









三大范式概念
第一范式
第一范式主要是确保数据表中每个字段的值必须具有原子性,最小数据单元。
第二范式
第二范式要求,在满足第一范式的基础上,还要满足数据表里的每一条数据记录,都是可唯一标识的。而且所有非主键字段,都必须完全依赖主键,不能只依赖主键的一部分。
第三范式
第三范式是在第二范式的基础上,确保数据表中的每一个非主键字段都和主键字段直接相关。
也就是说,要求数据表中的所有非主键字段不能依赖于其他非主键字段(即,不能存在非主属性A 依赖于非主属性 B,非主属性B依赖于主键C的情况,即存在“A一B一C”的决定关系)。
通俗地讲,该规则的意思是所有 非主键属性 之间不能有依赖关系,必须 相互独立。
第一范式图文详解
user表存储 id,username(用户名),password(密码),user_info(用户信息)。这样子设计违反了第一范式,user_info存储了两种信息,还可以再分,可以分为地址(address)和电话号码(phone)两个字段。

修改后符合第一范式,分字段

第二范式图文详解
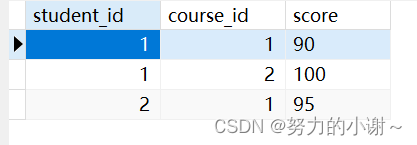
score表存储了student_id(学生id),course_id(课程id),course_name(课程名称),score(课程分数)这里面的联合主键是学生id和课程id。它们才可以确定一个学生的具体的一个课程的分数。score字段是完全依赖于主键的(学生id,课程id),才可以确定具体的分数,但是course_name不是完全依赖于主键的,它根据course_id就可以确定自己的课程名称。违反了第二范式。
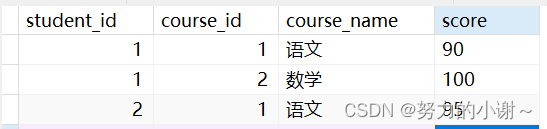
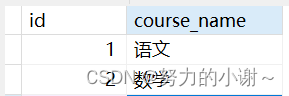
修改后符合第二范式,分成两张表
第三范式图文详解
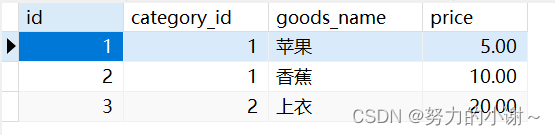
goods表,id是主键,category_id(分类id),category_name(分类名称),goods_name(商品名称),price商品价格。虽然非主键字段(category_id,category_name,goods_name,price)都依赖于主键(id),但是category_name还依赖于category_id(非主键id)不符合第三范式。

修改后分表,符合第三范式。

反范式化
有的时候不能简单按照规范要求设计数据表,因为有的数据看似几余,其实对业务来说十分重要。这个时候,我们就要遵循 业务优先 的原则,首先满足业务需求,再尽量减少冗余。
如果数据库中的数据量比较大,系统的UV和PV访问频次比较高,则完全按照MySOL的三大范式设计数据表,读数据时会产生大量的关联查询,在一定程度上会影响数据库的读性能。如果我们想对查询效率进行优化,反范式优化也是一种优化思路。此时,可以通过在数据表中 增加冗余字段 来提高数据库的读性能。
反范式化举例
下面的两张表设计,商品表和分类表,如果要经常查询商品的分类名称,连接查询就会浪费很多时间。可以在 goods 表中增加一个冗余字段
category_name字段,这样就不用每次都进行连接操作了。
goods(商品表)表:

category(分类表)表:

反范式化表设计
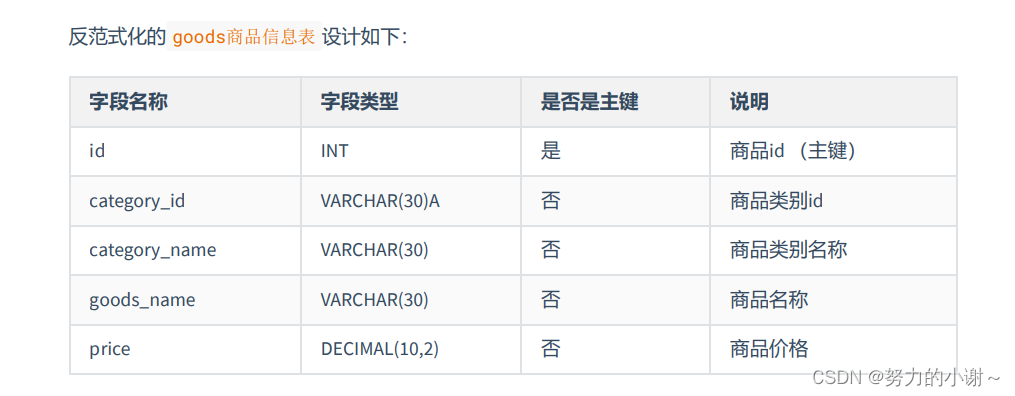
反范式的新问题
1.存储空间变大了
2.一个表中字段做了修改,另一个表中冗余的字段也需要做同步修改,否则数据不一致。
3.若采用存储过程来支持数据的更新、删除等额外操作,如果更新频繁,会非常消耗系统资源。
4.在数据量小的情况下,反范式不能体现性能的优势,可能还会让数据库的设计更加复杂。
反范式的适用场景
当冗余信息有价值或者能大幅度提高查询效率的时候,我们才会采取反范式的优化。
1.增加冗余字段的建议
2. 历史快照、历史数据的需要在现实生活中,我们经常需要一些冗余信息,比如订单中的收货人信息,包括姓名、电话和地址等。每次发生的订单收货信息都属于历史快照 ,需要进行保存,但用户可以随时修改自己的信息,这时保存这
些冗余信息是非常有必要的。
反范式优化也常用在 数据仓库 的设计中,因为数据仓库通常 存储历史数据 ,对增删改的实时性要求不强,对历史数据的分析需求强。这时适当允许数据的冗余度,更方便进行数据分析。















 294
294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









