







小伙伴们云计算第一阶段的知识内容属于外门弟子的功法,现在我们进入到了第二阶段,主要学习的是内门弟子的心法。
学习开始往思想方面靠拢,需要理清思路,编写脚本,执行第一阶段学习过的命令。才能使自己的技术与办事效率更上一层楼。不能光说不练,也不能光练不想。二者需要相辅相成,才能得到提高。
不然在一个岗位就会加大自己的可替代性,我们不是机器,并且善于思考,得学会找出走出学习困境的关键点,许多知识就像一门功夫的心法,只可意会不可言它,最终达到更高境界,才能应对更多的困境局面,猥琐发育到最后。

相信我,你也可以变成光。(〃'▽'〃)
SHELL DAY1
一、编写与执行脚本
什么是shell?
Shell是在Linux内核与用户之间的解释器程序,通常指的是bash,负责向内核翻译及传达用户/程序指令,如图-1所示。
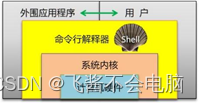
图-1
shell的使用方式:
1.交互执行指令:人工干预,执行效率底。
2.非交互执行指令:安静地在后台执行,执行效率高,方便写脚本。
若需要临时使用另一种Shell环境,可以直接执行对应的Shell解释器程序,比如只要执行sh可以切换到sh命令行环境。
快捷键与Tab键补齐
BASH可实现如下操作:

shell脚本:提前写好可执行的语句,可以完成特定任务的文件按顺序、批量化执行
- [root@svr7 ~]# cat /etc/shells #查看所有解释器
- [root@svr7 ~]# sh #切换成sh解释器
- sh-4.2# ls #利用sh解释器输入命令
- sh-4.2#exit #退出sh解释器
- [root@svr7 ~]#yum -y install ksh #若没有ksh解释器则安装
- [root@svr7 ~]#ksh #进入新解释器
若希望修改用户的登录Shell,管理员可以直接通过usermod(或useradd)命令设置。比如,以下操作可将用户zhangsan的登录Shell改为/bin/ksh:
- [root@svr5 ~]# usermod -s /bin/ksh zhangsan #执行修改操作
- [root@svr5 ~]# grep 'zhangsan' /etc/passwd
- zhangsan:x:516:516::/home/zhangsan:/bin/ksh #修改后
KSH解释器功能稀烂,最终还是选择了BASH解释器,知道有这解释器就行。
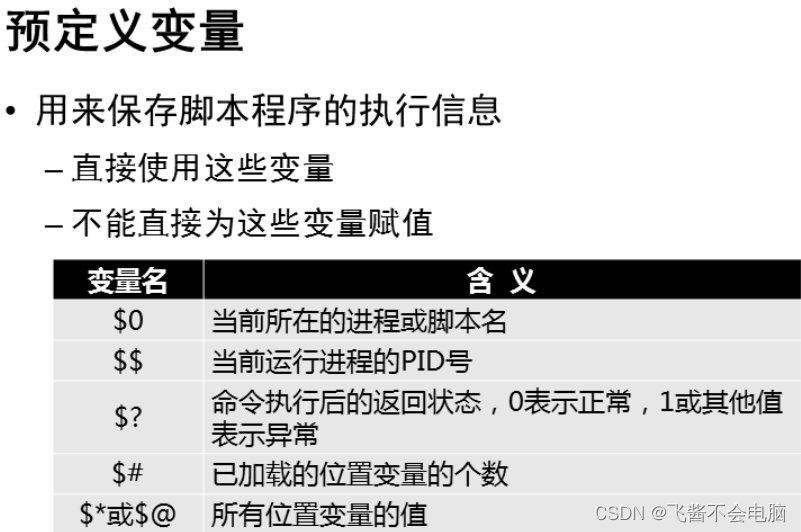
二、Shell变量









三、数值运算

小数运算


四、案例练习
简单Shell脚本的设计
问题
本案例要求编写三个脚本程序,分别实现以下目标:
- 在屏幕上输出一段文字“Hello World”
- 能够为本机快速配好Yum仓库
- 能够为本机快速装配好vsftpd服务
方案
一个规范的Shell脚本构成包括:
- 声明(需要的解释器)
- 注释信息(作者信息、步骤、思路、用途、变量含义等)
- 可执行语句(操作代码)
步骤
实现此案例需要按照如下步骤进行。
步骤一:编写第一个Shell脚本,输出“Hello World”
1)根据手动任务操作编写脚本文件
- [root@svr5 ~]# vim /opt/first.sh
- #!/bin/bash
- echo 'Hello World'
- [root@svr5 ~]# chmod +x /opt/first.sh #添加可执行权限
2)执行脚本,测试效果
- [root@svr5 ~]# /opt/first.sh
- Hello World
3)Shell脚本的执行方式:
方法一,作为“命令字”:指定脚本文件的路径,前提是有 x 权限
- [root@svr5 ~]# ./first.sh #指定相对路径
- [root@svr5 ~]# /opt/first.sh #指定绝对路径
方法二,作为“参数”:使用bash、sh、source、. 来加载脚本文件
- [root@svr5 ~]# bash first.sh #开启子进程
- [root@svr5 ~]# sh first.sh #开启子进程
- [root@svr5 ~]# source first.sh #不开启子进程
- [root@svr5 ~]# . first.sh #不开启子进程
4)再修改脚本进行测试:
- [root@svr5 ~]# vim /opt/first.sh
- #!/bin/bash
- echo 'Hello World'
- exit
- [root@svr5 ~]# vim /opt/first.sh
- #!/bin/bash
- echo 'Hello World'
- mkdir /opt/abc
- cd /opt/abc
步骤二:编写为本机快速配Yum仓库的Shell脚本
1)根据参考文件的内容,编写脚本内容如下:
- cp /etc/yum.repos.d/myyum.repo /opt #可以先备份原有yum配置文件
- [root@svr5 ~]# vim /opt/myyum.sh
- #!/bin/bash
- rm -rf /etc/yum.repos.d/*.repo
- echo "[abc]
- name=abc
- baseurl=file:///misc/cd
- gpgcheck=0" > /etc/yum.repos.d/abc.repo
- [root@svr5 ~]# chmod +x /opt/myyum.sh #添加可执行权限
2)执行脚本,测试效果
执行配置Yum仓库的脚本:
- [root@svr5 ~]# bash /opt/myyum.sh
检查配置结果:
- [root@svr5 ~]# ls /etc/yum.repos.d/* #仓库配置已建立
步骤三:编写快速装配ftp服务的Shell脚本
脚本文件如下:
- [root@svr5 ~]# vim /opt/ftpon.sh
- #!/bin/bash
- yum -y install vsftpd
- systemctl start vsftpd
- systemctl enable vsftpd
升级脚本,方法如下:
> 重定向标准输出
2> 重定向错误输出
&> 重定向所有输出
- [root@svr5 ~]# vim /opt/ftpon.sh
- #!/bin/bash
- yum -y install vsftpd &> /dev/null #将不需要的信息扔黑洞
- systemctl start vsftpd
- systemctl enable vsftpd

