







目录
7 下载 ssh 工具(vscode可以直接在本地打开不需要映射)
1 购买autoDL服务器
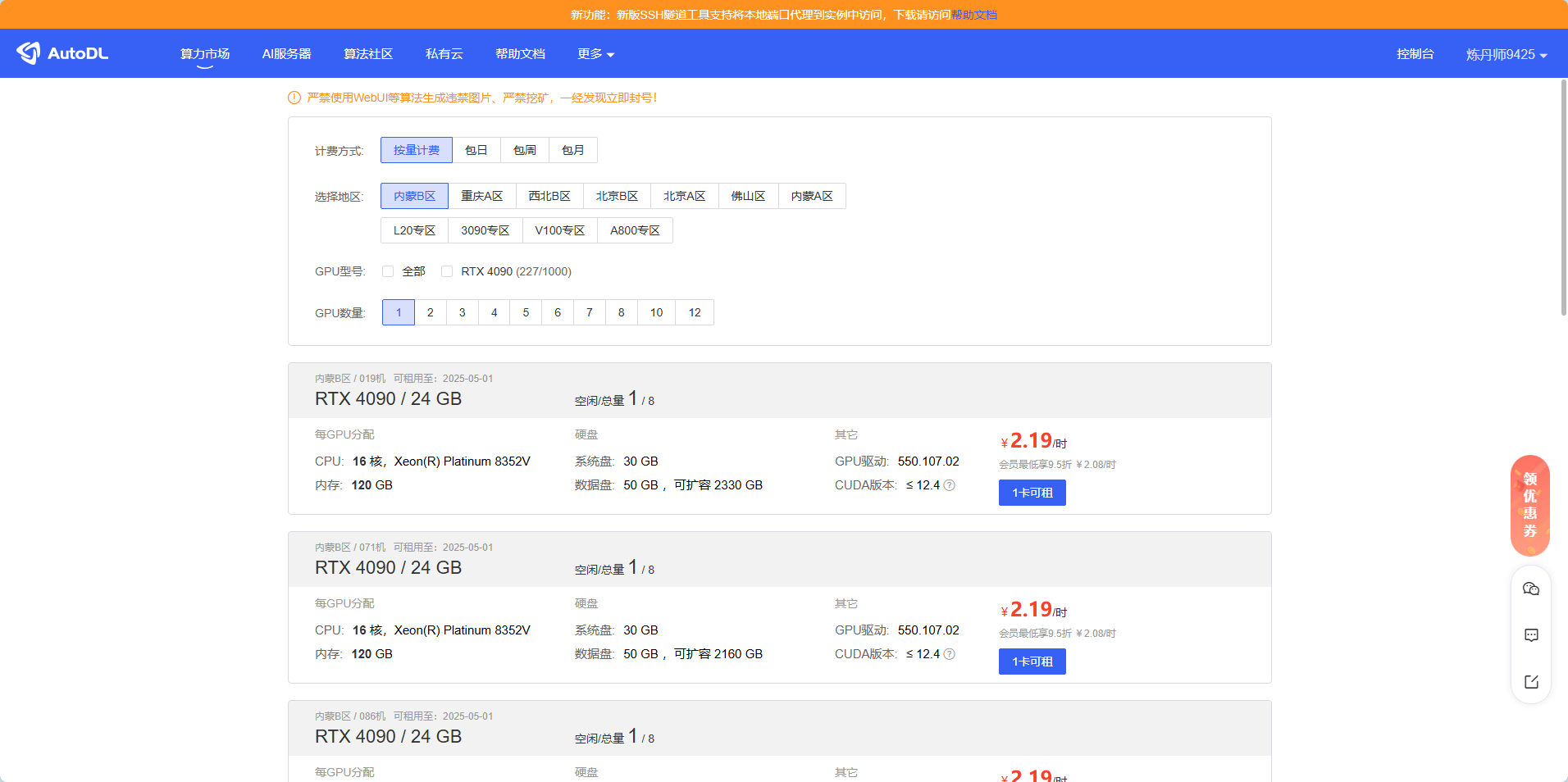
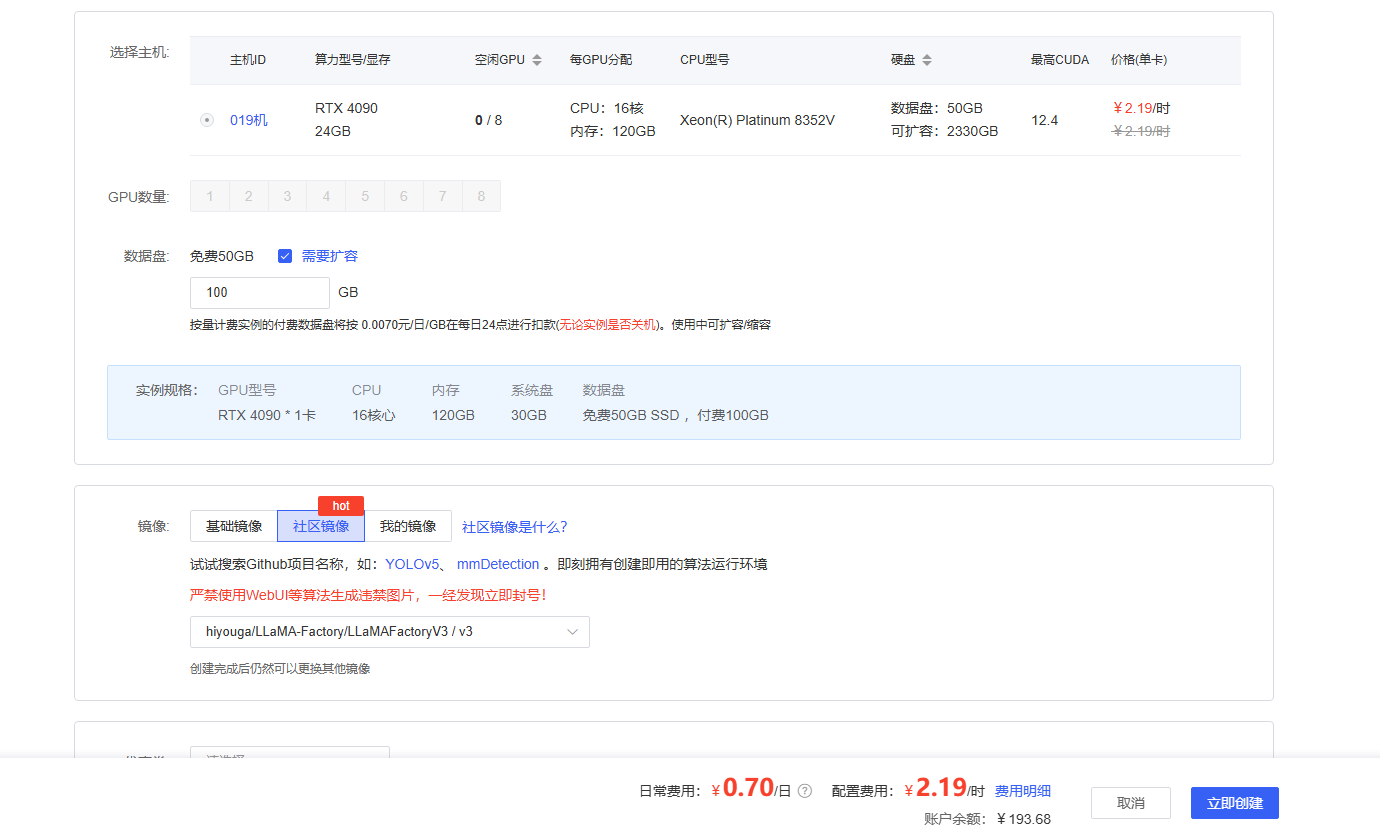
2 使用JupyterLab连接实例 或者使用vscode


vscdoe如下
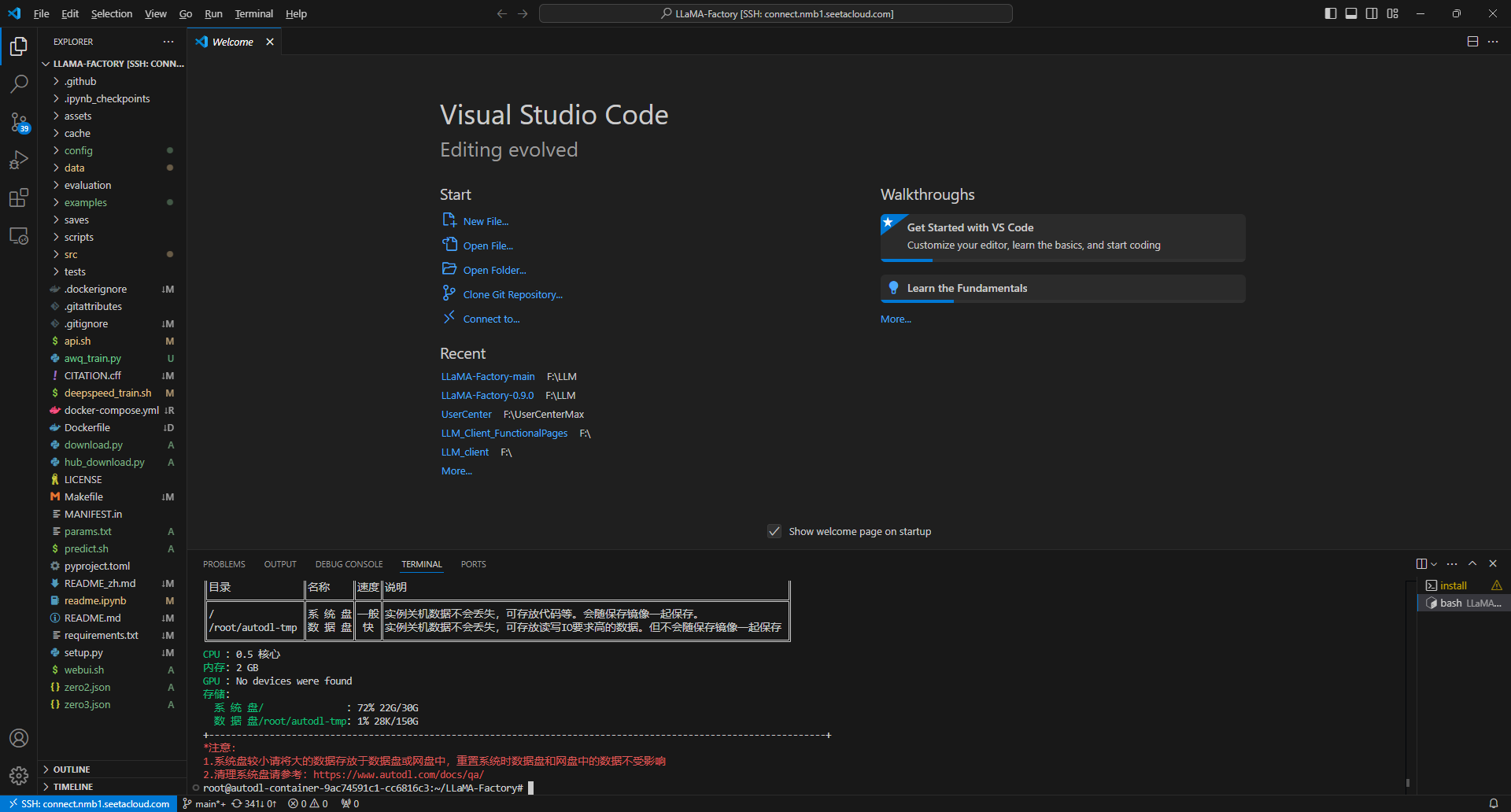
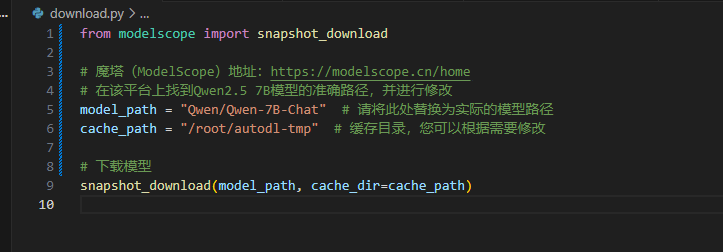
3 下载魔塔模型
修改download.py 文件 下载模型
from modelscope import snapshot_download
# 魔塔(ModelScope)地址:https://modelscope.cn/home
# 在该平台上找到Qwen2.5 7B模型的准确路径,并进行修改
model_path = "Qwen/Qwen2.5-7B-Instruct" # 请将此处替换为实际的模型路径
cache_path = "/root/autodl-tmp" # 缓存目录,您可以根据需要修改
