







flair是一个开源的自然语言处理(NLP)框架,旨在为研究人员提供用于各种文本分析任务的灵活高效的工具集。flair的框架构建在PyTorch上,支持多种NLP常见应用场景,例如命名实体识别(NER)、情感分析、词性标记(PoS)、语义消歧和分类。
https://github.com/flairNLP/flair![]() https://github.com/flairNLP/flair
https://github.com/flairNLP/flair
目录
一、本地验证
1、本地环境搭建
1.1 创建环境
conda创建python3.9环境。
conda create --name flair python=3.91.2 安装flair
从 GitHub 拉取代码。
git clone https://github.com/flairNLP/flair.git
cd flair直接按照文件安装依赖后续会报错,
AttributeError: 'LSTM' object has no attribute '_flat_weights'需要将requirements.txt文件中pytorch版本更改一下。
# torch>=1.5.0,!=1.8 改为
torch==1.11.0之后再安装依赖。
pip install -r requirements.txt
pip install gensim1.3 下载预训练模型
1.3.1 下载预训练模型
直接运行README中的示例代码会报错,
ValueError: Could not find any model with name 'ner'找不到对应的模型,需要先下载预训练模型到本地,代码中加载模型改为加载模型路径。
SequenceTagger.load(model_path)由于Hugging Face不支持国内访问,无法直接下载预训练模型,
huggingface_hub.utils._errors.LocalEntryNotFoundError: An error happened while trying to locate the file on the Hub and we cannot find the requested files in the local cache. Please check your connection and try again or make sure your Internet connection is on.可以使用梯子或者手动下载模型到本地。这里使用手动下载模型到本地文件夹models。
本次命名实体识别使用模型:
'ner': 'https://nlp.informatik.hu-berlin.de/resources/models/ner/en-ner-conll03-v0.4.pt'
使用wget下载。
mkdir models
cd models/
wget https://nlp.informatik.hu-berlin.de/resources/models/ner/en-ner-conll03-v0.4.pt1.3.2 使用Hugging Face的国内镜像下载token分词器。
在环境中设置 HF_ENDPOINT 环境变量,指向 Hugging Face 的国内镜像地址:
windows:
set HF_ENDPOINT=https://hf-mirror.commacOS/Linux:
export HF_ENDPOINT=https://hf-mirror.com 使用 huggingface-cli 命令行工具来下载模型。
huggingface-cli download distilbert-base-uncased2、构建本地示例应用
2.1 使用flair进行命名实体识别:
新建run_ner.py文件内容为:
from flair.data import Sentence
from flair.models import SequenceTagger
# 加载命名实体识别模型和情感分析模型
tagger = SequenceTagger.load("./models/en-ner-conll03-v0.4.pt")
# 输入语句
print('Please enter the sentence to be analyzed:')
inputs=input()
# NER
tagger_sentence = Sentence(inputs)
tagger.predict(tagger_sentence)
print(tagger_sentence.labels)输出:
2024-10-16 10:01:08,847 SequenceTagger predicts: Dictionary with 20 tags: <unk>, O, S-ORG, S-MISC, B-PER, E-PER, S-LOC, B-ORG, E-ORG, I-PER, S-PER, B-MISC, I-MISC, E-MISC, I-ORG, B-LOC, E-LOC, I-LOC, <START>, <STOP>
Please enter the sentence to be analyzed:
Our family took a trip to Washington DC and Hawaii this summer and it was a memorable one.
['Span[6:8]: "Washington DC"'/'LOC' (0.8451), 'Span[9:10]: "Hawaii"'/'LOC' (1.0)]2.2 使用gradio构建Web应用界面
安装gradio库。
pip install gradio编写Python函数来处理输入句子,并调用flair的实体提取。在界面中定义输入组件和输出组件,以接收用户输入的句子并显示实体提取的结果。
新建gradio_show.py文件内容为:
import gradio as gr
from flair.data import Sentence
from flair.models import SequenceTagger
# 加载命名实体识别模型和情感分析模型
tagger = SequenceTagger.load("./models/en-ner-conll03-v0.4.pt")
def analyze_sentence(input_text):
# 创建Sentence对象
tagger_sentence = Sentence(input_text)
# 使用命名实体识别模型进行预测
tagger.predict(tagger_sentence)
# 提取NER结果
ner_result = "\n".join([str(label) for label in tagger_sentence.labels])
return ner_result
# 创建Gradio界面
iface = gr.Interface(
fn=analyze_sentence,
inputs=gr.Textbox(label="Enter a sentence"),
outputs=[
gr.Textbox(label="Named Entities"),
],
examples=[
["Our family took a trip to Washington DC and Hawaii this summer and it was a memorable one.",]
],
title="Sentence Analysis with Flair",
description="Input a sentence and see the named entities and sentiment analysis results."
