







一、主要思想
基于先前我们所拥有的传统机器学习的分类器或者回归器,我们在第一层输出一系列预测结果。再基于这一系列预测结果,作为第二层模型的context输入,再最后输出一个集成的预测结果。
二、Blending
数据集T
【步骤】总结来说:训练集用来训练第一层模型,验证集用来调参,测试集用来度量模型效果
(1)将数据划分为训练集和测试集(test_set),再将训练集二次划分为训练集(train_set)和验证集(val_set)
(2)创建第一层的多个模型,这些模型可以同质化也可以异质化
(3)使用train_set训练(2)中的多个模型,然后用训练好的模型对val_set,test_set做预测得到val_predict,test_predict
(4)创建第二层模型,使用val_predict作为训练集训练第二层的模型
(5)使用第二层训练好的模型对第二层测试集test_predict进行预测,最后得到的cost即为整个预测集的误差
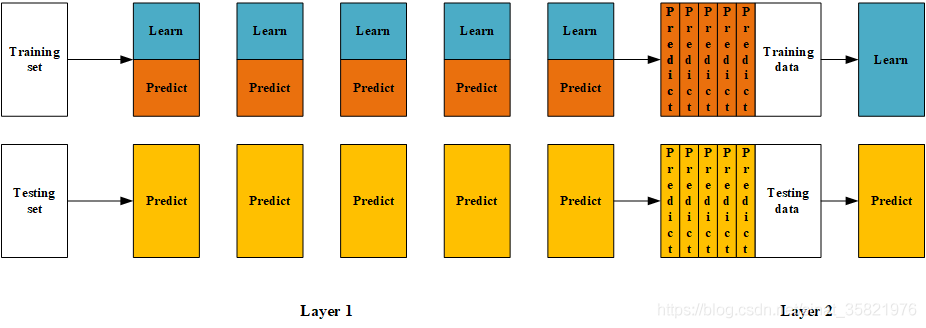
(图片转自https://blog.csdn.net/sinat_35821976/article/details/83622594)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1012
1012











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









