







说明:本篇是学习Reinforcement Learning Chapter 2 Multi-arm Bandits多臂老虎机问题的总结和感悟。
文章目录
基于强化学习的一些前言
- 强化学习最重要的特征是,使用训练信息来评估所采取的行动,而不是通过给出正确的行动来指导。这就是为什么产生了主动探索的需要,以及对良好行为的明确的试错搜索。
- 简单说明强化学习要素:主体、环境、策略、奖励信号、价值函数,以及可选的环境模型。策略定义了主体在给定时间内的行为方式;奖励信号定义了强化学习问题中的目标。奖励信号表示的是某一选择之后直接意义上的好的奖励,而价值函数表示的是长期的好的奖励结果。可选的环境模型指在实际经历未来可能的情况之前,通过考虑未来可能的情况来决定行动方针的任何方法。
- 本篇内容从简单的非关联问题引入,研究强化学习的评估方面内容。
一、An n-Armed Bandit Problem是什么?
该问题是强化学习的典型问题,也是一个预期奖励最大化问题:在选择、行动之后获得一定的奖励,通过对过去的行为学习,决定下一步选择。最终的目标是在一段时间内最大化预期的总奖励。
问题的命名来源是每一个动作选择就像是在玩老虎机的一个杠杆,奖励是击中头奖的回报。通过重复的行动选择,通过把行动集中在最好的杠杆上来最大化的收益。
在这个问题中存在一个探索和开发矛盾点。探索即不断尝试新的选择以期望可以获得比当前最优解更好的办法;而开发则是使用当前最优解保证获得较高的收益。总的来说,开发是一步最大化预期回报的正确做法,但从长远来看,探索可能会产生更大的总回报。
下面的内容是对于如何平衡二者之间的矛盾提出的基本解决办法。
二、Action-Value Methods
这部分将更仔细地研究一些简单的方法来估计行动的值,并使用估计来做出行动选择决策。一个动作的真正价值是当该动作被选择时所获得的平均奖励。
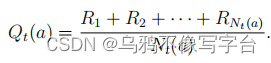
1. greedy method
greedy的办法:最简单的动作选择规则是选择估计最高奖励值的动作。它总是利用当前的知识来最大限度地获得即时奖励;它没有花任何时间来取样明显的劣等的行为,看看它们是否真的会更好。
这种办法可以用下式表示:
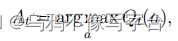
2. ε-greedy method
ε-greedy的办法:在大多数时间内使用greedy的办法(直接使用当前最高奖励值的动作),但每隔一段时间,比如小概率ε,从所有具有相同概率的行动中随机选择,独立于行动值估计。
下面将用一个例子比较两种办法的相对有效性:
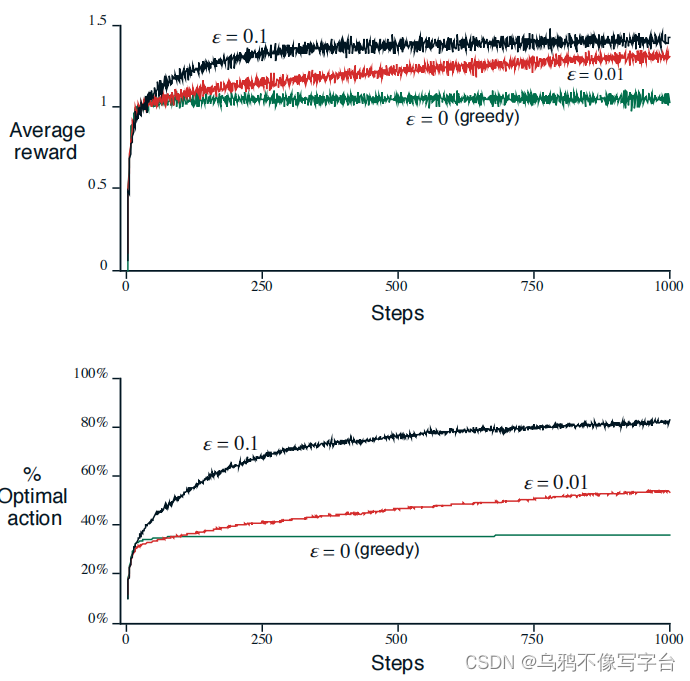
ε-greedy的方法最终表现得更好,因为它们继续探索,并提高了它们识别最优行动的机会。ε=0.1方法探索了更多,通常会更早地找到最优操作,但选择它的时间不会超过91%。ε=0.01方法改进得更慢,但最终在两种性能指标上都优于ε=0.1方法。
另一方面,如果奖励方差为零,那么greedy的方法在尝试一次后就会知道每个动作的真实值。在这种情况下,greedy方法实际上可能表现最好,因为它很快就会找到最优动作,然后永远不会探索。
三、Incremental Implementation
对于上述讨论的简单情况,存在一个问题是,它的内存和计算需求会随着时间的推移而增长。也就是说,行动a后的额外奖励需要更多的记忆来存储它,并导致需要更多的计算来确定Qt(a)。
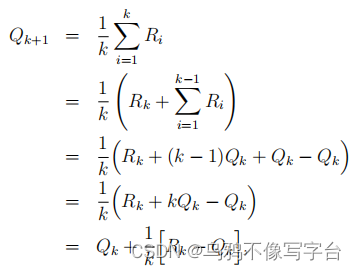
一般形式是:NewEstimate ← OldEstimate + StepSize [ Target − OldEstimate ] .
四、跟踪非平稳问题
当遇到有效的非平稳的强化学习问题时,在奖励方面,最近的奖励是更值得重视的。最流行的方法之一是使用一个恒定的步长参数α用于更新。

经过逐步迭代,可以得到Qk+1是过去奖励和Q的初始估计的加权平均值Q。
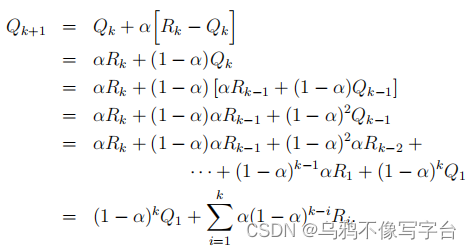
五、最优初始值
初始值,Q1(a),在某些情况下也会对学习的最终结果产生影响。
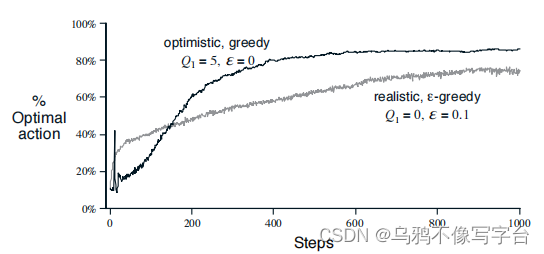
上图显示了使用Q1(a)=+5的greedy方法的性能。为了进行比较,也给出了一个与Q1(a)=0的ε-greedy方法。最初,乐观方法表现更差因为它探索更多,但最终表现更好因为它的探索随着时间的推移而减少。
然而,任何以任何特殊方式关注初始状态的方法都不太可能有助于处理一般的非平稳情况。
总结
本篇内容从强化学习的本质出发,以最简单的多臂老虎机问题为例引入greedy等相关办法的说明,并对其基本影响因素进行了讨论。















 479
479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