)
# 启动Gradio应用
iface.launch()启动Gradio应用,并在浏览器中访问其界面以进行测试。
2024-10-16 10:09:17,121 SequenceTagger predicts: Dictionary with 20 tags: <unk>, O, S-ORG, S-MISC, B-PER, E-PER, S-LOC, B-ORG, E-ORG, I-PER, S-PER, B-MISC, I-MISC, E-MISC, I-ORG, B-LOC, E-LOC, I-LOC, <START>, <STOP>
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.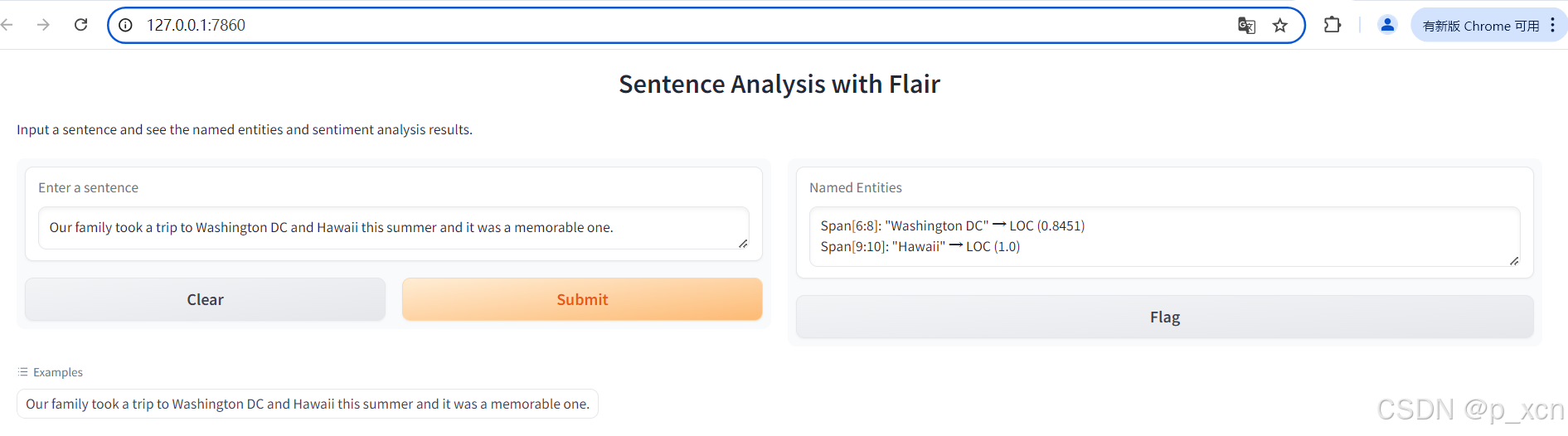
二、使用华为云服务运行代码
1、搭建鲲鹏ECS环境
-
由于昇腾NPU资源售罄,所以本次是在鲲鹏CPU和Euler 操作系统上进行部署。
- 以下创建所有云服务的区域需保持一致,这里统一选择:华北-北京四。
1.1 创建虚拟私有云VPC
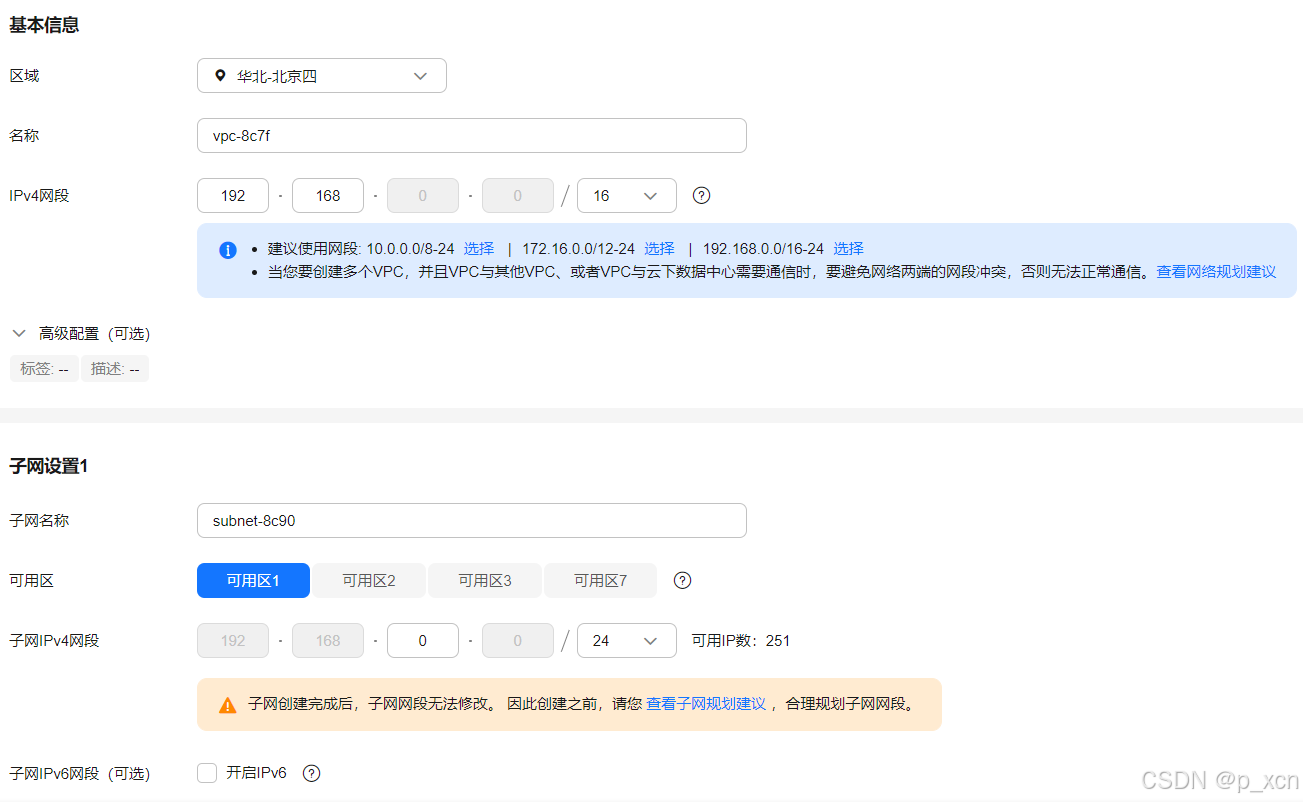
在控制台点开左上角搜索到虚拟私有云VPC,点击创建虚拟私有云。
配置概要:
区域:华北-北京四
名称:自定义
IPv4网段:选择192.168.0.0/16
子网名称:自定义
可用区:可用区1
其他设为默认。
