






目录
1、Transform简介
Transformer中抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成。更准确地讲,Transformer由且仅由self-Attenion和Feed Forward Neural Network组成。一个基于Transformer的可训练的神经网络可以通过堆叠Transformer的形式进行搭建,作者的实验是通过搭建编码器和解码器各6层,总共12层的Encoder-Decoder,并在机器翻译中取得了BLEU值得新高。
2、Transform结构
Transformer的实验基于机器翻译

Transform本质是Encoder-Decoder的结构

论文中所设置的,编码器由6个编码block组成,同样解码器是6个解码block组成。与所有的生成模型相同的是,编码器的输出会作为解码器的输入,如图3所示:

我们继续分析每个encoder的详细结构:在Transformer的encoder中,数据首先会经过一个叫做‘self-attention’的模块得到一个加权之后的特征向量 Z ,这个Z 便是论文公式1中的 Attention(Q,K,V):

得到的Z,会被送到encoder的下一个模块,Feed Forward Neural Network,这个全连接有两层,第一层的激活函数是ReLU,第二层是一个线性激活函数,可以表示为:
![]()

Decoder的结构如图5所示,它和encoder的不同之处在于Decoder多了一个Encoder-Decoder Attention,两个Attention分别用于计算输入和输出的权值:

- Self-Attention:当前翻译和已翻译的前文之间的关系;
- Encoder-Decnoder Attention:当前翻译和编码的特征向量之间的关系。
3、Transform encoder过程
首先将词通过word2vec表示为向量,第一层encoder的输入直接为词x的向量表示,而在其他层中,输入则是上一个block的输出。如下图所示:

4、Attention
Attention模型并不只是盲目地将输出的第一个单词与输入的第一个词对齐。Attention机制的本质来自于人类视觉注意力机制。人们在看东西的时候一般不会从到头看到尾全部都看,往往只会根据需求观察注意特定的一部分,就是一种权重参数的分配机制,目标是协助模型捕捉重要信息。即给定一组<key,value>,以及一个目标(查询)向量query,attention机制就是通过计算query与每一组key的相似性,得到每个key的权重系数,再通过对value加权求和,得到最终attention数值。

5、Self-Attention
5.1、self-Attention细节描述
Self-Attention是Transformer最核心的内容,其核心内容是为输入向量的每个单词学习一个权重
在self-attention中,每个单词有3个不同的向量,它们分别是Query向量( Q ),Key向量( K)和Value向量( V ),长度均是64。它们是通过3个不同的权值矩阵由嵌入向量 X 乘以三个不同的权值矩阵 WQ,WK ,WV 得到,其中三个矩阵的尺寸也是相同的。均是 512*64;Q,K,V这些向量的概念是很抽象,但是它确实有助于计算注意力。相较于RNNs,transformer具有更好的并行性。

- 如上文,将输入单词转化成嵌入向量;
- 根据嵌入向量得到 q ,k,v 三个向量;
- 为每个向量计算一个score: score=q*k ;
- 为了梯度的稳定,Transformer使用了score归一化,即除以 sqrt(dk)=8 (论文中使用key向量的维度是64维,其平方根=8,这样可以使得训练过程中具有更稳定的梯度。);
- 对score施以softmax激活函数,使得最后的列表和为1;这个softmax的分数决定了当前单词在每个句子中每个单词位置的表示程度。很明显,当前单词对应句子中此单词所在位置的softmax的分数最高,但是,有时候attention机制也能关注到此单词外的其他单词,这很有用。
- softmax点乘Value值 v ,得到加权的每个输入向量的评分 v ;相当于保存对当前词的关注度不变的情况下,降低对不相关词的关注。
- 相加之后得到最终的输出结果 ;这会在此位置产生self-attention层的输出(对于第一个单词)。
5.2、矩阵运算过程描述


6、Multi-Head Attention
Multi-Head Attention相当于 h 个不同的self-attention的集成(ensemble),在这里我们以 h=8 举例说明。Multi-Head Attention的输出分成3步:
1、将数据 X 分别输入到5章节所示的8个self-attention中,得到8个加权后的特征矩阵 ![]()
2、将8个 ![]() 按列拼成一个大的特征矩阵;前馈神经网络没法输入8个矩阵,所以需要把8个矩阵降为1个,在这里通过把8个矩阵连在一起。
按列拼成一个大的特征矩阵;前馈神经网络没法输入8个矩阵,所以需要把8个矩阵降为1个,在这里通过把8个矩阵连在一起。
3、特征矩阵经过一层全连接后得到输出 Z 。
具体过程如下:

7、Transform的encoder整体结构

在self-attention需要强调的最后一点是其采用了残差网络 中的short-cut结构,目的当然是解决深度学习中的退化问题。FFN 相当于将每个位置的Attention结果映射到一个更大维度的特征空间,然后使用ReLU引入非线性进行筛选,最后恢复回原始维度。
8、自注意机制的复杂度
对于使用自注意力机制的原因,论文中提到主要从三个方面考虑(每一层的复杂度,是否可并行,长距离依赖学习),并给出了和RNN,CNN计算复杂度的比较。可以看到,如果输入序列n小于表示维度d的话,每一层的时间复杂度self-attention是比较有优势的。当n比较大时,作者也给出了一种解决方案self-attention(restricted)即每个词不是和所有词计算attention,而是只与限制的r个词去计算attention。在并行方面,多头attention和CNN一样不依赖于前一时刻的计算,可以很好的并行,优于RNN。在长距离依赖上,由于self-attention是每个词和所有词都要计算attention,所以不管他们中间有多长距离,最大的路径长度也都只是1。可以捕获长距离依赖关系。

9、Positional Encoding
transformer给encoder层和decoder层的输入添加了一个额外的向量Positional Encoding,维度和embedding的维度一样,这个向量采用了一种很独特的方法来让模型学习到这个值,这个向量能决定当前词的位置,或者说在一个句子中不同的词之间的距离。计算方法如下
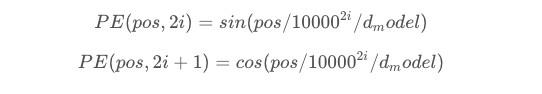
其中pos是指当前词在句子中的位置,i是指向量中每个值的index,可以看出,在偶数位置,使用正弦编码,在奇数位置,使用余弦编码。最后把这个Positional Encoding与embedding的值相加,作为输入送到下一层。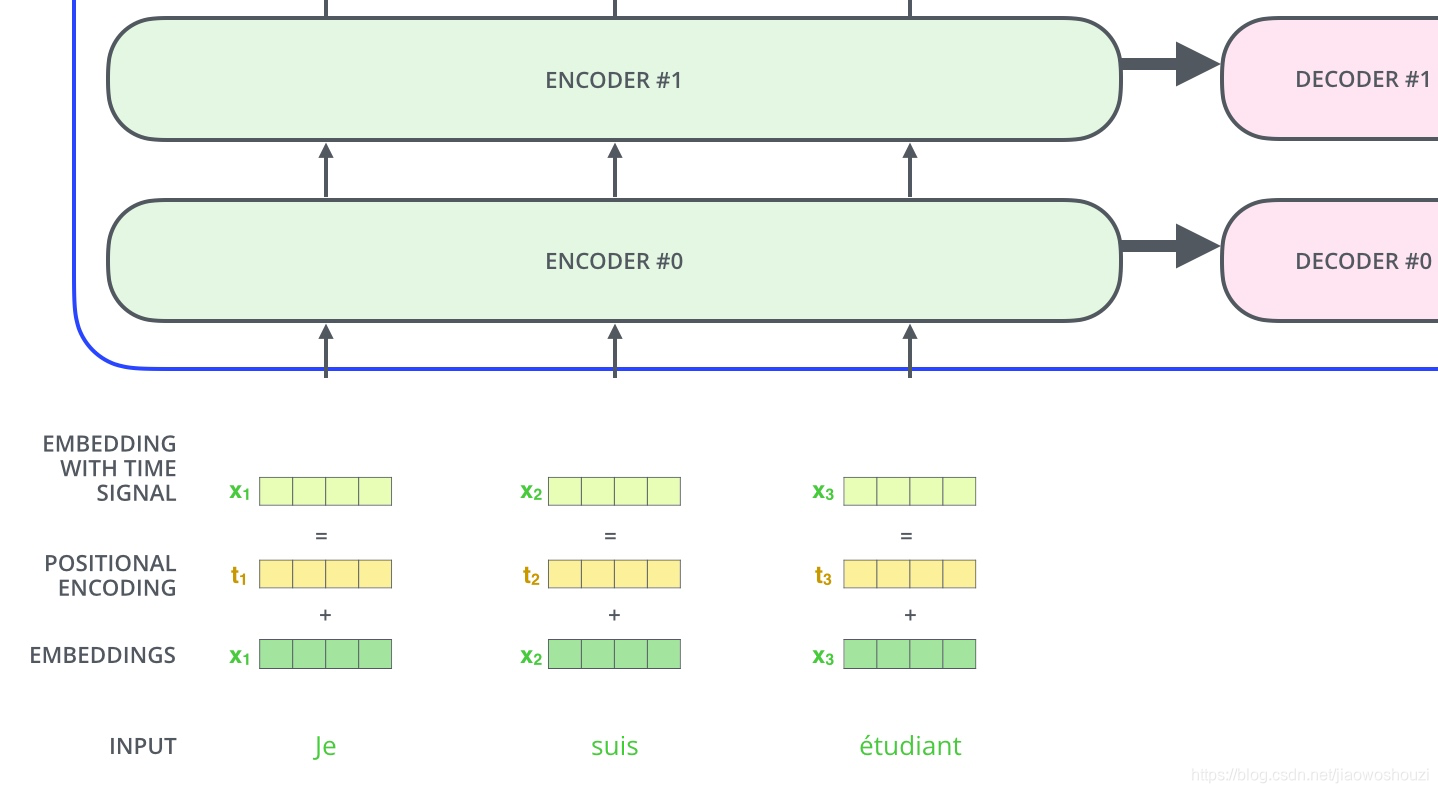
eg:嵌入维度为4,考虑位置编码的情况如下:
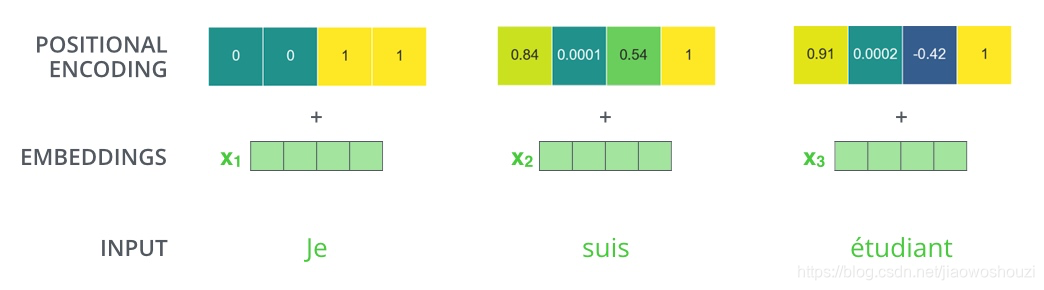
10、残差模块和Layer normalization
在transformer中,每一个子层(self-attetion,ffnn)之后都会接一个残差模块,并且有一个Layer normalization;
eg: 2个Encoder和2个Decoder的Transformer:

10.1、残差引入目的
随着网络深度的增加,训练变得愈加困难,这主要是因为在基于随机梯度下降的网络训练过程中,误差信号的多层反向传播非常容易引发“梯度弥散”(梯度过小会使回传的训练误差信号极其微弱)或者“梯度爆炸”(梯度过大导致模型出现NaN)的现象。目前一些特殊的权重初始化策略和批规范化(BN)等方法使这个问题得到了极大改善——网络可以正常训练了!! 但是实际情形不容乐观。当模型收敛时,另外的问题又来了:随着网络深度的增加,训练误差没有降低反而升高。 这一现象与直觉极其不符,浅层网络可以被训练优化到一个很好的解,那么对应的更深层的网络至少也可以,而不是更差。这一现象在一段时间内困扰着更深层卷积神经网络的设计、训练和应用。
残差模块:y=F(x,w)+x
高速公路网络的“变换门”和“携带门”都为恒等映射时(即令 T=1,C=1T=1,C=1 ),就得到了残差网络
10.2、Normalization引入目的
Normalization有很多种,但是它们都有一个共同的目的,那就是把输入转化成均值为0方差为1的数据。我们在把数据送入激活函数之前进行normalization(归一化),因为我们不希望输入数据落在激活函数的饱和区。 Batch Normalization。BN的主要思想就是:在每一层的每一批数据上进行归一化。我们可能会对输入数据进行归一化,但是经过该网络层的作用后,我们的数据已经不再是归一化的了。随着这种情况的发展,数据的偏差越来越大,我的反向传播需要考虑到这些大的偏差,这就迫使我们只能使用较小的学习率来防止梯度消失或者梯度爆炸。

Layer normalization它也是归一化数据的一种方式,不过 LN 是在每一个样本上计算均值和方差,而每一个特征维度上进行归一化

11、Decoder层
transform的整体结构如下图所示;在解码器中,Transformer block比编码器中多了个encoder-decoder attention。在encoder-decoder attention中, Q 来自于解码器的上一个输出,K 和 V 则来自于与编码器的输出。
由于在机器翻译中,解码过程是一个顺序操作的过程,也就是当解码第 K 个特征向量时,我们只能看到第 K-1 及其之前的解码结果,论文中把这种情况下的multi-head attention叫做masked multi-head attention。transfrom的encoder和decoder整体架构如下:

11.1、Mask
mask 表示掩码,它对某些值进行掩盖,使其在参数更新时不产生效果。Transformer 模型里面涉及两种 mask,分别是 padding mask 和 sequence mask。
11.2、Padding Mask
padding mask:因为每个批次输入序列长度是不一样,需要对输入序列进行对齐。给较短的序列后面填充 0,对于输入太长的序列,截取左边的内容,把多余的直接舍弃。这些填充的位置,没什么意义,所以我们的attention机制不应该把注意力放在这些位置上,所以我们需要进行一些处理。
具体的做法是,把这些位置的值加上一个非常大的负数(负无穷),这样的话,经过 softmax,这些位置的概率就会接近0!
而我们的 padding mask 实际上是一个张量,每个值都是一个Boolean,值为 false 的地方就是我们要进行处理的地方。
11.3、Sequence mask
sequence mask 是为了使得 decoder 不能看见未来的信息。也就是对于一个序列,在 time_step 为 t 的时刻,我们的解码输出应该只能依赖于 t 时刻之前的输出,而不能依赖 t 之后的输出。因此我们需要想一个办法,把 t 之后的信息给隐藏起来。
具体做法:产生一个上三角矩阵,上三角的值全为0。把这个矩阵作用在每一个序列上。
- 对于 decoder 的 self-attention,同时需要padding mask 和 sequence mask 作为 attn_mask,具体实现就是两个mask相加作为attn_mask。
- 其他情况,attn_mask 一律等于 padding mask。
eg:

编码器处理输入序列,最终输出为一组注意向量k和v。每个解码器将在其“encoder-decoder attention”层中使用k,v注意向量,这有助于解码器将注意力集中在输入序列中的适当位置:
11.4、解码过程
对于Decoder,和Encoder一样,初始输入为词嵌入+词位置编码;不同在于,self attention只关注输出序列中的较早的位置。在self-attention 计算中的softmax步骤之前屏蔽了特征位置(设置为 -inf)来完成的。encoder-decoder attention过程和self-attention一致,只是其k,v来自于编码器的输出。

动图可以参考:https://blog.csdn.net/jiaowoshouzi/article/details/89073944
https://blog.csdn.net/qq_41664845/article/details/84969266
12、输出层
Decoder的输出是浮点数的向量列表。把得到的向量映射为需要的词,需要线性层和softmax层获取预测为词的概率。
线性层是一个简单的全连接神经网络,它是由Decoder堆栈产生的向量投影到一个更大,更大的向量中,称为对数向量
假设实验中我们的模型从训练数据集上总共学习到1万个英语单词(“Output Vocabulary”)。这对应的Logits矢量也有1万个长度-每一段表示了一个唯一单词的得分。在线性层之后是一个softmax层,softmax将这些分数转换为概率。选取概率最高的索引,然后通过这个索引找到对应的单词作为输出。

13、 优缺点总结
优点:
(1)虽然Transformer最终也没有逃脱传统学习的套路,Transformer也只是一个全连接(或者是一维卷积)加Attention的结合体。但是其设计已经足够有创新,因为其抛弃了在NLP中最根本的RNN或者CNN并且取得了非常不错的效果,算法的设计非常精彩,值得每个深度学习的相关人员仔细研究和品位。
(2)Transformer的设计最大的带来性能提升的关键是将任意两个单词的距离是1,这对解决NLP中棘手的长期依赖问题是非常有效的。
(3)Transformer不仅仅可以应用在NLP的机器翻译领域,甚至可以不局限于NLP领域,是非常有科研潜力的一个方向。
(4)算法的并行性非常好,符合目前的硬件(主要指GPU)环境。
缺点:
(1)粗暴的抛弃RNN和CNN虽然非常炫技,但是它也使模型丧失了捕捉局部特征的能力,RNN + CNN + Transformer的结合可能会带来更好的效果。
(2)Transformer失去的位置信息其实在NLP中非常重要,而论文中在特征向量中加入Position Embedding也只是一个权宜之计,并没有改变Transformer结构上的固有缺陷。
参考文章
https://blog.csdn.net/weixin_44695969/article/details/102997574 (残差网络)
https://blog.csdn.net/jiaowoshouzi/article/details/89073944 (一文读懂bert,介绍了传统的神经网络模型,及transform详解)
https://blog.csdn.net/qq_41664845/article/details/84969266 (transform很详细的介绍)
https://zhuanlan.zhihu.com/p/139595546 (各种mask策略)
http://jalammar.github.io/illustrated-transformer/ (英文transfrom详解)
https://zhuanlan.zhihu.com/p/48508221 (transform针对改进点解析的文章)
https://zhuanlan.zhihu.com/p/60821628 (transform的一些细节优化点详解)
















 1409
1409











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









