







目录
概念:
好处:
1:可以动态保存任意多个对象,使用比较方便。
2:提供一系列方便的操作对象的方法:add,remove,set,get。
3:使用集合添加,删除新的元素更简洁快捷。
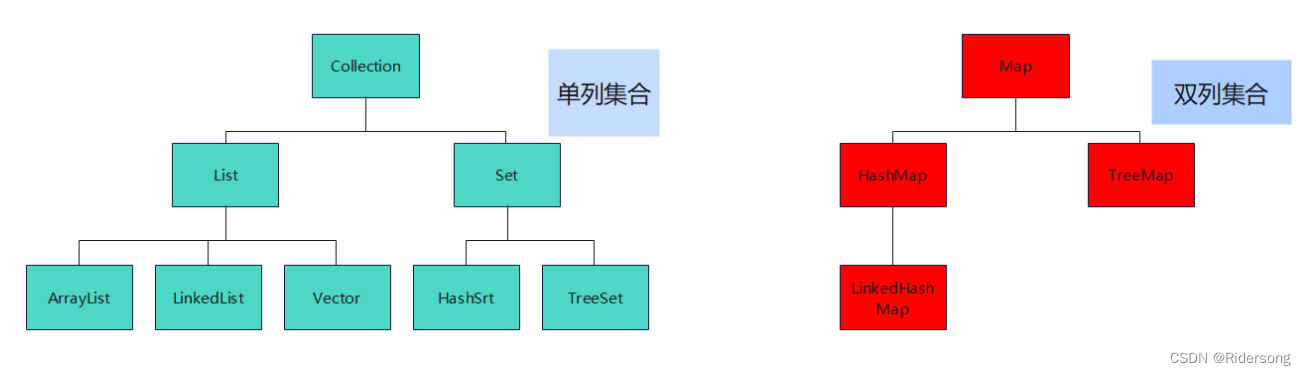
集合框架图:
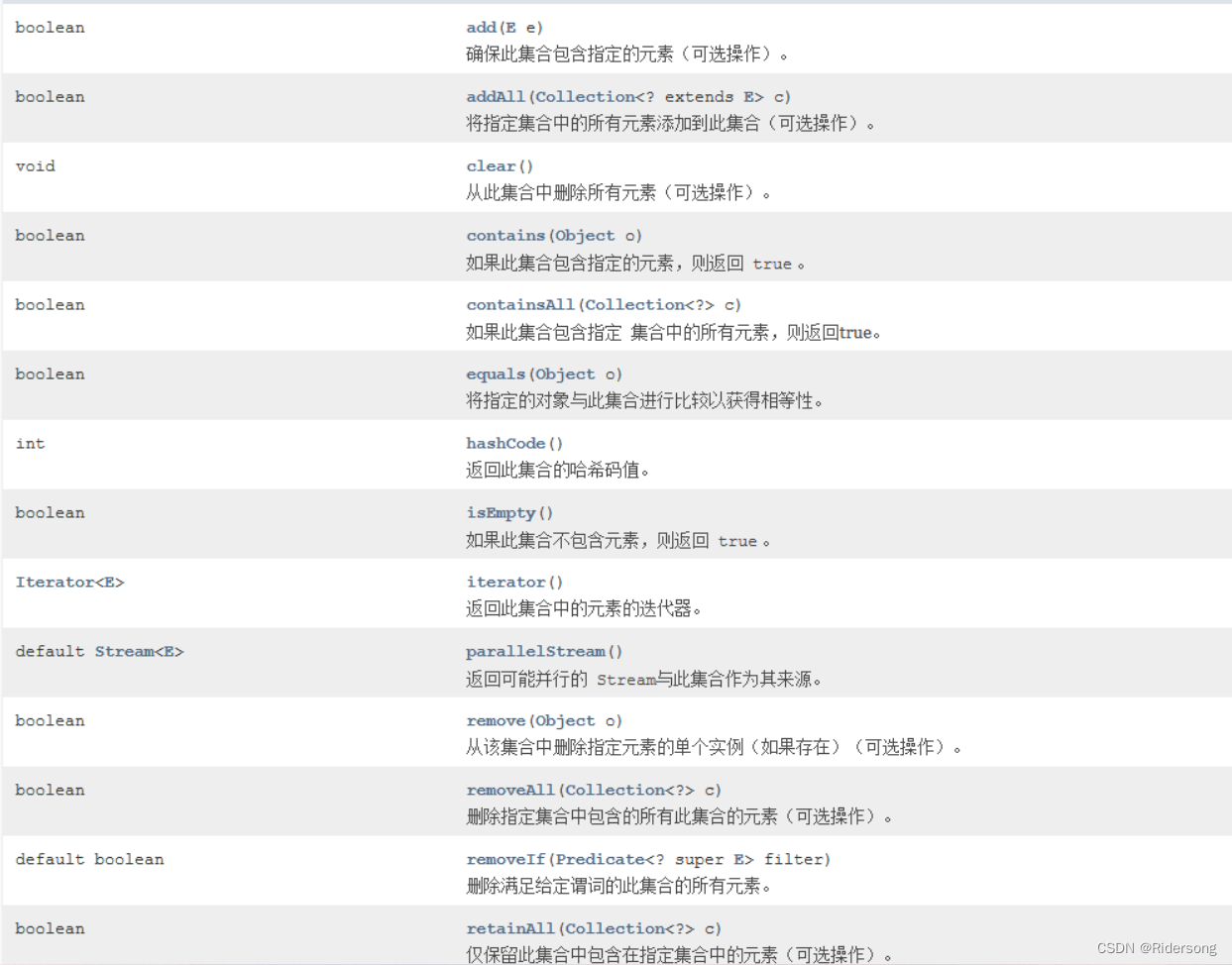
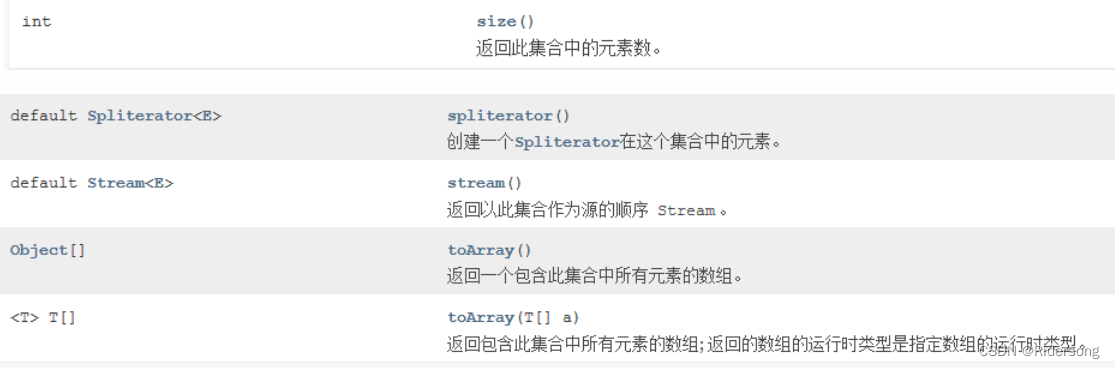
Collection接口和常用方法:
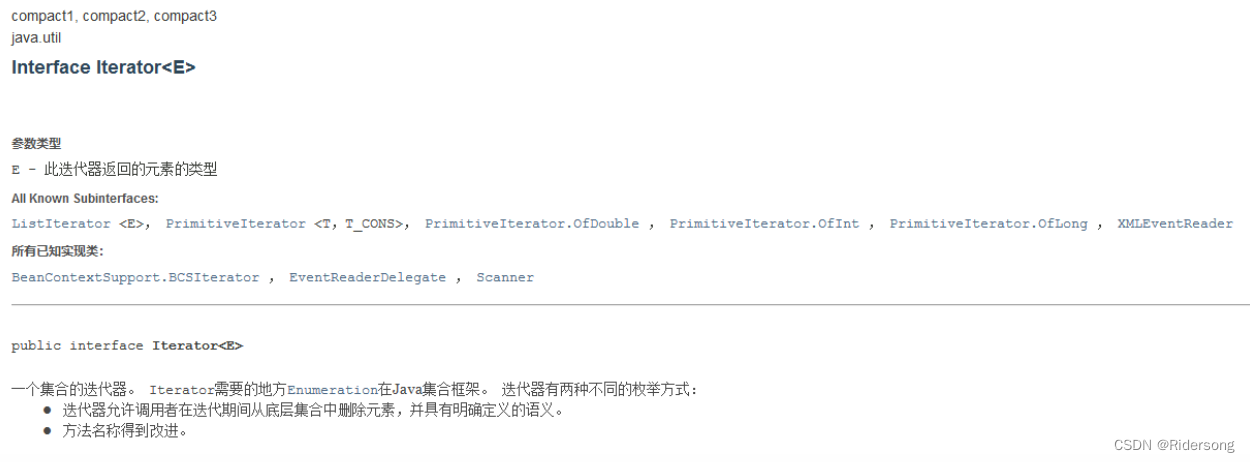
Iteratord迭代器:
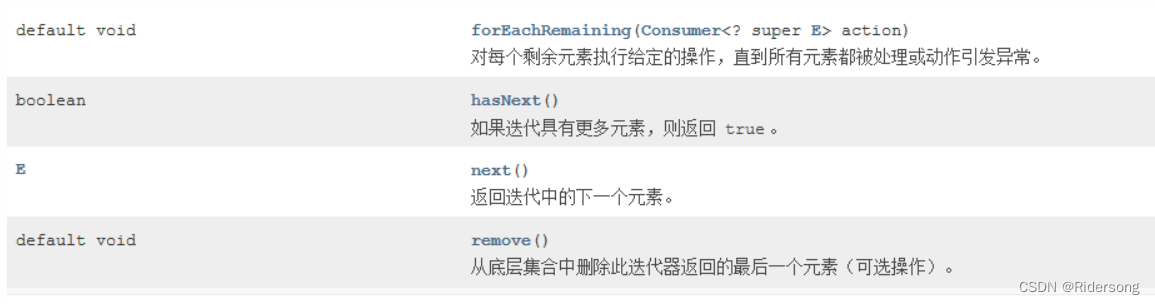
public class CollectionTset {
public static void main(String[] args) {
List list=new ArrayList();
list.add(new Book("西游记","好看",1900));
list.add(new Book("三国演义","好看",1900));
list.add(new Book("红楼梦","好看",1900));
list.add(new Book("水浒传","好看",1900));
Iterator iterator= list.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.println(next);
}
}
}
class Book{
private String name;
private String sc;
private int data;
public Book(String name, String sc, int data) {
this.name = name;
this.sc = sc;
this.data = data;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSc() {
return sc;
}
public void setSc(String sc) {
this.sc = sc;
}
public int getData() {
return data;
}
public void setData(int data) {
this.data = data;
}
@Override
public String toString() {
return "Book{" +
"name='" + name + '\'' +
", sc='" + sc + '\'' +
", data=" + data +
'}';
}
}
List:
1:List集合类中元素有序(即添加顺序和取出顺序一致),且可重复。
2:List集合中的每个元素都有其对应的顺序索引,即支持索引。