参考文档:
1.2 创建弹性云服务器ECS
参考文档:
快速购买和使用Linux ECS_弹性云服务器 ECS_华为云
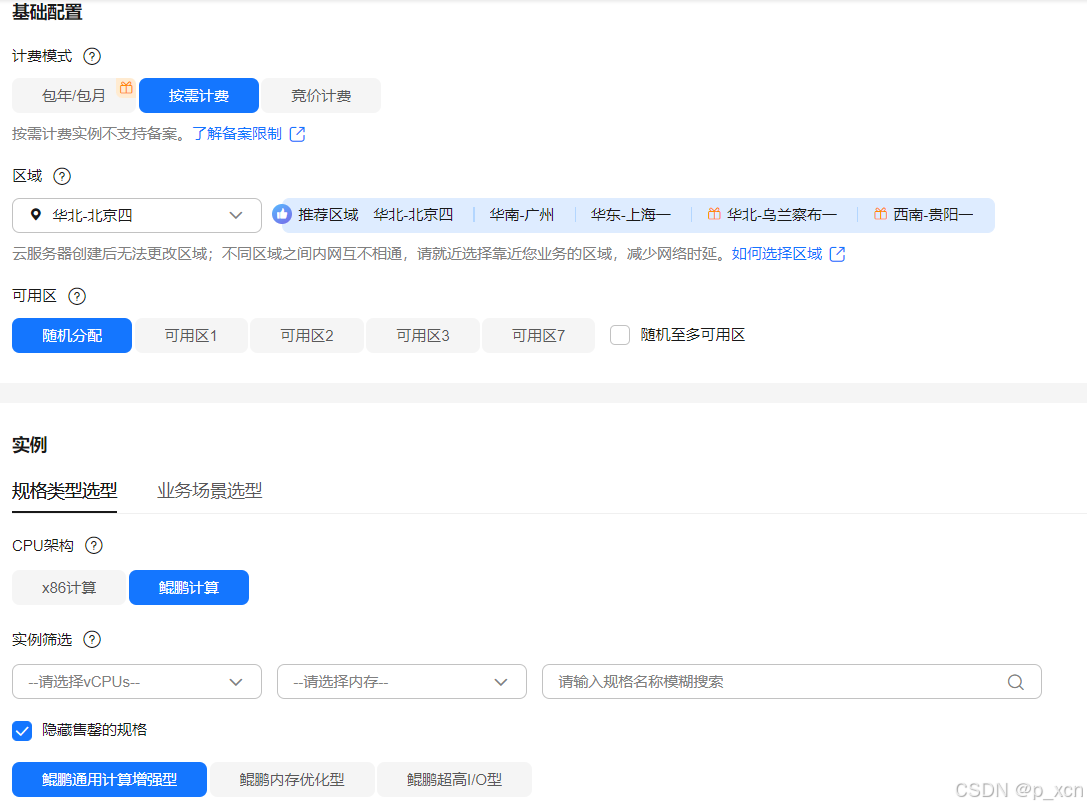
配置概要:
基础配置
计费模式: 按需计费
区域/可用区: 华北-北京四 | 随机分配
实例
规格: 鲲鹏通用计算增强型 | kc1.large.4 | 2vCPUs | 8GiB
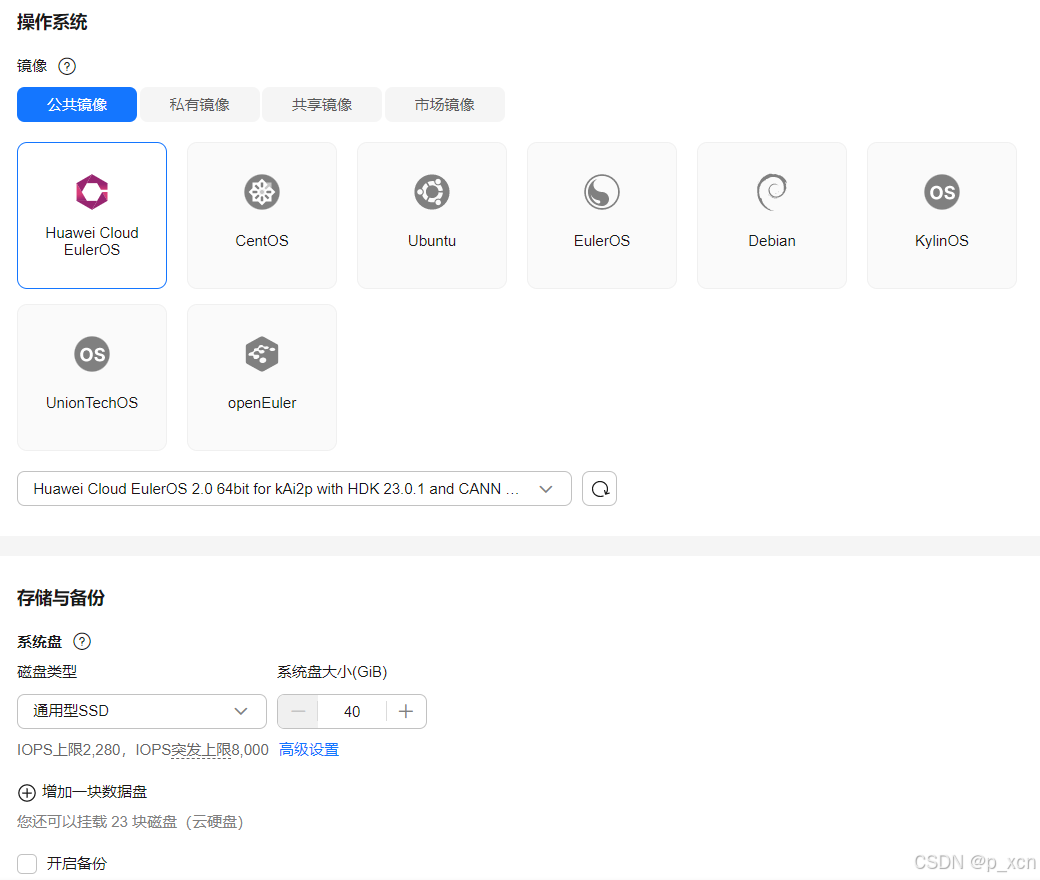
操作系统
镜像: Huawei Cloud EulerOS 2.0 64bit for kAi2p with HDK 23.0.1 and CANN 7.0.0.1 RC
存储与备份
系统盘: 通用型SSD, 40GiB
网络
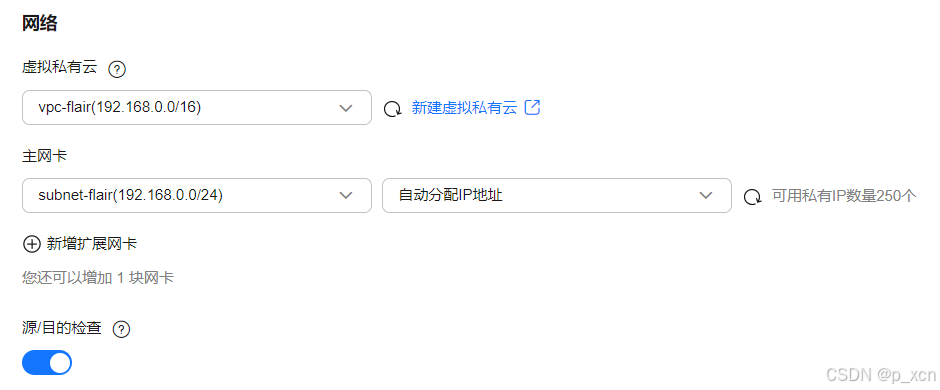
虚拟私有云: 选择上一步所创建VPC
源/目的检查: 开启
安全组
default
公网访问
弹性公网IP: 全动态BGP | 按流量计费 | 1 Mbit/s
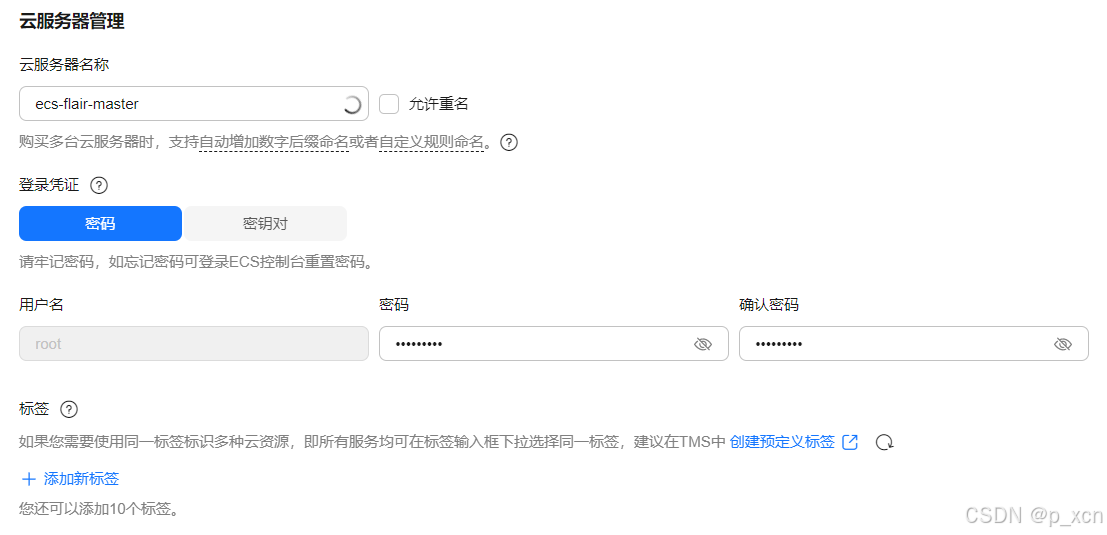
云服务器管理
云服务器名称: 自定义
登录凭证: 密码
其他设为默认。
点击立即创建,跳转回弹性云服务器列表,所创建ECS状态由创建中变为运行中即为创建成功。

1.3 登录ECS
点击弹性云服务器列表中相应服务器操作下的远程登陆,
