







看的黑马视频记的笔记
目录
1.入门知识点
分布式计算:
概念:
多个计算机合作,共同完成一个计算手段
两种模式:
1.分散-->汇总(聚合)(MapReduce就为该种模式)


2.中心调度-->步骤执行(Spark、Flink)
指挥小弟执行第几阶段、计算完交换数据

MapReduce(分布式计算,分散汇总模式)
概念
MapReduce是“分散->汇总”模式的分布式计算框架,可供开发人员开发相关程序进行分布式数据计算。
MapReduce提供了Map和Reduce2个编程接口:
Map(分散)功能接口提供分散功能,有服务器分布式对数据进行处理
Reduce(汇总)提供聚合功能,将分布式的处理结果汇总统计

执行原理

假设有四台计算机,文件分成三份,三台各自处理数据统计,一台汇总
注:
MapReduce尽管可以通过Java、Python等语言进行程序开发,但当下年代基本没人会写它的代码了,因为太过时了。 尽管MapReduce很老了,但现在仍旧活跃在一线,主要是Apache Hive框架非常火,而Hive底层就是使用的MapReduce。
Yarn(分布式资源调度)
概述
管控整个分布式服务器集群的全部资源,整合进行统一调度,可以提高资源利用率
MapRudece是基于Yarn运行的,YARN用来调度资源给MapReduce分配和管理运行资源
所以,MapReduce需要YARN才能执行(普遍情况)
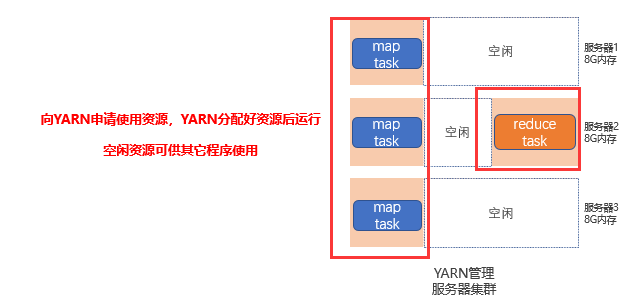
Yarn架构(核心架构+辅助架构)
核心架构(与HDFS非常相似、主从架构)

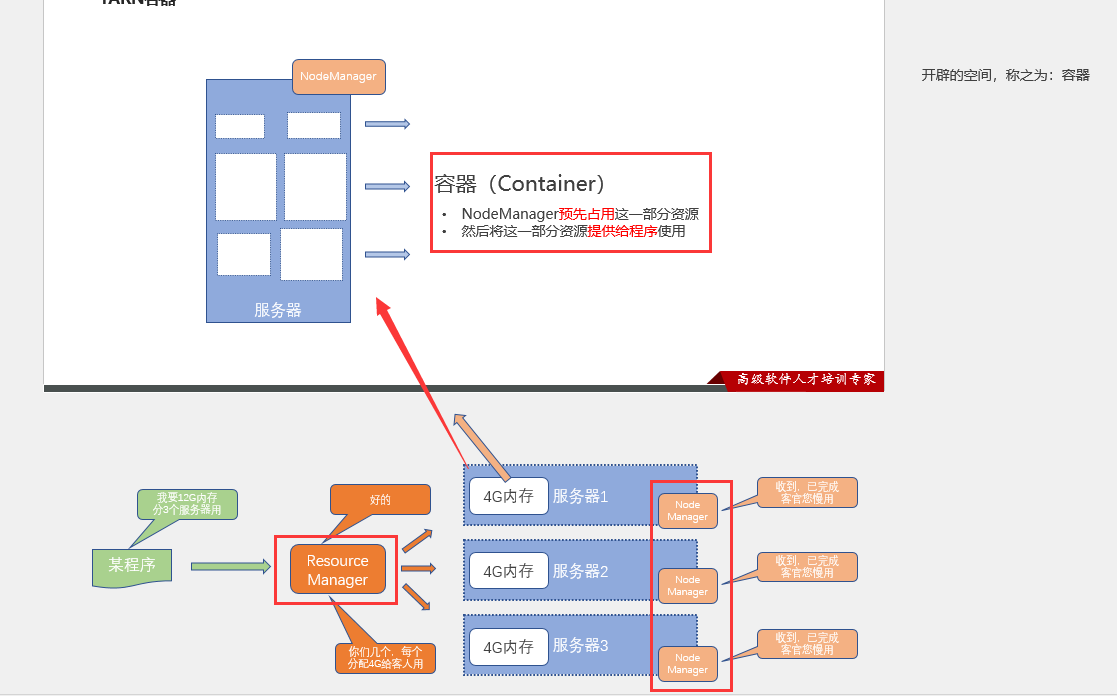
与HDFS非常相似
ResourceManager:整个集群的资源调度者(集群资源的管家),负责协调调度各个程序所需的资源。
NodeManager:单个服务器的资源调度者(单个设备的管家),负责调度单个服务器上的资源提供给应用程序使用。
容器类似于一个集装箱,程序运行在容器内,无法突破容器的资源限制
辅助架构
代理服务器(ProxyServer):给Yarn提供一定的安全保障
JobHistoryServer历史服务器:统一收集到HDFS,由历史服务器托管为WEB UI供用户在浏览器统一查看
管控整个分布式服务器集群的全部资源,整合进行统一调度
2.部署
在node1以hadoop用户做出以下改进:
mapred-env.sh
export JAVA_HOME=/export/server/jdk
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
export HADOOP_MAPRED_ROOT_LOGGER=INFO,RFAmapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description></description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
<description></description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
<description></description>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/data/mr-history/tmp</value>
<description></description>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/data/mr-history/done</value>
<description></description>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
</configuration>yarn-env.sh
export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
# export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
# export YARN_LOG_DIR=$HADOOP_HOME/logs/yarn
export HADOOP_LOG_DIR=$HADOOP_HOME/logsyarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
<description></description>
</property>
<property>
<name>yarn.web-proxy.address</name>
<value>node1:8089</value>
<description>proxy server hostname and port</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>Configuration to enable or disable log aggregation</description>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
<description>Configuration to enable or disable log aggregation</description>
</property>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
<description></description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
<description></description>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/nm-local</value>
<description>Comma-separated list of paths on the local filesystem where intermediate data is written.</description>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data/nm-log</value>
<description>Comma-separated list of paths on the local filesystem where logs are written.</description>
</property>
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>10800</value>
<description>Default time (in seconds) to retain log files on the NodeManager Only applicable if log-aggregation is disabled.</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>Shuffle service that needs to be set for Map Reduce applications.</description>
</property>
</configuration>分发到另外两个节点
node1配置完,为了省事直接分发给node2、node3
scp * node2:`pwd`/
scp * node3:`pwd`/启动YARN
#一键启动YARN集群(可控制resourcemanager、nodemanager、proxyserver三种进程
):
$HADOOP_HOME/sbin/start-yarn.sh
#启动历史服务器
$HADOOP_HOME/bin/mapred --daemon start historyserver
jps