# 下载模型
snapshot_download(model_path, cache_dir=cache_path)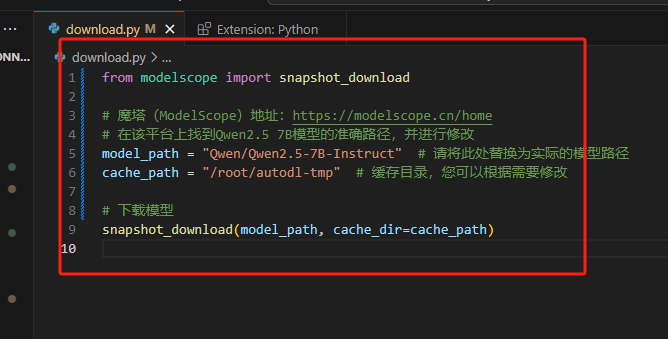
运行download.py文件 下载对应模型


4 学术加速
source /etc/network_turbo

5 下载Hugging Face模型
6 启动webui
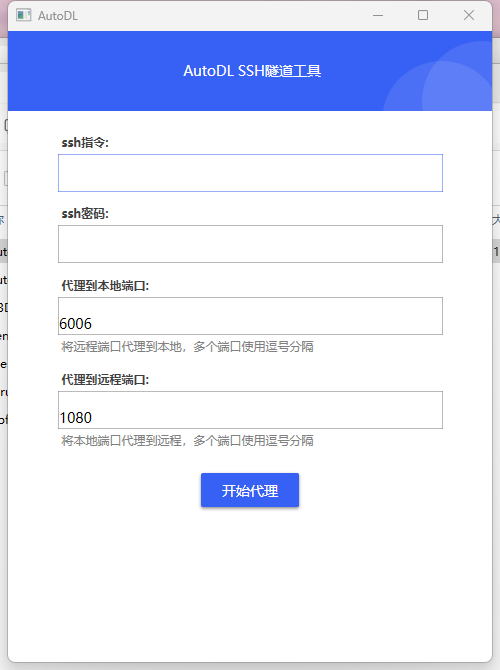
7 下载 ssh 工具(vscode可以直接在本地打开不需要映射)
运行 AutoDL.exe文件
8 模型加载和使用
加载模型
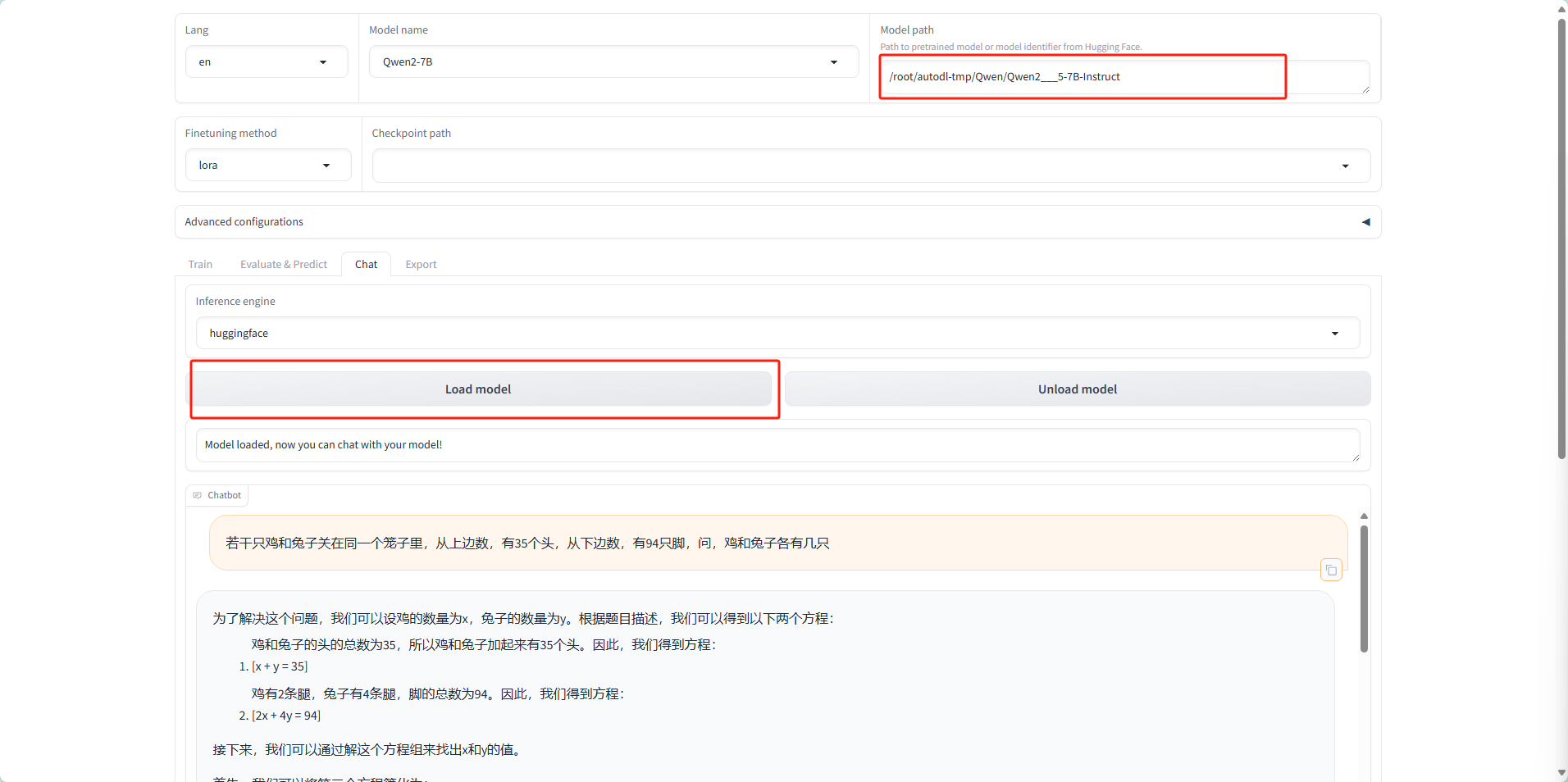
使用模型

微微调参数:
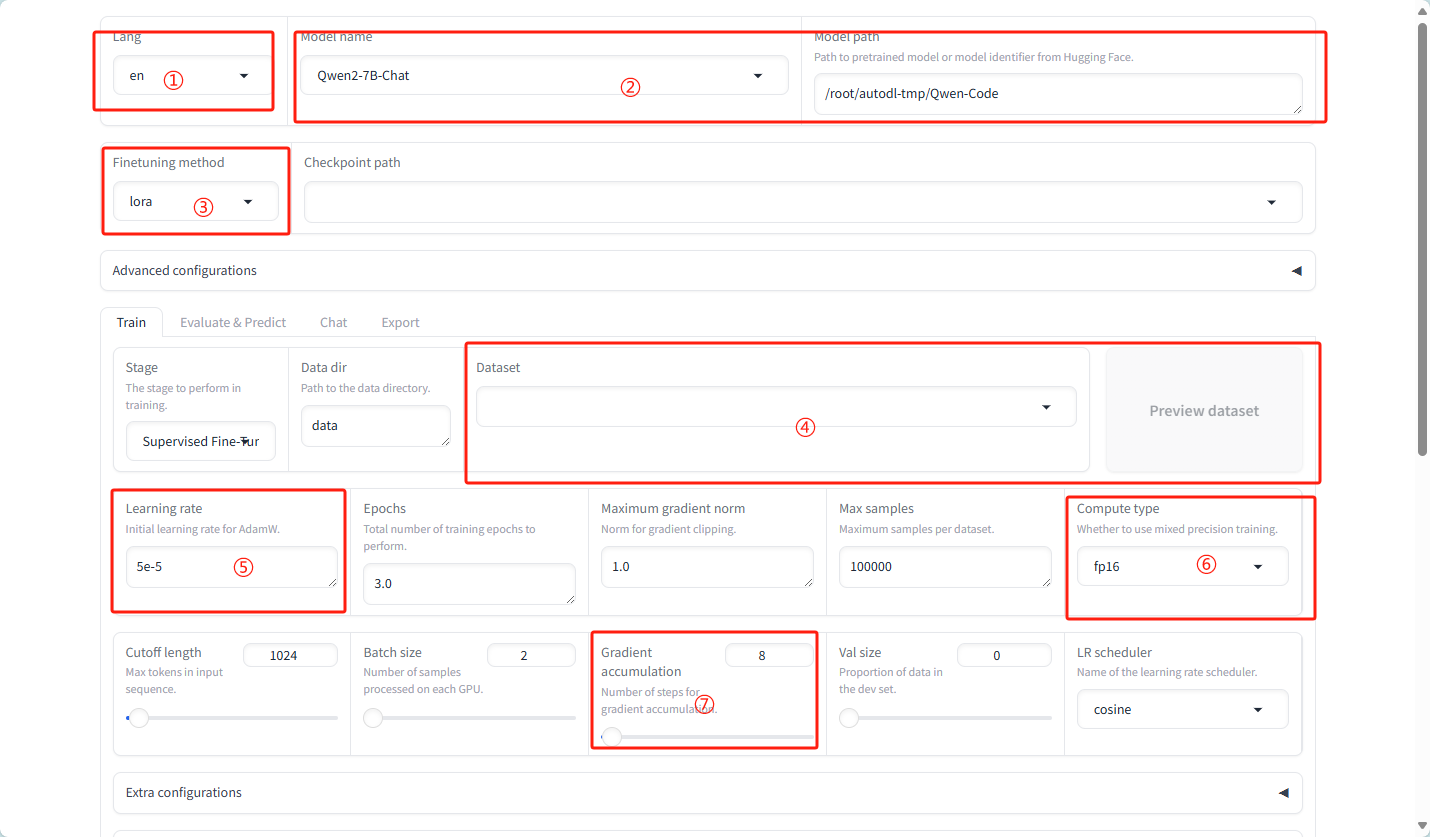
①语言:选择模型支持的语言,例如zh。
②模型名称:选择要微调的模型,例如LLaMA3-8B-Chat。
③微调方法:选择微调技术,如lora。
④数据集:选择用于训练的数据集。
⑤学习率:设置模型训练的学习率。
⑥计算类型:根据GPU类型选择计算精度,如bf16或fp16。
bf16(bfloat16):