3:List容器中的每个元素都对应一个整数型的序号记载其在容器中的位置,可以根据序号存取容器中的元素。
4:List实现的常用类有:ArrayList,LinkedList,Vector。
ArrayList:
1:ArrayList可以存入null。
2:ArrayList是由数组来实现数据存储的。
3:ArrayList基本等同于Vector,处理ArrayList是线程不安全的(但执行效率更高),多线程下不建议使用。
4:ArrayList中维护了一个Object类型的数组elementData.transient Object[] elementData;transient表示瞬间,短暂的,表示该属性不会被序列化。
5:当创建ArrayList对象时,如果使用的是无参构造器,则初始数组的容量为0,第一次添加,则扩容数组容量为10,如果需要再一次扩容,则扩容为之前的1.5倍。
6:如果使用的是指定大小的构造器,则初始数组容量大小为指定大小,如需扩容则直接扩容原数组大小的1.5倍。
Vector:
1:底层也是一个对象数组。
2:Vector是线程同步的,即线程安全,Vector类的操作方法都带有synchronized(同步锁)。
3:开发中,需要线程同步安全时,考虑使用Vector。
LinkedList:
1:LinkedList底层实现了双向链表和双端队列特定。
2:可以添加任意元素,包括null。
3:线程不安全,没有实现同步。
4:元素的添加和删除利用了底层的双向链表,不是依靠数组来实现的。
ArrayList和LinkedList比较:
| 底层结构 | 增删的效率 | 改查的效率 | |
|---|---|---|---|
| ArrayList | 可变数组 | 较低,数组扩容 | 较高 |
| LinkedList | 双向链表 | 较高,通过链表追加 | 较低 |
1:如果改查多选ArrayList。
2:如果增删多选LinkedList。
3:一般来说,在程序中,查询操作居多,大部分情况下选择ArrayList。
Set:
1:无序(添加和取出的顺序不一致),没有索引。
2:不允许重复元素,所以最多包含一个null。
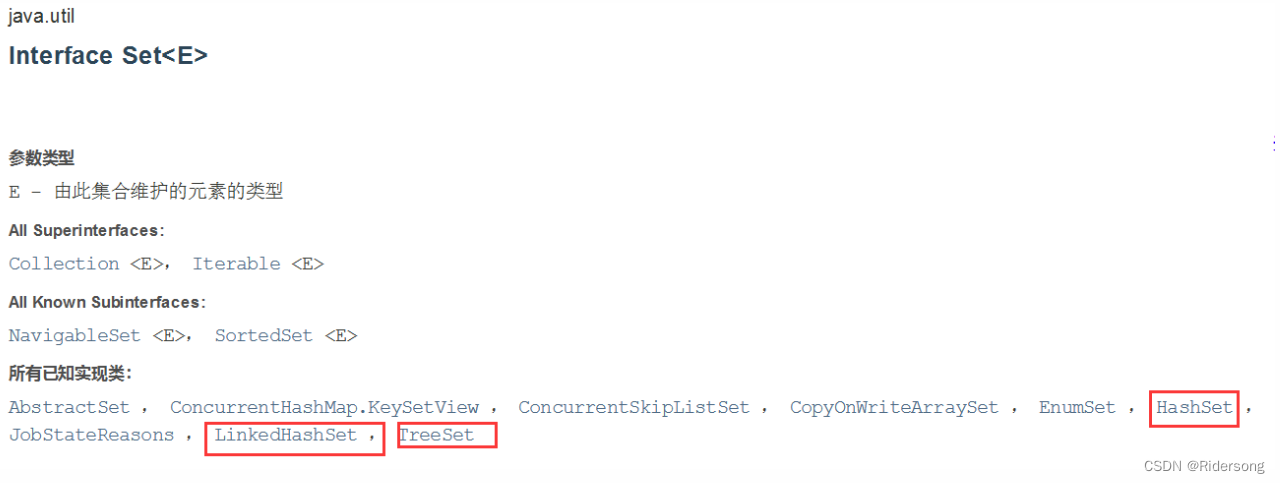

HashSet:
1:HashSet底层实际上是HashMap。(HashMap底层是:数组+链表+红黑树)

2:可以存放null值但只能一个。
3:HashSet不保证元素是有序的,取决于hash后,再确定索引的结果
4:不能有重复元素/对象。
4:没有实现同步线程不安全。
public class CollectionTset2 {
public static void main(String[] args) {
Set set=new HashSet();
set.add("a1");
set.add("a2");
set.add("a3");
set.add(new Dog("a4"));