执行脚本,测试效果
执行快速装配vsftpd服务的脚本:
- [root@svr5 ~]# /opt/ftpon.sh
确认脚本执行结果:
- [root@svr5 ~]# rpm -q vsftpd
- [root@svr5 ~]# systemctl status vsftpd
案例3:使用Shell变量
问题
本案例要求熟悉Shell变量的使用,主要练习或验证下列内容:
- 定义/赋值/查看变量
- 环境/预定义/位置变量的应用
步骤
实现此案例需要按照如下步骤进行。
步骤一:自定义变量
1)新建/赋值变量
新建变量test,赋值“hello world”,通过set命令可以检查变量设置:
- [root@svr5 ~]# a=10 #等号两边不能有空格,变量名称可以用数字、字母、下划线,不能以数字开头,不能用特殊符号
2)查看变量(调用变量)
通过echo $变量名 可输出变量值:
- [root@svr5 ~]# echo $a
- 10
查看变量时,若变量名称与后面要输出的字符串连在一起,则应该以{}将变量名括起来以便区分:
- [root@svr5 ~]# echo $aRMB #无法识别变量名test
- [root@svr5 ~]# echo ${a}RMB #使用{}可以防止与后续字符混淆
- 10RMB
3)撤销自定义变量
若要撤销已有的变量,可将变量赋值为空或使用unset命令:
- [root@svr5 ~]# unset a #撤销变量test
- [root@svr5 ~]# echo $a #查看时已无结果
步骤二:使用环境变量
1)使用环境变量
当前用户的环境变量USER记录了用户名、HOME记录了家目录、SHELL记录了登录解释器、HOSTNAME记录主机名、UID是用户的id号:
- [root@svr5 ~]# echo $USER $HOME $SHELL $UID
- root /root /bin/bash 0
- [root@svr5 ~]# echo $HOSTNAME
- svr5
环境变量PS1表示Shell环境的一级提示符,即命令行提示符(\u 用户名、\h 主机名、\W 工作目录、\$ 权限标识):
- [root@svr5 src]# echo $PS1 #查看默认的一级提示
- [\u@\h \W]\$
- [root@svr5 src]#PS1='hehe#' #修改一级提示
- hehe# #更改结果
- hehe# PS1='[\u@\h \W]\$ ' #恢复原有设置
- [root@svr5 src]#
环境变量PS2表示二级提示符,出现在强制换行场合:
- [root@svr5 ~]# echo $PS2 #查看默认的二级提示
- >
- [root@svr5 src]# cd \ #强制换行,观察提示符效果
- > /root/
- [root@svr5 ~]# PS2='=> ' #手动修改二级提示
- [root@svr5 ~]# cd \ #再次验证提示符效果
- => ~
- [root@svr5 ~]# PS2='> ' #恢复原有设置
可以把变量放入/etc/profile,对所有用户有效;放入~/.bash_profile,仅对指定的用户有效
使用env可查看所有环境变量,使用set可查看所有变量
步骤三:使用位置变量与预定义变量
1)创建一个测试脚本,用来展示。
- [root@svr5 ~]# vim location.sh
- #!/bin/bash
- echo $0 #脚本的名称
- echo $1 #第一个参数
- echo $2 #第二个参数
- echo $* #所有参数
- echo $# #所有参数的个数
- echo $$ #当前进程的进程号
- echo $? #上一个程序的返回状态码
- [root@svr5 ~]# chmod +x location.sh #添加可执行权限
2)执行脚本location.sh
- [root@svr5 ~]# ./location.sh a b c
步骤四:创建账户与修改密码的脚本
首先编写一个创建账户tom,密码123456的脚本,然后通过下列方式改进
1)编写脚本。
- [root@svr5 ~]# vim /opt/user.sh
- #!/bin/bash
- useradd $1
- echo "$2" |passwd --stdin $1
执行脚本测试:
- [root@svr5 ~]# ./user.sh jerry 123456
- 更改用户 jerry 的密码 。
- passwd: 所有的身份验证令牌已经成功更新。
4 案例4:变量的扩展应用
4.1 问题
本案例要求进一步熟悉Shell变量的赋值控制,主要练习或验证下列内容:
- 三种引号对赋值的影响
- 使用read命令从键盘读取变量值
- 使用export发布全局变量
4.2 步骤
实现此案例需要按照如下步骤进行。
步骤一:三种引号对变量赋值的影响
使用双引号可以界定一个完整字符串。
- [root@svr5 ~]# xx=a b c
- -bash: b: command not found #未界定时赋值失败
- [root@svr5 ~]# xx="a b c" #界定后成功
- [root@svr5 ~]# touch aa bb #创建了两个文件
- [root@svr5 ~]# touch "aa bb" #创建了一个文件
- [root@svr5 ~]# ls #查看结果
2)单引号的应用
界定一个完整的字符串,并且可以实现屏蔽特殊符号的功能。
- [root@svr5 ~]# test=11
- [root@svr5 ~]# echo "$test"
- [root@svr5 ~]# echo '$test'
3)反撇号或$()的应用
使用反撇号或$()时,可以将命令执行的标准输出作为字符串存储,因此称为命令替换。
- a=date #仅仅将四个字母赋值给a
- a=`date` #将date执行结果赋值给a
- a=$(date) #效果同上
- [root@svr5 ~]# tar -czf log-`date +%Y%m%d`.tar.gz /var/log
步骤二:使用read命令从键盘读取变量值
1)read基本用法
执行后从会等待并接受用户输入(无任何提示的情况),并赋值给变量str:
- [root@svr5 ~]# read str
- What's happen ? #随便输入一些文字,按Enter键提交
- [root@svr5 ~]# echo $str #查看赋值结果
- What's happen ?
为了不至于使用户不知所措、莫名其妙,推荐的做法是结合-p选项给出友好提示:
- [root@svr5 ~]# read -p "请输入一个整数:" i
- 请输入一个整数:240
- [root@svr5 ~]# echo $i
- 240
结合之前的脚本
- #!/bin/bash
- read -p "请输入用户名" u #-p是可以定义提示信息,u相当于自
- 定义变量名称,可以存储用户看到提示信息后输入的字符
- useradd $u
- read -p "请输入密码" n
- echo "$n" | passwd --stdin $u
2)stty终端显示控制 【屏蔽屏幕键盘输入信息】
将回显功能关闭(stty -echo),
将回显功能恢复(stty echo)。
之前脚本再次改良:
- #!/bin/bash
- read -p "请输入用户名" u
- useradd $u
- stty -echo
- read -p "请输入密码" n
- stty echo
- echo "$n" | passwd --stdin $u
步骤三:使用export发布全局变量
默认情况下,自定义的变量为局部变量,只在当前Shell环境中有效,而在子Shell环境中无法直接使用。
- [root@svr5 ~]# yy="abc"
- [root@svr5 ~]# echo $yy #查看yy变量的值,有值
- [root@svr5 ~]# bash #开启bash子进程
- [root@svr5 ~]# echo $yy #查看yy变量的值,无值
- [root@svr5 ~]# exit #返回原有Shell环境
- [root@svr5 ~]# echo $yy #再次查看,有值
若希望定义的变量能被子进程使用:
- [root@svr5 ~]# export yy #发布已定义的变量
验证刚刚发布的全局变量:
- [root@svr5 ~]# bash #进入bash子Shell环境
- [root@svr5 ~]# echo $yy #查看全局变量的值 .. ..
案例5:Shell中的数值运算
问题
本案例要求熟悉Linux Shell环境的特点,主要练习以下操作:
- 使用$(( ))、$[ ]、let等整数运算工具:进行四则运算及求模结果
- 使用bc实现小数运算操作
步骤
实现此案例需要按照如下步骤进行。
步骤一:整数运算工具
1)使用$(())或$[]表达式
引用变量可省略 $ 符号;计算结果替换表达式本身,可结合echo命令输出。
对于变量X=1234,分别计算与78的加减乘除和求模运算结果:
- [root@svr5 ~]# X=1234
- [root@svr5 ~]# echo $((X+78)) 或 echo $[X+78]
- 1312
- [root@svr5 ~]# echo $((X-78))
- 1156
- [root@svr5 ~]# echo $((X*78))
- 96252
- [root@svr5 ~]# echo $((X/78))
- 15
- [root@svr5 ~]# echo $((X%78))
- 64
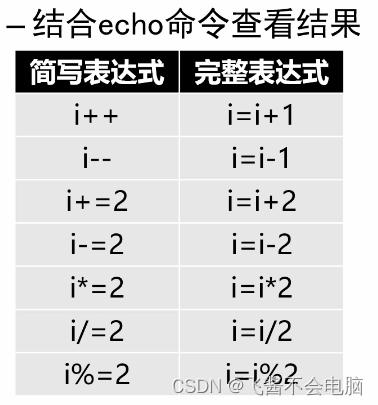
2)使用let命令
let命令可以直接对变量值做运算再保存新的值。
- 常规写法 主流写法
- let a=a+1 let a++ #变量a加1
- let a=a-1 let a-- #变量a减1
- let a=a+10 let a+=10 #变量a加10
- let a=a-10 let a-=10 #变量a减10
- let a=a*2 let a*=2 #变量a乘以2
- let a=a/2 let a/=2 #变量a除以2
- let a=a%3 let a%=3 #变量a除以3取余数
- 提示,let的主流写法可以用(( ))替代
步骤二:小数运算工具
1)bc交互式运算
先执行bc命令进入交互环境,然后再输入需要计算的表达式。
- [root@svr5 ~]# bc
2)bc非交互式运算
将需要运算的表达式通过管道操作交给bc运算。注意,小数位的长度可采用scale=N限制。
- [root@svr5 ~]#echo "1.1+1" | bc
- [root@svr5 ~]#echo "10/3" | bc
- [root@svr5 ~]#echo "scale=2;10/3" | bc #scale可以定义结果是小数点后多少位
以上就是第二阶段Shell 脚本的初次使用介绍,需要结合知识点熟练,才能达到融会贯通的境界。

我认为学习需要我们学会自我催眠,出门在外身份是自己给的,什么东邪西毒南帝北丐,哪些都是一步步积累起来的江湖地位,而你我的朋友,你需要让自己知道,你是真的能学会,学会了机会不就来了吗,身价工资不就起来了嘛。ヾ(◍°∇°◍)ノ゙
SHELL DAY2
脚本的编写和执行要有合理的逻辑顺序,必须遵守机器的使用方法,相关命令在编写脚本时,一个参数和变量值的变化,轻则导致服务器运算效率,重则导致影响机器运行稳定性,造成不可估量的损失,所以编写脚本前,一定要避免不必要的逻辑死循环错误,导致影响机器运行。

一、条件测试
目的:实现脚本运行时的智能化决策。
为命令的执行提供直接的识别依据。例如:
1.文件或目录的读写执行等状态。
2.数值的大小。
3.字符串是否匹配
4.多条件组合。
条件测试的基本用法
1)语法格式
使用“test 表达式”或者[ 表达式 ]都可以,注意空格不要缺少。
条件测试操作本身不显示出任何信息。所以可以在测试后查看变量$?的值来做出判断。
字符串测试
1)== 比较两个字符串是否相同
检查当前用户是否为root。
当root用户执行时:
- [root@svr5 ~]# [ $USER == "root" ] #测试
- [root@svr5 ~]# echo $? #查看结果0为对,非0为错
当普通用户执行时:
- [zengye@svr5 ~]$ [ $USER == "root" ]
- [zengye@svr5 ~]$ echo $? #查看结果0为对,非0为错
2)!= 比较两个字符串是否不相同
当普通用户执行时:
- [zengye@svr5 ~]$ [ $USER != "root" ]
当root用户执行时:
- [root@svr5 ~]# [ $USER != "root" ]
3)变量为空时:
- [ "$c" == abc ] #如果变量为空,有可能报错,加双引号可以避免
- [ -z $c ] #判断变量是否为空
- [ ! -z $c ] #判断变量是否非空
还有一个-n可以测试变量是否不为空(相当于! -z)。
或者结合&&、||等逻辑操作显示出结果 。
4)一行执行多条命令的情况
- # A && B #仅当A命令执行成功,才执行B命令
- # A || B #仅当A命令执行失败,才执行B命令
- # A ; B #执行A命令后执行B命令,两者没有逻辑关系
步骤三:多个条件/操作的逻辑组合

