







目录
2. HDFS实验,包括Shell命令操作和Java接口访问
0. 前置准备
0.1 安装虚拟机
(若已安装则可跳过)
· 接下来设置静态IP地址。打开终端,先通过ifconfig命令查询IP地址,在ens33处,并记住。
然后在使用vim /etc/sysconfig/network-scripts/ifcfg-ens33
vim /etc/sysconfig/network-scripts/ifcfg-ens33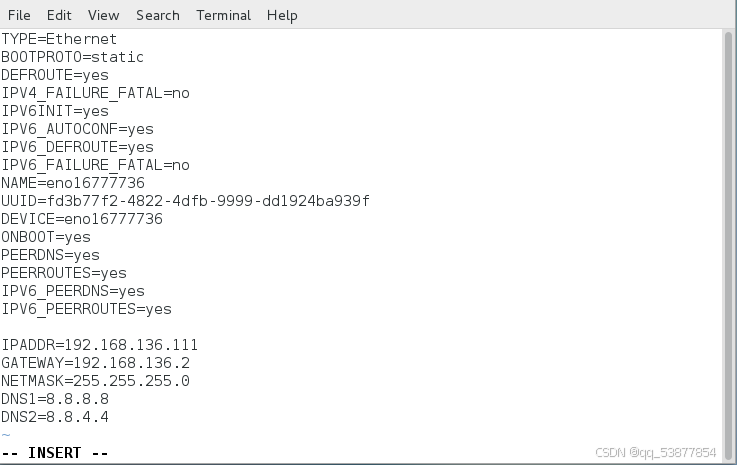
0.2 Linux统一设置
步骤01 配置主机名称。
将主机名取为server+IP最后一部分作为主机名称,下面例子取主机名为server201,是因为本主机的IP地址设置为192.168.56.201。若是xxx.xxx.xxx.22,则改为server22
hostnamectl set-hostname server201步骤02 修改hosts文件。
192.168.56.201 server201步骤03 关闭且禁用防火墙。
systemctl stop firewalld
systemctl disable firewalld步骤04 禁用SELinux,需要重新启动。
vim /etc/selinux/config
SELINUX=disabled步骤05 在/usr/java目录下,安装JDK1.8.x。
首先在Oracle官网下载JDK1.8的Linux版本,如图所示。

可通过winscp上传到Linux中的/usr/java/目录下并解压:
tar -zxvf jdk-8u281-linux-x64.tar.gz -C /usr/java/步骤06 配置JAVA_HOME环境变量。
vim /etc/profile在profile文件最后,添加以下配置:
export JAVA_HOME=/usr/java/jdk1.8.0_281
export PATH=.:$PATH:$JAVA_HOME/bin让环境变量生效:
source /etc/profile检查Java版本:
[root@localhost bin]# java -version
java version "1.8.0_281"
Java(TM) SE Runtime Environment (build 1.8.0_192-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.192-b12, mixed mode)至此,基本的环境就配置完成了。
1. Hadoop安装配置
1.1 环境准备
步骤01 关闭防火墙。
以下命令检查防火墙的状态:
sudo firewall-cmd --state
runningrunning表示防火墙正在运行。以下命令用于停止和禁用防火墙:
systemctl stop firewalld.service
systemctl disable firewalld.service步骤02 配置免密码登录。
配置免密码登录的主要目的,就是在使用Hadoop脚本启动Hadoop的守护进程时,不需要再提示用户输入密码。SSH免密码登录的主要实现机制,就是在本地生成一个公钥,然后将公钥配置到需要被免密码登录的主机上,登录时自己持有私钥与公钥进行匹配,如果匹配成功,则登录成功,否则登录失败。
可以使用ssh-keygen命令生成公钥和私钥文件,并将公钥文件复制到被SSH登录的主机上。以下是ssh-keygen命令,输入后直接按两次回车即可生成公钥和私钥文件:

如上面所说,生成的公钥和私钥文件将被放到~/.ssh/目录下。其中id_rsa文件为私钥文件,rd_rsa.pub为公钥文件。现在我们再使用ssh-copy-id将公钥文件发送到目标主机。由于登录的是本机,所以直接输入本机名即可:
[hadoop@server201 ~]$ ssh-copy-id server201
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/hadoop/.
ssh/id_rsa.pub"
The authenticity of host 'server201 (192.168.56.201)' can't be established.
ECDSA key fingerprint is SHA256:KqSRs/H1WxHrBF/tfM67PeiqqcRZuK4ooAr+xT5Z4OI.
ECDSA key fingerprint is MD5:05:04:dc:d4:ed:ed:68:1c:49:62:7f:1b:19:63:5d:8
e.
Are you sure you want to continue connecting (yes/no)? yes 输入yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filt
er out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are pro
mpted now it is to install the new keys输入密码然后按回车键,将会提示成功信息:
hadoop@server201's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'server201'"
and check to make sure that only the key(s) you wanted were added.此命令执行以后,会在~/.ssh目录下多出一个用于认证的文件,其中保存了某个主机可以登录的公钥信息,这个文件为~/.ssh/authorized_keys。
现在再使用ssh server201命令登录本机,将会发现不用再输入密码,即可以直接登录成功。
[hadoop@server201 ~]$ ssh server201
Last login: Tue Mar 9 20:52:56 2021 from 192.168.56.11.2 Hadoop伪分布式安装
在安装之前,请确定已经安装了JDK1.8,并正确配置了JAVA_HOME、PATH环境变量。
在磁盘根目录下,创建一个app目录,并授权给hadoop用户。然后将会把Hadoop安装到此目录下。先切换到根目录下:
[hadoop@server201 ~]$ cd /添加sudo前缀使用mkdir创建/app目录:
[hadoop@server201 /]$ sudo mkdir /app将此目录的所有权授予给hadoop用户和hadoop组:
[hadoop@server201 /]$ sudo chown hadoop:hadoop /app切换进入/app目录:
[hadoop@server201 /]$ cd /app/使用ll -d命令查看本目录的详细信息,可看到此目录已经属于hadoop用户:
[hadoop@server201 app]$ ll -d
drwxr-xr-x 2 hadoop hadoop 6 3月 9 21:35 .下载hadoop:Index of /apache/hadoop/common/stable (tsinghua.edu.cn)

将Hadoop的压缩包通过winscp上传到/app目录下,并解压到此文件中。可用ll命令查看本目录是否上传成功。
[hadoop@server201 app]$ ll
总用量 386184
-rw-rw-r-- 1 hadoop hadoop 395448622 3月 9 21:40 hadoop-3.4.0.tar.gz使用tar命令-zxvf参数解压此文件:
[hadoop@server201 app]$ tar -zxvf hadoop-3.4.0.tar.gz以下开始配置Hadoop。Hadoop的所有配置文件都在hadoop-3.4.0/etc/hadoop目录下。首先切换到此目录下,然后开始配置:
[hadoop@server201 hadoop-3.4.0]$ cd /app/hadoop-3.4.0/etc/hadoop/步骤01 配置hadoop-env.sh文件。
hadoop-env.sh文件是Hadoop的环境文件,在此文件中需要配置JAVA_HOME变量。在此文件的最后一行输入以下配置,然后按Esc键,再输入:wq保存退出即可:
export JAVA_HOME=/usr/java/jdk1.8.0_281
步骤02 配置core-site.xml文件。core-site.xml文件是HDFS的核心配置文件,用于配置HDFS的协议、端口号和地址。注意:Hadoop 3.0以后HDFS的端口号建议为8020,但如果查看Hadoop的官网示例,依然延续使用的是Hadoop 2之前的端口9000,以下配置我们将使用8020端口,只要保证配置的端口没有被占用即可。配置时,需要注意大小写。使用vim打开core-site.xml文件,进入编辑模式:
[hadoop@server201 hadoop]$ vim core-site.xml
在<configuration></configuration>两个标签之间输入以下内容:(注意修改server201)
<property>
<name>fs.defaultFS</name>
<value>hdfs://server201:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/app/datas/hadoop</value>
</property>配置说明:● fs.defaultFS:用于配置HDFS的主协议,默认为file:///。● hadoop.tmp.dir:用于指定NameNode日志及数据的存储目录,默认为/tmp。
步骤03 配置hdfs-site.xml文件。hdfs-site.xml文件用于配置HDFS的存储信息。使用vim打开hdfs-site.xml文件,并在<configuration></configuration>标签中输入以下内容:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>配置说明:● dfs.replication:用于指定文件块的副本数量。HDFS特别适合于存储大文件,它会将大文件切分成每128MB一块,存储到不同的DataNode节点上,且默认会每一块备份2份,共3份,即此配置的默认值为3,最大为512。由于我们只有一个DataNode,所以这儿将文件副本数量修改为1。● dfs.permissions.enabled:访问时,是否检查安全,默认为true。为了方便访问,暂时把它修改为false。
步骤04 配置mapred-site.xml文件。
通过名称可见,此文件是用于配置MapReduce的配置文件。通过vim打开此文件,并在<configuration>标签中输入以下配置:
$ vim mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>配置说明:● mapreduce.framework.name:用于指定调试方式。这里指定使用YARN作为任务调用方式。
步骤05 配置yarn-site.xml文件。由于上面指定了使用YARN作为任务调度,所以这里需要配置YARN的配置信息,同样,使用vim编辑yarn-site.xml文件,并在<configuration>标签中输入以下内容:
<property>
<name>yarn.resourcemanager.hostname</name>
<value>server201</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>通过hadoop classpath命令获取所有classpath的目录,然后配置到上述文件中。由于没有配置Hadoop的环境变量,所以这里需要输入完整的Hadoop运行目录,命令如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1184
1184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









