






大模型微调“瘦身”记(三):P-Tuning——让Prompt“活”起来,从v1到v2的通用进化之路
在前几篇关于PEFT(参数高效微调)的文章中,我们探讨了Adapter系列和基于连续Prompt的Prefix/Prompt Tuning。今天,我们要聚焦由清华大学团队提出的另外两个非常有影响力的方法:P-Tuning 和 P-Tuning v2。
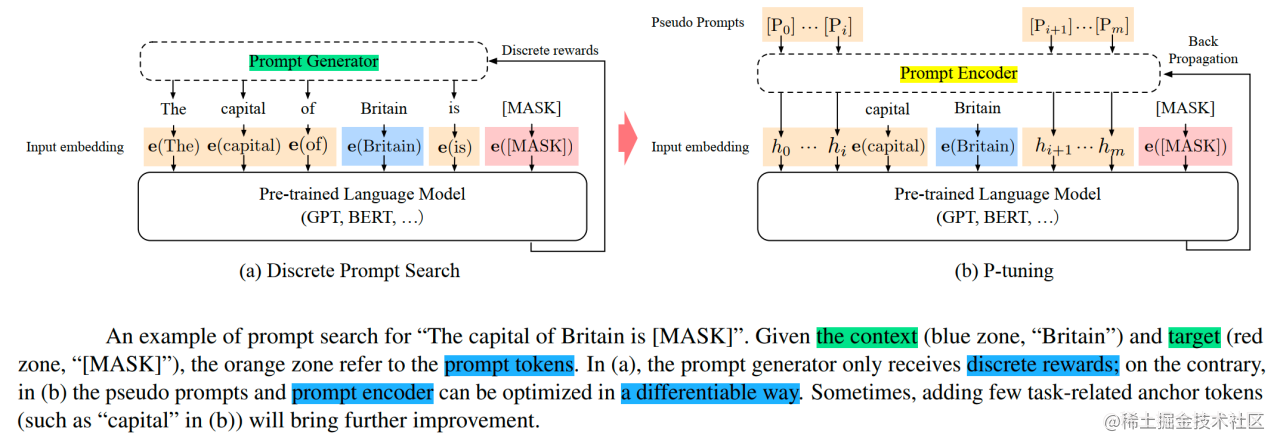
我们已经知道,手动设计Prompt(提示语)就像是给大模型下达指令,但这种方式非常“玄学”,效果对措辞极其敏感,差一个字可能谬以千里。自动化搜索离散Prompt又成本高昂且未必最优。
传统Prompt设计存在两大痛点:
- 离散Prompt敏感:人工设计的Prompt对词序、长度极为敏感(如GPT-3中增减一个词可能导致准确率波动±5%)
- 自动化搜索成本高:离散Token搜索难以找到最优解,且需要大量计算资源

P-Tuning系列正是为了解决这个问题而生,它们的核心思想是将原来需要人工绞尽脑汁设计的离散、固定的Prompt,变成模型可以自己学习的、连续可微的“虚拟Token”(Virtual Tokens)。这就像是把生硬的指令变成了可以灵活调整的“咒语”,让模型自己找到最有效的沟通方式。
一、 P-Tuning (v1):让GPT也能更好地理解NLU任务
1. 背景:打破Prompt设计瓶颈,解锁GPT潜能
P-Tuning(出自论文 GPT Understands, Too)的提出,旨在解决两个核心痛点:
- Prompt敏感性与设计难题:如上所述,手动Prompt效果不稳定,自动化搜索成本高且可能非最优。
- 挖掘GPT在NLU上的潜力:当时普遍认为像BERT这样的掩码语言模型(MLM)更擅长自然语言理解(NLU)任务,而GPT系列自回归模型相对较弱。P-Tuning试图证明,通过合适的Prompting方式,GPT也能在NLU任务上表现出色。
P-Tuning的核心思路是:不再依赖人工设计的真实Token作为Prompt,而是引入少量可学习的、连续的“虚拟Token”(Virtual Token Embeddings),让模型在训练中自动优化这些虚拟Token,找到最适合任务的“隐式Prompt”。
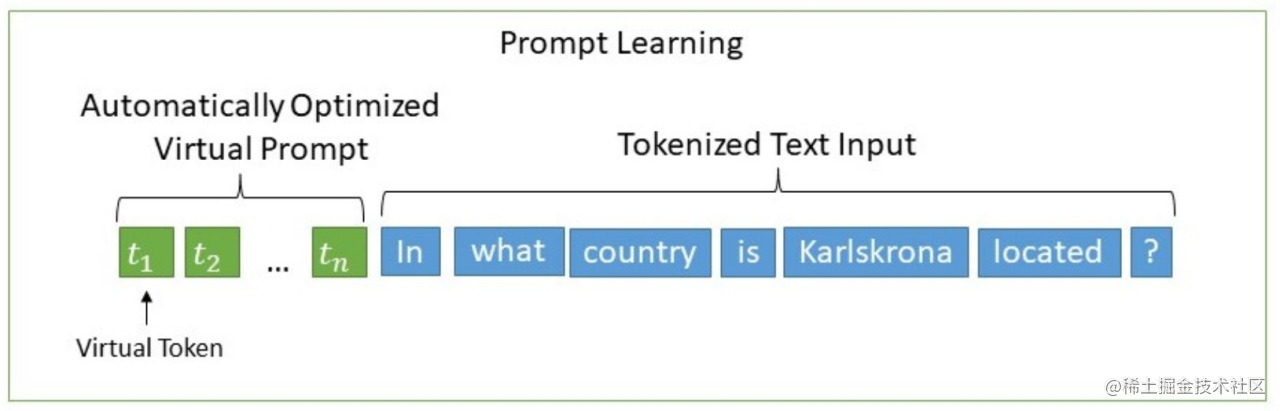
2. 技术原理:引入Prompt Encoder (MLP+LSTM)
-
核心机制:可学习的虚拟Token
P-Tuning与Prompt Tuning类似,也是在输入层将一些可学习的虚拟Token嵌入(p_1, ..., p_k)插入到原始输入的词嵌入序列(e_1, ..., e_n)中。与Prompt Tuning不同的是,P-Tuning允许这些虚拟Token插入到序列的任意位置,而不仅仅是作为前缀。这更像是将传统模板中的某些占位符替换为可学习的向量。例如,一个模板可以是