1)&&,逻辑与
给定条件必须都成立,整个测试结果才为真。
检查变量X的值是否大于10,且小于30:
- [root@svr5 ~]# X=20 #设置X变量的值为20
- [root@svr5 ~]# [ $X -gt 10 ] && [ $X -lt 30 ] && echo "YES"
2)||,逻辑或
只要其中一个条件成立,则整个测试结果为真。
只要/tmp/、/var/spool/目录中有一个可写,则条件成立:
- [root@svr5 ~]# [ -w "/tmp/" ] || [ -w "/var/spool/" ] && echo "OK"
还可以按以下方式理解与测试
A && B A、B任务都成功算真
A || B A、B 任务有一个成功算真
- touch a b c
- ls a && ls b && ls c #结果是都显示
- ls a || ls b || ls c #结果是显示a
- ls a && ls b || ls c #结果是显示a和b
- ls a || ls b && ls c #结果是显示a和c
- [ root != $USER ] && echo "非管理员不能执行该脚本" && exit
人工智能提示词:
解释一下,当目前拥有文件a、b、c,执行ls a && ls b || ls c命令之后,为什么可以看到a和b
步骤四:整数值比较
参与比较的必须是整数(可以调用变量) 参数如图:

1)-eq 比较两个数是否相等。
- [root@svr5 ~]# X=20 #定义一个测试变量
- [root@svr5 ~]# [ $X -eq 20 ] && echo "yes" || echo "no"
2)-ne 比较两个数是否不相等。
- [root@svr5 ~]# [ $X -ne 20 ] && echo "yes" || echo "no"
3)-gt 比较前面的整数是否大于后面的整数。
- [root@svr5 ~]# [ $X -gt 10 ] && echo "yes" || echo "no"
4)-ge 比较前面的整数是否大于或等于后面的整数。
- [root@svr5 ~]# [ $X -ge 10 ] && echo "yes" || echo "no"
5)-lt 比较前面的整数是否小于后面的整数。
- [root@svr5 ~]# [ $X -lt 10 ] && echo "yes" || echo "no"
6)-le 比较前面的整数是否小于或等于后面的整数。
- [root@svr5 ~]# [ $X -le 10 ] && echo "yes" || echo "no"
准备环境:
- yum -y install mailx postfix #安装邮件客户端软件和服务端程序
- systemctl restart postfix #启动邮件服务
- echo "测试" | mail -s test root #编写脚本前,测试下邮件功能是否正常 ,mail -s是发送邮件,test是标题,root是给谁发,echo后面写要发送的邮件内容,如果邮件太多可以删除/var/spool/mail/root文件清空邮箱
小练习:
编写shell脚本,检查服务器拥有的用户总数量(cat passwd),如果当前数量是29,如果大于该值,则发邮件通知管理员
然后测试,以下命令不是脚本内容,要在命令行中敲,不写在脚本中
编写脚本:
格式: vim 脚本名.sh
- #!/bin/bash
- x=$(cat /etc/passwd | wc -l) #将目前用户数量赋值给变量x
- [ $x -gt 29 ] && echo "用户数量发生变化,服务器可能被入 侵" | mail -s test root #如果目前用户数量大于29,就发邮件给管理员,29是之前查看的用户数量
- chmod u+x test01.sh #然后给脚本加x权限
- crontab -e #编写计划任务
- */2 * * * * /opt/test01.sh #定义每2分钟执行脚本
下面这个软件想用的可以下载,不想用的跳到下一小节内容。
辅助软件
人工智能提示词:该阶段学习过程中会用到一个代码领域专业性强的AI ,想改进代码或者没有思路,可以搜索了解一下。 它的名字叫 VScode ,是文本工具的一种。其中加模块后有更多惊喜功能,辅助我们更快更好打敲代码。该软件也不占用内存空间,才几百M大小。它里面有一个AI模块,就叫TongYiLingmas是基于阿里云账户的一个AI大模型。最主要的一点是它开源免费,手机或支付宝扫码就能注册账号。

一顿下一步,想放在其他盘,选位置的时候自己改。






识别文件/目录的状态

1)-e 判断对象是否存在(不管是目录还是文件)
- [root@svr5 ~]# [ -e "/opt/a" ] && echo "yes" || echo "no"
2)-d 判断对象是否为目录(存在且是目录)
- [root@svr5 ~]# [ -d "/opt/b" ] && echo "yes" || echo "no"
3)-f 判断对象是否为文件(存在且是文件)
- [root@svr5 ~]# [ -f "/opt/c" ] && echo "yes" || echo "no"
4)-r 判断对象是否可读
- [root@svr5 ~]# [ -r "/opt/a" ] && echo "yes" || echo "no"
5)-w 判断对象是否可写
- [root@svr5 ~]# [ -w "/opt/a" ] && echo "yes" || echo "no"
6)-x 判断对象是否具有x权限
- [root@svr5 ~]# [ -x "/opt/a" ] && echo "yes" || echo "no"
注意:-r与-w对root无效
二、IF选择结构
小伙伴们,选择结构的知识每一个编程语言都会涉及到,也是云计算与大数据相关行业的必需要掌握的知识之一。O(∩_∩)O
本案例要求编写3个Shell脚本,分别实现以下目标:
- 检测/if_test/cdrom目录,若不存在则创建
- 检测并判断指定的主机是否可ping通
- 从键盘读取一个数值,按情况给出不同结果
方案
if单分支的语法组成:
- if 条件测试;then
- 命令序列
- fi
if双分支的语法组成:
- if 条件测试;then
- 命令序列1
- else
- 命令序列2
- fi
if多分支的语法组成:
- if 条件测试1 ;then
- 命令序列1
- elif 条件测试2 ;then
- 命令序列2
- else
- 命令序列n
- fi
步骤
实现此案例需要按照如下步骤进行。
步骤一:使用if单分支
1)编写脚本如下:
- #!/bin/bash
- if [ $UID -eq 0 ];then
- echo "我是管理员"
- echo ok
- fi
步骤二:检测/if_test/cdrom目录,若存在则输出ok,若不存在则创建
- [root@svr5 ~]# vim dir.sh
- #!/bin/bash
- dir="/if_test/cdrom/"
- if [ -d $dir ];then
- echo ok
- else
- mkdir -p $dir
- fi
人工智能提示词:
编写shell脚本,检测/if_test/cdrom目录,若存在则输出ok,若不存在则创建
编写脚本,检测并判断指定的主机是否可ping通
1)分析任务需求
使用ping命令检测目标主机时,可通过$?来判断ping目标主机的成败。
为了节省ping测试时间,可以只发送3个测试包(-c 3)、缩短发送测试包的间隔秒数(-i 0.2)、等待反馈的超时秒数(-W 1)。比如,检查可ping通的主机:
- [root@svr5 ~]# ping -c 3 -i 0.2 -W 1 192.168.88.5
- [root@svr5 ~]# echo $? #执行状态表示成功
- 0
2)脚本编写参考如下:
- [root@svr5 ~]# vim pinghost.sh
- #!/bin/bash
- ping -c 3 -i 0.2 -W 1 $1 &> /dev/null
- if [ $? -eq 0 ] ; then
- echo "Host $1 is up."
- else
- echo "Host $1 is down."
- fi
- [root@svr5 ~]# chmod +x pinghost.sh
3)测试、验证脚本功能
- [root@svr5 ~]# ./pinghost.sh 192.168.88.5
- Host 192.168.88.5 is up.
- [root@svr5 ~]# ./pinghost.sh 192.168.88.50
- Host 192.168.88.50 is down.
步骤三:从键盘读取一个数值,按情况给出不同结果
1)脚本编写参考如下:
- #!/bin/bash
- read -p "询问内容" x
- if 条件;then
- echo "情况一"
- elif 条件;then
- echo "情况二"
- elif 条件;then
- echo "情况三"
- else
- echo "情况四"
- fi
人工智能提示词:
编写shell脚本,使用if双分支测试ip地址192.168.88.2是否可以ping通
三、循环结构
使用for循环结构

问题
本案例要求编写一个Shell脚本chkhosts.sh,利用for循环来检测多个主机的存活状态
方案
使用for循环,语法结构如下所示:
- for 变量名 in 值1 值2 值3 #值的数量决定循环任务的次数
- do
- 命令序列
- done
步骤
实现此案例需要按照如下步骤进行。
步骤一:练习for循环基本用法
通过循环批量显示5个hello world:
- [root@svr5 ~]# vim for01.sh
- #!/bin/bash
- for i in 1 2 3 4 5
- do
- echo "hello world"
- done
通过循环批量显示10个abc:
- [root@svr5 ~]# vim for02.sh
- #!/bin/bash
- for i in {1..10}
- do
- echo "abc"
- done
通过循环批量显示10个数字:
- [root@svr5 ~]# vim for03.sh
- #!/bin/bash
- for i in {1..10}
- do
- echo "$i"
- done
- a=10
- for i in `seq $a` #如果循环次数是通过变量决定可以用seq指令
- do
- echo "$i"
- done
编写脚本,批量创建账户
- #!/bin/bash
- for i in $(cat /opt/name.txt) #循环批量创建name.txt里面所有账户,文档中每行是一个名字,该文档要提前创建,与脚本在同一目录下即可
- do
- useradd $i
- done
步骤二:批量检测多个主机的存活状态
1)编写脚本如下:
- [root@svr5 ~]# vim chkhosts.sh
- #!/bin/bash
- for i in {1..10}
- do
- ping -c 3 -i 0.2 -W 1 192.168.88.$i &> /dev/null
- if [ $? -eq 0 ] ; then
- echo "88.$i is up."
- else
- echo "88.$i is down."
- fi
- done
思考,如何最后输出up与down 的总数?
人工智能提示词:
编写shell脚本,使用if双分支与for循环测试ip地址192.168.88.1 ~ 192.168.88.10是否可以ping通,最后还要给出ping通与不通的主机数量
附加扩展知识(C语言风格的for循环语法格式)

- [root@svr5 ~]# vim cfor.sh
- #!/bin/bash
- for ((i=1;i<=5;i++))
- do
- echo $i
- done
使用while循环结构
while循环属于条件式的执行流程,会反复判断指定的测试条件,只要条件成立即执行固定的一组操作,直到条件变化为不成立为止。所以while循环的条件一般通过变量来进行控制,在循环体内对变量值做相应改变,以便在适当的时候退出,避免陷入死循环。
使用while循环,语法结构如下所示:

- while 条件测试 #根据条件的结果决定是否要执行任务,条件测试成功的话就执行,如果失败立刻结束循环
- do
- 命令序列
- done
练习while循环基本用法
脚本1,无限的死循环脚本:
- [root@svr5 ~]# vim while01.sh
- #!/bin/bash
- i=1
- while [ $i -le 5 ]
- do
- echo "abc"
- done
- [root@svr5 ~]# chmod +x while01.sh
- [root@svr5 ~]# ./while01.sh #死循环,需要使用Ctrl+C终止脚本
机器也是需要编写休息指令的,死循环必须要设置相应的停顿机制。

有了脚本1的教训,加上休息机制,结果就会大有不容。机器得到了休息,你完成了任务。二者达成了共赢局面。机器和人类的区别,可以说是天与地的区别,它休息一秒钟,相当于我们睡了一觉。
脚本2,死循环的一般格式:
- [root@svr5 ~]# vim while02.sh
- #!/bin/bash
- while : #冒号可以表示条件为真
- do
- echo "abc"
- sleep 0.1 #休息0.1秒
- done
- [root@svr5 ~]# chmod +x while02.sh
- [root@svr5 ~]# ./while02.sh #死循环,需要使用Ctrl+C终止脚本
有了 SLEEP 指令的帮助,机器得到了响应休息时间,机器减少了不必要的损坏麻烦。

脚本3,有效循环脚本:
- [root@svr5 ~]# vim while03.sh
- #!/bin/bash
- i=1
- while [ $i -le 5 ]
- do
- echo "$i"
- let i++
- done
SHELL DAY03
一、WHILE循环中断机制

1 案例1:中断及退出
1.1 问题
本案例要求编写两个Shell脚本,相关要求如下:
- 从键盘循环取整数(0结束)并求和,输出最终结果
1.2 方案
通过break、continue、exit在Shell脚本中实现中断与退出的功能。
exit结束循环以及整个脚本
break可以结束整个循环

continue结束本次循环,进入下一次循环

案例如下:
- [root@svr5 ~]# vim test.sh
- #!/bin/bash
- for i in {1..5}
- do
- [ $i -eq 3 ]&& break #这里将break替换为continue,exit分别测试脚本执行效果
- echo $i
- done
- echo "Game Over"
1.3 步骤
实现此案例需要按照如下步骤进行。
步骤一:编写持续创建用户脚本sum.sh
1)编写脚本文件
- #!/bin/bash
- x=0
- while :
- do
- read -p "请输入要创建的用户名(0是结束并显示本次创建用户总数):" n
- [ -z "$n" ] && continue #如果n是空值则重新进行循环任务
- [ "$n" == 0 ] && break #如果n是0则退出循环执行循环后任务
- useradd "$n" &> /dev/null
- if [ $? -eq 0 ];then
- let x++ #每次成功创建用户,将x加1
- else
- echo 无效用户名
- fi
- done
- echo "本次共创建$x个用户"
人工智能提示词:
编写shell脚本,可以利用循环无限创建用户,但如果输入0则退出并输出本次创建的用户总数
二、case语句
2 案例2:基于case分支编写脚本

2.1 问题
编写脚本,相关要求如下:
- 要求通过位置变量执行不同任务
2.2 方案
case分支属于匹配执行的方式,它针对指定的变量预先设置一个可能的取值,判断该变量的实际取值是否与预设的某一个值相匹配,如果匹配上了,就执行相应的一组操作,如果没有任何值能够匹配,就执行预先设置的默认操作。
case分支的语法结构如下所示:
- case 变量 in
- 模式1)
- 命令序列1 ;;
- 模式2)
- 命令序列2 ;;
- .. ..
- *)
- 默认命令序列
- esac
脚本编写参考如下:
- #!/bin/bash
- case $1 in
- t) #如果$1是t就执行touch任务
- touch $2;;
- m) #如果$1是m就执行mkdir任务
- mkdir $2;;
- r) #如果$1是r就执行rm任务
- rm -rf $2;;
- *)
- echo "请输入t或者m或者r"
- esac
人工智能提示词:
编写shell脚本,利用case分支判断用户在执行脚本时传递的位置参数,最终实现文件的创建与删除
3 案例3:编写一键部署软件脚本
3.1 问题
本案例要求编写脚本实现一键部署Nginx软件(Web服务器):
- 一键源码安装Nginx软件
- 脚本自动安装相关软件的依赖包
3.2 步骤
实现此案例需要按照如下步骤进行。
1)依赖包
源码安装Nginx需要提前安装依赖包软件gcc,openssl-devel,pcre-devel
步骤一:编写脚本
1)参考脚本内容如下:
- [root@svr5 ~]# vim test.sh
- #!/bin/bash
- yum -y install gcc openssl-devel pcre-devel
- tar -xf nginx-1.22.1.tar.gz
- cd nginx-1.22.1
- ./configure
- make
- make install
2)确认安装效果
Nginx默认安装路径为/usr/local/nginx,其中sbin目录下放着主程序nginx
主程序命令参数:
- [root@svr5 ~]# /usr/local/nginx/sbin/nginx #启动服务
- [root@svr5 ~]# /usr/local/nginx/sbin/nginx -s stop #关闭服务
4 案例4:启动脚本
4.1 问题
本案例要求编写Ngin启动脚本,要求如下:
- 脚本支持start、stop、restart、status
- 脚本支持报错提示
- 脚本具有判断是否已经开启或关闭的功能
4.2 步骤
实现此案例需要按照如下步骤进行。
步骤一:编写脚本
脚本通过位置变量$1读取用户的操作指令,判断是start、stop、restart还是status。
ss命令可以查看系统中启动的端口信息,该命令常用选项如下:
-n以数字格式显示端口号
-t显示TCP连接的端口
-u显示UDP连接的端口
-l显示服务正在监听的端口信息,如httpd启动后,会一直监听80端口
-p显示监听端口的服务名称是什么(也就是程序名称)
1)参考脚本内容如下:
- [root@svr5 ~]# vim test.sh
- #!/bin/bash
- case $1 in
- start|kai)
- /usr/local/nginx/sbin/nginx;;
- stop|guan)
- /usr/local/nginx/sbin/nginx -s stop;;
- restart|cq)
- /usr/local/nginx/sbin/nginx -s stop
- /usr/local/nignx/sbin/nginx;;
- status|zt)
- ss -ntulp |grep -q nginx
- if [ $? -eq 0 ];then
- echo 服务已启动
- else
- echo 服务未启动
- fi;;
- *)
- echo Error;;
- esac
2)执行测试脚本:
- [root@svr5 ~]# ./test.sh start
- [root@svr5 ~]# ./test.sh stop
- [root@svr5 ~]# ./test.sh status
- [root@svr5 ~]# ./test.sh xyz
人工智能提示词:
编写shell脚本,利用case分支判断用户在执行脚本时传递的位置参数,最终实现某服务的开关、重启、查询状态
三、函数使用
5 案例5:使用Shell函数
5.1 问题
本案例要求编写脚本,相关要求如下:
- 将颜色输出的功能定义为函数
- 调用函数,可以自定义输出内容和颜色
5.2 方案
在Shell脚本中,将一些需重复使用的操作,定义为公共的语句块,即可称为函数。通过使用函数,可以使脚本代码更加简洁,增强易读性,提高Shell脚本的执行效率
1)函数的定义方法
格式1:
- function 函数名 {
- 命令序列
- .. ..
- }
格式2:
- 函数名() {
- 命令序列
- .. ..
- }
2)函数的调用
直接使用“函数名”的形式调用,如果该函数能够处理位置参数,则可以使用“函数名 参数1 参数2 .. ..”的形式调用。
注意:函数的定义语句必须出现在调用之前,否则无法执行。
3) 测试语法格式
- [root@svr5 ~]# a(){ #定义函数
- echo abc
- echo xyz
- }
- [root@svr5 ~]# a #调用函数
5.3 步骤
实现此案例需要按照如下步骤进行。
步骤一:编写mycolor.sh脚本
1)任务需求及思路分析
用户在执行时提供2个整数参数,这个可以通过位置变量$1、$2读入。
调用函数时,将用户提供的两个参数传递给函数处理。
颜色输出的命令:echo -e "\033[32mOK\033[0m"。
3X为字体颜色,4X为背景颜色,9x为字体高亮色,"\033[43;31mOK\033[0m"可以同时修改背景与字体颜色
2)根据实现思路编写脚本文件
- [root@svr5 ~]# vim mycolor.sh
- #!/bin/bash
- cecho() {
- echo -e "\033[$1m$2\033[0m"
- }
- cecho 32 OK
- cecho 33 OK
- cecho 34 OK
- cecho 35 OK
- [root@svr5 ~]# chmod +x mycolor.sh
3)测试脚本执行效果
- [root@svr5 ~]# ./mycolor.sh
还可以利用函数优化之前的nginx脚本
人工智能提示词:
编写shell脚本,利用函数与echo指令,输出彩色字体
四、字符串处理
6 案例6:字符串处理
6.1 问题
本案例要求熟悉字符串的常见处理操作,完成以下任务练习:
- 参考课上示范操作,完成字符串截取、替换等操作
- 编写批量修改扩展名脚本
6.2 方案
字符串截取的用法:
- ${变量名:起始位置:长度}
- 起始位置从0开始计数
字符串替换的两种用法:
- 只替换第一个匹配结果:${变量名/old/new}
- 替换全部匹配结果:${变量名//old/new}
字符串掐头去尾:
- 从左向右,最短匹配删除:${变量名#*关键词}
- 从左向右,最长匹配删除:${变量名##*关键词}
- 从右向左,最短匹配删除:${变量名%关键词*}
- 从右向左,最长匹配删除:${变量名%%关键词*}
6.3 步骤
实现此案例需要按照如下步骤进行。
步骤一:字符串的截取
1)使用 ${}表达式
格式:${变量名:起始位置:长度}
- [root@proxy opt]# a=abcd
- [root@proxy opt]# echo ${a:1:2} #从第二位截取两位
- bc
- [root@proxy opt]# echo ${a:0:2} #从头截取两位
- ab
一个8位随机密码的案例
首先实现1个字符的随机产生
- #!/bin/bash
- x=abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789
- n=$((RANDOM%62)) #得到0~61随机数存在变量n中
- p=${x:n:1} #通过截取,将1个随机字符赋值给变量p
然后完善:
- #!/bin/bash
- x=abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789
- pass= #使用变量pass
- for i in {1..8}
- do
- n=$((RANDOM%62))
- p=${x:n:1}
- pass+=$p #将随机得到的字符赋值给变量pass
- done
- echo $pass #最后喊出,得到8位长度随机字符串
人工智能提示词:
编写shell脚本,使用${变量:截取位置:1}格式,从大小写字母和数字中创建8位长度的随机字符串
步骤二:字符串的替换
1)只替换第1个子串
格式:${变量名/old/new}
还以前面的phone变量为例,确认原始值:
- [root@svr5 ~]# echo $phone
- 13788768897
将字符串中的第1个8替换为X:
- [root@svr5 ~]# echo ${phone/8/X}
- 137X8768897
2)替换全部子串
格式:${变量名//old/new}
将phone字符串中的所有8都替换为X:
- [root@svr5 ~]# echo ${phone//8/X}
- 137XX76XX97
步骤三:字符串的匹配删除
以处理系统默认的用户信息为例,定义变量A:
- [root@svr5 ~]# a=`head -1 /etc/passwd`
- [root@svr5 ~]# echo $a
- root:x:0:0:root:/root:/bin/bash
1)从左向右,最短匹配删除
格式:${变量名#*关键词}
删除从左侧第1个字符到最近的关键词“:”的部分,* 作通配符理解:
- [root@svr5 ~]# echo ${a#*:}
- x:0:0:root:/root:/bin/bash
2)从左向右,最长匹配删除
格式:${变量名##*关键词}
删除从左侧第1个字符到最远的关键词“:”的部分:
- [root@svr5 ~]# echo $a #确认变量a的值
- root:x:0:0:root:/root:/bin/bash
- [root@svr5 ~]# echo ${a##*:}
- /bin/bash
3)从右向左,最短匹配删除
格式:${变量名%关键词*}
删除从右侧最后1个字符到往左最近的关键词“:”的部分,* 做通配符理解:
- [root@svr5 ~]# echo ${a%:*}
- root:x:0:0:root:/root
4)从右向左,最长匹配删除
格式:${变量名%%关键词*}
删除从右侧最后1个字符到往左最远的关键词“:”的部分:
- [root@svr5 ~]# echo ${a%%:*}
- root
步骤四:编写批量修改扩展名脚本
可以先用touch abc{01..10}.txt 创建10个文件作为素材
- #!/bin/bash
- for i in $(ls *.txt) #找到所有的txt文件交给for循环
- do
- n=${i%.*} #用去尾的方法删除扩展名
- mv $i $n.doc #再将源文件扩展名修改为doc
- done
人工智能提示词:
编写shell脚本,使用${变量%}格式,实现批量修改扩展名从txt变成doc
7 案例7:字符串初值的处理
7.1 问题
本案例要求编写一个脚本可以创建用户,密码可以自定义也可以使用默认值123456
7.2 方案
通过${var:-初值}判断变量是否存在,决定变量的初始值。
7.3 步骤
实现此案例需要按照如下步骤进行。
步骤一:认识字符串初值的最常见处理方法
1)只取值,${var:-word}
若变量var已存在且非空,则返回 $var 的值;否则返回字串“word”,原变量var的值不受影响。
变量值已存在的情况:
- [root@svr5 ~]# XX=11
- [root@svr5 ~]# echo $XX #查看原变量值
- 11
- [root@svr5 ~]# echo ${XX:-123} #因XX已存在,输出变量XX的值
- 11
步骤二:
- [root@svr5 ~]# cat /root/test.sh
- #!/bin/bash
- read -p "请输入用户名:" user
- [ -z $user ] && exit #如果无用户名,则脚本退出
- read -p "请输入密码:" pass
- pass=${pass:-123456} #如果用户没有输入密码,则默认密码为123456
- useradd $user
- echo "$pass" | passwd --stdin $user
人工智能提示词:
使用${var:-初值}格式编写shell脚本,提示输入用户密码时,如果直接回车则密码是123456
SHELL DAY04
一、正则表达式
正则表达式的知识,在数据库与文本处理中方面较为广泛,他可以根据使用目的,用各种特殊字符组合,进而匹配出对应的数据结果。

