






背景:
在训练决策树模型时,会出现欠拟合和过拟合两种情况。而剪枝的目的就是解决过拟合问题。
过拟合:过拟合是指过于精确地匹配了特定数据集,导致获得的模型不能良好地拟合其他数据或预测未来的观察结果的现象。模型如果过拟合,会导致模型的偏差很小,但是方差会很大
欠拟合:是指不能很好的从训练数据中,学习到有用的数据模式,从而针对训练数据和待预测的数据,均不能获得很好的预测效果。如果使用的训练样本过少,较容易获得欠拟合的训练模型。 
一:剪枝(预剪枝&后剪枝)
1:预剪枝:在决策树生成时,先对每个节点进行估计,若当前节点的划分不能带来决策树泛化性能提升,则停止划分并将当前节点标记为叶节点。
1.1 :预剪枝对于何时停止决策树的生长有以下几种方法:(转自)
( 1 )当树到达一定深度的时候,停止树的生长。
( 2 )当到达当前结点的样本数量小于某个阈值的时候,停止树的生长。
( 3 )计算每次分裂对测试集的准确度提升,当小于某个阈值的时候 ,不再继续扩展。
1.2:优缺点:预剪枝具有思想直接、算法简单、效率高等优点,适合解决大规模数据的问题。 但是,对于上述阈值,需要一定的经验来进行判断。另外,预剪枝存在欠拟合风险。这是 因为,虽然当前的划分会导致测试集准确率降低或提升不高,但在之后的划分中,准确率 会有显著提升也不无可能。
2:后剪枝:先从生成一棵完整的决策树,然后自底向上地对非叶节点进行考察,若将该节点对应的子树替换成叶节点能带来决策树泛化能力的提升,则将该子树替换成叶节点。
2.1:具体操作:
1.如果存在任一子集是一棵树,则在该子集递归剪枝过程
2.计算不合并的误差
3.如果合并会降低误差的话,就将叶节点合并在回归树一般用总方差计算误差(即用叶子节 点的值减去所有叶子节点的均值)。
2.2:优缺点:
相比于预剪枝,后剪枝的泛化能力更强,但是计算开销会更大。
二:以下为例:
2.1前提(ID3)
ID3算法
我们基于纯度来构建决策树
经典的 “不纯度”的指标有三种,分别是信息增益(ID3 算法)、信息增益率(C4.5 算法)以及基尼指数(Cart 算法)