- 定义与结构:bf16,即Brain Floating Point 16-bit,是一种16位浮点数格式,主要用于深度学习和机器学习中的高效计算。它包含1位符号位、8位指数位和7位尾数位。
- 特点:
- 指数范围广泛:由于使用了8位指数,bf16能够表示的数值范围与32位浮点数(FP32)相同,大约是±3.4×10-38。这使得bf16在表示大范围数值时具有优势。
- 尾数精度较低:与FP32的23位尾数相比,bf16的7位尾数位导致其在表示精确小数时精度较低。然而,这种精度损失在深度学习中通常是可以接受的,因为深度学习模型往往对数值的精确性要求不如传统数值计算高。
- 存储和计算效率高:与FP32相比,bf16所需的存储和内存带宽减少了一半。这使得硬件可以在同样的带宽和存储容量下处理更多的数据,从而加速深度学习模型的训练和推理过程。
- 应用场景:bf16主要用于深度学习的训练和推理过程,特别是在需要大量计算的场景下,如大规模神经网络训练。
fp16(半精度浮点数):
- 定义与结构:fp16,即16位浮点数表示法,也称为半精度浮点数。它包含1位符号位、5位指数位和10位尾数位。
- 特点:
- 指数范围较小:与bf16相比,fp16的5位指数位限制了其表示的数值范围。其最大正数为6.55×10^4,这可能导致在某些情况下发生溢出或下溢。