选择使用CloudShell登录。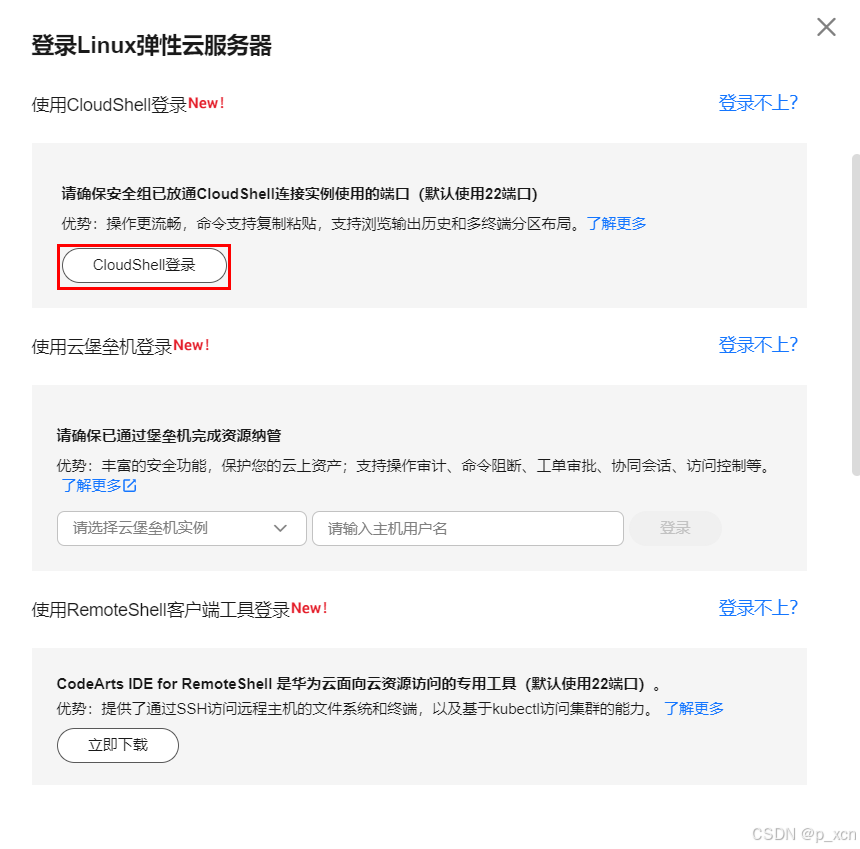
输入创建云服务器时设置的密码,点击连接。这里也能看到后续开放端口需要使用的公网IP。
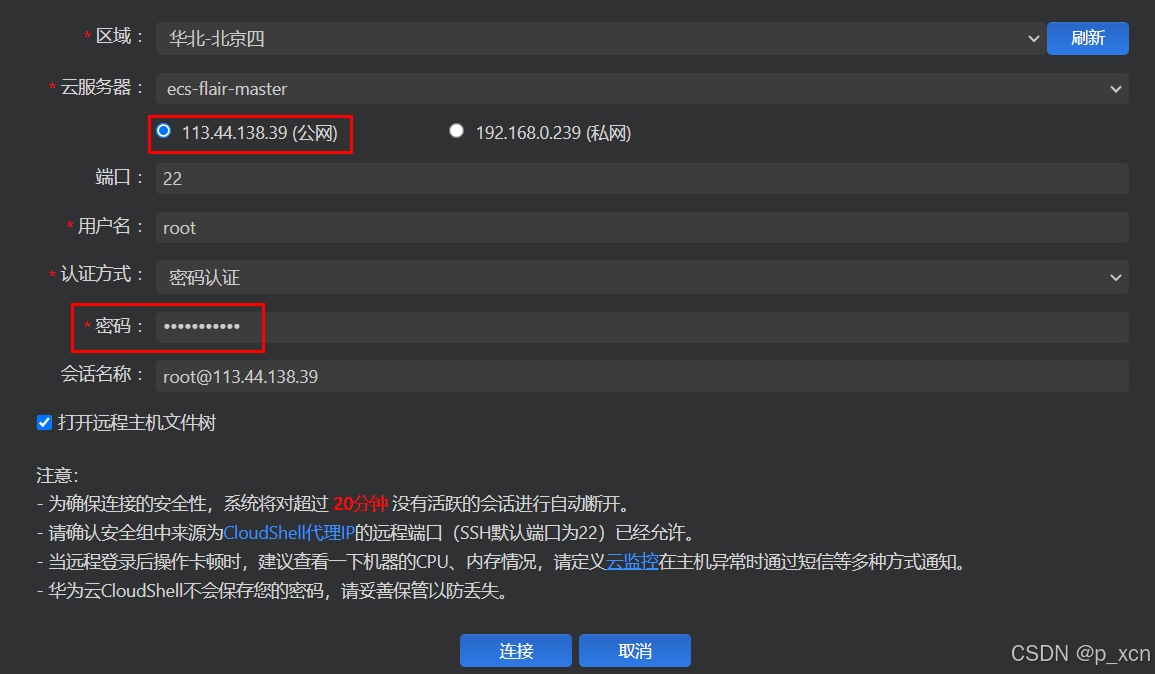
进入服务器界面。
2、ECS环境下运行代码
2.1 参照本地验证步骤搭建环境
环境依赖安装和token分词器下载步骤与本地验证时一致。右键上传文件。
运行推理代码run_ner.py,能够正常进行

- 如果出现报错:
ImportError: cannot import name 'soft_unicode' from 'markupsafe' (/usr/local/lib64/python3.9/site-packages/markupsafe/__init__.py)更新一个与Jinja2兼容的markupsafe版本即可
pip install markupsafe==2.0.1 - 如果出现报错:
huggingface_hub.errors.HFValidationError: Repo id must be in the form 'repo_name' or 'namespace/repo_name': './models/en-ner-conll03-v0.4.pt'. Use `repo_type` argument if needed.模型的路径只能是单层目录或两层目录,需移动到项目路径下或更改模型路径。