1 案例1:使用正则表达式
1.1 问题
本案例要求熟悉正则表达式的编写,完成以下任务:
- 利用grep或egrep工具练习正则表达式的基本用法
1.2 方案
表-1 基本正则列表

表-2 扩展正则列表

1.3 步骤
实现此案例需要按照如下步骤进行。
步骤一:正则表达式匹配练习
1)基本正则表达式
- head -5 /etc/passwd > user #准备素材
测试 ^ $ [] [^]
- grep ^root user #找以root开头的行
- grep bash$ user #找以bash结尾的行
- grep ^$ user #找空行
- grep -v ^$ user #显示除了空行的内容
- grep "[root]" user #找r、o、t任意一个字符
- grep "[rot]" user #效果同上
- grep "[^rot]" user #显示r或o或t以外的内容
- grep "[0123456789]" user #找所有数字
- grep "[0-9]" user #效果同上
- grep "[^0-9]" user #显示数字以外内容
- grep "[a-z]" user #找所有小写字母
- grep "[A-Z]" user #找所有大写字母
- grep "[a-Z]" user #找所有字母
- grep "[^0-9a-Z]" user #找所有符号
测试 . *
- grep "." user #找任意单个字符,文档中每个字符都可以理解为任意字符
- grep "r..t" user #找rt之间有2个任意字符的行
- grep "r.t" user #找rt之间有1个任意字符的行,没有匹配内容,就无输出
- grep "*" user #错误用法,*号是匹配前一个字符任意次,不能单独使用
- grep "ro*t" user #找rt,中间的o有没有都行,有几次都行
- grep ".*" user #找任意,包括空行 .与*的组合在正则中相当于通配符的效果
测试 \{n\} \{n,\} \{n,m\} \(\)
- grep "ro\{1,2\}t" user #找rt,中间的o可以有1~2个
- grep "ro\{2,6\}t" user #找rt,中间的o可以有2~6个
- grep "ro\{1,\}t" user #找rt,中间的o可以有1个以及1个以上
- grep "ro\{3\}t" user #找rt,中间的o必须只有有3个
- grep "\(0:\)\{2\}" user #找连续的2个0: 小括号的作用是将字符组合为一个整体
扩展正则表达式
以上命令均可以加-E选项并且去掉所有\,改成扩展正则的用法
比如grep "ro\{1,\}t" user可以改成 grep -E "ro{1,}t" user
或者egrep "ro{1,}t" user
- grep "ro\{1,\}t" user #使用基本正则找o出现1次以及1次以上
- egrep "ro{1,}t" user #使用扩展正则,效果同上,比较精简
- egrep "ro+t" user #使用扩展正则,效果同上,最精简
- grep "roo\{0,1\}t" user #使用基本正则找第二个o出现0~1次
- egrep "roo{0,1}t" user #使用扩展正则,效果同上,比较精简
- egrep "roo?t" user #使用扩展正则,效果同上,最精简
- egrep "(0:){2}" user #找连续的2个0: 小括号的作用是将字符组合为一个整体
- egrep "root|bin" user #找有root或者bin的行
- egrep "the\b" abc.txt #找单词the,右边不允许出现数字、字母、下划线
- egrep "\bthe\b" abc.txt #the两边都不允许出现数字、字母、下划线
- egrep "\<the\>" abc.txt #效果同上
思考:如何匹配大范围的数字?比如250-255
二、sed基本用法
2 案例2:sed基本用法
2.1 问题
本案例要求熟悉sed命令的p、d、s等常见操作
2.2 方案
sed文本处理工具的用法:
特点:逐行处理。
- 用法1:前置命令 | sed [选项] '条件指令'
- 用法2:sed [选项] '条件指令' 文件.. ..
2.3 步骤
实现此案例需要按照如下步骤进行。
步骤一:认识sed工具
sed命令的常用选项如下:
-n(屏蔽默认输出,默认sed会输出读取文档的全部内容)
-r(支持扩展正则)
-i(修改源文件)
- 条件可以是行号或者/正则/,没有条件时默认为所有行都执行指令
- 指令可以是p输出、d删除、s替换
步骤二:使用sed
1)行号案例
- head -5 /etc/passwd > user #准备素材
- sed -n 'p' user #输出所有行
- sed -n '1p' user #输出第1行
- sed -n '2p' user #输出第2行
- sed -n '3p' user #输出第3行
- sed -n '2,4p' user #输出2~4行
- sed -n '2p;4p' user #输出第2行与第4行
- sed -n '3,+1p' user #输出第3行以及后面1行
- sed -n '1~2p' /etc/passwd #输出奇数行
2)使用正则当条件
- sed -n '/^root/p' user #输出以root开头的行
- sed -n '/root/p' user #输出包含root的行
- sed -nr '/^root|^bin/p' user #输出以root开头的行或bin开头的行,|是扩展正则,需要r选项
3)特殊用法
- sed -n '1!p' user #输出除了第1行的内容,!是取反
- sed -n '$p' user #输出最后一行
- sed -n '=' user #输出行号,如果是$=就是最后一行的行号
以上操作,如果去掉-n,在将p指令改成d指令就是删除
步骤三:sed工具的p、d、s操作指令案例集合
1)p指令案例集锦(自己提前生成一个a.txt文件)
- [root@svr5 ~]# sed -n 'p' a.txt #输出所有行,等同于cat a.txt
- [root@svr5 ~]# sed -n '4p' a.txt #输出第4行
- [root@svr5 ~]# sed -n '4,7p' a.txt #输出第4~7行
- [root@svr5 ~]# sed -n '/^bin/p' a.txt #输出以bin开头的行
- [root@svr5 ~]# sed -n '$=' a.txt #输出文件的行数
2)d指令案例集锦(自己提前生成一个a.txt文件)
- [root@svr5 ~]# sed '3,5d' a.txt #删除第3~5行
- [root@svr5 ~]# sed '/xml/d' a.txt #删除所有包含xml的行
- [root@svr5 ~]# sed '/xml/!d' a.txt #删除不包含xml的行,!符号表示取反
- [root@svr5 ~]# sed '/^install/d' a.txt #删除以install开头的行
- [root@svr5 ~]# sed '$d' a.txt #删除文件的最后一行
- [root@svr5 ~]# sed '/^$/d' a.txt #删除所有空行
3)sed命令的s替换基本功能(s/旧内容/新内容/选项):
- [root@svr5 ~]# vim shu.txt #新建素材
- 2017 2011 2018
- 2017 2017 2024
- 2017 2017 2017
- sed 's/2017/6666/' shu.txt #把所有行的第1个2017替换成6666
- sed 's/2017/6666/2' shu.txt #把所有行的第2个2017替换成6666
- sed '1s/2017/6666/' shu.txt #把第1行的第1个2017替换成6666
- sed '3s/2017/6666/3' shu.txt #把第3行的第3个2017替换成6666
- sed 's/2017/6666/g' shu.txt #所有行的所有个2017都替换
- sed '/2024/s/2017/6666/g' shu.txt #找含有2024的行,将里面的所有2017替换成6666
思考:如果想把 /bin/bash 替换成 /sbin/sh 怎么操作?
- sed -i '1s/bin/sbin/' user #传统方法可以一个一个换,先换一个
- sed -i '1s/bash/sh/' user #再换一个
如果想一步替换:
- sed 's//bin/bash//sbin/sh/' user #直接替换,报错
- sed 's/\/bin\/bash/\/sbin\/sh/' user #使用转义符号可以成功,但不方便
- sed 's!/bin/bash!/sbin/sh!' user #最佳方案,更改s的替换符
- sed 's(/bin/bash(/sbin/sh(' user #替换符号可以用键盘上大部分字符
三、sed 文本块处理
3 案例3:编写脚本,搭建httpd服务,用82号端口开启服务
编写脚本,按下列方法实现
- #!/bin/bash
- setenforce 0 #关闭selinux
- yum -y install httpd &> /dev/null #安装网站
- echo "sed-test~~~" > /var/www/html/index.html #定义默认页
- sed -i '/^Listen 80/s/0/2/' /etc/httpd/conf/httpd.conf #修改配置文件,将监听端口修改为82
- systemctl restart httpd #开服务
- systemctl enable httpd #设置开机自启
然后运行脚本
- curl 192.168.2.5:82 #脚本运行之后,测试82端口看到页面即可
- sed-test~~~
- ss -ntulp | grep httpd #检查服务的端口是否为82
人工智能提示词:
使用sed工具编写shell脚本,将httpd服务的端口修改为82,并定义默认页面为”sed-test”后开启服务
4 sed综合脚本应用
4.1 问题
本案例要求编写脚本,实现以下需求,效果如图-1:
- 找到使用bash作登录Shell的本地账户名
- 列出这些账户的shadow密码记录
- 按每行“账户名 --> 密码记录”保存到文件中

