






注:参考多篇文章与代码所得,在某些过程处可能存在一些理解错误,请大家批评指正。
一、实验内容
利用异常检测方法对甲状腺疾病进行检测。
二、数据介绍
数据集包含16个类别属性,5个数据属性和1个目标属性,共22个属性。
1、 类别属性:
age: continuous.
sex: categorical, M, F.
on thyroxine: categorical, f, t.
query on thyroxine: categorical, f, t.
on antithyroid medication: categorical, f, t.
sick: categorical, f, t.
pregnant: categorical, f, t.
thyroid surgery: categorical, f, t.
I131 treatment: categorical, f, t.
query hypothyroid: categorical, f, t.
query hyperthyroid: categorical, f, t.
lithium: categorical, f, t.
goitre: categorical, f, t.
tumor: categorical, f, t.
hypopituitary: categorical, f, t.
psych: categorical, f, t.
其中年龄标准化为(0,1), 类别变量对应方式: {"M" -> 0 , "F" -> 1}, or {"f" ->0, "t" -> 1}.
2、 数值属性:
TSH: continuous.
T3: continuous.
TT4: continuous.
T4U: continuous.
FTI: continuous.
3、 目标属性:
outlierlabel(target): categorical, o, n。"o" 为离群点and "n" 为正常。最后一列为空,可删除。
三、实验过程
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# 一、导入数据集
data = pd.read_csv("D:/班级作业/数据挖掘/实验报告/甲状腺疾病数据/annthyroid_unsupervised_anomaly_detection.csv")
data.head()
#二、数据探索性分析
import seaborn as sns
# 1.查看数据规模
print(data.shape)
# 2.粗略查看数据集
print (data.describe())
# 3.查看缺失情况(发现无缺失)
print (data.isnull().sum())
# 4.直方图查看各特征的分布
data.hist(figsize=(15,10))
plt.show()
# 5. 皮尔逊相关性分析可视化
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文
plt.rcParams['axes.unicode_minus'] = False # 显示负号