3、构建服务器示例应用
3.1 将 Gradio 绑定到服务器的公网 IP 地址
直接在ECS环境下运行本地验证的示例应用文件gradio_show.py,会发现打开的URL是一个无法访问的地址https://console.huaweicloud.com+端口号。
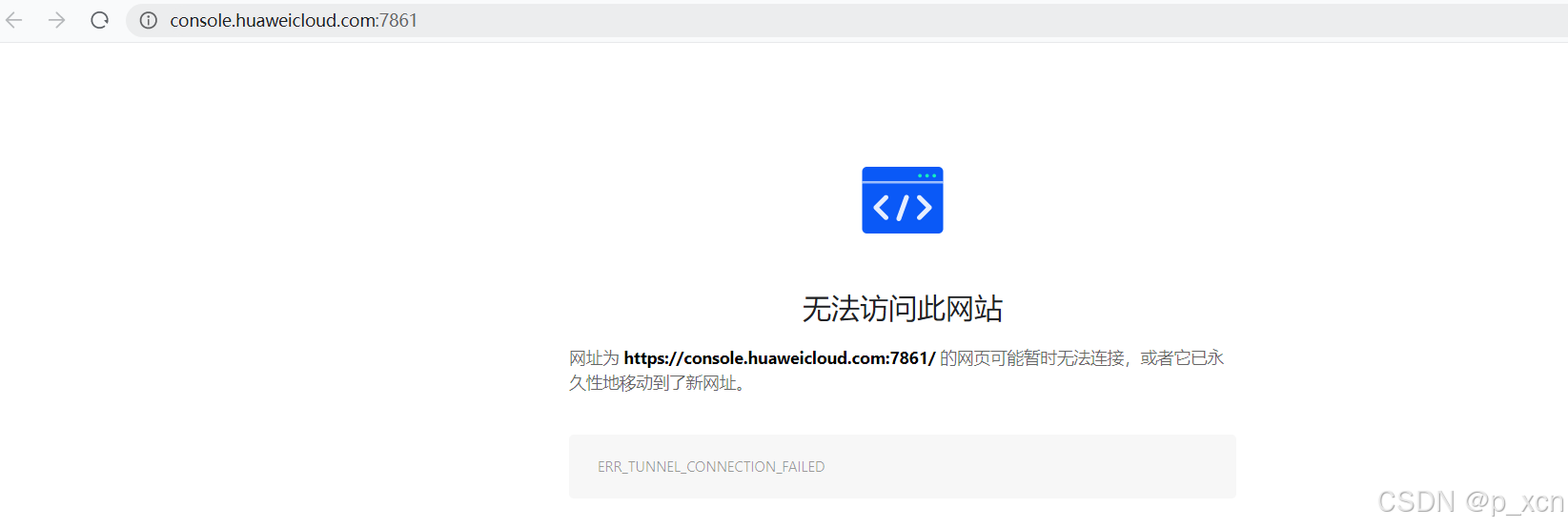
这是因为在 ECS 服务器上运行 Gradio 应用时,默认情况下Gradio 会绑定到 127.0.0.1,这意味着它只能在服务器本地访问。为了从外部访问 Gradio 应用,需要将 Gradio 绑定到服务器的公网 IP 地址或所有网络接口。
查看弹性公网IP和设置开放端口流程参考:查看华为云ECS弹性公网IP和设置开放端口-CSDN博客
改写ECS云服务器中的gradio_show.py文件:
# # 启动Gradio应用
# iface.launch()
# 改为
iface.launch(server_name="0.0.0.0", server_port=7860)运行文件:

通过以下 URL 访问 gradio 应用:
http://113.44.138.39:7860/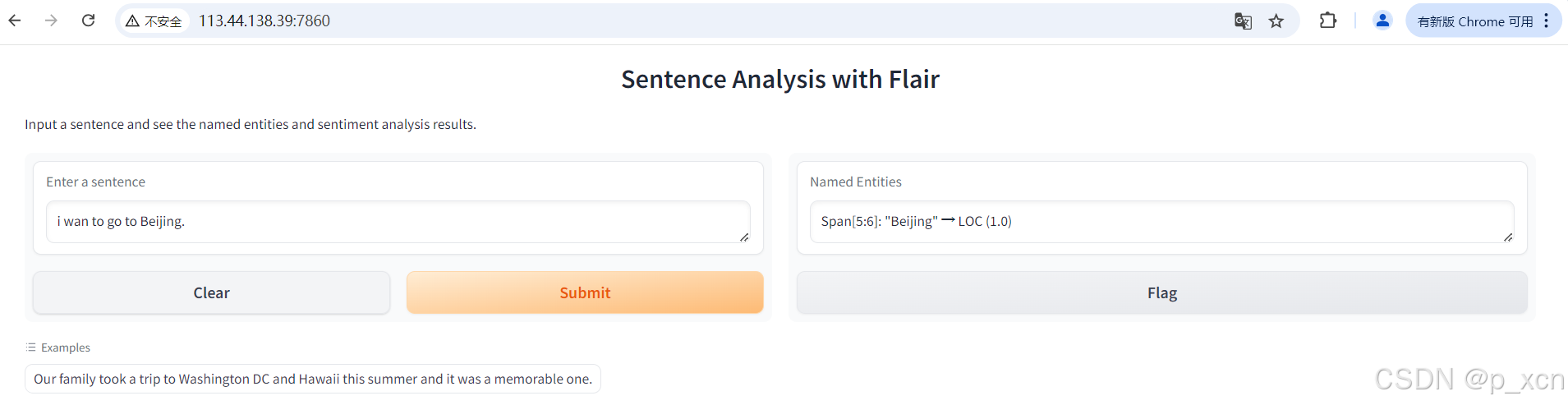
3.2 持续运行进程
如需让进程在用户退出终端后继续运行,可以使用nohup 命令:
nohup python gradio_show.py三、使用昇腾NPU进行环境搭建
昇腾环境:
芯片类型:昇腾910B3
CANN版本:CANN 7.0.1.5
驱动版本:23.0.6
操作系统:Huawei Cloud EulerOS 2.0
1.查看NPU硬件信息
使用 npu-smi 命令来查看 NPU 的硬件信息。
npu-smi info
如果 Health 状态为 OK,说明 NPU 和 CANN 正常运行。
2.NPU环境下运行代码
2.1 参照本地验证步骤搭建环境
环境依赖安装和token分词器下载步骤与本地验证时一致。
安装torch相应版本的torch_npu:pytorch 发行版 - Gitee.com。
wget https://gitee.com/ascend/pytorch/releases/download/v6.0.rc2.1-pytorch1.11.0/torch_npu-1.11.0.post15-cp39-cp39-linux_aarch64.whl
pip install torch_npu-1.11.0.post15-cp39-cp39-linux_aarch64.whl2.2 验证NPU环境
新建测试verify_npu.py:
import torch
import torch_npu
# 检查 NPU 是否可用
if torch.npu.is_available():
print("NPU is available.")