图-1
4.2 方案
基本思路如下:
- 先用sed工具取出登录Shell为/bin/bash的账户
- 再结合循环取得的账户记录,逐行进行处理
- 针对每一行账户记录,采用掐头去尾的方式获得名称、密码
- 按照指定格式追加到文件
4.3 步骤
实现此案例需要按照如下步骤进行。
- #!/bin/bash
- u=$(sed -n '/bash$/s/:.*//p' /etc/passwd) #找到passwd文档中以bash结尾的行,然后将行中冒号以及冒号后面内容都删除,此处的p代表仅仅显示s替换成功的行,最后赋值给u
- for i in $u #将那些用bash的账户名交给for循环
- do
- pass=$(grep $i /etc/shadow) #用每个账户名去shadow中找对应信息
- pass=${pass#*:} #掐头,从左往右删除到第1个冒号
- pass=${pass%%:*} #去尾,从右往左删除到最后一个冒号,经过上述步骤,pass就是最终要的密码了
- echo "$i --> $pass" #按格式喊出,如果要存到文件中就用追加重定向
- done
环境准备:可以把第一阶段的虚拟机的 88.2 , 88.3的虚拟机卸载了,只留下 一个主机192.168.88.240就行。

配置IP之前,看下WINDOWS真机网卡private1,2分别是那个88,89那个网段。后续好给WEB1,2. CLIENT客户机测试相应功能服务。
思路:配好PROXY主机的 private1网段,给它配置好YUM,修改主机名和IP地址。
配置好后克隆给WEB1,WEB2,CLIENT机器,再分别进去设置他们的主机名和IP。
最后 用PING命令与PROXY机器测试网络联通性。
相关操作: 设置主机名--》设置网卡别名--》手动设置网卡IP--》激活网卡配置。
PING 网关IP:192.168.99.254 (网卡1)/ 192.168.88.524( 添加硬件网卡,Private2网段后配置---》克隆虚拟机--》分别配置主机名/网卡IP。
(不记得配置了,可以去看看第一阶段的相关命令)

目的:模拟真实企业服务器与客户机环境,最小化安装,节省服务器空间。
SHELL DAY5
一、awk应用

1 正则表达式补充
\w 匹配数字、字母、下划线
- egrep "roo\w" user #找roo后面必须是数字或字母或下划线的字符串
\s 匹配空格、tab键
- egrep "roo\s" user #找roo后面是1个空格或者tab键打出来的空格的字符串,如果没有
- 就不输出
\d 匹配数字,和[0-9]等效
- egrep "(25[0-5]\.|2[0-4][0-9]\.|1?[0-9]?[0-9]\.){3}(25[0-5]|2[0-4][0-9]|1?[0-9]?[0-9])" #匹配ip地址
- grep -P "(25[0-5]\.|2[0-4]\d\.|1?\d?\d\.){3}(25[0-5]|2[0-4]\d|1?\d?\d)" #匹配ip地址
2 sed补充
a行下追加 i行上添加 c替换整行
- sed 'a 666' user #所有行的下面追加666
- sed '1a 666' user #第1行的下面追加666
- sed '/^bin/a 666' user #在以bin开头的行的下面追加666
- sed 'i 666' user #所有行的上面添加666
- sed '5i 666' user #第5行的上面添加666
- sed '$i 666' user #最后1行的上面添加666
- sed 'c 666' user #所有行都替换成666
- sed '1c 666' user #替换第1行为666
替换特殊用法
- cat abc.txt #先准备素材
- 100 laowang
- 98 gangge
- 59 laoniu
- sed -r 's/([0-9]+)(\s+)([a-z]+)/\3\2\1/' abc.txt #使用替换功能更改文本列,此处小括号相当于保留(复制),\1相当于粘贴之前第1个小括号里的内容
下面,我们欢迎虚拟机云计算领域,文本处理三兄弟,最后一位登场。

3 案例1:使用awk提取文本
3.1 问题
本案例要求使用awk工具完成下列过滤任务:
- 练习awk工具的基本用法
- 提取本机系统数据
- 格式化输出信息
3.2 步骤
实现此案例需要按照如下步骤进行。
步骤一:awk的基本用法
1)基本操作方法
格式1:awk [选项] '[条件]{指令}' 文件
格式2:前置指令 | awk [选项] '[条件]{指令}'
其中,print 是最常用的编辑指令;若有多条编辑指令,可用分号分隔。
Awk过滤数据时支持仅打印某一列,如第2列、第5列等。
处理文本时,默认将空格、制表符作为分隔符。
条件可以用/ /的方式,与sed类似
awk常用内置变量:
$0 文本当前行的全部内容
$1 文本的第1列
$2 文件的第2列
$3 文件的第3列,依此类推
NR 文件当前行的行号
NF 文件当前行的列数(有几列)
- [root@svr5 ~]# cat abc.txt
- hello the world
- welcome to beijing
- awk '{print}' abc.txt #输出所有
- awk '/to/{print}' abc.txt #输出有to的那行
- awk '{print $2}' abc.txt #输出所有行的第2列
- awk '/to/{print $1}' abc.txt #输出有to的那行的第1列
- awk '{print $0}' abc.txt #输出所有行所有列
- awk '{print $0,$1}' abc.txt #输出所有行所有列,第1列
- awk '{print NR}' abc.txt #输出所有行的行号
- awk '{print NR,$0}' abc.txt #输出所有行的行号,所有列
- awk '{print NR,NF}' abc.txt #输出所有行的行号,列号(有几列)
再使用之前的user文档测试
- awk '/^bin/{print NR}' user #找以bin开头的行,显示该行的行号
- awk '/^bin/{print NR,$0}' user #找以bin开头的行,显示该行的行号,所有列
- awk '{print NF}' user #输出所有行的列号(每行有几列)
2)选项 -F 可指定分隔符
- awk -F: '{print $1}' user #文档中如果没有空格,可以用F修改分隔符
- awk -F: '{print $1,$6}' user #使用冒号作为列的分隔符,显示第1、6列
awk还识别多种单个的字符,比如以“:”或“/”分隔
- awk -F [:/] '/^root/{print $1,$10}' user
awk的print指令不仅可以打印变量,还可以打印常量
- awk -F: '{print $1" 的家目录是 "$6}' user #输出常量,加双引号即可
- awk -F: '{print $1" 的解释器是 "$7}' user
步骤二:利用awk提取本机系统数据
1)收集根分区剩余容量
- df -h | awk '/\/$/{print $4}' #使用df -h 作为前置指令交给awk处理找到以/结尾的行,并输出第4列
- df -h | awk '/\/$/{print "根分区剩余容量是"$4}' #然后加常量输出
2)收集网卡流量信息
RX为接收的数据量,TX为发送的数据量。packets以数据包的数量为单位,bytes以字节为单位:
- ifconfig eth0 | awk '/RX p/{print "eth0网卡接收的数据量是"$5"字节"}'
- ifconfig eth0 | awk '/TX p/{print "eth0网卡发送的数据量是"$5"字节"}'
步骤三:格式化输出信息
1)awk处理的时机
awk会逐行处理文本,支持在处理第一行之前做一些准备工作,以及在处理完最后一行之后做一些总结性质的工作。在命令格式上分别体现如下:
- awk [选项] '[条件]{指令}' 文件
- awk [选项] 'BEGIN{指令} {指令} END{指令}' 文件
- BEGIN{ } 行前处理,读取文件内容前执行,指令执行1次
- { } 逐行处理,读取文件过程中执行,指令执行n次
- END{ } 行后处理,读取文件结束后执行,指令执行1次
- awk -F: 'BEGIN{print "start"}{print $1}END{print "over"}' user
- awk 'BEGIN{print NR}{print NR}END{print NR}' user
2)格式化输出/etc/passwd文件
要求: 格式化输出passwd文件内容时,要求第一行为列表标题,中间打印用户的名称、UID、家目录信息,最后一行提示一共已处理文本的总行数,效果如图-1所示。

