







数据结构与算法之美(二分)
二分查找
一、什么是二分查找
二分查找针对的是一个有序的数据集合,每次通过跟区间中间的元素对比,将待查找的区间缩小为之前的一半,直到找到要查找的元素,或者区间缩小为0。
比如说,我们现在来做一个猜字游戏。我随机写一个0到99之间的数字,然后你来猜我写的是什么。猜的过程中,你每猜一次,我就会告诉你猜的大了还是小了,直到猜中为止。
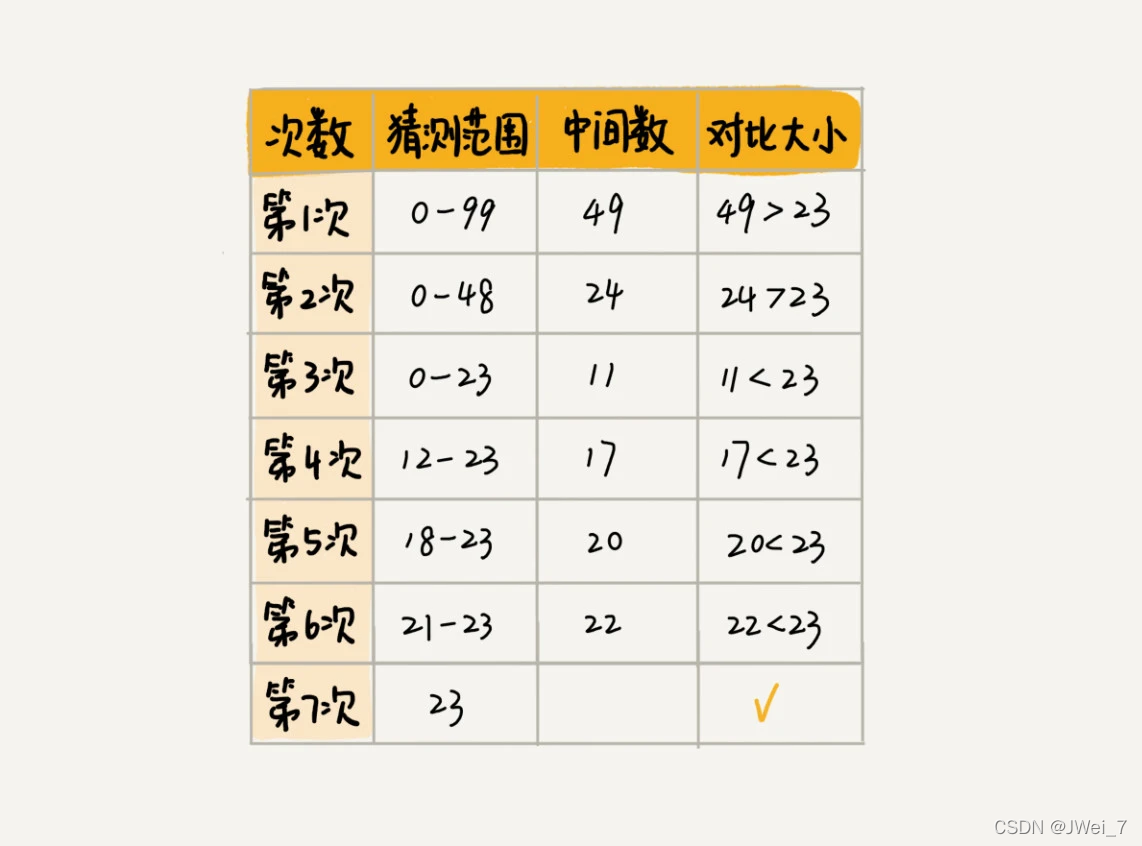
二、时间复杂度分析?
1.时间复杂度
二分查找是一种非常高效的查找算法,高效到什么程度呢?我们来分析一下它的时间复杂度。
假设数据大小是n,每次查找后数据都会缩小为原来的一半,最坏的情况下,直到查找区间被缩小为空,才停止。所以,每次查找的数据大小是:n,n/2,n/4,…,n/(2^k),…,这是一个等比数列。当n/(2^k)=1时,k的值就是总共缩小的次数,也是查找的总次数。而每次缩小操作只涉及两个数据的大小比较,所以,经过k次区间缩小操作,时间复杂度就是O(k)。通过n/(2^k)=1,可求得k=log2n,所以时间复杂度是O(logn)。2.认识O(logn)
①这是一种极其高效的时间复杂度,有时甚至比O(1)的算法还要高效。为什么?
