






由于英文字符每个占一字节,汉字则一个占两字节,C++的string对于中文字符的处理一直是 差强人意,尤其是针对汉英混合的字符串进行截取,更容易出现乱码的现象,因此我们可以使用wstring(宽字符)进行处理。
一、差异:
wstring是宽字符,占用2个字节的大小,即16bit;string是窄字符,占用1个字节的大小,即8bit。
wstring一般针对UNICODE编码格式,一个单元一个char;string一般针对ASCII编码格式,一个单元两个char。
/ /关于Unicode可以自行百度。
二、例子:
下面以英文字符串(hellow world) 和汉字(这是一个示例程序)举例:
1、使用string处理:
#include <iostream>
#include <string>
using namespace std;
int main()
{
string a;
getline(cin, a);
cout << a<<endl;
cout << a.substr(5, 5);
}输出结果:
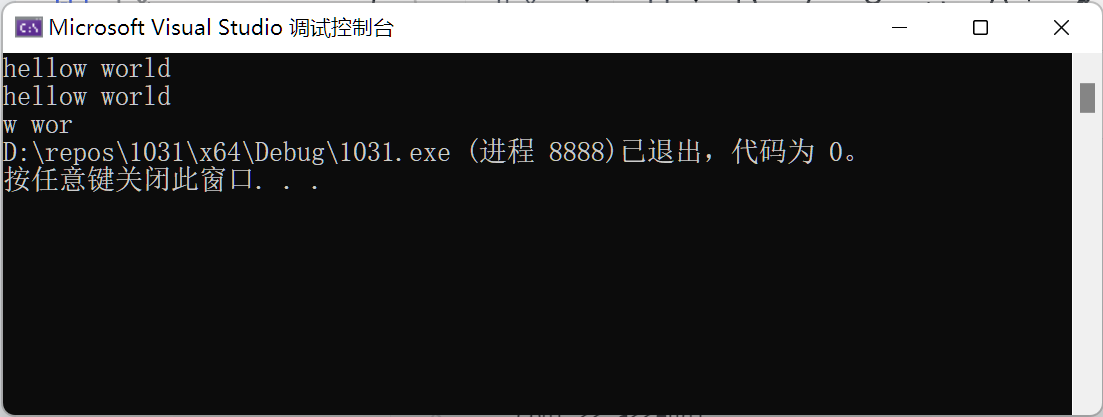
可以看到汉字的截取发生乱码,因为一个汉字2字节,从第5开始截取5个则截取了半个汉字。
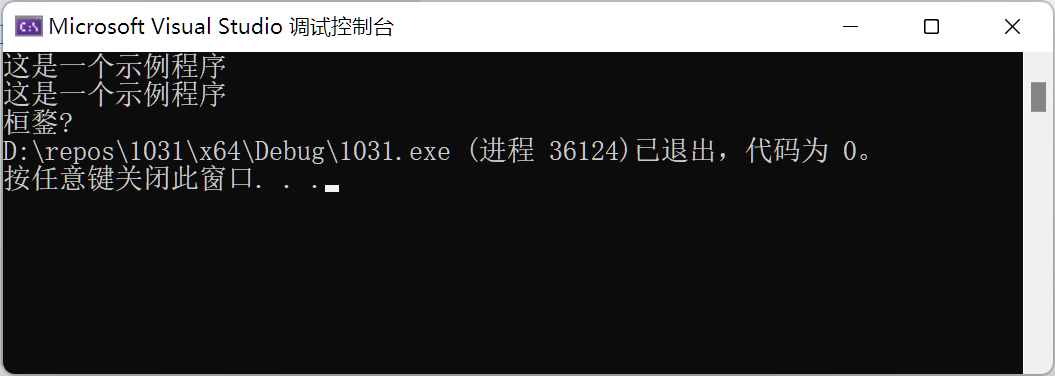
将 cout << a.substr(5, 5);改为 cout << a.substr(4,4);则结果为:
可见截取4字节,即截取了两个汉字。
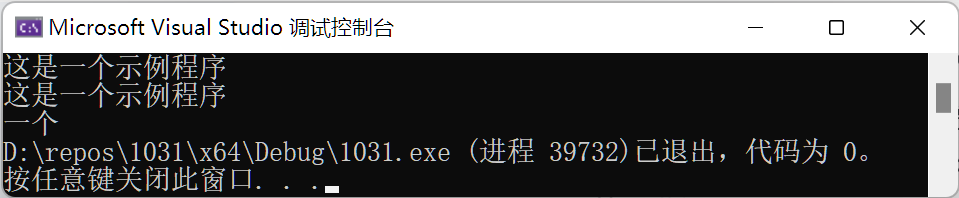
同时针对string的字符处理也容易出现问题,例如s.find(str);如图:

因此可以使用wstring去简化中英混合字符串的判断。
2、wstring
2.1 wstring与string相似,可以使用wcin、wcout、getline(wcin,wstr)以及stoi,string类的操作;并同时提供了相互转换的方法:
wstring wstr1;
wstring_convert<codecvt_utf8<wchar_t>> convert; //定义转换器
string str = convert.to_bytes(wstr1); //wstring-->string
wstring str2 = convert.from_bytes(str); //string-->wstring2.2 针对于wcin、wcout,需要进行locale地域设置,才能使其按照相应的编码方式进行输入输出:
wcout.imbue(locale(""));
wcin.imbue(locale(""));
//针对全局:
locale old=locale::global(locale(""));//设置全局并记录旧的方便还原
locale::global(old);//命令执行完后还原旧的避免影响其他部分(仅针对输入输出流设置可以减小对于程序其他部分的影响)
2.3 将wstring设为汉语时,前面需加L:wstring wstr=L“你好”。
2.4 使用wstring处理示例:
#include <iostream>
#include <string>
using namespace std;
int main()
{
wcout.imbue(locale(""));
wcin.imbue(locale(""));
wstring a;
getline(wcin, a);
wcout << a<<endl;
wcout << a.substr(5,5);
}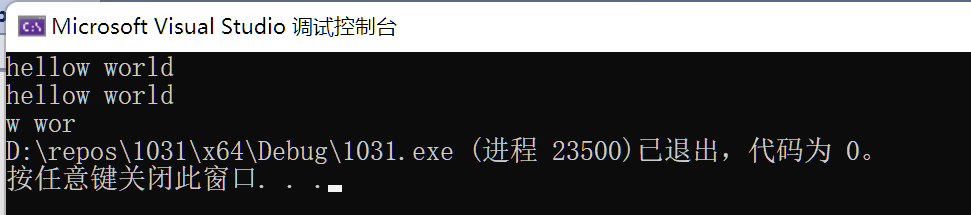

PS:如果不进行地域限制,则返回值仍然是乱码。
作为刚学C++的菜鸡,这些都是自己查到问到的,欢迎各位指正以及补充!!
















 3203
3203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