corr = data.corr(method="pearson")
plt.figure(figsize=(10,10))
sns.heatmap(corr,annot=True)
plt.show()
#三、特征分析
# 标签编码
data.iloc[:,21] = data.iloc[:,21].map({'o': -1, 'n': 1}) #o是离群点,n是正常点
data[["Outlier_label "]]
# 划分训练集和测试集
from sklearn.model_selection import train_test_split
X = data.iloc[:,0:21]
y = data[["Outlier_label "]]
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=42)
X_test
# 建模分析
np.random.seed(42)
plt.rcParams['font.sans-serif']=['SimHei'] #中文和负数的显示
plt.rcParams['axes.unicode_minus'] = False
#1.LOF
from sklearn.metrics import accuracy_score
from sklearn.metrics import recall_score
from sklearn.neighbors import LocalOutlierFactor
rate_of_accuracy = [] # 记录不同参数下的准确率
rate_of_recall = [] # 记录不同参数下的召回率
for i in range(1,31):
clf = LocalOutlierFactor(n_neighbors=i, novelty=True)
clf.fit(X_train)
y_pred_test = clf.predict(X_test) # 得到模型的预测结果
accuracy = accuracy_score(y_test, y_pred_test) # 得到模型预测出来正确值比例
rate_of_accuracy.append(accuracy) # 记录准确率
recall = recall_score(y_test, y_pred_test) # 得到模型召回率
rate_of_recall.append(recall) # 记录召回率
# 模型效果可视化
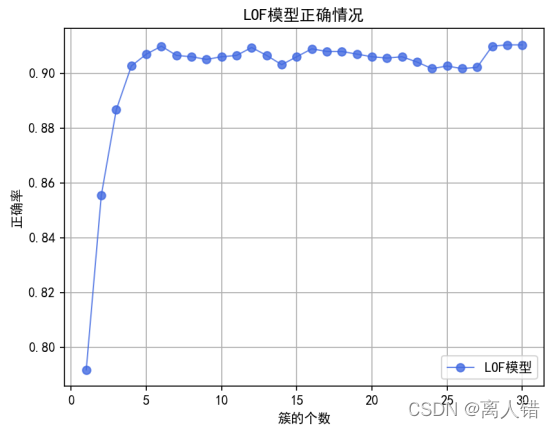
plt.title("LOF模型正确情况")
plt.plot(list(range(1,31)),rate_of_accuracy, 'ro-', color='#4169E1', alpha=0.8, linewidth=1, label='LOF模型')
plt.legend(loc="best")
plt.xlabel('簇的个数')
plt.ylabel('正确率')
plt.grid()
plt.show()
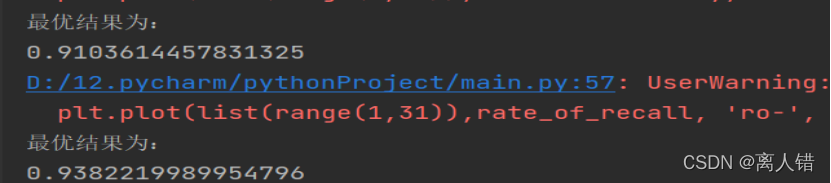
print("最优结果为:")
print(max(rate_of_accuracy))