②因为logn是一个非常“恐怖“的数量级,即便n非常大,对应的logn也很小。比如n等于2的32次方,也就是42亿,而logn才32。
③由此可见,O(logn)有时就是比O(1000),O(10000)快很多。
如果大家伙对时间复杂度不太了解 可以去看一下我之前的博客 有一个专门分析时间复杂度的文章
三、如何实现二分查找?
1.非递归(循环实现)
public int bsearch(int[] a, int n, int value) {
int low = 0;
int high = n - 1;
while (low <= high) {
int mid = (low + high) / 2;
if (a[mid] == value) {
return mid;
} else if (a[mid] < value) {
low = mid + 1;
} else {
high = mid - 1;
}
}
return -1;
}
2.递归实现
// 二分查找的递归实现
public int bsearch(int[] a, int n, int val) {
return bsearchInternally(a, 0, n - 1, val);
}
private int bsearchInternally(int[] a, int low, int high, int value) {
if (low > high) return -1;
int mid = low + ((high - low) >> 1);
if (a[mid] == value) {
return mid;
} else if (a[mid] < value) {
return bsearchInternally(a, mid+1, high, value);
} else {
return bsearchInternally(a, low, mid-1, value);
}
}
注意事项
1.循环退出条件
注意是low<=high,而不是low<high。
2.mid的取值
实际上,mid=(low+high)/2这种写法是有问题的。因为如果low和high比较大的话,两者之和就有可能会溢出。改进的方法是将mid的计算方式写成low+(high-low)/2。更进一步,如果要将性能优化到极致的话,我们可以将这里的除以2操作转化成位运算 low+((high-low)>>1) [一定要注意这个括号,不然符号优先级就会出问题]。因为相比除法运算来说,计算机处理位运算要快得多。
3.low和high的更新
low=mid+1,high=mid-1。注意这里的+1和-1,如果直接写成low=mid或者high=mid,就可能会发生死循环。比如,当high=3,low=3时,如果a[3]不等于value,就会导致一直循环不退出。
四、使用条件(应用场景的局限性)
二分查找的时间复杂度是O(logn),查找数据的效率非常高。
不过,并不是什么情况下都可以用二分查找,它的应用场景是有很大局限性的。那什么情况下适合用二分查找,什么情况下不适合呢?
1.顺序表结构
二分查找依赖的是顺序表结构,即数组。
2.有序数据
二分查找针对的是有序数据,因此只能用在插入、删除操作不频繁,一次排序多次查找的场景中。
3.数据量太小
数据量太小不适合二分查找,与直接遍历相比效率提升不明显。但有一个例外,就是数据之间的比较操作非常费时,比如数组中存储的都是长度超过300的字符串,那这是还是尽量减少比较操作使用二分查找吧。
4.数据量太大
数据量太大也不是适合用二分查找,因为数组需要连续的空间,若数据量太大,往往找不到存储如此大规模数据的连续内存空间。
五、四种常见的二分查找变形问题
1.查找第一个值等于给定值的元素
如果我们查找的是任意一个值等于给定值的元素,当a[mid]等于要查找的值时,a[mid]就是我们要找的元素。但是,如果我们求解的是第一个值等于给定值的元素,当a[mid]等于要查找的值时,我们就需要确认一下这个a[mid]是不是第一个值等于给定值的元素。
public int bsearch(int[] a, int n, int value) {
int low = 0;
int high = n - 1;
while (low <= high) {
int mid = low + ((high - low) >> 1);
if (a[mid] > value) {
high = mid - 1;
} else if (a[mid] < value) {
low = mid + 1;
} else {
// 比如 数组为{0 1 2 3 4 5 **5** 5 6 7 8 9 10} 表*是第一次遇到的 但是 它不是我们需要的第一个
if ((mid == 0) || (a[mid - 1] != value)) return mid; //如果当前位置是第一个 那么就是最前的
//或者 如果 当前值 不是第一个 那么接着循环一次 然后 找到第一个为止
else high = mid - 1;
}
}
return -1;
}
2.查找最后一个值等于给定值的元素
public int bsearch(int[] a, int n, int value) {
int low = 0;
int high = n - 1;
while (low <= high) {
int mid = low + ((high - low) >> 1);
if (a[mid] > value) {
high = mid - 1;
} else if (a[mid] < value) {
low = mid + 1;
} else {
if ((mid == n - 1) || (a[mid + 1] != value)) return mid;
else low = mid + 1;
}
}
return -1;
}
我们还是重点看第11行代码。如果a[mid]这个元素已经是数组中的最后一个元素了,那它肯定是我们要找的;如果a[mid]的后一个元素a[mid+1]不等于value,那也说明a[mid]就是我们要找的最后一个值等于给定值的元素。