[x_1, ..., x_i, p_1, ..., p_k, x_{i+1}, ..., x_n]对应的嵌入序列。
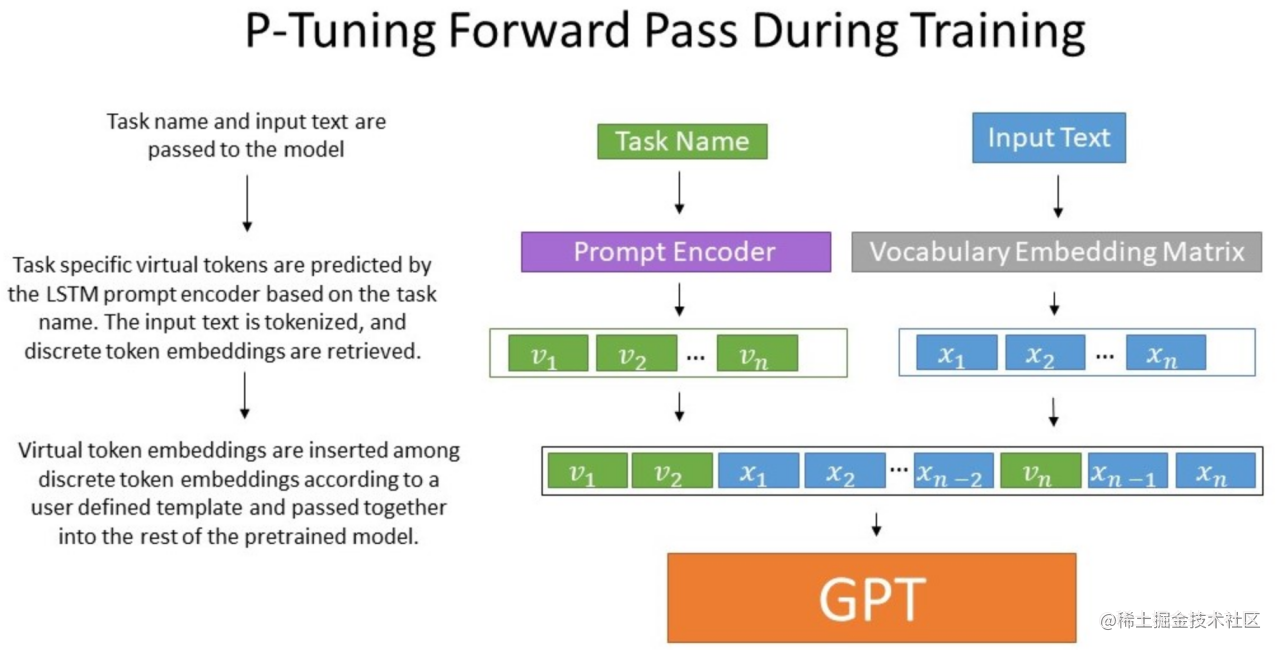
-
关键创新:Prompt Encoder
作者发现,预训练语言模型的词嵌入空间已经高度离散化。如果直接随机初始化虚拟Token嵌入p_i并进行优化,很容易陷入局部最优,并且忽略了这些虚拟Token之间可能存在的内在联系(比如语法或语义上的依赖)。为了解决这个问题,P-Tuning引入了一个Prompt Encoder来生成这些虚拟Token的最终表示。这个Encoder通常由一个双向LSTM(BiLSTM)和一个MLP(多层感知机) 组成:
- 初始化一系列可学习的伪Token(Pseudo Tokens)
h_1, ..., h_k。这些是真正需要训练的参数。 - 将这些伪Token输入到BiLSTM中,捕捉它们之间的序列依赖关系。
o_i = BiLSTM(h_i, (o_{i-1}, c_{i-1})) - 将LSTM的输出通过一个MLP(通常是两层)进行转换,得到最终注入到模型输入中的虚拟Token嵌入
p_i。
p_i = MLP(o_i)
这个Prompt Encoder的作用是:
- 平滑优化空间:使得优化过程更稳定,不易陷入糟糕的局部最优。
- 建模Token间依赖:让虚拟Token之间能相互关联,形成更有意义的“隐式Prompt”。
- 初始化一系列可学习的伪Token(Pseudo Tokens)
-
训练过程:
- 冻结整个预训练语言模型(LM)的参数。
- 只训练Prompt Encoder(即伪Token
h_i、LSTM和MLP的参数) 的参数。
-
代码示例 (PyTorch风格,概念性展示Prompt Encoder)
import torch import torch.nn as nn class PromptEncoder(nn.Module): def __init__(self, prompt_len, hidden_size, embedding_dim, lstm_dropout=0.0): super().__init__() self.prompt_len = prompt_len self.embedding_dim = embedding_dim # LM的词嵌入维度 self.hidden_size = hidden_size # LSTM和MLP的隐藏层大小 # 1. 