#查看召回率
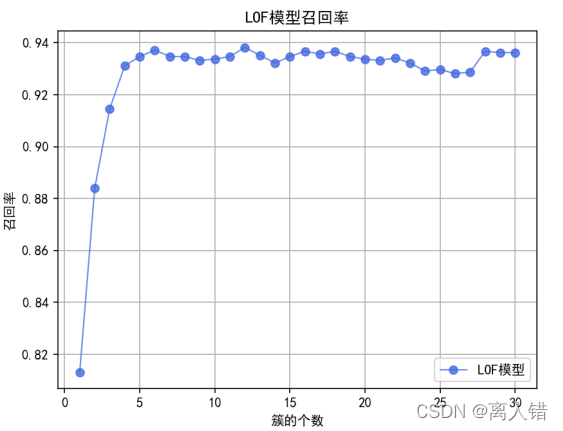
plt.title("LOF模型召回率")
plt.plot(list(range(1,31)),rate_of_recall, 'ro-', color='#4169E1', alpha=0.8, linewidth=1, label='LOF模型')
plt.legend(loc="best")
plt.xlabel('簇的个数')
plt.ylabel('召回率')
plt.grid()
plt.show()
print("最优结果为:")
print(max(rate_of_recall))
#2.iForest
from sklearn.ensemble import IsolationForest
from sklearn.metrics import accuracy_score
from sklearn.metrics import recall_score
rate_of_accuracy = [] # 记录不同参数下的准确率
rate_of_recall = [] # 记录不同参数下的召回率
for i in np.arange(50,201,5):
IF = IsolationForest(n_estimators=i)
IF.fit(X_train)
y_pred_test = IF.predict(X_test) # 得到模型的预测结果
accuracy = accuracy_score(y_test, y_pred_test) # 得到模型预测出来正确值比例
rate_of_accuracy.append(accuracy) # 记录准确率
recall = recall_score(y_test, y_pred_test) # 得到模型召回率
rate_of_recall.append(recall) # 记录召回率
# 模型效果可视化
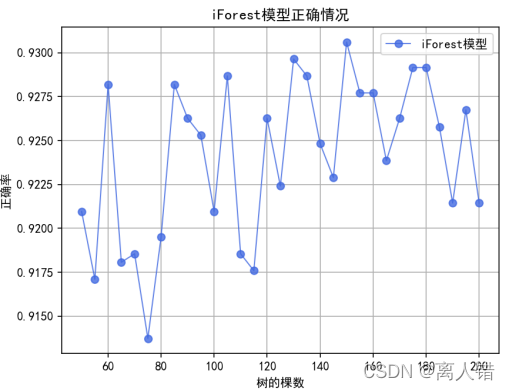
plt.title("iForest模型正确情况")
plt.plot(list(np.arange(50,201,5)),rate_of_accuracy, 'ro-', color='#4169E1', alpha=0.8, linewidth=1, label='iForest模型')
plt.legend(loc="best")
plt.xlabel('树的棵数')
plt.ylabel('正确率')
plt.grid()
plt.show()
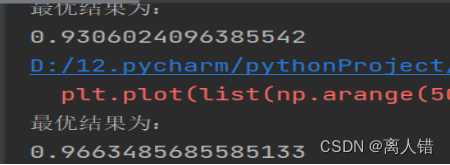
print("最优结果为:")
print(max(rate_of_accuracy))
#查看召回率
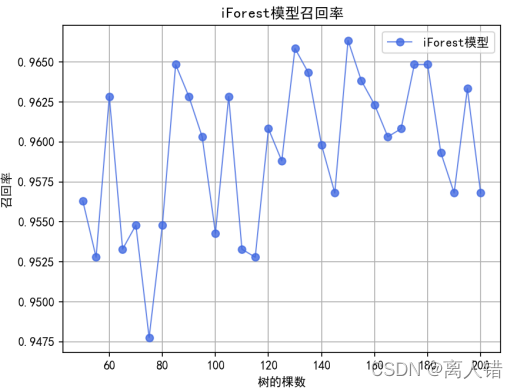
plt.title("iForest模型召回率")
plt.plot(list(np.arange(50,201,5)),rate_of_recall, 'ro-', color='#4169E1', alpha=0.8, linewidth=1, label='iForest模型')