如果我们经过检查之后,发现a[mid]后面的一个元素a[mid+1]也等于value,那说明当前的这个a[mid]并不是最后一个值等于给定值的元素。我们就更新low=mid+1,因为要找的元素肯定出现在[mid+1, high]之间。
3.查找第一个大于等于给定值的元素
现在我们再来看另外一类变形问题。在有序数组中,查找第一个大于等于给定值的元素。比如,数组中存储的这样一个序列:3,4,6,7,10。如果查找第一个大于等于5的元素,那就是6。
public int bsearch(int[] a, int n, int value) {
int low = 0;
int high = n - 1;
while (low <= high) {
int mid = low + ((high - low) >> 1);
if (a[mid] >= value) {
if ((mid == 0) || (a[mid - 1] < value)) return mid;
else high = mid - 1;
} else {
low = mid + 1;
}
}
return -1;
}
如果a[mid]小于要查找的值value,那要查找的值肯定在[mid+1, high]之间,所以,我们更新low=mid+1。
对于a[mid]大于等于给定值value的情况,我们要先看下这个a[mid]是不是我们要找的第一个值大于等于给定值的元素。如果a[mid]前面已经没有元素,或者前面一个元素小于要查找的值value,那a[mid]就是我们要找的元素。这段逻辑对应的代码是第7行。
如果a[mid-1]也大于等于要查找的值value,那说明要查找的元素在[low, mid-1]之间,所以,我们将high更新为mid-1。
4.查找最后一个小于等于给定值的元素
现在,我们来看最后一种二分查找的变形问题,查找最后一个小于等于给定值的元素。比如,数组中存储了这样一组数据:3,5,6,8,9,10。最后一个小于等于7的元素就是6。是不是有点类似上面那一种?实际上,实现思路也是一样的。
有了前面的基础,你完全可以自己写出来了,所以我就不详细分析了。我把代码贴出来,你可以写完之后对比一下。
public int bsearch7(int[] a, int n, int value) {
int low = 0;
int high = n - 1;
while (low <= high) {
int mid = low + ((high - low) >> 1);
if (a[mid] > value) {
high = mid - 1;
} else {
if ((mid == n - 1) || (a[mid + 1] > value)) return mid;
else low = mid + 1;
}
}
return -1;
}
六、适用性分析
1.凡事能用二分查找法解决的,绝大部分我们更倾向于用散列表或者二叉查找树,即便二分查找在内存上更节省,但是毕竟内存如此紧缺的情况并不多。
2.求“值等于给定值”的二分查找确实不怎么用到,二分查找更适合用在**”近似“**查找问题上。比如上面讲几种变体(第五点)。
注意:
变体的二分查找算法写起来非常烧脑,很容易因为细节处理不好而产生Bug,这些容易出错的细节有:终止条件、区间上下界更新方法、返回值选择。
七。推荐题目
二分查找
https://pintia.cn/problem-sets/15/problems/923
本题要求实现二分查找算法。
函数接口定义:
Position BinarySearch( List L, ElementType X );
其中List结构定义如下:
typedef int Position;
typedef struct LNode *List;
struct LNode {
ElementType Data[MAXSIZE];
Position Last; /* 保存线性表中最后一个元素的位置 */
};
L是用户传入的一个线性表,其中ElementType元素可以通过>、==、<进行比较,并且题目保证传入的数据是递增有序的。函数BinarySearch要查找X在Data中的位置,即数组下标(注意:元素从下标1开始存储)。找到则返回下标,否则返回一个特殊的失败标记NotFound。
裁判测试程序样例:
#include <stdio.h>
#include <stdlib.h>
#define MAXSIZE 10
#define NotFound 0
typedef int ElementType;
typedef int Position;
typedef struct LNode *List;
struct LNode {
ElementType Data[MAXSIZE];
Position Last; /* 保存线性表中最后一个元素的位置 */
};
List ReadInput(); /* 裁判实现,细节不表。元素从下标1开始存储 */
Position BinarySearch( List L, ElementType X );
int main()
{
List L;
ElementType X;
Position P;
L = ReadInput();
scanf("%d", &X);
P = BinarySearch( L, X );
printf("%d\n", P);
return 0;
}
输入样例1:
5
12 31 55 89 101
31
输出样例1:
2
输入样例2:
3
26 78 233
31
输出样例2:
0
Position BinarySearch( List L, ElementType X )
{
int left=1,right=L->Last;
int ans;
while(left<=right)
{
int mid=(left+right)/2;
if(L->Data[mid]==X)
{
ans=mid;
return ans;
}
else if(L->Data[mid]<X)
{
left=mid+1;
}
else if(L->Data[mid]>X)
{
right=mid-1;
}
}
return NotFound;
}














 4622
4622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









