







Pandas库的使用
1. Pandas库的介绍
Pandas是Python第三方库,提供高性能易用数据类型和分析工具。引用pandas库:
import pandas as pd
对Pandas库的理解:
两个数据类型: Series, DataFrame
基于上述数据类型的各类操作
基本操作、运算操作、特征类操作、关联类操作
Pandas基于NumPy实现的,NumPy与Pandas的区别如下:
| Numpy | Pandas |
|---|---|
| 基础数据类型, ndarray | 扩展数据类型, Series 和 DataFrame |
| 关注数据的结构表达(维度,数据间的关系) | 关注数据的应用表达(数据与索引间关系) |
2. Pandas库数据类型及操作
- Series = 索引 + 一维数据
- DataFrame = 行列索引 + 二维数据
- 理解数据类型与索引的关系,操作索引即操作数据
- 重新索引、数据删除、算术运算、比较运算
- 像对待单一数据一样对待Series和DataFrame对象
2.1 Series类型
2.1.1 Series类型
Series类型由一组数据及与之相关的数据索引组成。
Series举例:pd.Series() 函数参数1指定索引值,参数2指定索引,省略参数2可创建从0开始的自动索引。

Series类型可以由如下类型创建:Python列表、标量值、Python字典、ndarray、其他函数
- 从标量值创建

- 从Python字典类型创建

- 从ndarray类型创建(十分常用)

2.1.2 Series类型基本操作
-
索引类型Index的常用方法

-
Series类型包括index索引和values两部分
.index可获得索引,.values可获得数据,举例如下:

其中Series中的自动索引和自定义索引并存,但不能混用
- Series类型的操作类似ndarray类型
- 索引方法相同,采用
[] - NumPy中运算和操作可用于Series类型
- 可以通过自定义索引的列表进行切片
- 可以通过自动索引进行切片,如果存在自定义索引,则一同被切片
- 索引方法相同,采用
举例:

Series操作中如果只对其中的一个元素进行索引,比如 b[3],则取出的是 b[3] 对应的值6;如果是自动索引切片,如 b[:3],则切出来的还是一个Series类型的数据,有索引也有值。
- Series类型的操作类似Python字典类型
- 通过自定义索引访问
- 保留字in操作
- 使用
.get()方法
举例:

- Series类型对齐操作,Series类型在运算中会自动对齐不同索引的数据

- Series对象和索引都可以有一个名字,存储在属性.name中

- Series对象可以随时修改并即刻生效
总结:Series是一维带“标签”数组。index_0 -> data_a ,Series基本操作类似ndarray和字典,根据索引对齐。
2.2 DataFrame类型
2.2.1 DataFrame类型介绍
- DataFrame类型由共用相同索引的一组列组成。
- DataFrame是一个表格型的数据类型,每列值类型可以不同。
- DataFrame既有行索引(index)、也有列索引(column)。
- DataFrame常用于表达二维数据,但可以表达多维数据。
2.2.2 DataFrame类型可以由如下类型创建
- 二维ndarray对象,自动创建行索引和列索引

- 由一维ndarray、列表、字典、元组或Series构成的字典

将表格数据转换为字典,而后用DataFrame类型来表示:

- 在表格 --> 字典 --> DataFrame的转换过程中,对应关系如下:
- 原表格中的一列 ----> 字典中的一个元素
- 原表格的表头 ----> 字典中的键 ----> DataFrame中列索引
DataFrame获得其中的元素,索引默认取一列的元素,取一行的元素需要使用 .ix[索引],二维索引取具体的值,如下图:

其中,d['同比'] 表示取 “同比” 该列带有行索引的数据,d.ix['c2'] 表示取 c2 这一行带有列索引的数据,d['同比']['c2'] 表示取对应的具体值。
总结:DataFrame是二维带“标签”数组,基本操作类似Series,依据行列索引。