plt.legend(loc="best")
plt.xlabel('树的棵数')
plt.ylabel('召回率')
plt.grid()
plt.show()
print("最优结果为:")
print(max(rate_of_recall))
#3.one-class SVM
from sklearn import svm
rate_of_accuracy3 = [] # 记录不同参数下的准确率
rate_of_recall3 = [] # 记录不同参数下的召回率
for i in np.arange(0.05,1.05,0.05):
osvm3 = svm.OneClassSVM(nu=i, kernel="sigmoid", gamma='scale').fit(X_train)
y_pred_test3 = osvm3.predict(X_test) # 得到模型的预测结果
accuracy3 = accuracy_score(y_test, y_pred_test3) # 得到模型预测出来正确值比例
rate_of_accuracy3.append(accuracy3) # 记录准确率
recall3 = recall_score(y_test, y_pred_test3) # 得到模型召回率
rate_of_recall3.append(recall3) # 记录召回率
# 模型效果可视化
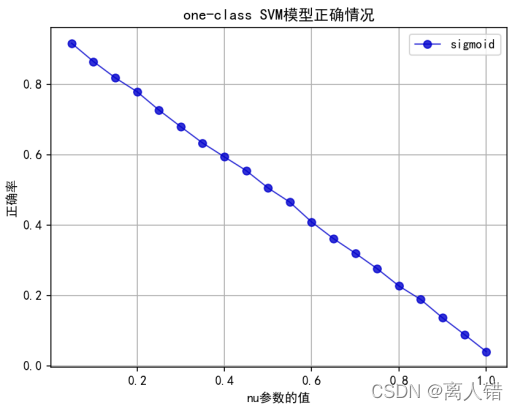
plt.title("one-class SVM模型正确情况")
plt.plot(list(np.arange(0.05,1.05,0.05)),rate_of_accuracy3, 'ro-', color='mediumblue', alpha=0.8, linewidth=1, label='sigmoid')
plt.legend(['sigmoid'],loc="best")
plt.xlabel('nu参数的值')
plt.ylabel('正确率')
plt.grid()
plt.show()
#查看召回率
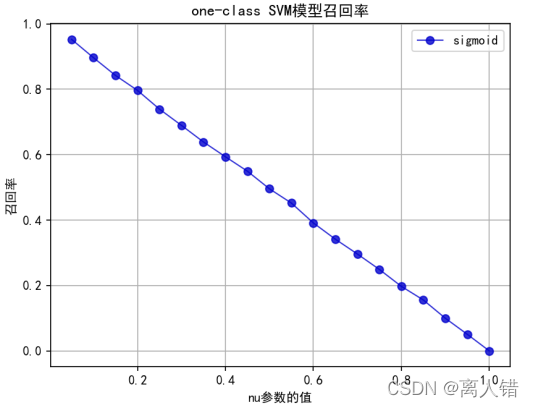
plt.title("one-class SVM模型召回率")
plt.plot(list(np.arange(0.05,1.05,0.05)),rate_of_recall3, 'ro-', color='mediumblue', alpha=0.8, linewidth=1, label='sigmoid')
plt.legend(['sigmoid'],loc="best")
plt.xlabel('nu参数的值')
plt.ylabel('召回率')
plt.grid()
plt.show()
print("最优结果为:")
print(max(rate_of_accuracy3))
print("最优结果为:")
print(max(rate_of_recall3))1.数据导入
2.数据探索性分析
1)数据分列:将22个属性值分为22列
2)查看数据规模、缺失情况
