (countCharmingSubarrays(6, 3, sequence3) == 14) << std::endl;
return 0;
}运行结果:
58 五子棋获胜策略
# 问题描述
- 假设存在一个五子棋棋盘,大小未知。上面只摆放了一些白色的棋子,现在你的手中还有一个白色棋子,要求找出在棋盘的哪些位置摆放这个棋子,能够使棋盘上出现五颗棋子连成一线。
- 备注:棋盘上当前不存在连成一条线的五个棋子,但至少存在一个点能够凑出五子一线(不限于横、竖、斜线)
## 输入格式
- 第一行输入一个正整数 `n`,表示棋盘的宽度,棋盘总共可以容纳 `n^2` 个棋子。
- 第 2 到 `n+1` 行输入 `n` 个数字。每次输入 `n` 个数,其中 `1` 代表有棋子,`0` 代表没有棋子。
## 输出格式
- 如果有 `n` 个可放置点,输出 `n` 行。
- 每行输出两个数字,以空格分隔,分别代表放置点在棋盘上的行数和列数。
- 输出顺序需要按照行数从小到大、列数从小到大的顺序。
## 输入样例
```
6
0 0 0 0 0 0
0 1 0 0 0 0
0 0 1 0 0 0
0 0 0 1 0 0
0 0 0 0 1 0
0 0 0 0 0 0
```
## 输出样例
1 1
6 6
## 数据范围
- 第一行中,棋盘宽度为 `[1, 10)` 中的整数。
- 第 2 到 `n+1` 行中,只会出现 `0` 或 `1`。问题分析:
这个题目跟我之前做过的一个题目很像,那个是动态的,双方互相落子判断谁胜利,这个是给你一个棋局,没有黑白方,判断落子胜利有几种方式,原理就是落子时,判断上下左右左斜右斜,且在规定范围内,是否可以达到五子连珠。
代码如下:
#include <iostream>
#include <vector>
#include <utility>
#include <sstream>
using namespace std;
// 函数检查某个位置可以形成五子连线
bool canFormLine(int x, int y, const vector<vector<int>>& board, int n) {
// 定义四个方向:右,下,右下,左下
int directions[4][2] = {{1, 0}, {0, 1}, {1, 1}, {1, -1}};
for (auto& dir : directions) {
int count = 1; // 当前位置记为1
int dx = dir[0], dy = dir[1];
// 检查正向
for (int step = 1; step < 5; ++step) {
int nx = x + dx * step;
int ny = y + dy * step;
if (nx >= 0 && nx < n && ny >= 0 && ny < n && board[nx][ny] == 1) {
count++;
} else {
break;
}
}
// 检查反向
for (int step = 1; step < 5; ++step) {
int nx = x - dx * step;
int ny = y - dy * step;
if (nx >= 0 && nx < n && ny >= 0 && ny < n && board[nx][ny] == 1) {
count++;
} else {
break;
}
}
// 如果形成五子连接,则返回 true
if (count >= 5) return true;
}
return false; // 没有符合条件的连线
}
// 主解决方案函数
string solution(int n, vector<vector<int>>& board) {
vector<pair<int, int>> results;
// 检查每个位置是否能放置新棋子形成五子连线
for (int i = 0; i < n; ++i) {
for (int j = 0; j < n; ++j) {
if (board[i][j] == 0) { // 只检查空位
if (canFormLine(i, j, board, n)) {
results.emplace_back(i + 1, j + 1); // 记录行列,+1因要求从1开始
}
}
}
}
// 格式化输出结果
stringstream ss;
ss << "{";
for (size_t i = 0; i < results.size(); ++i) {
ss << "{" << results[i].first << ", " << results[i].second << "}";
if (i < results.size() - 1) {
ss << ", "; // 不在最后一个元素后添加逗号
}
}
ss << "}"; // 结束括号
return ss.str(); // 返回结果字符串
}
int main() {
vector<vector<int>> array = {
{0, 0, 0, 0, 0, 0},
{0, 1, 0, 0, 0, 0},
{0, 0, 1, 0, 0, 0},
{0, 0, 0, 1, 0, 0},
{0, 0, 0, 0, 1, 0},
{0, 0, 0, 0, 0, 0}
};
//cout << solution(6, array) << endl;
cout << (solution(6, array) == "{{1, 1}, {6, 6}}") << endl;
return 0;
}运行结果:
困难题目
已完成 2
8 进制求和转换
# 问题描述
给定两个二进制字符串,返回他们的和(用十进制字符串表示)。输入为非空字符串且只包含数字 1 和 0 ,请考虑大数问题。时间复杂度不要超过 O(n^2),其中 n 是二进制的最大长度。
## 输入格式
每个样例只有一行,两个二进制字符串以英文逗号“,”分割
## 输出格式
输出十进制格式的两个二进制的和
**输入样例**:
101,110
**输出样例**:
11
**数据范围**:
每个二进制不超过 100 个字符,JavaScript 语言下请考虑大数的情况。问题分析:
- 函数签名:
-
string addBinary(const string &a, const string &b):这个函数接收两个二进制字符串,并返回它们的十进制和作为字符串。
- 变量初始化:
-
string result;:用于存储二进制加法的中间和最终结果(在反转之前)。int carry = 0;:初始化进位为0。int i = a.size() - 1;和int j = b.size() - 1;:分别初始化两个字符串的索引,从末尾开始遍历。
- 循环逻辑:
-
while (i >= 0 || j >= 0 || carry):当任一字符串还有未处理的位或存在进位时,继续循环。- 在循环内部,首先处理进位,然后根据索引
i和j的有效性,将对应位置的字符转换为数字并加到sum上。 - 更新进位
