




 本文讲述了作者在毕业设计中遇到的数据泛化问题,探讨了数据不足、过拟合、模型复杂度过高、数据分布偏移等因素导致的泛化难题,并通过增加训练批次来部分解决了这个问题。
本文讲述了作者在毕业设计中遇到的数据泛化问题,探讨了数据不足、过拟合、模型复杂度过高、数据分布偏移等因素导致的泛化难题,并通过增加训练批次来部分解决了这个问题。
时隔一年多,再次记录最近遇到的问题
最近在弄毕业设计,其中就遇到一个很头疼的问题,训练的时候好好的。


但是最后跑模型的时候发现实际的效果差的多如下
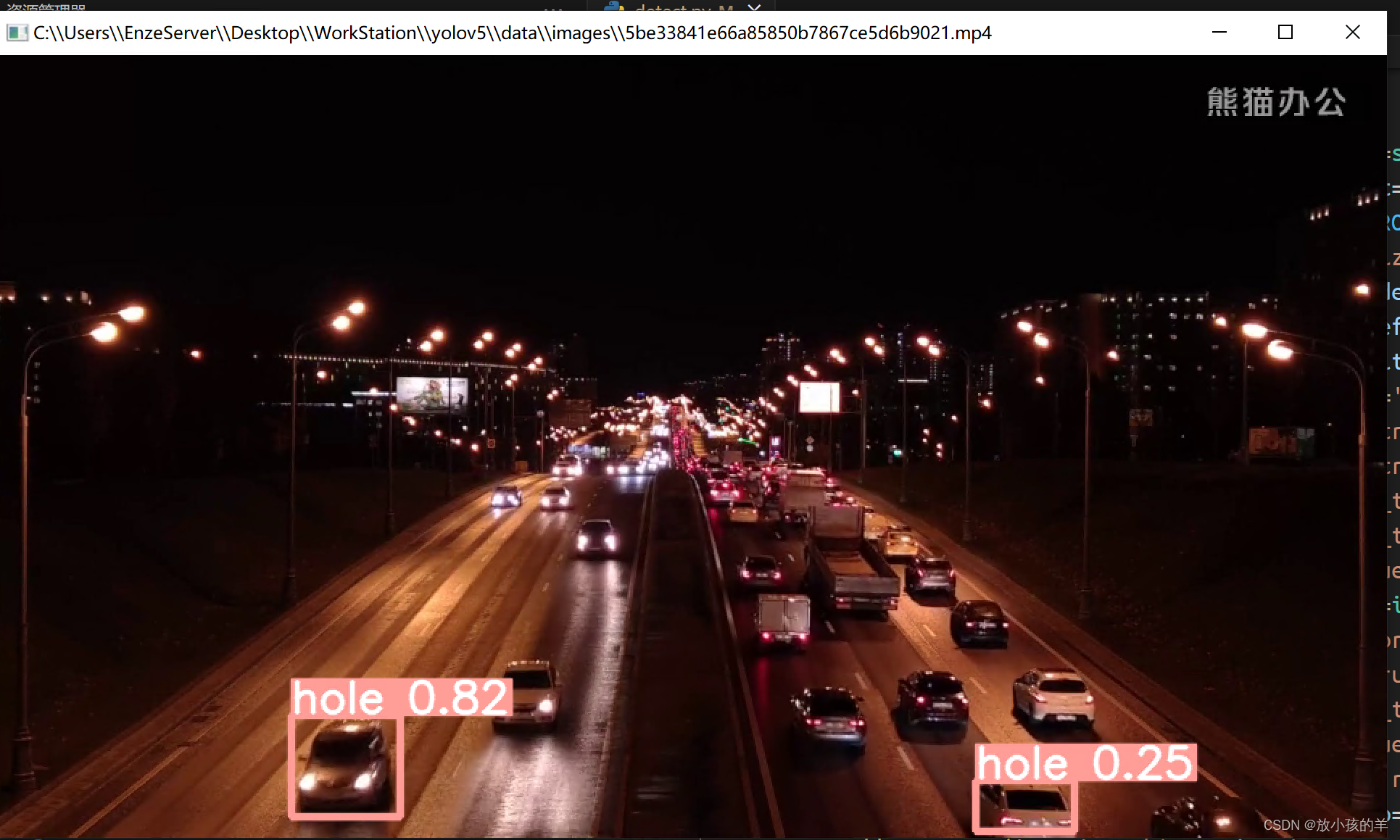
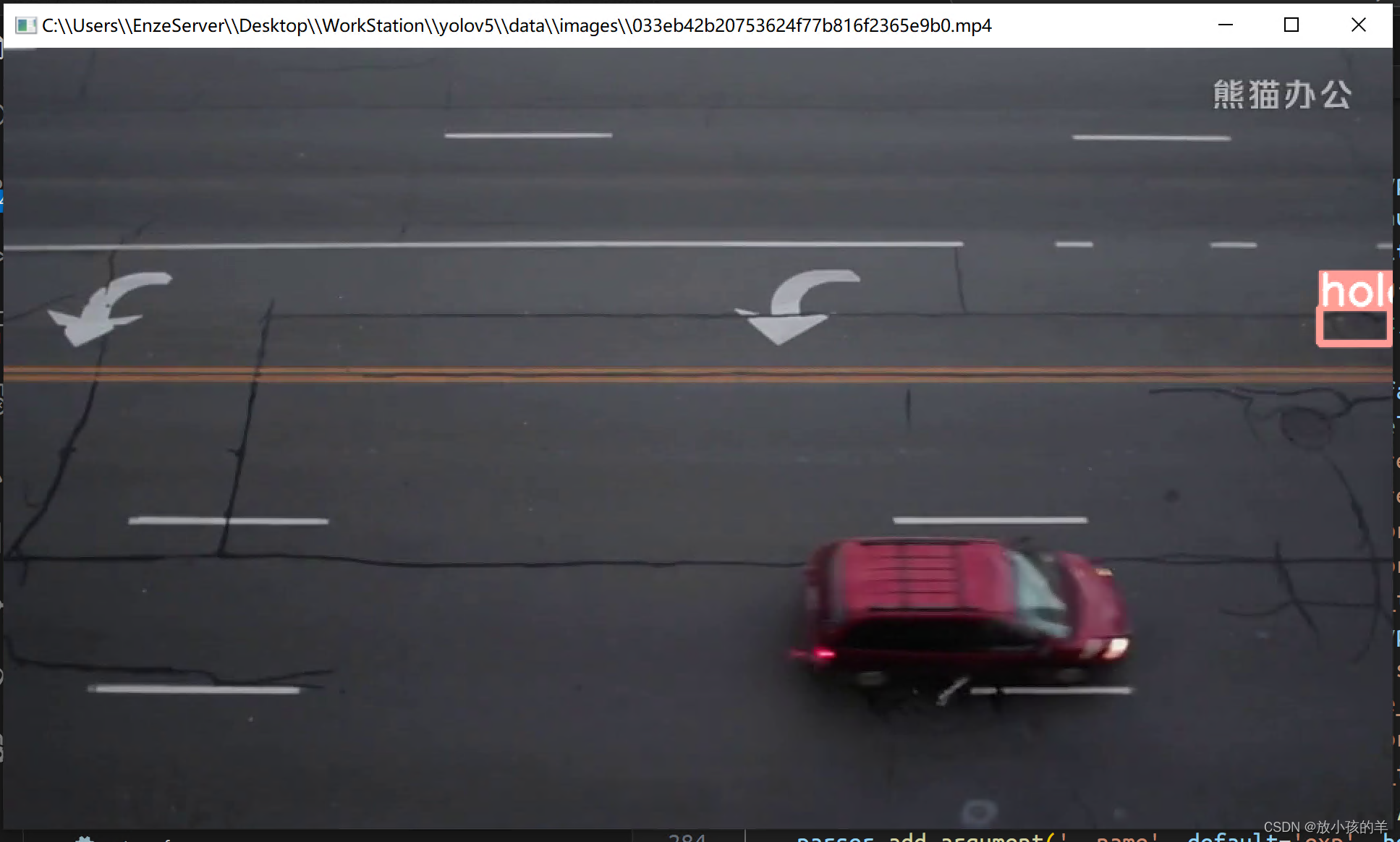
真的要被无语死了
首先跟大家解释一下啥叫数据泛化的问题
泛化问题在机器学习和深度学习中是一个普遍存在的挑战。它指的是模型在训练集上表现良好,但在未见过的测试数据上表现不佳的情况。以下是导致泛化问题的一些常见原因:
理性的分析了一下结果,能被我检索到的如下
1.数据不足或不平衡:当训练数据量不足或者不平衡(各类别样本数量差异过大)时,模型可能无法捕捉到数据的真实分布,导致泛化性能下降。
2.过拟合(Overfitting):模型过度拟合了训练数据的噪声或特定样本的特征,而忽略了真实数据的整体分布。这会导致模型在训练集上表现很好,但在测试集上泛化能力较差。
3.模型复杂度过高:当模型的复杂度过高时,例如神经网络的层数过多或者参数量过大,容易导致过拟合,使得模型在未见过的数据上泛化能力较差。
4.数据分布偏移(Distribution Shift):当训练集和测试集的数据分布不一致时,模型在训练集上学到的特征可能无法有效地推广到测试集上,导致泛化性能下降。
5.特征选择不当:选择的特征可能不够代表真实数据的关键信息,或者包含了与任务无关的噪声,这会影响模型的泛化能力。
6.训练过程中的随机性:某些算法(如随机初始化权重、随机梯度下降等)在训练过程中引入了随机性,这可能导致模型在不同训练过程中学到不同的特征,影响泛化性能。
这是官方的解释,于是我采取最简单粗暴的方式
多训练,增加训练批次,强制解决!由最开始的150epoch增加到450epoch
最后的结果,有用的,强制解决部分数据泛化的问题

















 2008
2008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