2.3 Pandas库的数据类型操作
-
如何改变Series和DataFrame对象?
- 增加或重排:重新索引
- 删除:drop
-
重新索引
.reindex()
.reindex()能够改变或重排Series和DataFrame索引
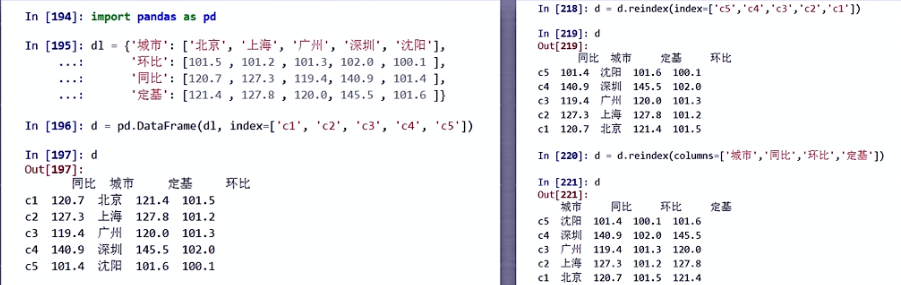
- 删除指定索引对象
.drop()
.drop()能够删除Series和DataFrame指定行或列索引

2.4 Pandas库的数据类型运算
- 算数运算法则
- 算术运算根据行列索引,补齐后运算,运算默认产生浮点数
- 补齐时缺项填充NaN(空值)
- 二维和一维(一维Series默认在轴1参与运算,即二维中的每一行与一维元素进行运算)、一维和零维(一维的每个元素都与零维元素运算)间为广播运算
- 采用
+-*/符号进行的二元运算产生新的对象
3. Pandas数据特征分析
- 一组数据的摘要(摘要:有损地提取数据特征的过程)
- 排序
.sort_index()、.sort_values() - 基本统计函数
.describe() - 累计统计函数
.cum*()、.rolling().* - 相关性分析
.corr()、.cov()
- 排序
3.1 数据排序
.sort_index() 方法在指定轴上根据索引进行排序,默认升序。
.sort_index(axis=0, ascending=True)
举例:

.sort_values()方法在指定轴上根据数值进行排序,默认升序。
Series.sort_values(axis=0, ascending=True)
DataFrame.sort_values(by, axis=0, ascending=True) # by: axis轴上的某个索引或索引列表
.sort_values() 方法举例:

注意:空值NaN统一放到排序末尾
3.2 数据的基本统计分析
- 适用于Series和DataFrame类型的方法

- 适用于Series类型的方法

在Series和DataFrame中,几乎可以囊括所有方法的结果,该方法是 describe() 方法:
| 方法 | 说明 |
|---|---|
| .describe() | 针对0轴(各列)的统计汇总 |
- 一维的Series对象使用
.describe()方法之后仍然为Series对象,如下图:

- 二维的DataFrame对象使用
.describe()方法之后仍然为DataFrame对象,如下图:

3.3 数据的累计统计分析
累计统计分析函数能对序列中的前1-n个数进行累计运算,可减少for循环的使用,使得数据的运算变得更加灵活。
适用于Series和DataFrame类型,基本统计分析函数如下:
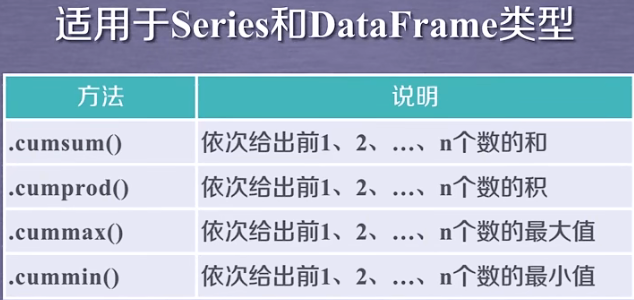
基本统计分析函数举例如下:

适用于Series和DataFrame类型,滚动计算(窗口计算)函数如下:

滚动计算函数举例如下:

3.4 数据的相关分析
适用于Series和DataFrame类型,相关分析函数如下:

相关分析函数举例如下:
















 1951
1951











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