carry和结果字符串result。
- 结果处理:
-
reverse(result.begin(), result.end());:由于是从字符串末尾开始构建结果,因此最后需要反转字符串。long long decimalSum = stoll(result, 0, 2);:将二进制字符串转换为十进制长整数。这一步实际上是多余的,因为题目要求返回的是十进制字符串,而不是长整数。return to_string(decimalSum);:将十进制长整数转换回字符串并返回。由于前面的stoll转换是多余的,这一步也可以优化为直接返回result字符串(在反转之后)。
代码如下:
#include <iostream>
#include <string>
#include <algorithm>
using namespace std;
// 函数用于二进制字符串的加法
string addBinary(const string &a, const string &b) {
string result;
int carry = 0; // 进位
int i = a.size() - 1;
int j = b.size() - 1;
while (i >= 0 || j >= 0 || carry) {
int sum = carry; // 先将进位加上
if (i >= 0) {
sum += a[i] - '0'; // 将字符转换为数字
i--;
}
if (j >= 0) {
sum += b[j] - '0'; // 将字符转换为数字
j--;
}
carry = sum / 2; // 计算新的进位
result.push_back((sum % 2) + '0'); // 结果取余,转换为字符
}
reverse(result.begin(), result.end()); // 反转结果
long long decimalSum = stoll(result, 0, 2);
return to_string(decimalSum);
}
// 主函数
int main() {
// You can add more test cases here
std::cout << (addBinary("101", "110") == "11") << std::endl;
std::cout << (addBinary("111111", "10100") == "83") << std::endl;
std::cout << (addBinary("111010101001001011", "100010101001") == "242420") << std::endl;
std::cout << (addBinary("111010101001011", "10010101001") == "31220") << std::endl;
return 0;
}运行结果:
27 查找热点数据
# 问题描述
给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按任意顺序返回答案。
- 1 <= nums.length <= 10^5
- k 的取值范围是 [1, 数组中不相同的元素的个数]
- 题目数据保证答案唯一,换句话说,数组中前 k 个高频元素的集合是唯一的
你所设计算法的时间复杂度必须优于 O(n log n) ,其中 n 是数组大小。
**示例 1**
输入: nums = [1,1,1,2,2,3], k = 2
输出: [1,2]
**示例 2**
输入: nums = [1], k = 1
输出: [1]问题分析:
- 参数:
-
vector<int>& nums: 输入的整数数组。int k: 需要返回的前k个高频元素的数量。
- 局部变量:
-
unordered_map<int, int> freqMap: 用于存储每个数字的频率。vector<pair<int,int>> result: 存储哈希表中的键值对(数字及其频率)。stringstream ss: 用于构建最终返回的字符串。
- 逻辑流程:
-
- 构建频率映射: 遍历输入数组
nums,使用unordered_map记录每个数字的频率。 - 存储映射到结果向量: 将
freqMap中的每个键值对(数字及其频率)添加到result向量中。 - 排序: 使用
sort函数对result向量进行排序,排序依据是元素的频率(降序)。 - 构建返回字符串: 遍历排序后的
result向量的前k个元素,将它们转换为字符串并使用逗号分隔,存储在stringstream中。 - 返回结果: 将
stringstream中的内容转换为字符串并返回。
- 构建频率映射: 遍历输入数组
代码如下:
#include <iostream>
#include <vector>
#include <unordered_map>
#include <queue>
#include <sstream>
#include <algorithm>
using namespace std;
string topKFrequent(vector<int>& nums, int k) {
// 使用哈希表记录每个元素的频率
unordered_map<int, int> freqMap;
for (int num : nums) {
freqMap[num]++;
}
vector<pair<int,int>> result;
for(auto x : freqMap){
result.push_back(x);
}
sort(result.begin(), result.end(), [](const pair<int, int>& a, const pair<int, int>& b) {
return a.second > b.second;
});
stringstream ss;
for (size_t i = 0; i < k; ++i) {
ss << result[i].first;
if (i < k - 1) {
ss << ",";
}
}
return ss.str();
}
int main() {
// You can add more test cases here
std::vector<int> nums1 = {1, 1, 1, 2, 2, 3};
std::vector<int> nums2 = {1};
//cout << topKFrequent(nums1, 2) << endl;
std::cout << (topKFrequent(nums1, 2) == "1,2") << std::endl;
std::cout << (topKFrequent(nums2, 1) == "1") << std::endl;
return 0;
}运行结果:


















 2153
2153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