启动WEB UI页面
在浏览器输入http://node1:8088

3.提交自带MapReduce示例程序到Yarn运行
YARN作为资源调度管控框架,其本身提供资源供许多程序运行,常见的有:
-
MapReduce程序
-
Spark程序
-
Flink程序
wordcount
这些内置的示例MapReduce程序代码,都在:$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar文件内。
可以通过 hadoop jar 命令来运行它,提交MapReduce程序到YARN中。
#在/export操作
vim words.txt
#填入
itheima itcast itheima itcast
hadoop hdfs hadoop hdfs
hadoop mapreduce hadoop yarn
itheima hadoop itcast hadoop
itheima itcast hadoop yarn mapreduce
hadoop fs -mkdir -p /input/wordcount
hadoop fs -mkdir /output
hadoop fs -put words.txt /input/wordcount/
#提交示例MapReduce程序WordCount到YARN中执行
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount hdfs://node1:8020/input/wordcount/ hdfs://node1:8020/output/wc1
#参数
参数wordcount,表示运行jar包中的单词计数程序(Java Class)
参数1是数据输入路径(hdfs://node1:8020/input/wordcount/)
参数2是结果输出路径(hdfs://node1:8020/output/wc1), 需要确保输出的文件夹不存在
提交程序后,可以在YARN的WEB UI页面看到运行中的程序(http://node1:8088/cluster/apps)

查看结果:
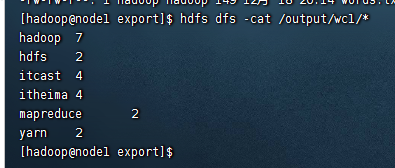
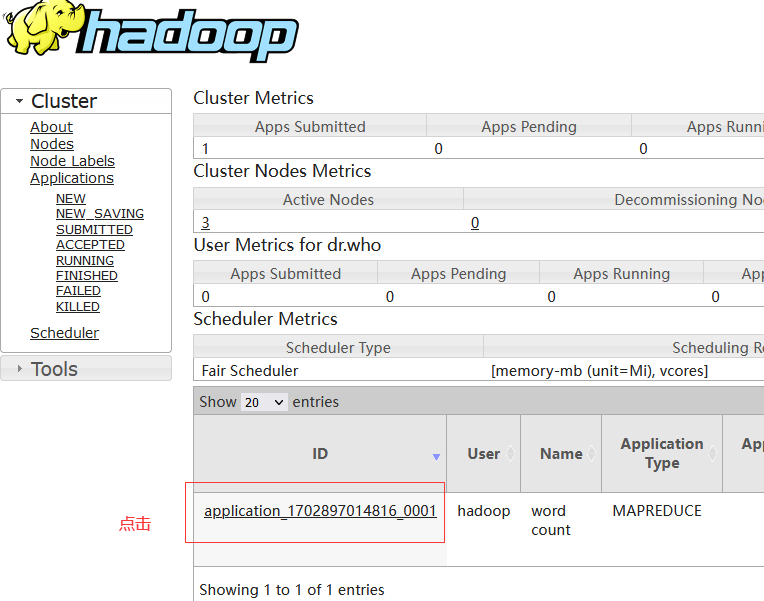
查看到详细的运行日志信息

求圆周率
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar pi 3 1000
#参数pi表示要运行的Java类,这里表示运行jar包中的求pi程序
#参数3,表示设置几个map任务
#参数1000,表示模拟求PI的样本数(越大求的PI越准确,但是速度越慢)
















 1315
1315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