set.add(new Dog("a4"));//名字一样但是是不同对象
set.add(new String("sjj"));
set.add(new String("sjj"));//只加入一个
// Java程序中的所有字符串文字(例如"abc" )都被实现为此类的实例。相当于两个sjj为同一个对象实例
Iterator iterator= set.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.println(next);
}
}
}
class Dog{
private String name;
public Dog(String name) {
this.name = name;
}
@Override
public String toString() {
return "Dog{" +
"name='" + name + '\'' +
'}';
}
}
LinkedHashSet:
1:是HashSet的子类
2:底层是一个LinkedHashMap,底层维护的是数组+双向链表
3:根据元素的hashCode值来决定元素的存储位置
4:不允许添加相同元素。
TreeSet:
1:使用无参构造器时,插入顺序和输出顺序不同,相对无序。输出顺序一般按照Ascii码大小排序
2:有参构造器里可以传入一个比较器,指定排序规则。
3:底层是TreeMap
public class TreeSet_Test {
public static void main(String[] args) {
TreeSet treeSet=new TreeSet((Object o1,Object o2)->{
//调用了String的compareTo方法进行字符串大小比较
return ((String)o2).compareTo((String) o1);
//按照长度大小,这样的话"tom"和"abc"都是长度为3,会被认为是同一个元素,不能同时加入进去。
//return ((String)o2).length()-((String) o1).length();
});
treeSet.add("a111");
treeSet.add("a22");
treeSet.add("a3");
System.out.println(treeSet);
}
}
Map:
1:Map和Collection并列存在。用于保存具有映射关系的数据:Key-Value。
2:Key和Value可以是任何引用类型的数据,会封装到HashMap$Node对象中。
3:Key不允许重复。出现相同Key时,就相当于替换Key对应的Value值。
4:Value可以重复。
5:Key和Value都可以为null,但是Key只能有一个null,Value为null的可以有多个。
6:常用String类作为Map的Key。
7:Key和Value存在单向一对一关系,即通过指定的Key总能找到对应的Value。