可学习的伪Token (初始化参数) # Shape: (prompt_len, hidden_size) self.pseudo_tokens = nn.Parameter(torch.randn(prompt_len, hidden_size)) # 2. BiLSTM层 self.lstm = nn.LSTM(input_size=hidden_size, hidden_size=hidden_size // 2, # 双向,所以 hidden_size/2 num_layers=2, dropout=lstm_dropout, bidirectional=True, batch_first=True) # 3. MLP层 (e.g., two layers) self.mlp = nn.Sequential( nn.Linear(hidden_size, hidden_size), nn.ReLU(), nn.Linear(hidden_size, embedding_dim) # 输出维度匹配LM的嵌入维度 ) def forward(self): # Input pseudo_tokens shape: (prompt_len, hidden_size) # Add batch dimension for LSTM: (1, prompt_len, hidden_size) pseudo_tokens_batch = self.pseudo_tokens.unsqueeze(0) # LSTM output shape: (1, prompt_len, hidden_size) lstm_output, _ = self.lstm(pseudo_tokens_batch) # MLP input shape: (prompt_len, hidden_size) after squeeze # MLP output shape: (prompt_len, embedding_dim) prompt_embeds = self.mlp(lstm_output.squeeze(0)) return prompt_embeds # 这些是最终要插入到输入序列的虚拟Token嵌入 # --- 如何在模型输入时使用 --- # (假设 prompt_encoder 是 PromptEncoder 的实例) # (假设 inputs_embeds 是原始输入的词嵌入, shape: (batch_size, seq_len, embedding_dim)) # (假设 prompt_indices 是虚拟token要插入的位置) # 1. 获取虚拟Token嵌入 (与batch无关,只需计算一次) # virtual_token_embeds shape: (prompt_len, embedding_dim) virtual_token_embeds = prompt_encoder() # 2. 