- 尾数精度较高:尽管fp16的指数范围较小,但其10位尾数位使得它在表示精确小数时具有较高的精度。这使得fp16在某些对精度要求较高的应用中具有优势。
- 计算速度快:由于fp16的数据长度较短,它在进行计算时能够更快地处理数据,从而加速训练和推理过程。
- 应用场景:fp16常用于加速深度学习的训练和推理过程,特别是在对内存和计算资源有限制的场景中。然而,由于其指数范围较小,可能需要采取额外的措施来防止溢出或下溢问题。
⑦梯度累计:设置梯度累计的批次数。
9 多GPU微调Lora
nohup bash deepspeed_train.sh &
![]()
10 大模型微调示例
更改模型:因为我的数据是对话模式的,所以需要使用chat级别的模型
改为Qen-7B-Chat
对话数据集
上传到项目下的data/chat 目录下
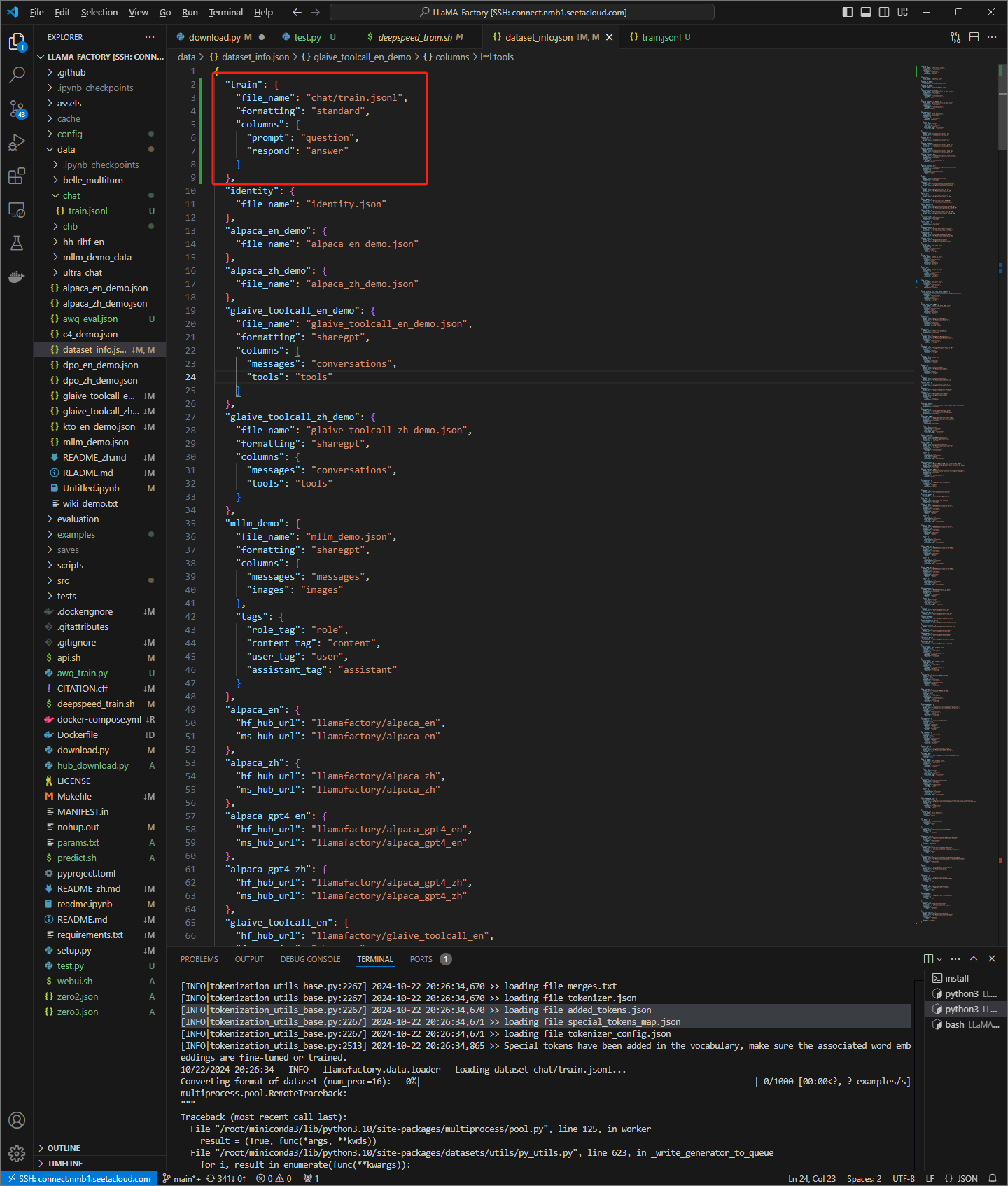
设置dataset_info.json文件
添加如下内容
"train": {
"file_name": "chat/train.jsonl",
"formatting": "standard",
"columns": {
"prompt": "question",