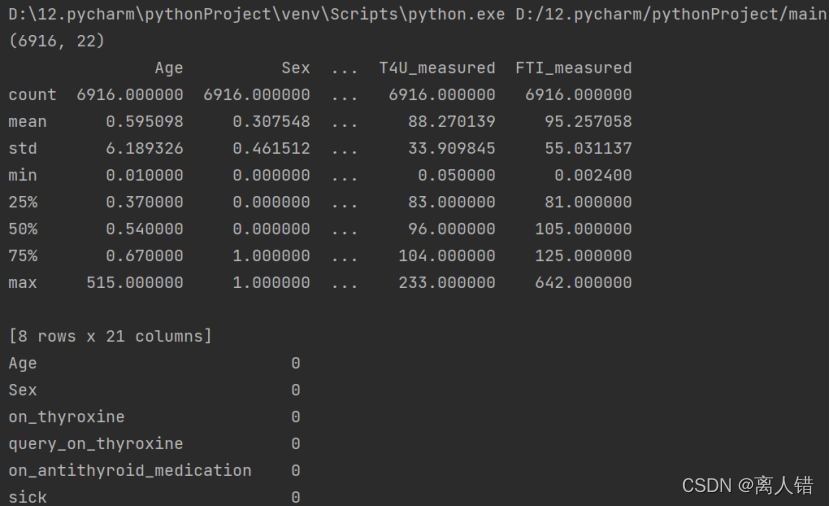
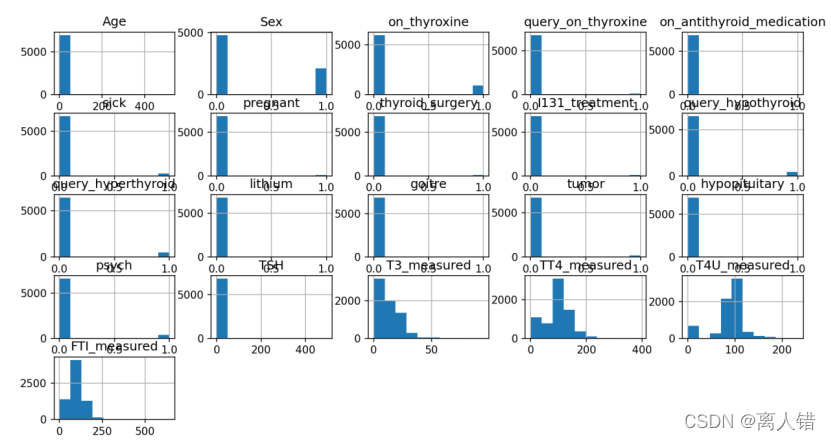
3)直方图查看各特征的分布
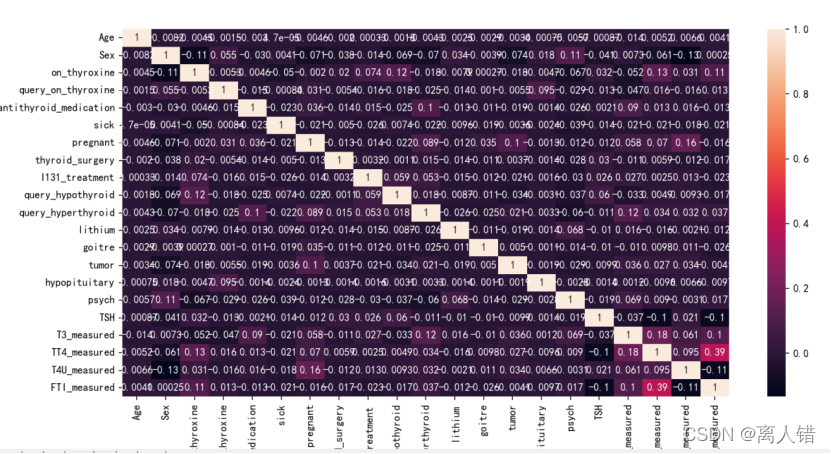
4)皮尔逊相关性分析可视化
3.特征分析
1 )LOF:
思想:
是一种基于距离的异常检测算法。通过比较每个点p和其邻域的密度来判断该点是否为异常点,如果点p的密度越低,越有可能被认为是异常点。至于密度,是通过点和点之间的距离来进行计算的,点和点之间的距离越小,则密度越高;反之则就越低。
步骤:
(1)指定离群异常检测算法的k值大小和离群因子大小判断的阈值大小epsilon;
(2)结合指定k值,计算出每一个原始数据的局部离群因子大小大小;
(3)输出局部离群因子大于1的点,即判读为异常点,小于1的点判断输出为正常点。
结果:
2 )iForest
思想:
孤立森林是一个基于Ensemble的快速离群点检测方法,适用于连续数据的异常检测,通过对样本点的孤立来检测异常值。具体来说,该算法利用孤立树(iTree)的二叉搜索树结构来孤立样本。由于异常值的数量较少且与大部分样本的疏离性,因此,异常值会被更早的孤立出来,也即异常值会距离iTree的根节点更近,而正常值则会距离根节点有更远的距离。此外,相较于LOF,K-means等传统算法,孤立森林算法对高纬数据有较好的鲁棒性。
步骤:
该算法大致可以分为两个阶段,第一个阶段我们需要训练出 t 颗孤立树,组成孤立森林。随后我们将每个样本点带入森林中的每棵孤立树,计算平均高度,之后再计算每个样本点的异常值分数
结果:
3 )one-class SVM
思想:
给定给一个包含正例和反例的样本集合,svm的目的是寻找一个超平面来对样本根据正例和反例进行分割。在one-class classification中,仅仅只有一类的信息是可以用于训练,其他类别的(总称outlier)信息是缺失的,也就是区分两个类别的边界线是通过仅有的一类数据的信息学习得到的。思路是寻找一个超平面将样本中的正例圈出来,预测就是用这个超平面做决策,在圈内的样本就认为是正样本。
步骤:
可用SVDD,期望最小化超球体的体积,从而最小化异常点数据的影响
结果:
四、实验结果及分析
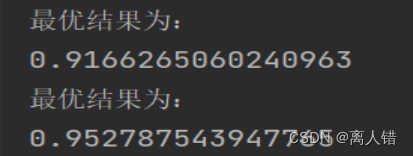
使用LOF、 iForest、one-class SVM分别获得的准确率和召回率的最优结果是:0.9103614457831325、0.9382219989954796;
0.9306024096385542、0.9663485685585133;
0.9166265060240963、0.952787543947765
由此可得,相比iForest的准确率最高,召回率也最高;而LOF的准确率和召回率最低;而one-class SVM模型的召回率与核函数的选取有关,上述代码选择了sigmod核为核函数。因此我们在选择模型的时候要选择适合的模型以及参数,这样才能得到更加准确的效果。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