将虚拟Token嵌入扩展到batch维度 # virtual_token_embeds_batch shape: (batch_size, prompt_len, embedding_dim) batch_size = inputs_embeds.size(0) virtual_token_embeds_batch = virtual_token_embeds.unsqueeze(0).expand(batch_size, -1, -1) # 3. 插入到输入嵌入中 (这里以添加到最前面为例) # combined_embeds shape: (batch_size, prompt_len + seq_len, embedding_dim) combined_embeds = torch.cat([virtual_token_embeds_batch, inputs_embeds], dim=1) # 4. 构造对应的Attention Mask (省略细节,参考Prompt Tuning部分) # combined_attention_mask = ... # 5. 将 combined_embeds 和 combined_attention_mask 输入LM # outputs = language_model(inputs_embeds=combined_embeds, attention_mask=combined_attention_mask) -
实验结果:
- P-Tuning在许多NLU任务上取得了与全量微调相当甚至更好的效果。
- 显著提升了GPT在NLU任务上的表现,证明了其潜力,甚至在某些任务上超过了同等规模的BERT。
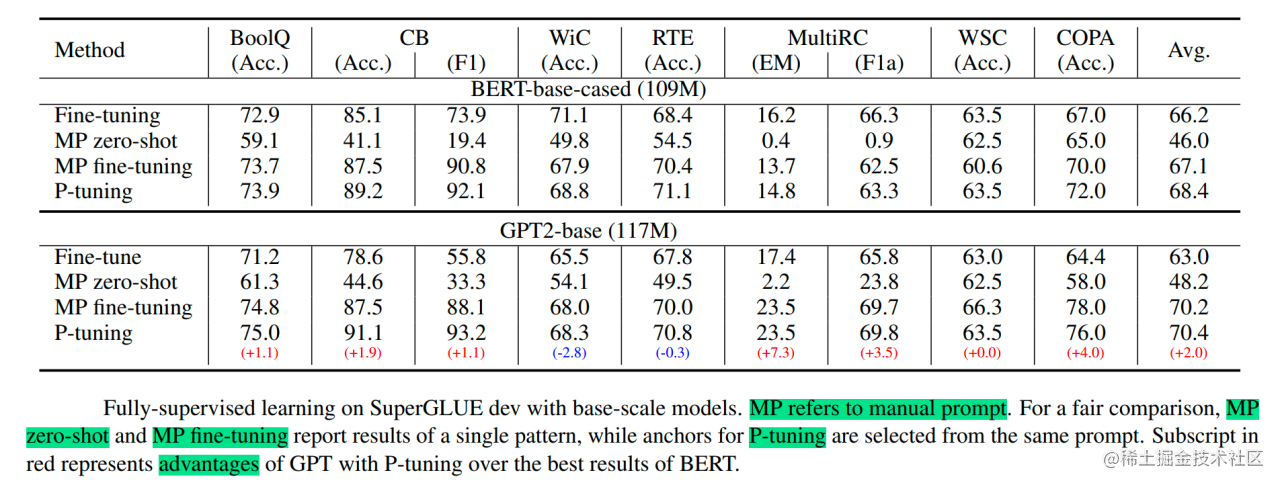
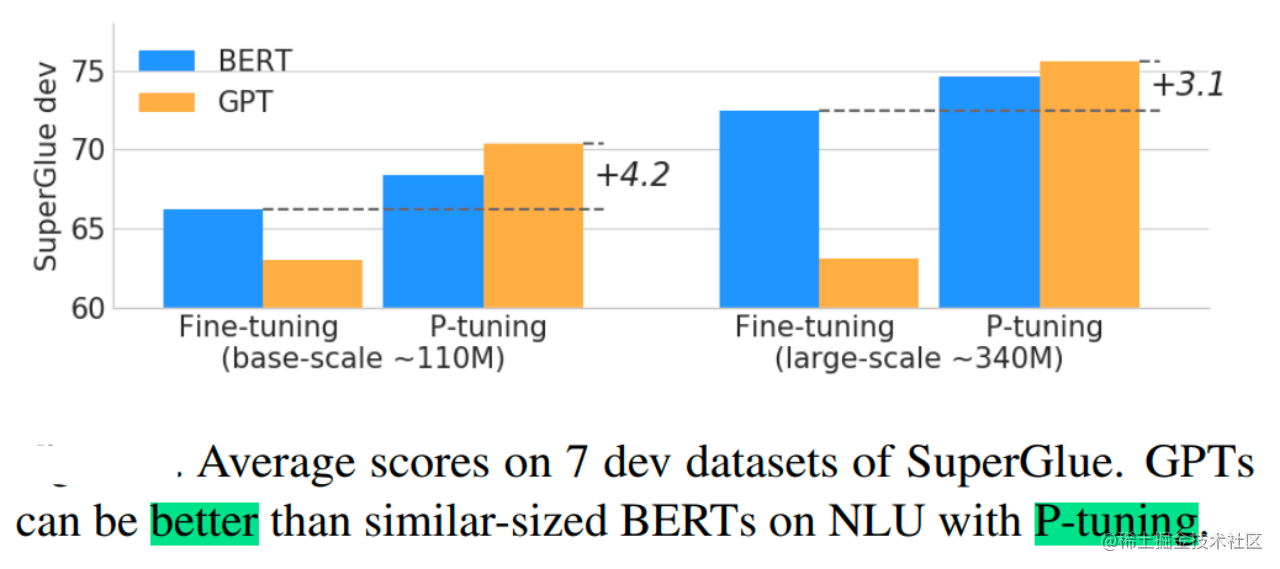
(图5: P-Tuning 性能接近甚至优于全量微调) (图6: P-Tuning 下 GPT 在 NLU 任务上超越 BERT)
二、 P-Tuning v2:走向通用性,媲美全量微调
1. 背景:P-Tuning v1 与 Prompt Tuning 的局限性
尽管P-Tuning v1和Prompt Tuning取得了成功,但它们仍存在一些问题,限制了其广泛应用:
- 缺乏规模通用性(Scale Generalization):Prompt Tuning的论文指出,它主要在超大模型(>10B参数) 上才能媲美全量微调。对于中小型模型(100M - 1B),效果与全量微调差距较大。P-Tuning v1虽然有所改善,但这个问题依然存在。
- 缺乏任务通用性(Task Generalization):它们在一些分类或简单生成任务上表现不错,但在复杂的序列标注任务(如命名实体识别NER、抽取式问答QA、语义角色标注SRL)上效果不佳。