8:Map里Node内部类实现了Map.Entry接口,该接口提供了两个重要方法:getKey(),getValue(),方便遍历,因为Map没有实现Iterable(迭代器)接口。
public class CollectionTest3 {
public static void main(String[] args) {
Map map=new HashMap<>();
map.put("1","a1");
map.put("2","a2");
map.put("3","a3");
map.put("4","a4");
Set set= map.entrySet();
System.out.println(set.getClass());
for (Object o : set) {
Map.Entry entry=(Map.Entry) o;
System.out.println(entry.getKey()+"---"+entry.getValue());
}
}
}几种遍历方式:
public class CollectionTest5 {
public static void main(String[] args) {
Person person1=new Person("sjj",1,18001);
Person person2=new Person("lj",2,17000);
Person person3=new Person("gjl",3,18000);
Map<Integer,Person> map=new HashMap<>();
map.put(person1.getId(),person1);
map.put(person2.getId(),person2);
map.put(person3.getId(),person3);
map.put(4,new Person("dl",4,19000));
//1
for (Integer Key : map.keySet()) {
if(map.get(Key).getMoney()>18000){
System.out.println(map.get(Key));
}
}
//2
for (Person value : map.values()) {
if (value.getMoney()>18000){
System.out.println(value);
}
}
//3
Iterator<Map.Entry<Integer, Person>> iterator=map.entrySet().iterator();
while (iterator.hasNext()) {
Person entry=iterator.next().getValue();
if(entry.getMoney()>18000){
System.out.println(entry);
}
}
//4