"respond": "answer"
}
}
选择数据集
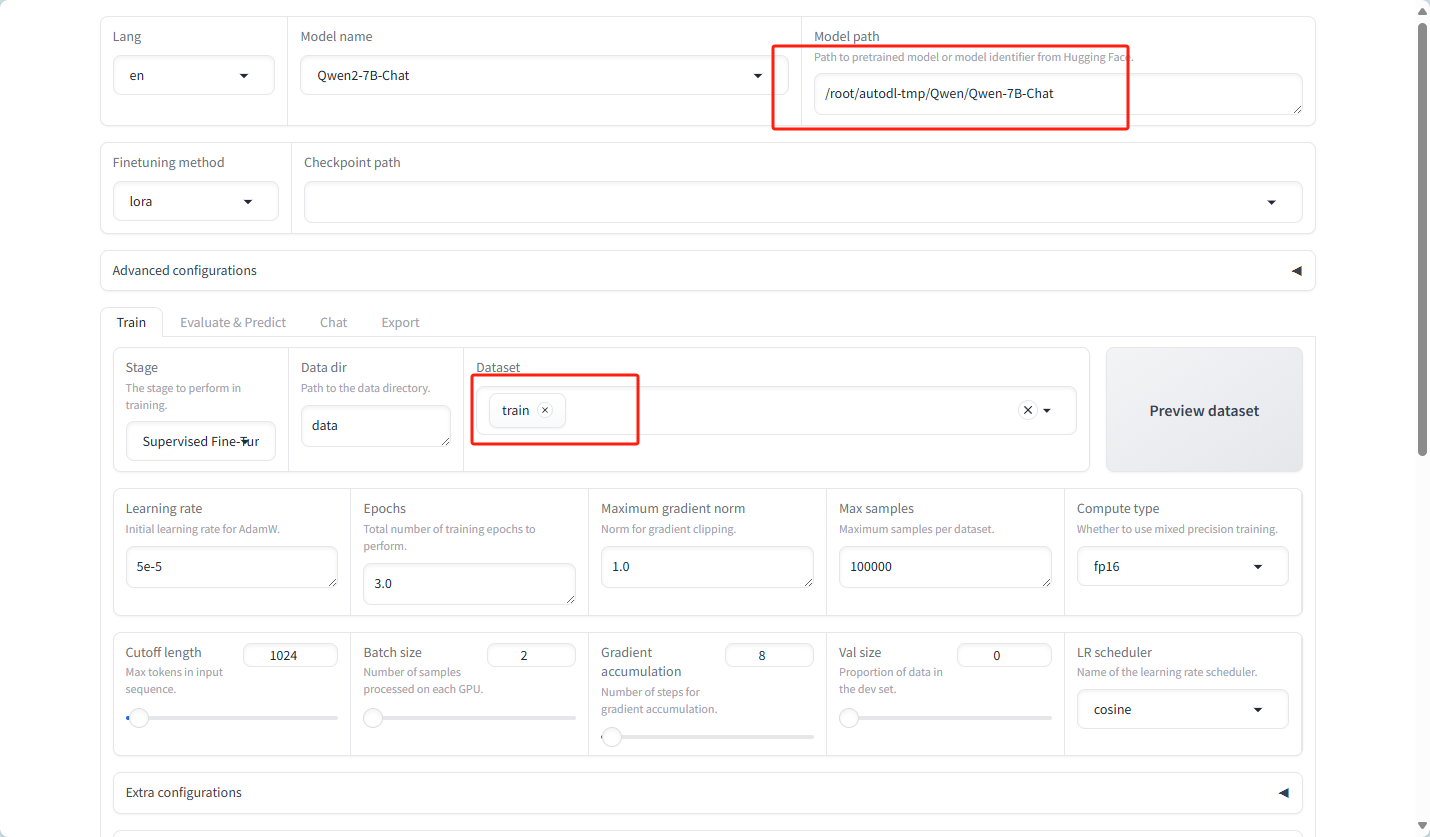
开始训练
更改为chat模型后,仍然和instruct模型相同的错误
train数据集
dataset_info.json 文件
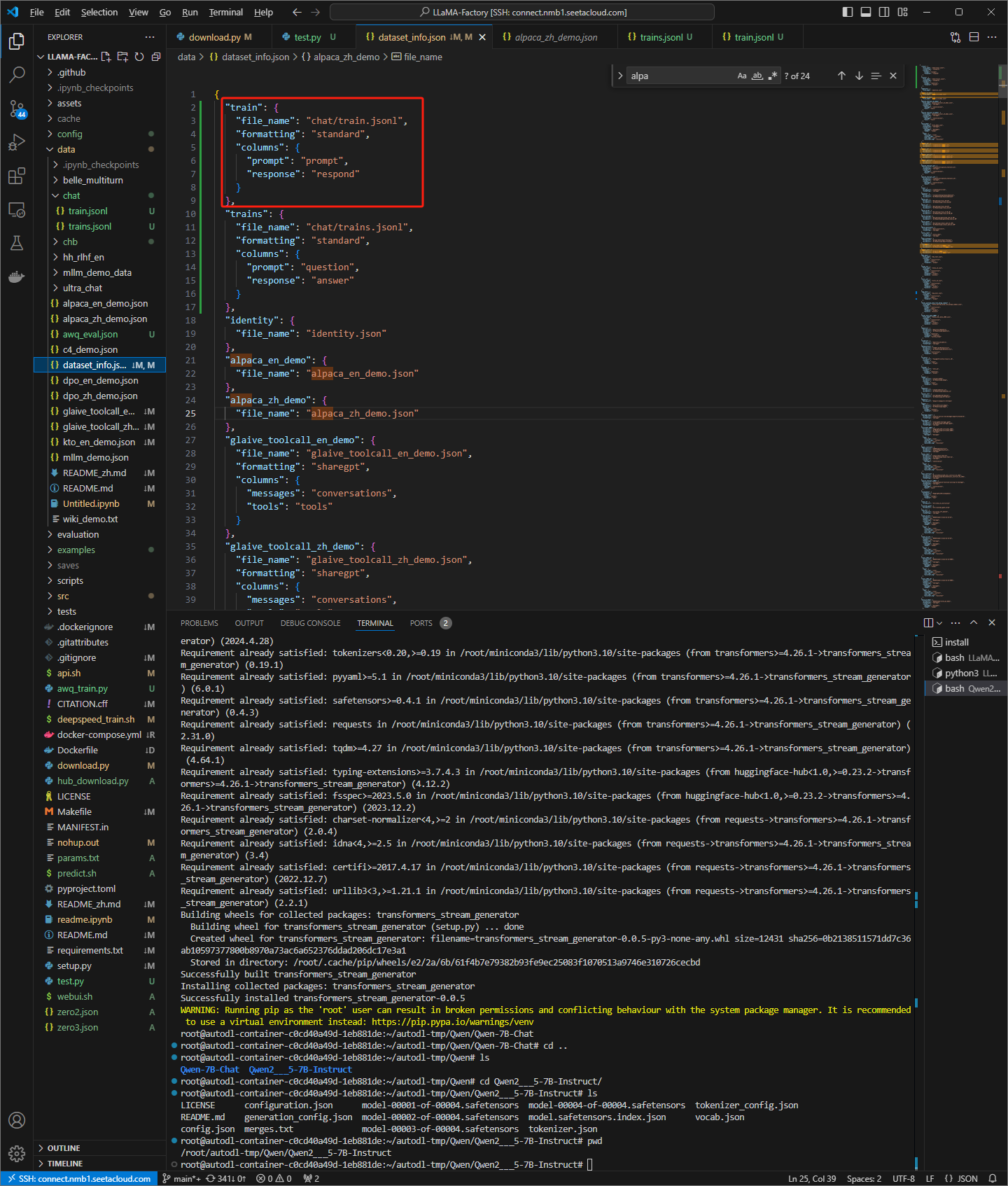

更换为trains数据集,仍然报和instruct模型相同的错误
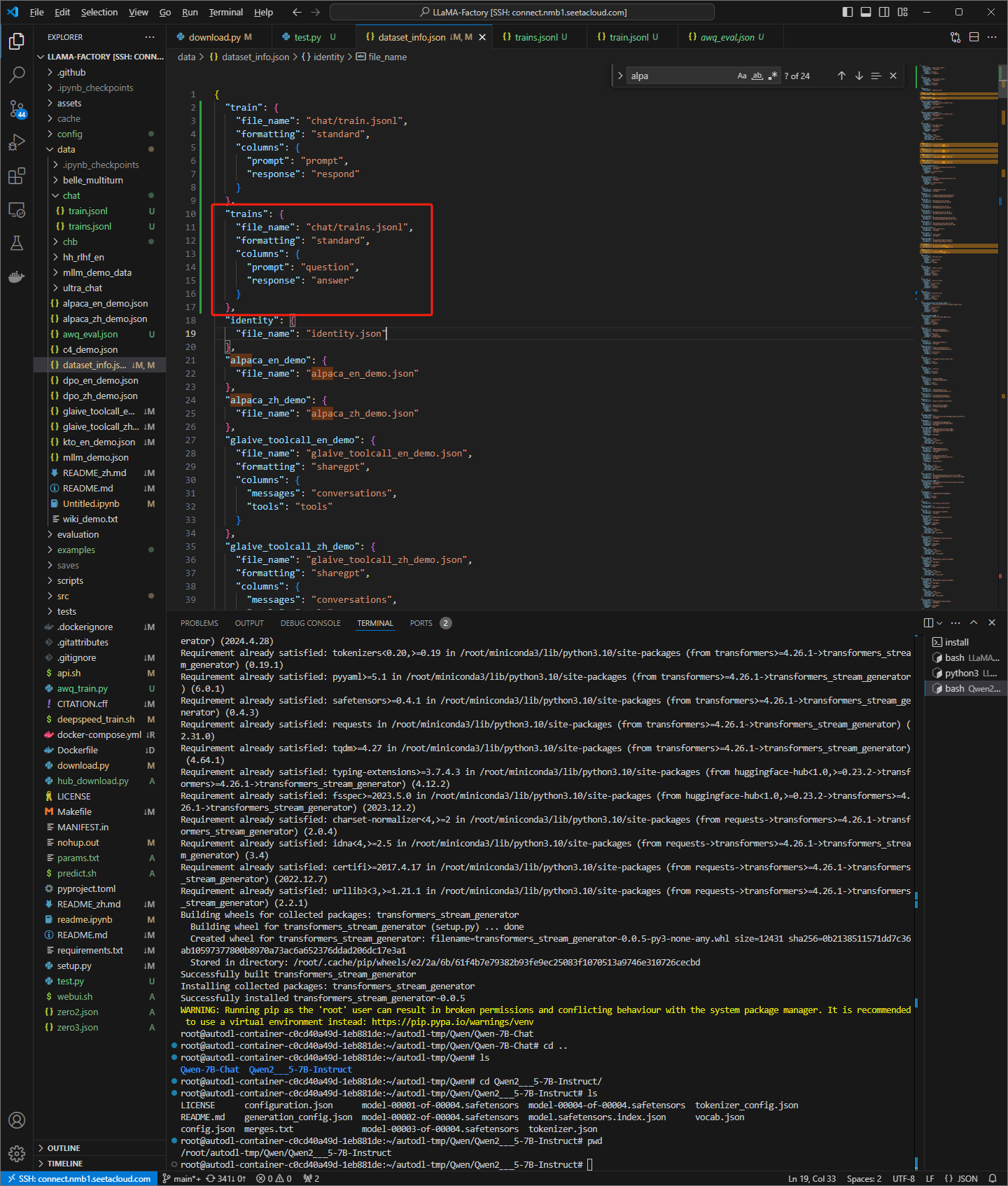
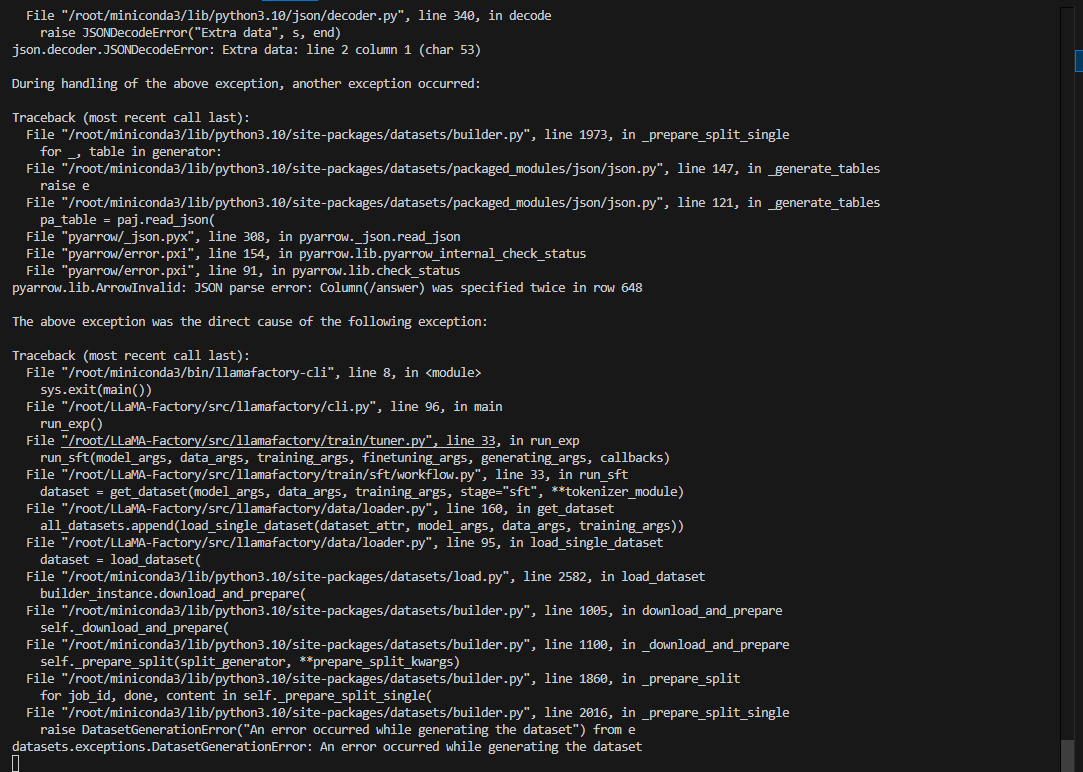
所以可能有两个问题
1 是我的dataset_info写的有问题 2 是模型问题
所以我选择项目自带的数据
alpaca_zh_demo.json
运行后,数据梳理通过,但是
GPU的显存不够
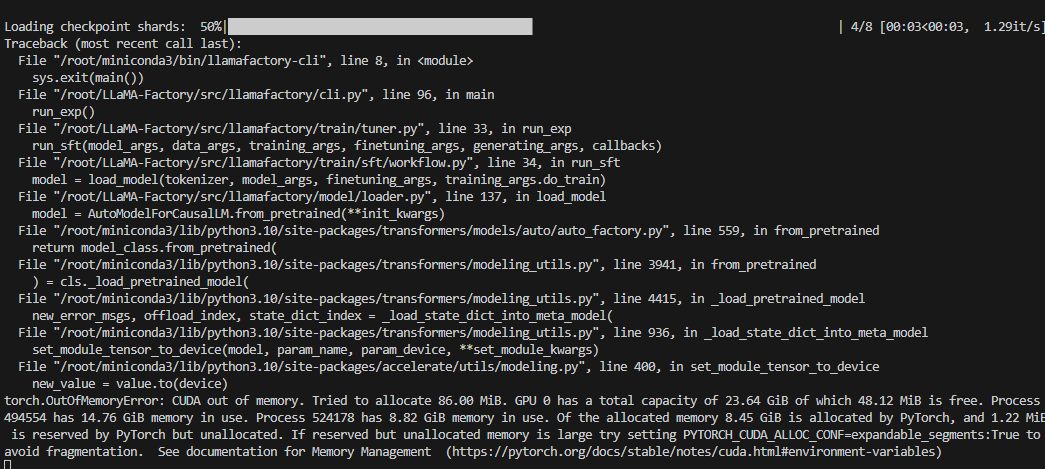
所以我选择换回我的instruct模型,仍然溢出
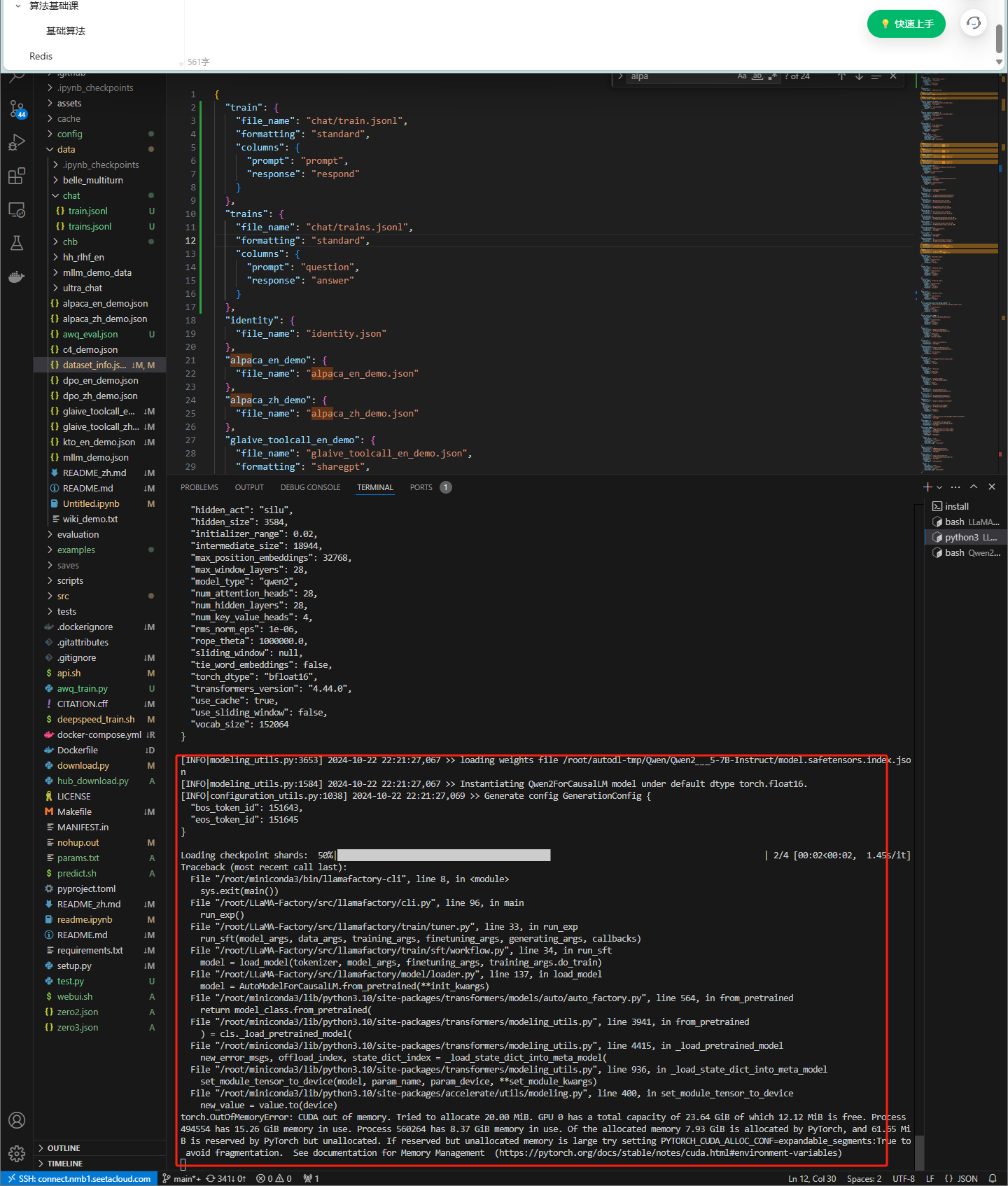
后面我仔细阅读文档,修改了 dataset_info.json文件,可以通过数据,达到内存溢出哪一步