- 浅层Prompt的优化挑战(Shallow Prompt Optimization):只在输入层插入Prompt,其影响需要经过多层Transformer才能传递到最终输出,这种影响相对间接。同时,由于只在输入层,可学习的参数量也受到限制(通常仅占总参数的~0.01%)。
P-Tuning v2(出自论文 P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks)正是为了解决这些问题而提出的,目标是成为一个在各种模型规模和NLU任务上都能媲美全量微调的通用解决方案。
2. 技术原理:深度提示优化 (Deep Prompt Tuning) + 若干改进
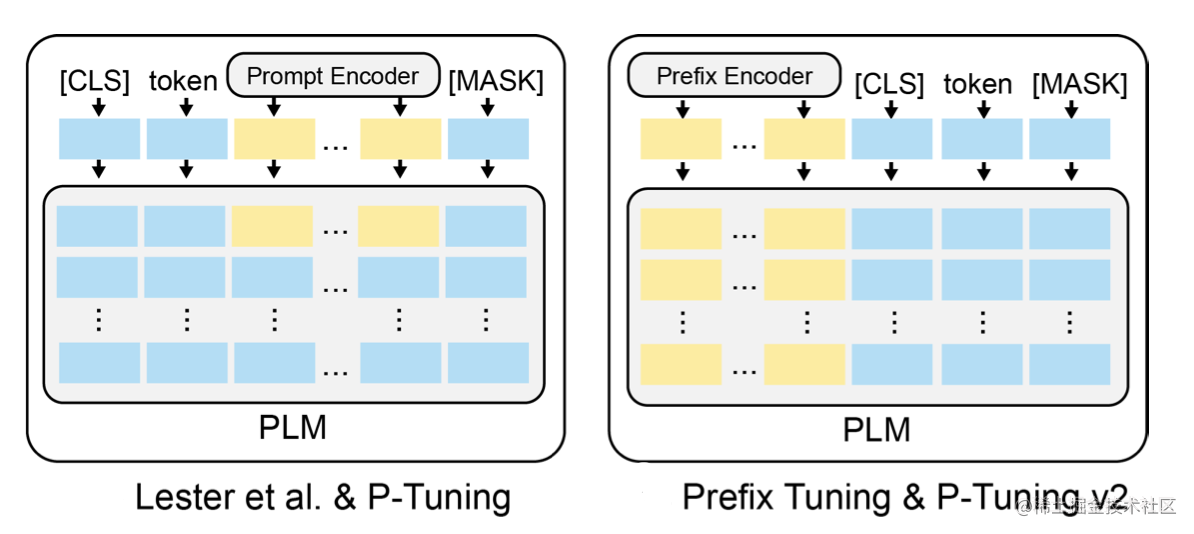
P-Tuning v2的核心思想借鉴了Prefix Tuning,采用了深度提示优化(Deep Prompt Tuning):将可学习的Prompt Token嵌入到Transformer的每一层(或部分层)的输入中,而不仅仅是第一层。
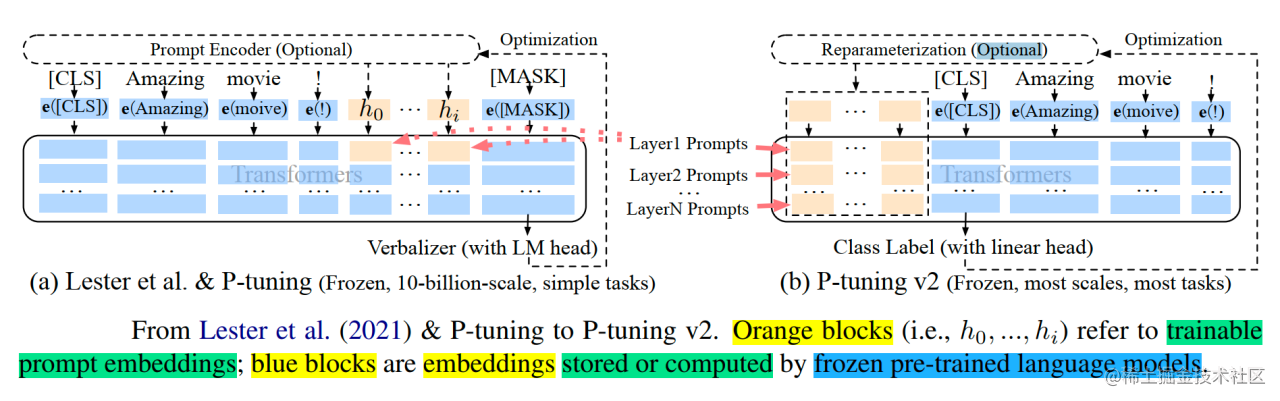
这样做的好处是:
- 增加可调参数量:参数量从v1的0.01%增加到0.1%-3%(仍远小于全量微调),提供了更大的模型容量来适应任务。
- 更直接的影响:深层Prompt可以直接影响模型在高层的表示学习和预测,引导更有效。
P-Tuning v2的具体做法与Prefix Tuning类似,但有几个关键区别和改进:
-
移除了重参数化编码器(No Reparameterization):
- P-Tuning v1的LSTM+MLP或Prefix Tuning的MLP,在v2中被移除了。
- 原因:作者发现,对于深度提示优化,这种重参数化带来的稳定性或性能提升很小(尤其在中小型模型上),甚至有时会损害性能。直接优化每一层的Prompt嵌入效果足够好。
- 这意味着P-Tuning v2直接学习每一层所需的Prompt嵌入
P_i(i是层索引)。
-
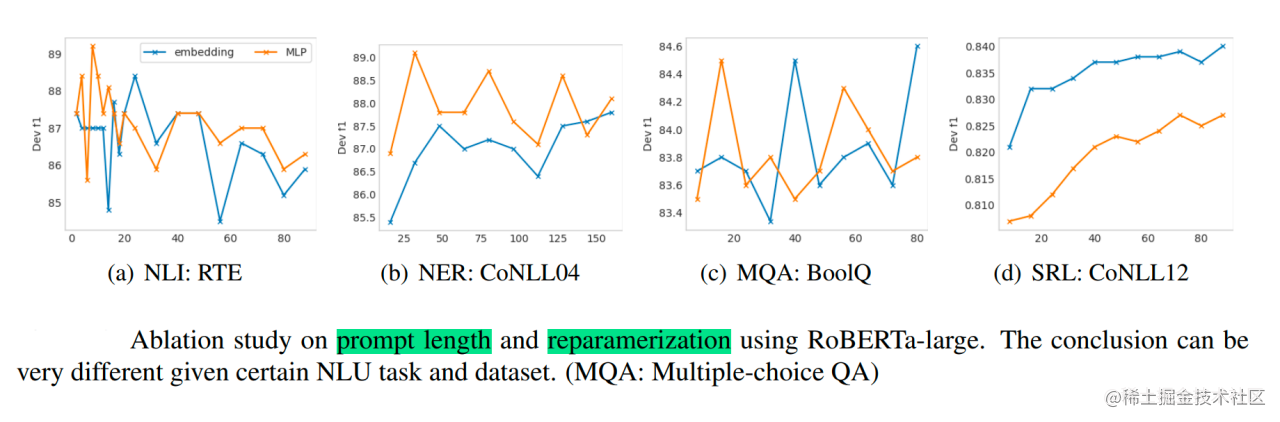
任务相关的提示长度(Task-Specific Prompt Length):
- 认识到不同任务的复杂度不同,v2强调需要根据任务调整Prompt的长度 (
prompt_len)。 - 简单任务(如情感分类)可能只需要较短的Prompt(20),而复杂任务(如序列标注、阅读理解)可能需要更长的Prompt(100)才能达到最佳效果。
- 认识到不同任务的复杂度不同,v2强调需要根据任务调整Prompt的长度 (
-
多任务学习优化(Multi-task Learning):
- 可选但推荐:先在一个包含多个相关任务的数据集上预训练Prompt参数,然后再在目标下游任务上微调。
- 好处:
- 缓解优化难题:为Prompt提供更好的初始化,尤其是在数据量较少的任务上。
- 知识共享:让Prompt学习到跨任务的通用知识,提升在目标任务上的表现。