ID3 算法计算的是信息增益
信息增益指的就是划分可以带来纯度的提高,信息熵的下降。
它的计算公式,是父亲节点的信息熵减去所有子节点的信息熵。
在计算的过程中,我们会计算每个子节点的归一化信息熵,即按照每个子节点在父节点中出现的概率,来计算这些子节点的信息熵。所以信息增益的公式可以表示为:
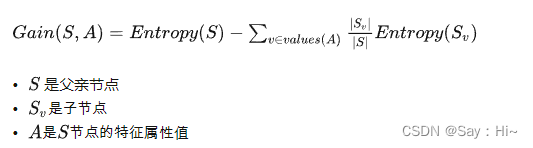
 ID3信息增益后
ID3信息增益后
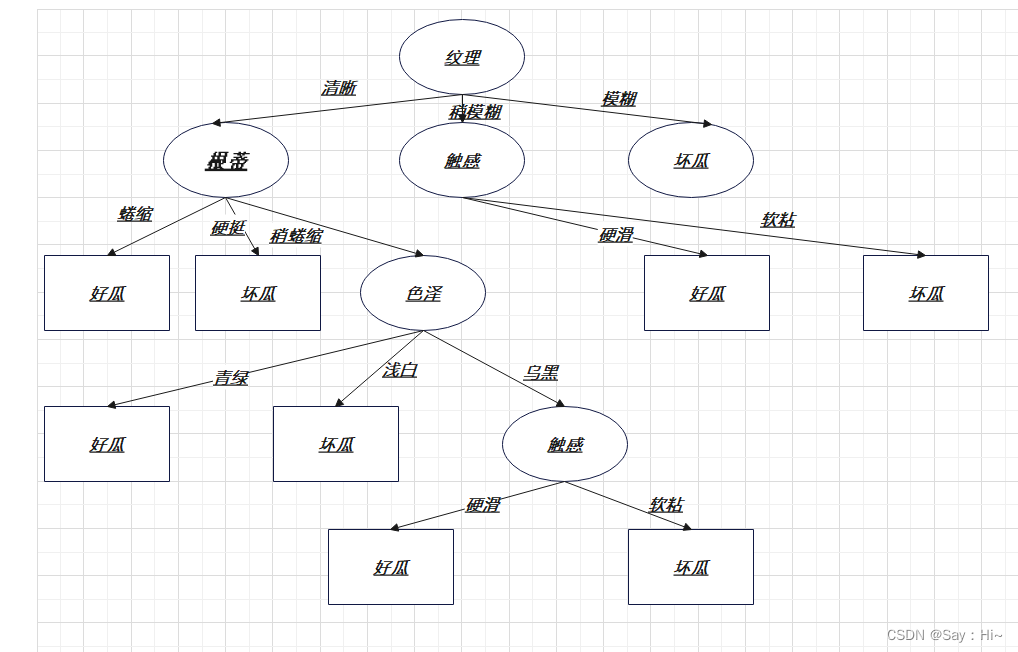
限定深度为2后:
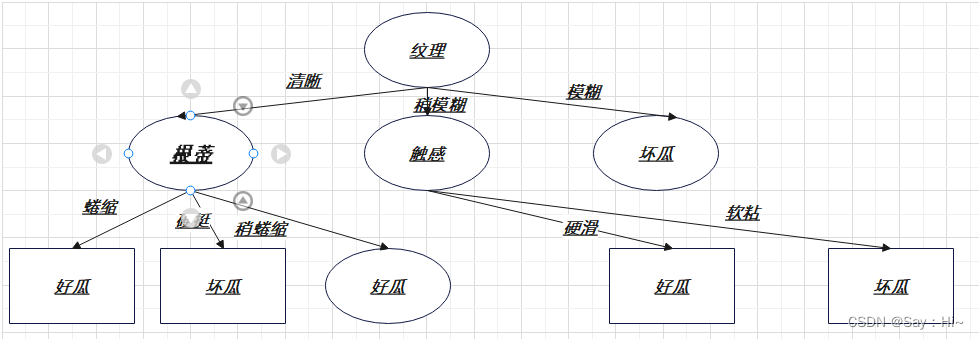
在ID3算法的话,阈值出现在信息增益的比较环节,阈值不同,生成的树也会不同,
设阈值为0.4 ,根据特征计算出来的信息增益都是小于阈值的,也就是说特征并不会个分类带来确定性,那么可以根据数据集中好瓜和坏瓜的数量来确定类标记。
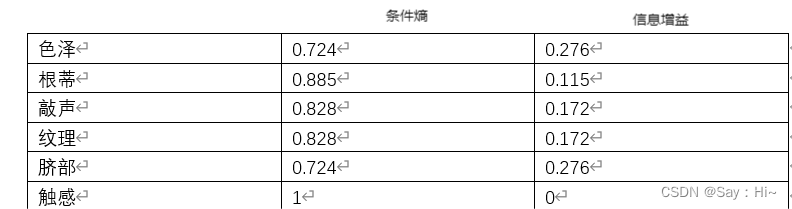
信息增益:
色泽= 0.019 根蒂= 0.143 敲声=0.140 纹理=0.381 脐部= 0.289 触感=0.006
2.1设置指标:测试集上的误差率:测试集中错误分类的实例占比:测试集上的准确率:测试集中正确分类的实例占比。误差率越高,代表泛化能力越弱,误差率越低,代表泛化能力越强
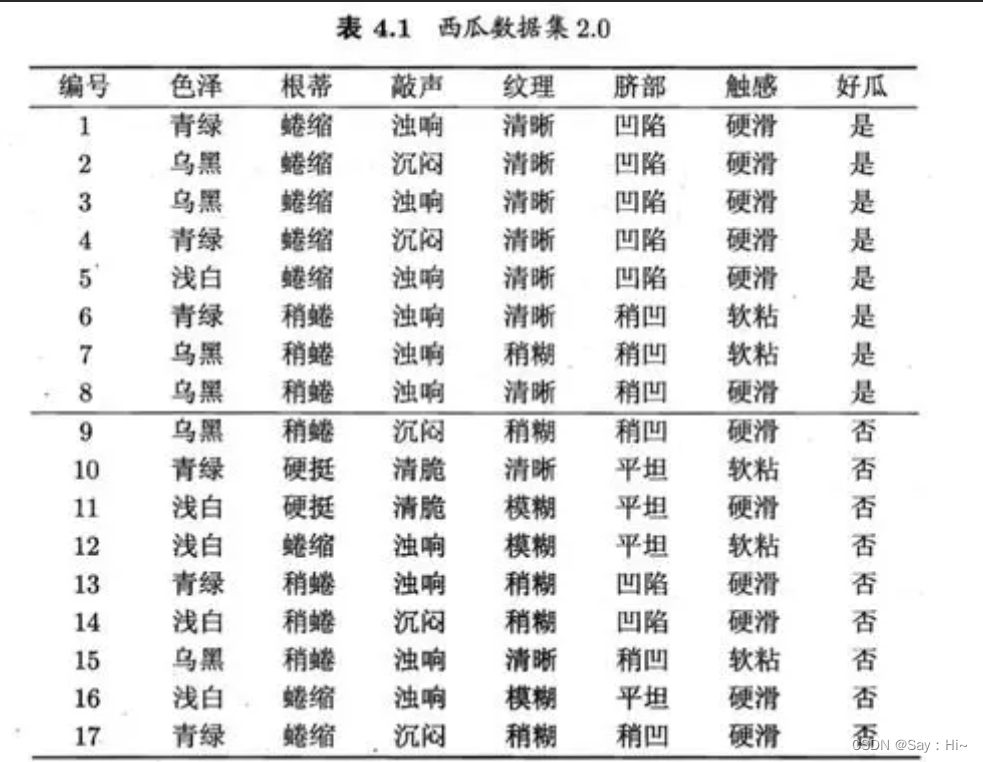
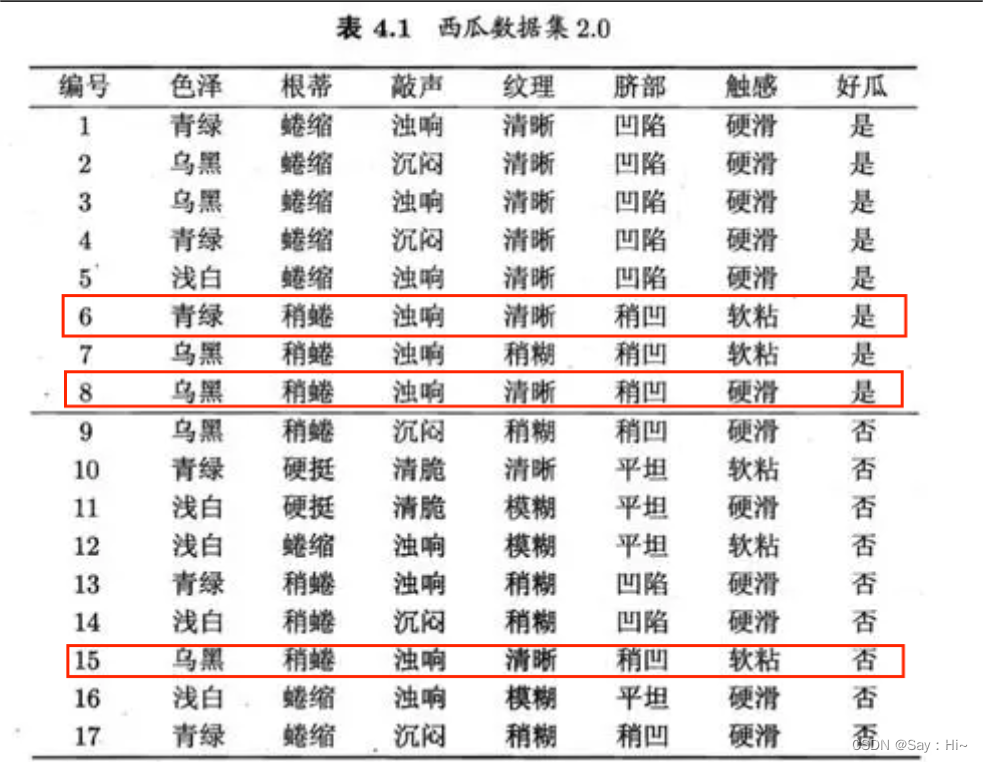
2.2划分训练集(1、2、3、6、7、10、14、15、16、17)和测试集(4、5、8、9、11、12、13)计算误差率:
由此可见预剪枝的特点是从根节点开始,一边生成决策树,一边根据深度、阈值、或者指标进行剪枝。
三:相关代码