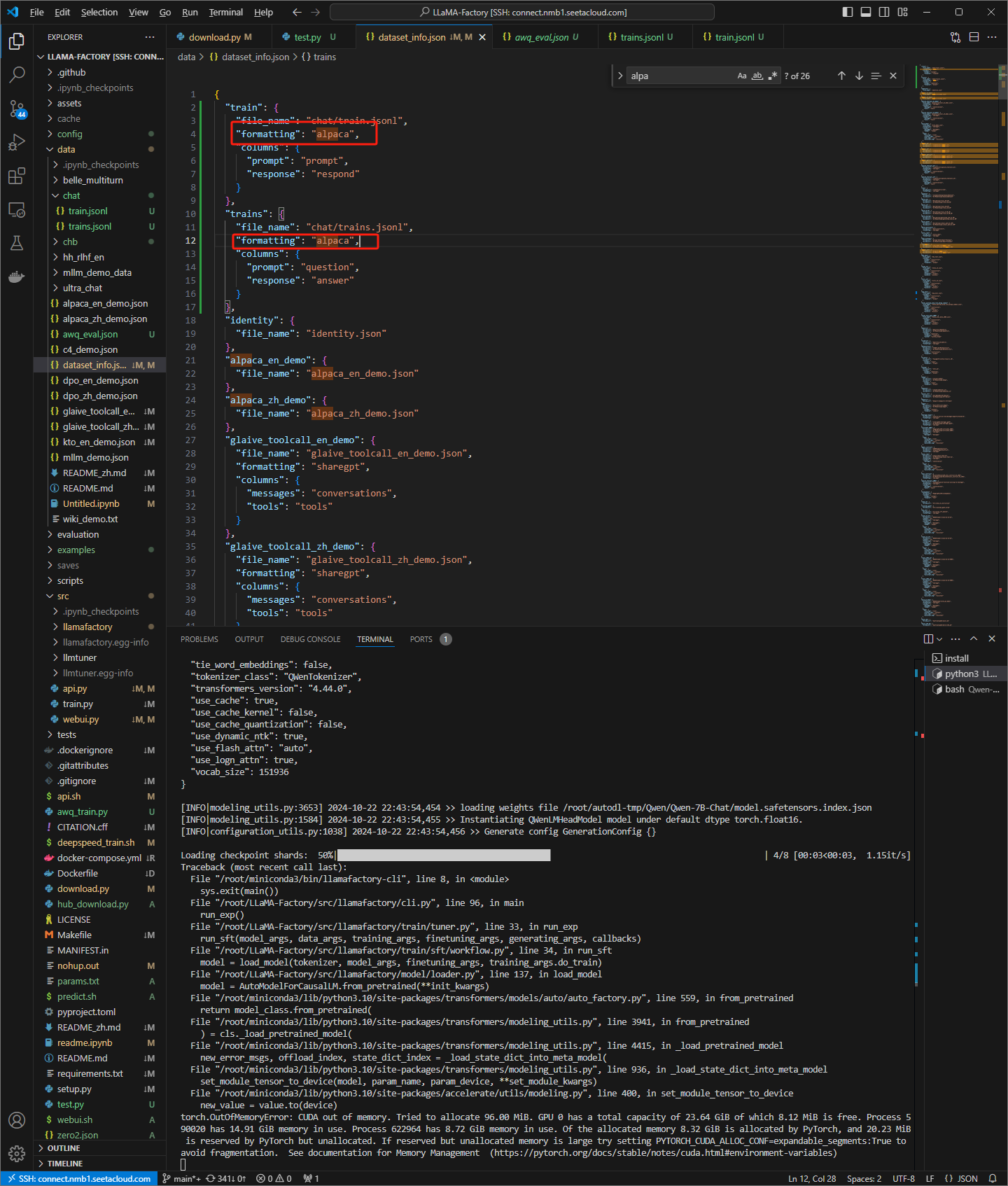
如何解决溢出问题?小点的模型已经尝试过,还有清理碎片,释放显存等
尝试增加到两张显卡
成功 开始训练
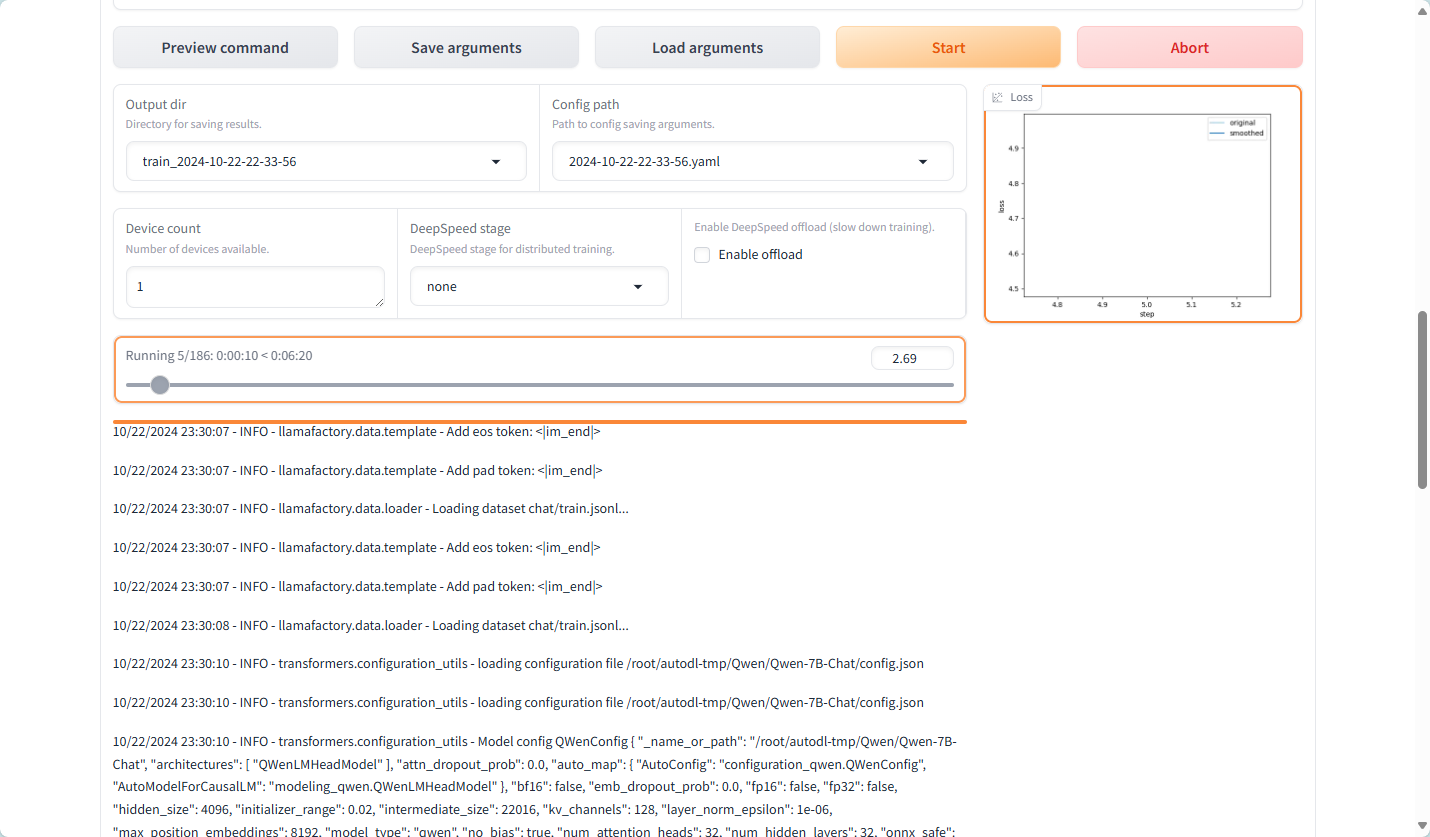
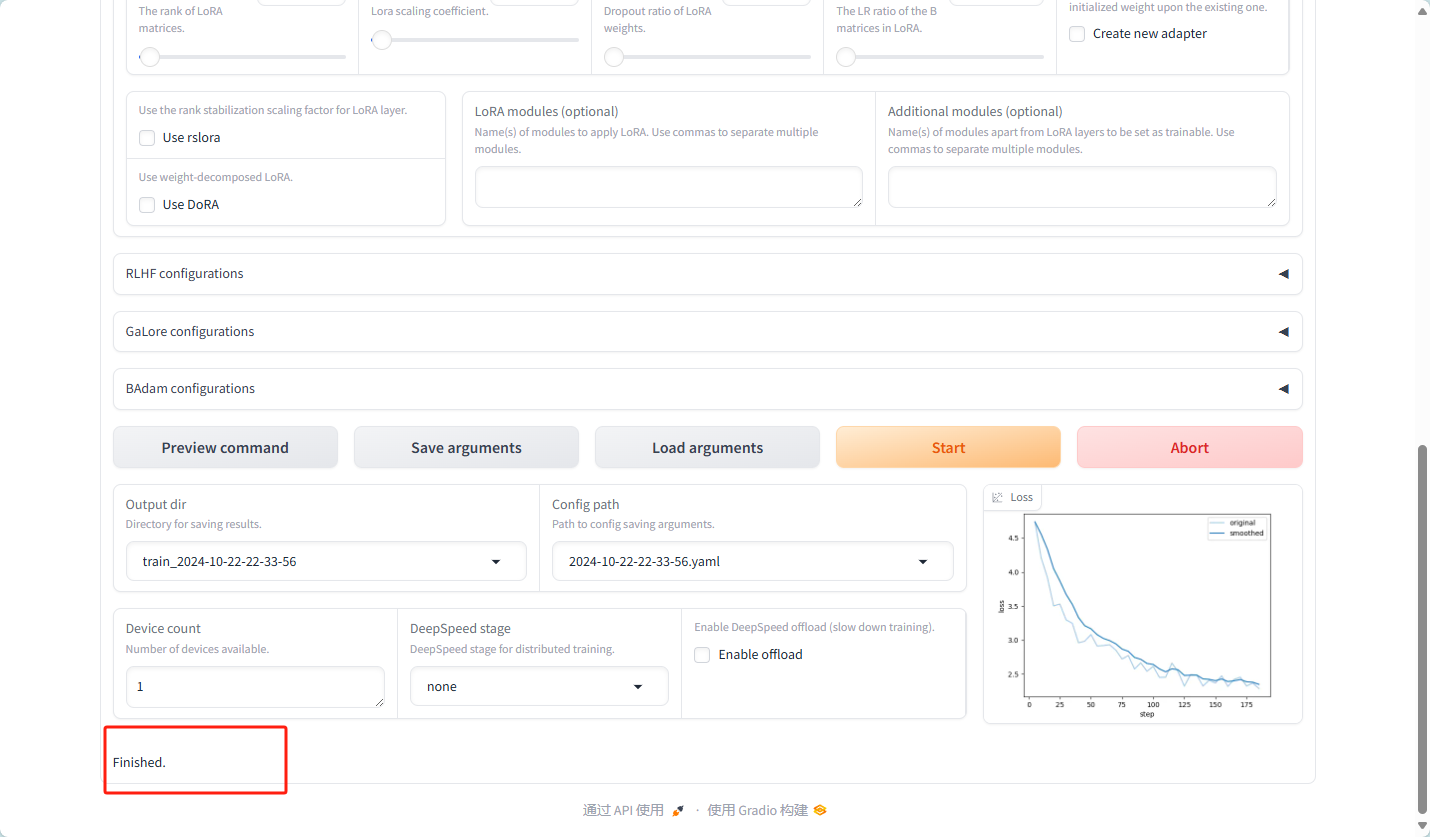
训练结果的文件夹
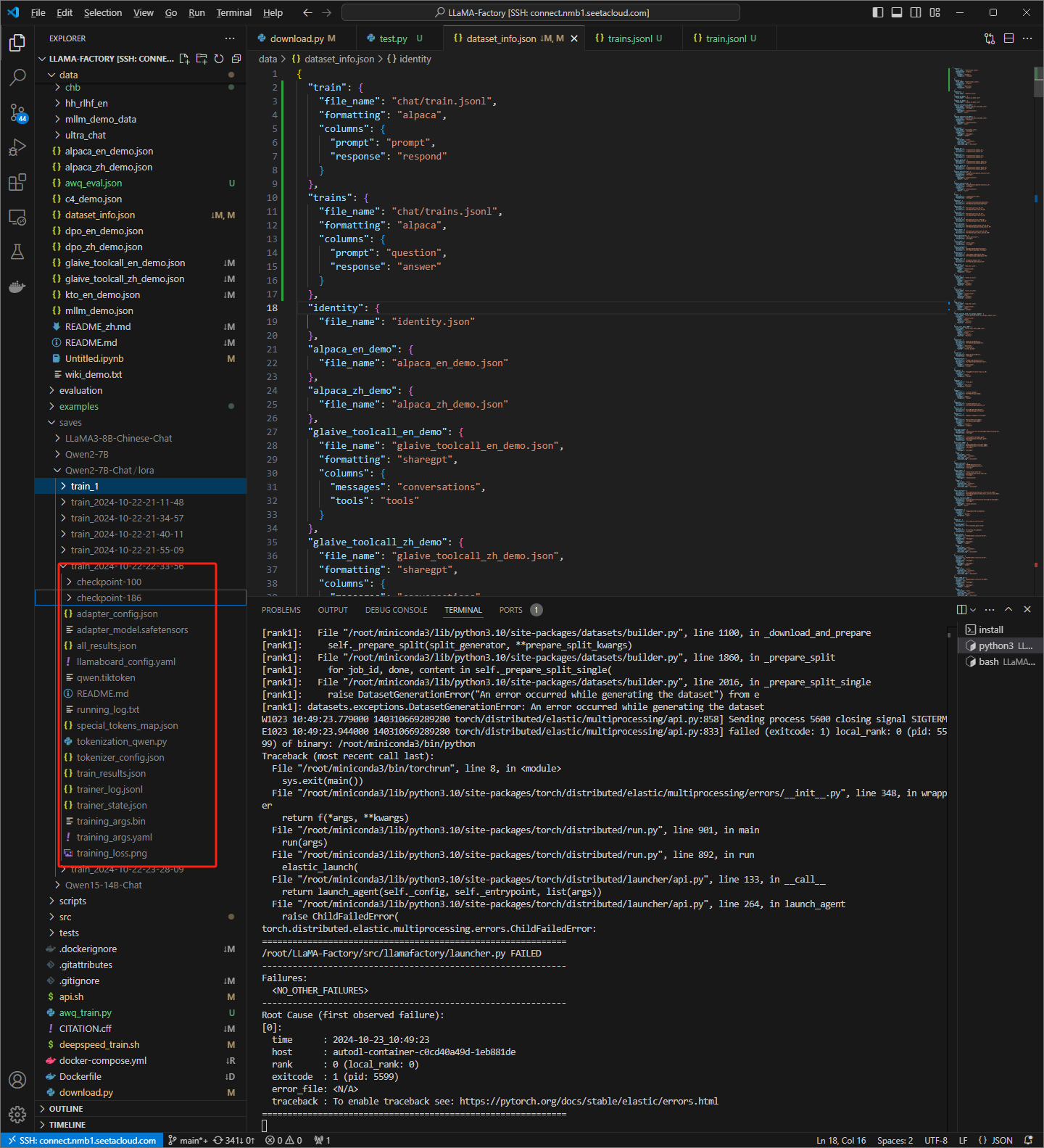
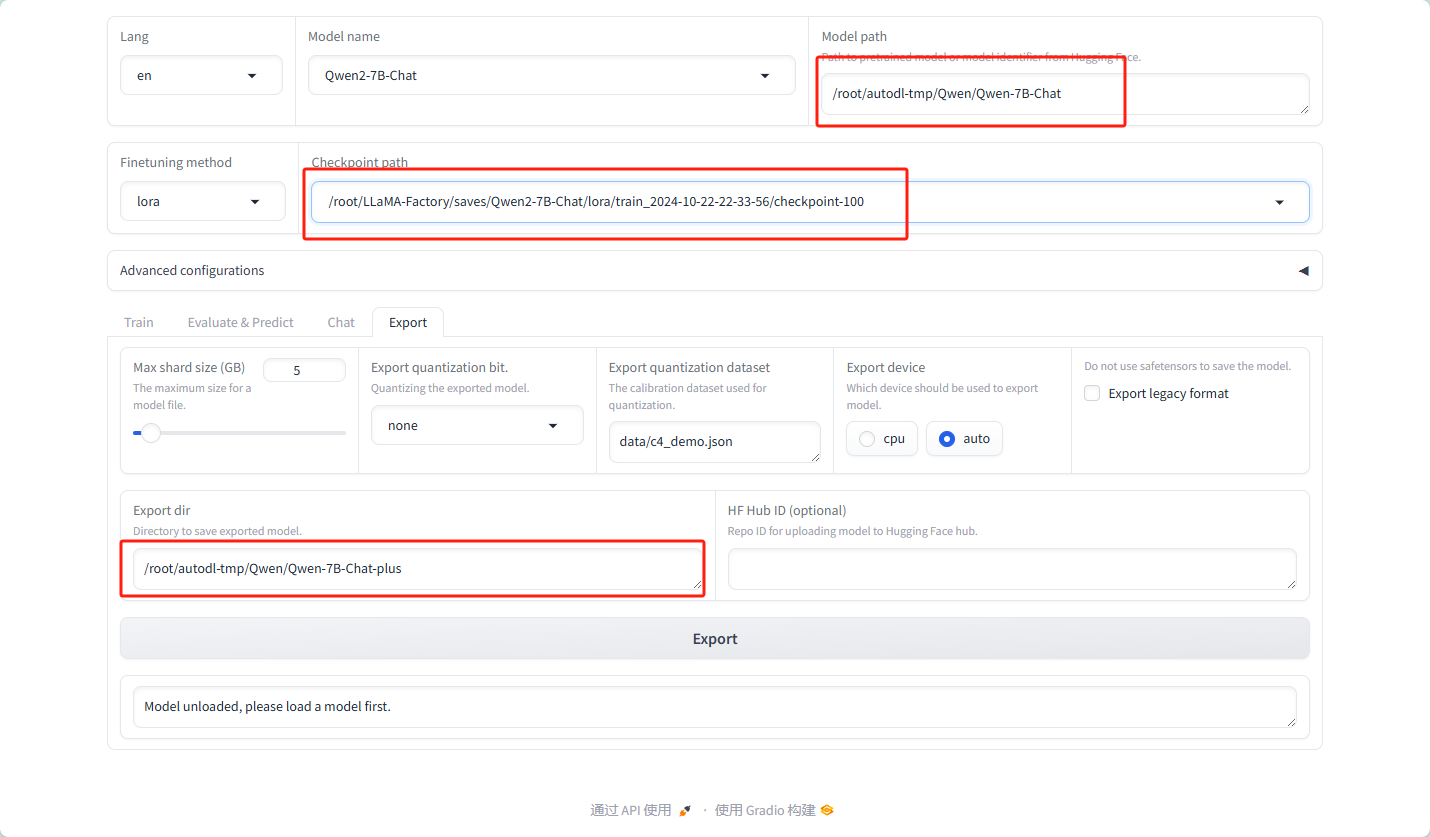
将结果的路径
/root/LLaMA-Factory/saves/Qwen2-7B-Chat/lora/train_2024-10-22-22-33-56/checkpoint-100
输出目录
/root/autodl-tmp/Qwen/Qwen-7B-Chat-plus
但是 结果路径也可以直接使用训练结果的文件夹,会有训练成功的下拉框选项
详细导出参数:
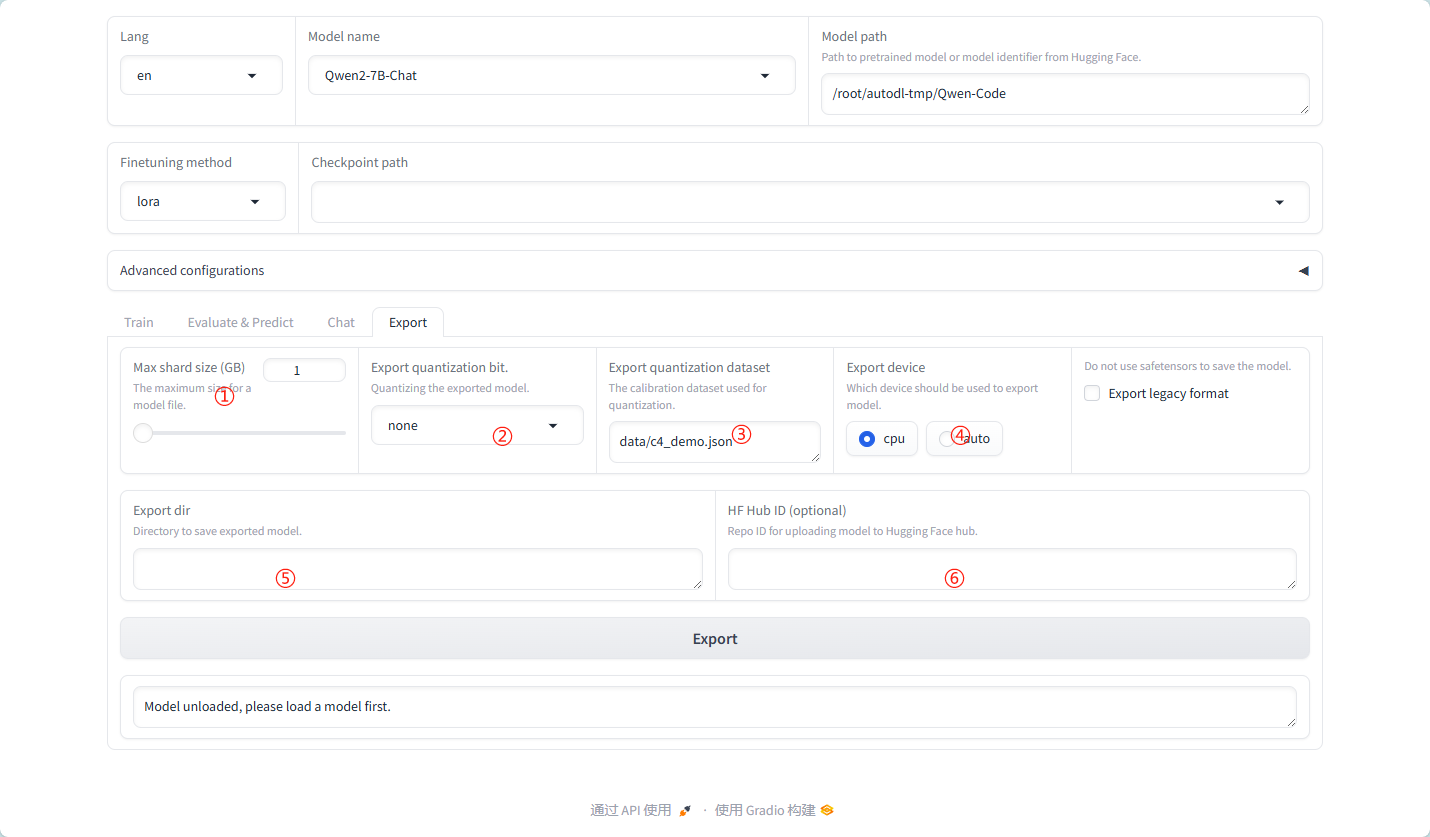
① MAX shard size:
这个参数定义了模型分片(shard)的最大大小。在导出大型模型时,由于内存或存储限制,模型可能需要被分割成多个较小的部分(即分片)进行存储和处理。通过设置MAX shard size,用户可以控制每个分片的大小,以确保它们能够适配到目标存储或计算环境中。
② Export quantization bit:
此参数用于指定模型导出时量化的位数。量化是一种减少模型大小和加速推理速度的技术,它通过将模型参数从较高的精度(如32位浮点数)降低到较低的精度(如8位整数)来实现。通过设置Export quantization bit,用户可以控制量化的粒度,从而影响模型的压缩率和性能。
③ Export quantization dataset:
这个参数指定了一个数据集,用于在导出模型时执行量化操作。在量化过程中,模型会使用这个数据集进行校准,以确保量化后的模型在推理时具有足够的准确性。选择适当的量化数据集对于获得良好的量化效果至关重要。
④ Export device:
此参数指定了模型导出时所使用的设备。在分布式或并行计算环境中,模型可以在不同的设备上(如CPU、GPU或TPU)进行导出。通过设置Export device,用户可以指定在哪个设备上执行导出操作,以充分利用可用的计算资源。
⑤ Export dir:
这个参数定义了模型导出时的目标目录。在导出模型时,用户需要指定一个存储位置来保存导出的模型文件。通过设置Export dir,用户可以控制模型文件的存储路径和文件名,以便于后续的管理和使用。
⑥ HF Hub ID:
此参数与Hugging Face Hub相关,它指定了一个唯一的标识符(ID),用于将导出的模型上传到Hugging Face Hub上。Hugging Face Hub是一个流行的机器学习模型库,用户可以在其中共享和下载模型。通过设置HF Hub ID,用户可以轻松地将自己的模型上传到Hugging Face Hub上,以便与其他人共享和使用。
导出的模型如下图:

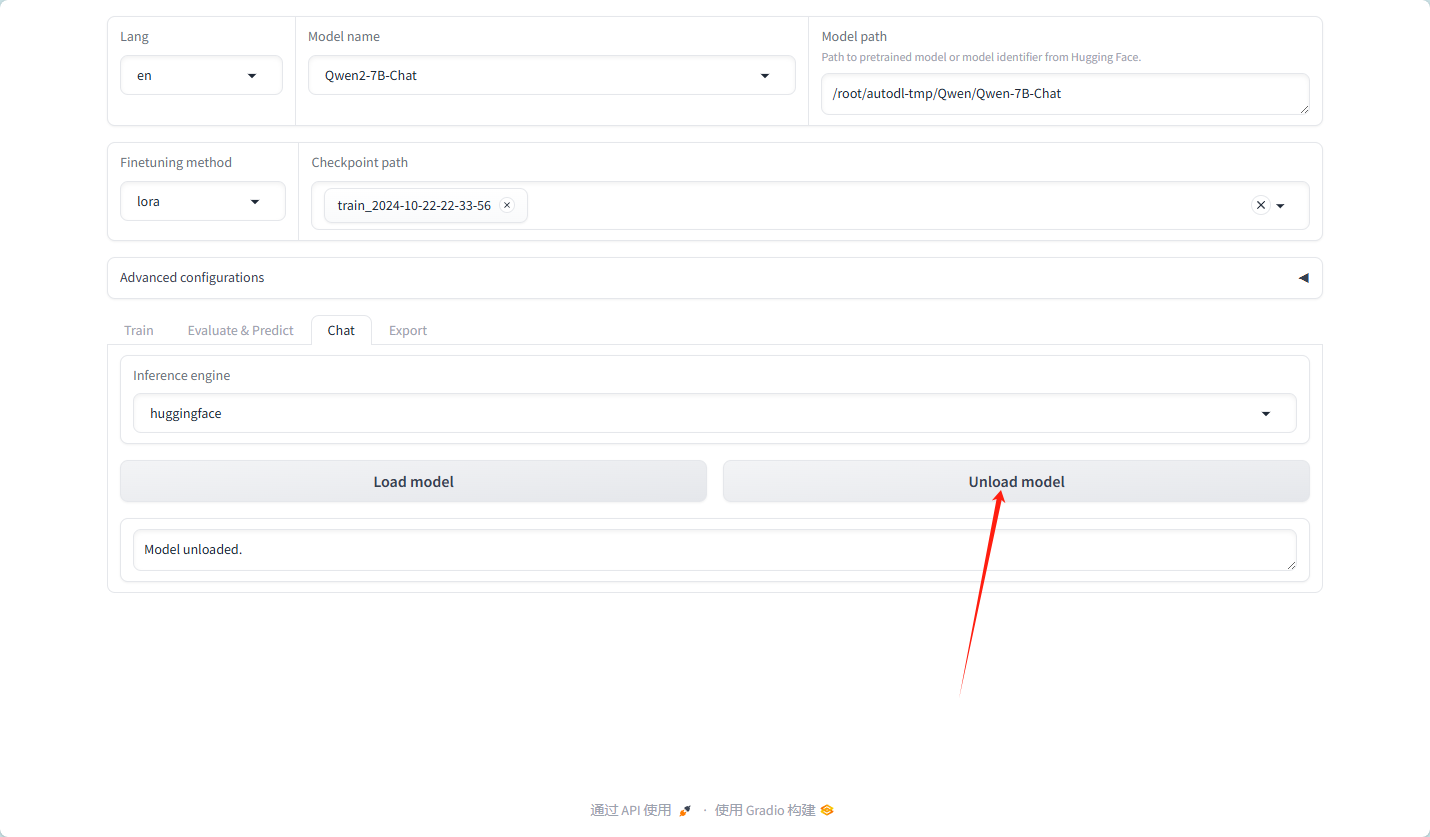
卸载模型,换为我们自己的模型
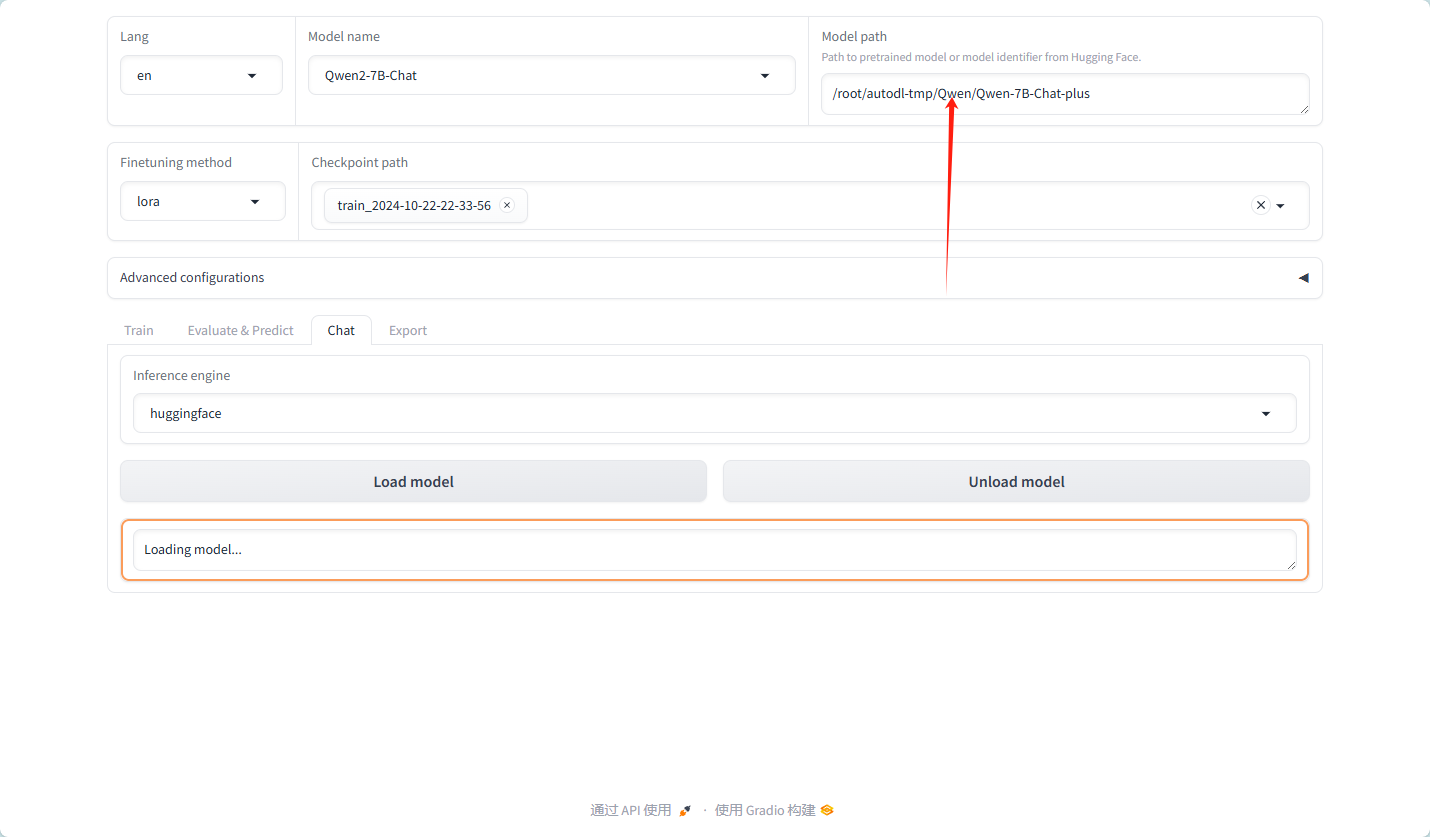
模型测试,以框中的问答为预期
结果:



显然,标准模式是可以的

同义词替换也是可以的,训练集中并没有“你能做啥?”,只有“你能做什么?”


















 889
889

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