for (Map.Entry<Integer, Person> integerPersonEntry : map.entrySet()) {
Person entry = integerPersonEntry.getValue();
if (entry.getMoney() > 18000) {
System.out.println(entry);
}
}
}
}
class Person{
private String name;
private int id;
private int money;
public Person(String name, int id, int money) {
this.name = name;
this.id = id;
this.money = money;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public int getMoney() {
return money;
}
public void setMoney(int money) {
this.money = money;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", id=" + id +
", money=" + money +
'}';
}
}
HashMap:
1:底层实现:数组+链表+红黑树。
2:HashMap没有实现同步,线程不安全。
Hashtable:
1:存放键值对。
2:使用方法与HashMap基本一样。
3:实现了同步,是线程安全的。
4:键值都不能为null。
Properties:
1:继承自Hashtable类,也是使用键值对来存储数据。
2:可以用于xxx.properties文件中,加载数据到Properties类对象,并进行读取和修改。
3:xxx.properties文件通常为配置文件。

Collections工具类:

如何选择适合的集合类:
1:先判断存储数据的类型:一组对象(单列),一组键值对(双列)。
2:单列:Collection接口
允许重复:List
增删多:LinkedList,底层维护了一个双向链表。
改查多:ArrayList:底层维护了Object类型的可变数组。
不允许重复:Set
无序:HashSet,底层是HashMap,维护了一个哈希表(数组+链表+红黑树)。
排序:TreeSet
插入和取出顺序一致:LinkedHashSet,维护数组+双向链表。
3:双列:Map接口
键无序:HashMap,维护了一个哈希表(数组+链表+红黑树)。
键排序:TreeMap
键插入和取出顺序一致:LinkedHashMap
读取文件:Properties















 484
484











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