#训练数据 def createTrainData(): lines_set = open('../data/ID3/Dataset.txt').readlines() labelLine = lines_set[2]; labels = labelLine.strip().split() lines_set = lines_set[4:11] dataSet = []; for line in lines_set: data = line.split(); dataSet.append(data); return dataSet, labels#测试数据 def createTestData(): lines_set = open('../data/ID3/Dataset.txt').readlines() lines_set = lines_set[15:22] dataSet = []; for line in lines_set: data = line.strip().split(); dataSet.append(data); return dataSetdef calcShannonEnt(dataSet): numEntries = len(dataSet) labelCounts = {} for featVec in dataSet: currentLabel = featVec[-1] if currentLabel not in labelCounts.keys(): labelCounts[currentLabel] = 0; labelCounts[currentLabel] += 1; shannonEnt = 0.0 for key in labelCounts: #求出每种类型的熵 prob = float(labelCounts[key])/numEntries #每种类型个数占所有的比值 shannonEnt -= prob * log(prob, 2) return shannonEnt; #返回熵#按照给定的特征划分数据集 def splitDataSet(dataSet, axis, value): retDataSet = [] for featVec in dataSet: #按dataSet矩阵中的第axis列的值等于value的分数据集 if featVec[axis] == value: #值等于value的,每一行为新的列表(去除第axis个数据) reducedFeatVec = featVec[:axis] reducedFeatVec.extend(featVec[axis+1:]) retDataSet.append(reducedFeatVec) return retDataSet #返回分类后的新矩阵#数据集划分 def chooseBestFeatureToSplit(dataSet): numFeatures = len(dataSet[0])-1 baseEntropy = calcShannonEnt(dataSet) bestInfoGain = 0.0; bestFeature = -1 for i in range(numFeatures): #求所有属性的信息增益 featList = [example[i] for example in dataSet] uniqueVals = set(featList) #第i列属性的取值(不同值)数集合 newEntropy = 0.0 for value in uniqueVals: #求第i列属性每个不同值的熵*他们的概率 subDataSet = splitDataSet(dataSet, i , value) prob = len(subDataSet)/float(len(dataSet)) #求出该值在i列属性中的概率 newEntropy += prob * calcShannonEnt(subDataSet) #求i列属性各值对于的熵求和 infoGain = baseEntropy - newEntropy #求出第i列属性的信息增益 if(infoGain > bestInfoGain): bestInfoGain = infoGain bestFeature = i return bestFeature
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









