






一、下载scala
1.下载
2.root命令下输入(或者+sudo)
tar -zxvf scala-2.10.7.tgz -C /usr/hadoop/3.配置
vim /etc/profile
输入:
export SCALA_HOME=/usr/hadoop/scala-2.10.7
export PATH=$PATH:$SCALA_HOME/bin![]()
保存,退出
4.source /etc/profile (root用户或+sudo)

成功截图
二、安装spark
1.下载解压
下载路径:Index of /dist/spark/spark-2.4.3
(root用户)
tar -zxvf spark-2.4.3-bin-hadoop2.7.tgz -C /usr/hadoop/spark下载后解压,到/usr/hadoop/spark目录下
2.配置环境
1)vim /etc/profile
export SPARK_HOME=/usr/hadoop/spark/spark-2.4.3-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/sbin2) spark-env.sh配置
如果没有spark-env.sh
找到spark-env.sh.template
cd /usr/hadoop/spark/spark-2.4.3-bin-hadoop2.7/conf
cp spark-env.sh.template spark-env.sh
vim spark-env.sh添加代码:
export JAVA_HOME=/usr/hadoop/jdk1.8.0_201
export HADOOP_CONF_DIR=/usr/hadoop/hadoop-2.8.5/etc/hadoop
export SPARK_MASTER_IP=master
export SPARK_MASTER_HOST=master
export SPARK_LOCAL_IP=master
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_MEMORY=1g
export SPARK_WORKER_CORES=2
export SPARK_MASTER_WEBUI_PORT=8088
注意:export SPARK_LOCAL_IP=master 在子节点中需要将master改为子节点的名称
3)slaves配置
slave1
slave2
4) 复制到其他节点
在master节点上安装配置完成Spark后,将整个spark目录拷贝到其他节点,并在各个节点上更新/etc/profile文件中的环境变量
5) 测试Spark
在master节点启动Hadoop集群
[root@master /hadoop-2.8.5] # sbin/start-all.sh在master节点启动spark
[root@master spark-2.4.3-bin-hadoop2.7]# sbin/start-all.sh master:
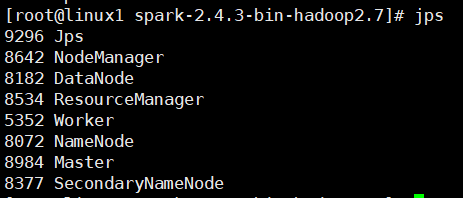
slave:
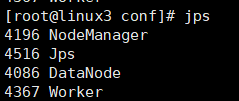
















 1263
1263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