-
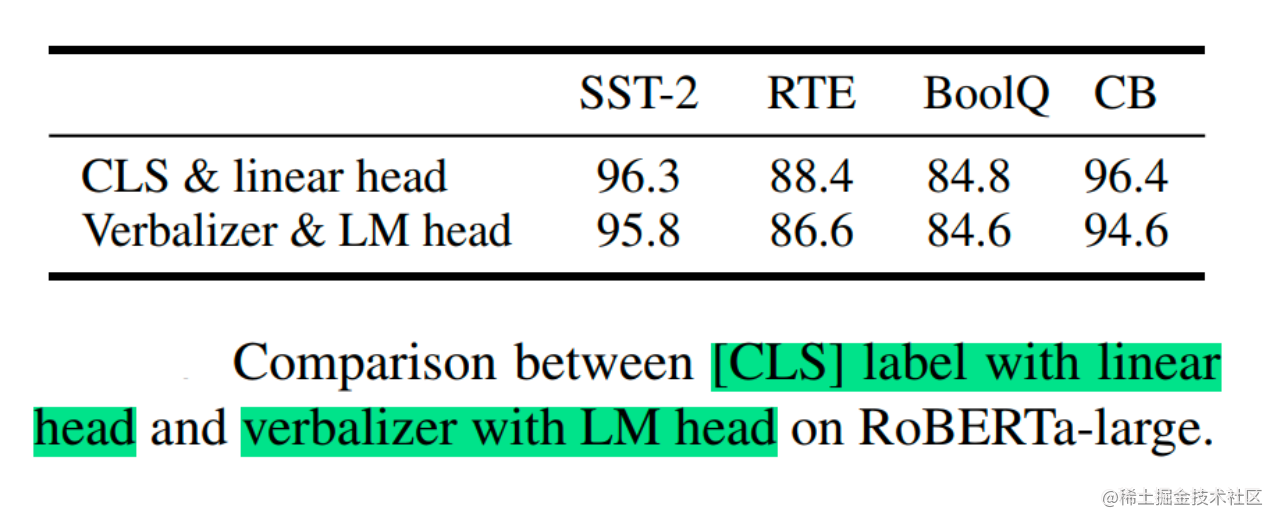
回归传统分类头(Classification Head over Verbalizer):
- P-Tuning v1和许多Prompt方法依赖Verbalizer,即将类别标签映射到词汇表中的具体单词(例如,情感分类的标签
positive/negative映射到单词"great"/“terrible”),让模型通过预测这些单词来完成分类。 - 问题:Verbalizer的设计本身又引入了类似Prompt设计的难题;并且它不适用于标签没有明确词语对应的情况(如序列标注的BIO标签)或需要句子嵌入的任务。
- P-Tuning v2的做法:放弃Verbalizer,回归传统微调范式。对于分类任务,在序列的特殊Token(如
[CLS])之上添加一个随机初始化的小型分类头(通常是一个线性层);对于序列标注任务,在每个Token的表示之上添加分类头。 - 好处:增强了通用性,使其能无缝应用于包括序列标注在内的各种NLU任务。
- P-Tuning v1和许多Prompt方法依赖Verbalizer,即将类别标签映射到词汇表中的具体单词(例如,情感分类的标签
-
代码示例 (概念性展示 P-Tuning v2 如何修改每一层输入)
- P-Tuning v2在每一层的实现方式与Prefix Tuning非常相似,都是将可学习的Prompt向量(通常是Key和Value)注入到Attention机制中。可以参考上一篇博客中Prefix Tuning的代码示例。
- 关键区别在于:P-Tuning v2没有用于生成这些Prompt向量的MLP(重参数化层),而是直接学习每层所需的
prefix_k和prefix_v参数。
# 概念性回顾 PrefixAttention (稍作修改以反映 P-Tuning v2 的直接学习) class DeepPromptAttention(nn.Module): def __init__(self, d_model, nhead, prefix_len, layer_idx): # layer_idx用于区分不同层 super().__init__() # ... (和 PrefixAttention 类似的 Q, K, V, out_proj) ... self.prefix_len = prefix_len self.layer_idx = layer_idx # 标识层号 # 直接学习该层的 Prefix Key 和 Value 参数 # P-Tuning v2 没有 MLP 来生成它们 # 参数命名体现层级特异性 (可选) self.prefix_k = nn.Parameter(torch.randn(self.nhead, self.prefix_len, self.d_head)) self.prefix_v = nn.Parameter(torch.randn(self.nhead, self.prefix_len, self.d_head)) # 注意:这些参数是可训练的,而模型的原始权重是冻结的 def forward(self, query, key, value, attention_mask=None): # ... (计算原始 Q, K, V) ... # ... (扩展 prefix_k, prefix_v 到 batch 维度) ... # k' = concat([prefix_k_batch, k], dim=2) # v' = concat([prefix_v_batch, v], dim=2) # ... (计算 Attention(q, k', v')) ... # ... (应用 Mask) ... # ... (输出投影) ... return output # 在整个Transformer模型中,每一层都使用这样一个 DeepPromptAttention 模块 # 并且每一层的 prefix_k, prefix_v 参数是独立学习的 -
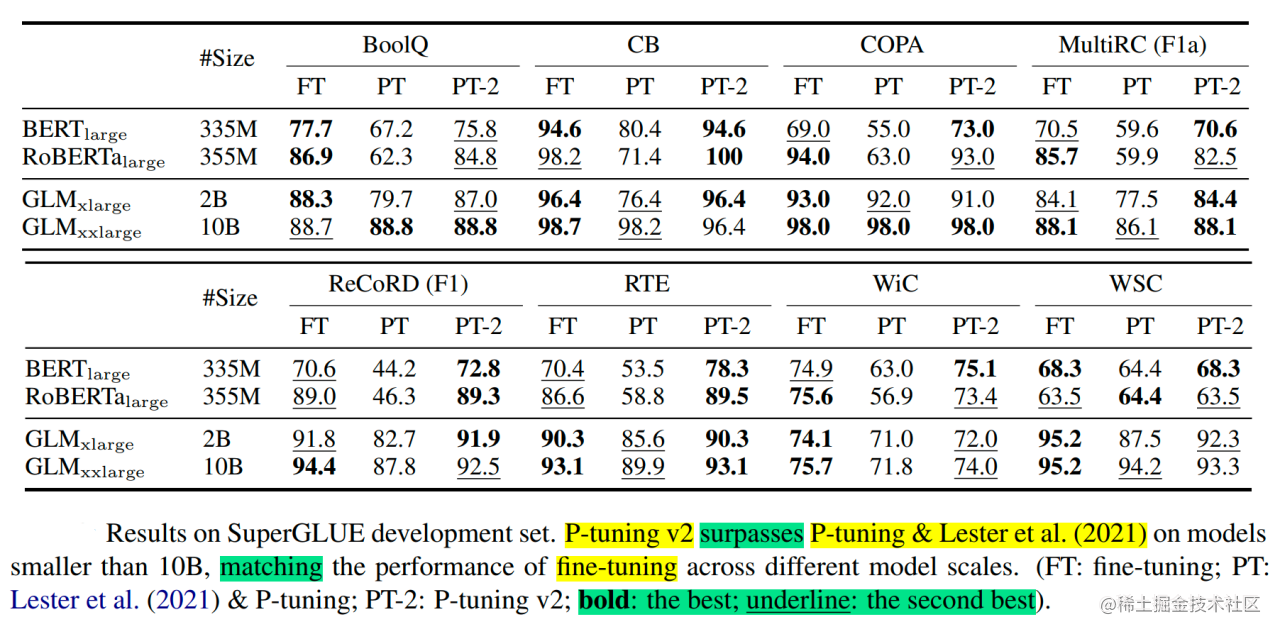
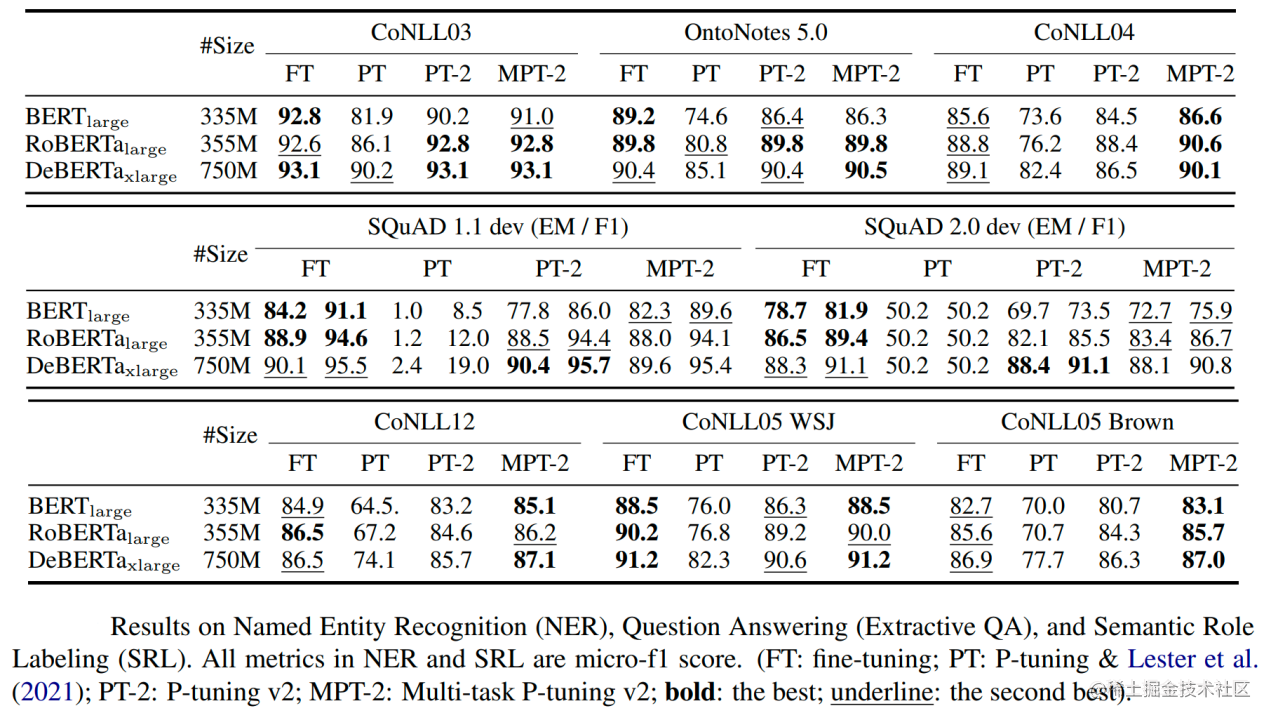
实验结果:
- 跨规模有效:P-Tuning v2在各种模型规模(从330M到10B+) 上都能稳定地达到或超过全量微调的性能。
- 跨任务通用:在简单NLU任务(如GLUE)和复杂序列标注任务(如NER、QA、SRL)上均表现出色,显著优于P-Tuning v1和Prompt Tuning。
- Prompt长度影响:证实了复杂任务需要更长的Prompt。
三、 P-Tuning v1 vs. v2:划重点
| 特性 | P-Tuning (v1) | P-Tuning v2 |
|---|---|---|
| Prompt插入位置 | 仅输入层,位置可选 | Transformer每一层 (Deep Prompt Tuning) |
| Prompt参数生成 | 需要Prompt Encoder (LSTM+MLP) | 直接学习每层Prompt参数,无Encoder |
| 参数量 | 极少 (~0.01%) | 较少 (~0.1% - 3%) |
| 模型规模依赖 | 对中小模型效果与FT差距大 | 对各种规模模型均有效 |
| 任务通用性 | 对复杂序列任务效果不佳 | 对各类NLU任务(包括序列标注)通用 |
| 分类方式 | 通常依赖Verbalizer | 回归传统分类头 (更通用) |
| 核心技术 | Prompt Encoder | Deep Prompt Tuning + 放弃重参数化 + 放弃Verbalizer |