device = torch.device('npu')
tensor = torch.tensor([1.0, 2.0, 3.0], device=device)
print(tensor)
else:
print("NPU is not available.")输出NPU is available则NPU 环境正常。

2.3 改写代码
直接将模型和句子.to("npu")的话predict步骤会报错:
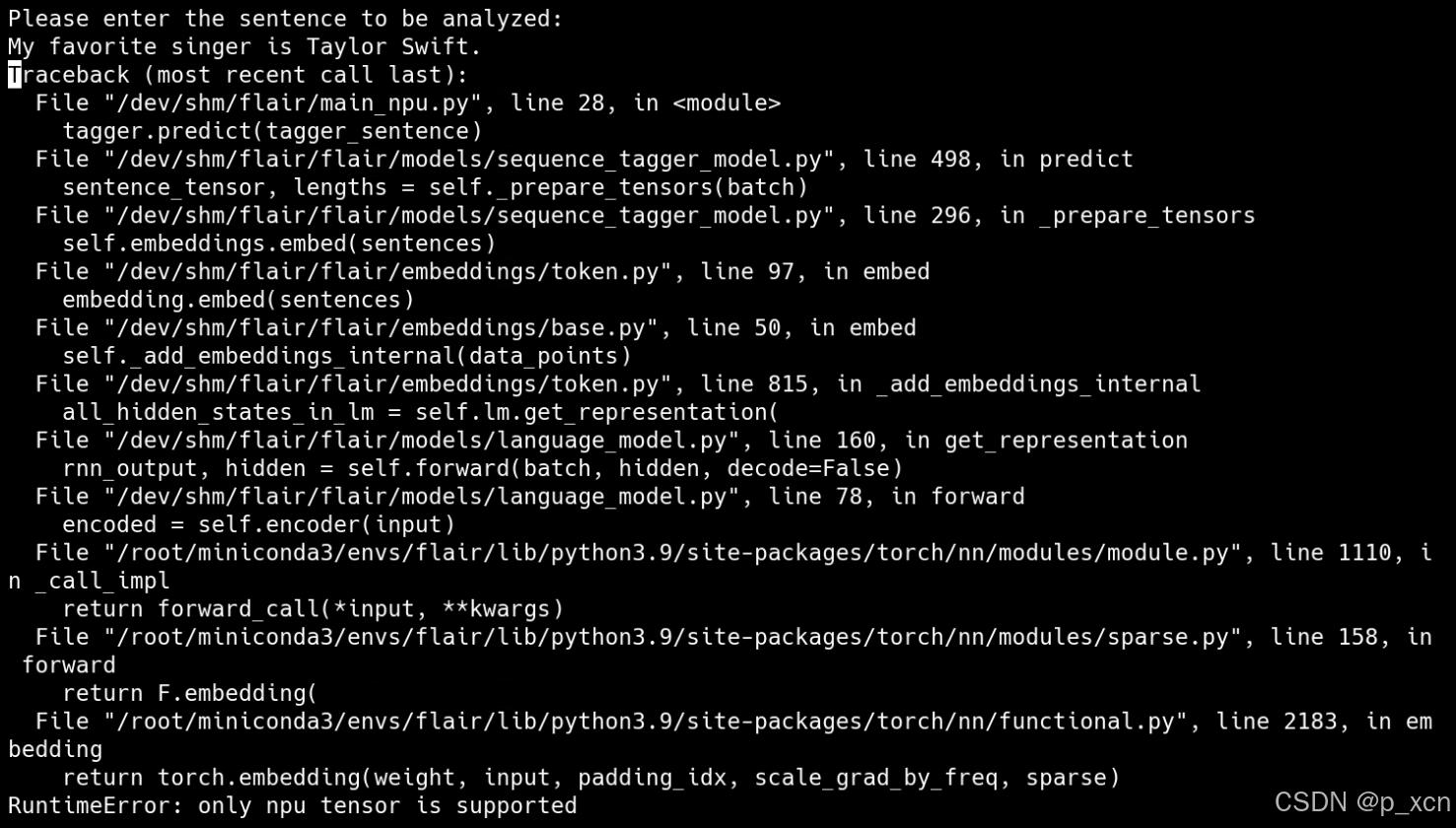
查看flair源码,发现flair原本支持CPU和GPU,init文件中已有属性flair.device,载入模型和创建句子时的init方法最后都会调用to方法移动到设备上,故在最前段加入代码:
import torch
import flair
if torch.npu.is_available():
print("NPU is available.")