图-1
3)根据实现思路编写、验证awk过滤语句
输出信息时,可以使用“\t”显示Tab制表位:
- awk 'BEGIN{print "User\tUID\tHome"}' #第1步输出表头信息
- awk -F: '{print $1"\t"$3"\t"$6}' user #第2步输出内容
- awk 'END{print "总计"NR"行" }' user #第3步输出结尾
- awk -F: 'BEGIN{print "User\tUID\tHome"}{print $1"\t"$3"\t"$6}END{print "总计"NR"行"}' user #合在一起写
4 案例2:awk处理条件
4.1 问题
- 本案例要求使用awk工具熟悉各种条件,以达到更精确查找某行的目的
4.2 步骤
实现此案例需要按照如下步骤进行。
步骤一:认识awk处理条件的设置
使用正则设置条件
/正则/ ~ 包含 !~不包含
- awk -F: '$6~/root/{print}' user #输出第6列包含root的行
- awk -F: '$6~/bin/{print}' user #输出第6列包含bin的行
- awk -F: '$6!~/bin/{print}' user #输出第6列不包含bin的行
2)使用数值/字符串比较设置条件
比较符号:==(等于) !=(不等于) >(大于)
>=(大于等于) <(小于) <=(小于等于)
- awk -F: '$3<3{print}' user #输出第3列小于3的行
- awk -F: '$3<=3{print}' user #输出第3列小于等于3的行
- awk -F: 'NR==2{print}' user #输出第2行
- awk -F: 'NR>2{print}' user #输出行号大于2的行
3)逻辑测试条件
- awk -F: 'NR>=3&&NR<=5{print}' user #找行号是3~5行
- awk -F: 'NR==2||NR==4{print}' user #找行号是2或者4的行
- awk -F: 'NR==2||NR==40{print}' user #如果只有一个条件满足就显示一个
当定义了条件且指令就是print时可以省略指令不写
- awk -F: '$7~/bash/&&$3<=500' user #找第7列包含bash并且第3列小于等于500的行
- awk 'NR==2&&NR==4' user #找行号既是2又是4的行,不存在,无输出
- awk -F: '$7~/bash/&&NR<=3' user #找第7列包含bash并且行号是1~3的
- awk -F: '$7~/bash/||NR<=3' user #找第7列包含bash或者行号是1~3的
4)数学运算
- awk 'NR%2==0{print NR,$0}' user #在条件中使用运算,找到将行号除以2余数等于0的行,然后输出该行的行号和所有列,相当于输出偶数行
5 使用awk统计网站访问量
使用awk统计网站访问量
- setenforce 0 #关闭selinux
- systemctl stop firewalld #关闭防火墙
- systemctl restart httpd #开启网站服务
使用浏览器多访问几次网站,包括本机用curl
- curl 192.168.88.2:82 #如果端口没改过就不用敲:82
- awk '{print $1}' /var/log/httpd/access_log #初步统计,不完美
6 案例3:awk数组
6.1 问题
本案例要求了解awk数组的使用
步骤一:awk数组
1)数组的语法格式
数组是一个可以存储多个值的变量,具体使用的格式如下:
定义数组的格式:数组名[下标]=元素值
调用数组的格式:数组名[下标]
- awk 'BEGIN{a=10;a=20;print a}' #首先测试普通变量
- awk 'BEGIN{a[1]=10;a[2]=20;print a[2],a[1]}' #使用awk测试数组,创建数组a,下标1对应值是10,下标2对应值是20,然后输出下标是2与下标是1的值
注意,awk数组的下标除了可以使用数字,也可以使用字符串,字符串需要使用双引号:
- awk 'BEGIN{a["abc"]="abcabc";a["xyz"]="xyzxyz";print a["xyz"]}'
以上信息是手工输入,还可以从文档收集
准备一个测试文档,里面有6行,每行分别是abc、xyz、abc、opq、xyz、abc 然后按照awk逐行处理的工作特点使用awk '{a[$1]++}' shu.txt 走完每一行得到下列结果,但不会输出到屏幕
- 逐行任务 每行实际执行 执行结果
- a[$1]++ a[abc]++ a[abc]=1
- a[$1]++ a[xyz]++ a[xyz]=1
- a[$1]++ a[abc]++ a[abc]=2
- a[$1]++ a[opq]++ a[opq]=1
- a[$1]++ a[xyz]++ a[xyz]=2
- a[$1]++ a[abc]++ a[abc]=3
- awk '{a[$1]++}END{print a["abc"]}' shu.txt #如果要看值,可以输出数组名[下标],由于数组下标不确定,逐行任务运算前可以不用BEGIN任务定义
根据上述操作了解数组可以收集信息,但收集完了之后查看确不方便,可以用for循环实现。方法如下:
for(变量名 in 数组名){print 变量名} #这个格式可以查看数组的所有下标
- awk '{a[$1]++}END{for(i in a){print i,a[i]}}' shu.txt #使用逐行任务与数组收集文档shu.txt中的信息,然后在END任务中使用for循环显示所有数组a的下标与值
二、综合案例
7 案例4:awk扩展应用
7.1 问题
本案例要求使用awk工具完成下列两个任务:
分析Web日志的访问量排名,要求获得客户机的地址、访问次数,并且按照访问次数排名
7.2 方案
1)awk统计Web访问排名
在分析Web日志文件时,每条访问记录的第一列就是客户机的IP地址,其中会有很多重复的IP地址。因此只用awk提取出这一列是不够的,还需要统计重复记录的数量并且进行排序。
通过awk提取信息时,利用IP地址作为数组下标,每遇到一个重复值就将此数组元素递增1,最终就获得了这个IP地址出现的次数。
针对文本排序输出可以采用sort命令,相关的常见选项为-r、-n、-k。其中-n表示按数字顺序升序排列,而-r表示反序,-k可以指定按第几个字段来排序。
7.3 步骤
实现此案例需要按照如下步骤进行。
步骤一:统计Web访问量排名
分步测试、验证效果如下所述。
1)提取IP地址及访问量
- awk '{ip[$1]++}END{for(i in ip){print ip[i],i }}' /var/log/httpd/access_log #数组名称可以自定义其他的,通过awk数组+for循环查看日志中哪个ip来访过以及来访的次数
2)对第1)步的结果根据访问量排名
- awk '{ip[$1]++}END{for(i in ip){print ip[i],i}}' /var/log/httpd/access_log | sort -nr #使用sort命令增加排序功能,-n是以数字形式排序,-r是降序
8 案例5:安全检测
8.1 问题
本案例要检测登录者的IP
检测安全日志,登录root且密码错误就输出对方IP
8.2 步骤
实现此案例需要按照如下步骤进行。
步骤一:准备工作
1)/var/log/secure是安全日志,如果有人登陆时输入错误密码的话信息会记录下来,这种信息可以用awk抓取出来,方法如下:
- awk '/Failed password for root/{ip[$11]++}END{for(i in ip){print i,ip[i]}}' /var/log/secure #统计安全日志中访问root账户且密码输入错误的ip地址与次数
9 案例6:编写监控脚本
9.1 问题
本案例要求编写脚本,实现计算机各个性能数据监控的功能,具体监控项目要求如下:
(类似鲁大师管家O(∩_∩)O)