简单理解:
- P-Tuning v1 ≈ Prompt Tuning + Prompt Encoder (LSTM+MLP)
- P-Tuning v2 ≈ Prefix Tuning (适配NLU) - Reparameterization MLP + Multi-task (Optional) + Classification Head
四、 面试直通车
面试官可能会这样问你关于P-Tuning系列的问题:
- P-Tuning (v1) 解决了什么问题?它与Prompt Tuning的主要区别是什么?
- 回答: 解决了手动Prompt敏感和设计难的问题。主要区别在于P-Tuning引入了Prompt Encoder (LSTM+MLP) 来生成虚拟Token嵌入,以稳定优化并建模Token间依赖,而Prompt Tuning直接学习嵌入。
- 为什么要用Prompt Encoder?
- 回答: 因为LM嵌入空间离散,直接优化易陷局部最优。Encoder可以平滑优化空间,并捕捉虚拟Token间的序列关系。
- P-Tuning v2相比v1主要改进了什么?解决了什么问题?
- 回答: 核心改进是采用深度提示优化(每层加Prompt),解决了v1在中小模型和复杂任务上效果不佳的问题(规模和任务通用性)。同时移除了Prompt Encoder,并回归传统分类头增强通用性。
- P-Tuning v2和Prefix Tuning有什么异同?
- 相同点: 都采用深度提示优化,在每层注入Prompt。
- 不同点: P-Tuning v2通常移除了Prefix Tuning中的重参数化MLP;P-Tuning v2更侧重NLU任务,并明确提出了多任务学习和使用传统分类头等策略。
- P-Tuning v2为什么放弃了Verbalizer?
- 回答: Verbalizer设计困难,且不适用于无意义标签(如BIO)或需要句子嵌入的任务。回归传统分类头使其更通用,能适配包括序列标注在内的更广泛任务。
结语
P-Tuning系列,特别是P-Tuning v2,代表了参数高效微调领域的重要进展。通过将Prompt从人工设计的离散符号转变为模型可学习的连续向量,并将其影响力深入到模型的每一层,P-Tuning v2成功地在广泛的模型规模和任务类型上实现了与全量微调相媲美的性能,同时保持了极高的参数效率。它不仅为我们提供了一个强大的微调工具,也为理解Prompting机制和大型语言模型的工作原理提供了深刻的见解。
希望这篇详细的解析能帮助你彻底理解P-Tuning和P-Tuning v2!如果还有任何疑问,欢迎随时提出!
参考:
https://zhuanlan.zhihu.com/p/635848732



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