9.2 步骤
实现此案例需要按照如下步骤进行。
步骤一:准备工作
1)部分常用命令
- [root@svr5 ~]# uptime #查看CPU负载
- [root@svr5 ~]# ifconfig eth0 #查看网卡流量
- [root@svr5 ~]# free #查看内存信息
- [root@svr5 ~]# df #查看磁盘空间
- [root@svr5 ~]# wc -l /etc/passwd #查看计算机账户数量
- [root@svr5 ~]# who |wc -l #查看登录账户数量
- [root@svr5 ~]# rpm -qa |wc -l #查看已安装软件包数量
步骤二:编写参考脚本
1)脚本内容如下:
- #!/bin/bash
- while :
- do
- clear #清屏
- free -h | awk '/^Mem:/{print "剩余内存容量是"$4}'
- df -h | awk '/\/$/{print "根分区剩余容量是"$4}'
- awk 'END{print "用户总数是"NR"个"}' /etc/passwd
- who | awk 'END{print "登录用户数量是"NR"个"}'
- uptime | awk '{print "cpu的15分钟平均负载是"$NF}'
- rpm -qa | awk 'END{print "安装的软件包数量是"NR"个"}'
- sleep 3
- done
人工智能提示词:
编写shell脚本,利用awk截取系统各种信息,如CPU的15分钟平均负载、网卡接收流量信息、内存与硬盘剩余空间大小、账户数量等,并每隔3秒循环显示一次
SHELL DAY06
项目实战
1 案例1:系统初始化
某企业准备了一批Linux服务器(系统有7版本与8版本)来运行业务,现在需要将服务器做初始配置,编写一个脚本可以匹配不同系统的服务器实现以下需求:
1,所有服务器永久关闭防火墙服务和SELinux
2,关闭7版本系统的命令历史记录,修改8版本的命令历史记录最多保存2000条并加上时间戳
3,关闭8版本系统的交换分区
4,定义root远程登录系统后的ssh保持时间为300秒
5,设置时间同步,ntp服务器地址是192.168.88.240
- #!/bin/bash
- #脚本执行完后,用ssh远程登录测试
- #可以先手工备份/etc/fstab和/etc/profile
- #1)判断当前账户身份,并关闭防火墙与selinux
- [ $UID -ne 0 ] && echo "请使用管理员操作" && exit
- systemctl stop firewalld
- systemctl disable firewalld
- setenforce 0
- sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
- #2)根据不同版本的系统执行各自的任务
- egrep -q "\s+8\.[0-9]" /etc/redhat-release #判断系统版本
- if [ $? -ne 0 ];then
- sed -ri 's/HISTSIZE=[0-9]+/HISTSIZE=0/' /etc/profile #关闭历史命令
- else
- sed -ri 's/HISTSIZE=[0-9]+/HISTSIZE=2000/' /etc/profile #历史命令2000条
- sed -i '/^export /i HISTTIMEFORMAT="%F %T "' /etc/profile #历史命令时间戳
- swapoff -a #关闭交换分区
- sed -i '/swap/s/^/#/' /etc/fstab #关闭交换分区自动挂载
- fi
- #3)最后所有机器设置ssh超时时间与时间同步
- echo "export TMOUT=300" >> ~/.bash_profile #定义ssh超时退出时间
- yum -y install chrony
- systemctl enable chronyd
- sed -ri '/^(pool|server).*iburst/s/^/#/' /etc/chrony.conf
- sed -i '1i server 192.168.88.240 iburst' /etc/chrony.conf
- systemctl restart chronyd
人工智能提示词:
编写shell脚本,关闭防火墙,利用sed永久关闭selinux,定义root远程登录系统后的ssh保持时间为300秒,并设置时间同步,ntp服务器地址是192.168.88.240,然后判断linux系统版本,关闭7版本系统的命令历史记录,修改8版本的命令历史记录最多保存2000条并加上时间戳,关闭8版本系统的交换分区
2 文档处理
首先要了解:
< 符号,输入重定向,可以在后面需要跟文件名,这样让程序不再从键盘读取数据,而是从文件中读取数据。
- mail -s test root < /opt/mail.txt
<< 符号也称Here Document,代表你需要的内容在这里,某指令导入字符串时使用,而无需文件
- mail -s test root << EOF
- hello
- test mail~
- EOF
使用read指令配合输入重定向可同时定义多个变量
- read a b
- abc xyz #同时为变量a赋值abc,变量b赋值xyz
- read a b < abc.txt #利用abc.txt文档内容赋值,仅读取第一行
结合while循环批量读取数据并通过read命令给变量赋值
- while read a b
- do
- echo $a $b
- done < abc.txt #利用abc.txt文档内容赋值,读取所有行
根据文档内容,创建账户并同时配置密码
首先准备测试文档user.txt
研发部
zhangsan haha123
人事部
lisi xixi456
wangwu lele789
销售部
zhaoliu kaka765
- #!/bin/bash
- while read name pass
- do
- [ -z $pass ] && continue #如果没有密码则不创建,那个是部门的名字的行
- useradd $name
- echo $pass | passwd --stdin $name
- done < user.txt
人工智能提示词:
编写shell脚本,利用循环处理下列文档,跳过部门行,创建用户的同时并配置第二列的密码
(此处将user.txt内容一起提交)
3 案例2:通过文档批量创建账户并配置密码
系统中的/dev/urandom可以获得取之不尽的随机字符,但内容太随意有些是不需要的,如果文档中没有密码,可以使用tr处理这些随机字符获取密码
- tr -cd '_a-zA-Z0-9' < /dev/urandom | head -c 10 #-c是取反 -d是删除,对_a-zA-Z0-9取反删除,剩下就只是_a-zA-Z0-9这个范围内的字符串,head -c 10 可以得到10位字符
编写脚本:
- #!/bin/bash
- x=$(awk '/^[a-zA-Z0-9]/&&!/已创建/{print NR}' user.txt)
- if [ -z "$x" ];then
- echo "没有新用户需要创建"
- column -t user.txt #排序对齐
- exit
- fi
- for i in $x #使用循环,分别处理刚才得到的行号
- do
- pass=$(tr -cd '_a-zA-Z0-9' < /dev/urandom | head -c 10) #创建随机密码
- sed -i "${i}s/$/\t$pass/" user.txt #在不同行的用户名后面添加密码
- read name pass << EOF #将文档中用户名和密码分别赋值给name与pass
- $(sed -n "${i}p" user.txt) #获取命令执行结果
- EOF #这里的EOF代表到此为止,将上一个EOF与这个EOF之间的内容输入重定向给read
- useradd $name
- echo $pass | passwd --stdin $name
- sed -i "${i}s/$/ 已创建/" user.txt #添加“已创建”字样
- done
- column -t user.txt
人工智能提示词:
编写shell脚本,循环处理user.txt文档每行,跳过没有英文的行(如研发部),创建用户的同时使用tr与random文件生成10位随机密码利用sed写在user.txt文档的用户名后(第二列),并给用户配置此密码,之后行尾追加“已创建”三个字写入user.txt文档
(此处将user.txt内容一起提交)
4 制作菜单脚本
4.1 步骤
实现此案例需要使用人工智能实现,执行脚本后可以操控ftp服务,具体需求如下:
要显示至少3个菜单,有安装服务、开启或关闭服务、退出
每个菜单要有对应的英文或者数字序号
当用户执行脚本后按下对应菜单的序号之后,即可执行对应的任务
人工智能提示词:
编写shell脚本,在rocky或redhat系统生成操控vsftpd的菜单,要求显示至少3个菜单,有安装服务、开启或关闭服务、退出,每个菜单要有对应的英文或者数字序号,当用户执行脚本后按下对应菜单的序号之后,即可执行对应的任务
- 参考代码:
- 1,首先创建安装服务的函数文件
- vim install_vsftpd
- install_vsftpd() {
- echo "安装服务中。。。"
- yum install -y vsftpd &> /dev/null
- echo "服务安装完毕"
- }
- 2,创建管理服务的函数文件(开启、关闭、查看状态)
- vim manage_vsftpd
- manage_vsftpd() {
- echo "=FTP 服务管理="
- echo "1. 开启服务"
- echo "2. 停止服务"
- echo "3. 检查状态"
- read -p "请输入你的选择 " action
- case $action in
- 1)
- systemctl start vsftpd
- echo "FTP 服务开启了";;
- 2)
- systemctl stop vsftpd
- echo "FTP 服务关闭了";;
- 3)
- systemctl status vsftpd;;
- *)
- echo "无效输入,请输入1~3"
- esac
- }
- 3,编写脚本
- vim ftp.sh
- #!/bin/bash
- . install_vsftpd #读取安装服务的函数文件
- . manage_vsftpd #读取管理服务的函数文件
- function main_menu() {
- echo "=FTP 服务菜单="
- echo "1. 安装服务"
- echo "2. 管理服务"
- echo "3. Exit"
- read -p "请输入你的选择:" choice
- case $choice in
- 1)
- install_vsftpd;;
- 2)
- manage_vsftpd;;
- 3)
- echo "退出脚本"
- exit;;
- *)
- echo "无效输入,请输入1~3"
- esac
- }
- main_menu #调用主菜单开始脚本
5 数据备份
1.备份/var/www/html 里面除了.tmp类型的所有文件到/opt/backup_data
2.备份的文件名要带时间戳,打tar包,格式为web_file_年-月-日.tar.gz
3.如果/opt/backup_data中备份的tar包凑齐5个之后,就都上传到目标服务器的/backup目录中并删除本地的这些tar包
4.任务执行成功或失败都要给出提示信息
使用tar工具可以通过文件选择功能的--exclude对不需要文件进行排除
- #!/bin/bash
- sou_path=/var/www/html #定义备份数据的目录变量
- tar_path=/opt/backup_data #定义tar包存储目录变量
- date=$(date +%Y-%m-%d) #时间格式变量
- ex_file=*.tmp #排除文件变量
- dest_ser_ip=192.168.88.2 #文件上传目标服务器
- tar -zcf ${tar_path}/web_file_${date}.tar.gz --exclude=$ex_file ${sou_path}
- file_total=$(ls ${tar_path} | wc -l) #定义tar包总数变量
- echo "${date}的文件已打tar包放入${tar_path},目前备份文件总数是${file_total}个"
- if [ $file_total -ge 5 ];then
- scp ${tar_path}/* root@$dest_ser_ip:/backup &> /dev/null
- if [ $? -ne 0 ];then
- echo "上传出错"
- else
- rm -rf ${tar_path}/web_file*
- echo "上传成功!"
- fi
- fi
人工智能提示词:
编写shell脚本,备份/var/www/html 里面除了.tmp类型的所有文件到/opt/backup_data,备份的文件名要带时间戳,打tar包,格式为web_file_年-月-日.tar.gz,如果/opt/backup_data中备份的tar包凑齐5个之后,就都scp到目标服务器的/backup目录中并删除本地的这些tar包,任务执行成功或失败都要给出提示信息
云计算SHELL模块全部内容,是每个云计算工程师必须要掌握的吃饭家伙,必须时常练习,才可以对知识加以使用。(* ̄︶ ̄)















 735
735











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