flair.device = torch.device('npu')
else:
print("NPU is not available.")
flair.device = torch.device('cpu')这时出现新的报错: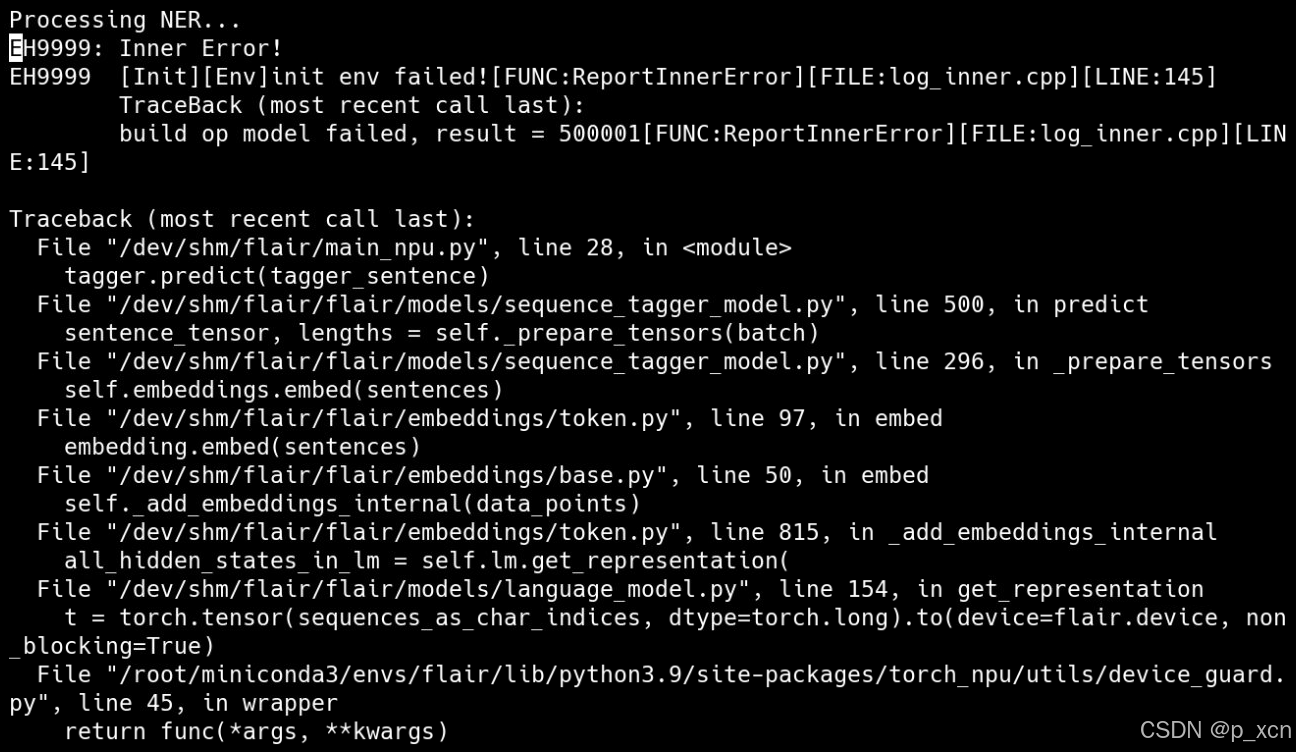
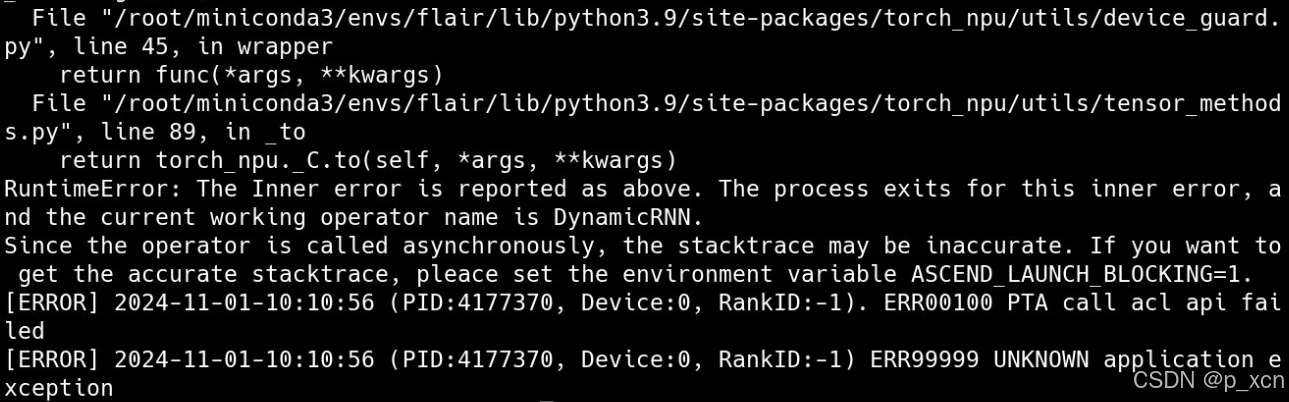
按照提示进行设置,获得准确的堆栈跟踪:
export ASCEND_LAUNCH_BLOCKING=1报错变成了:
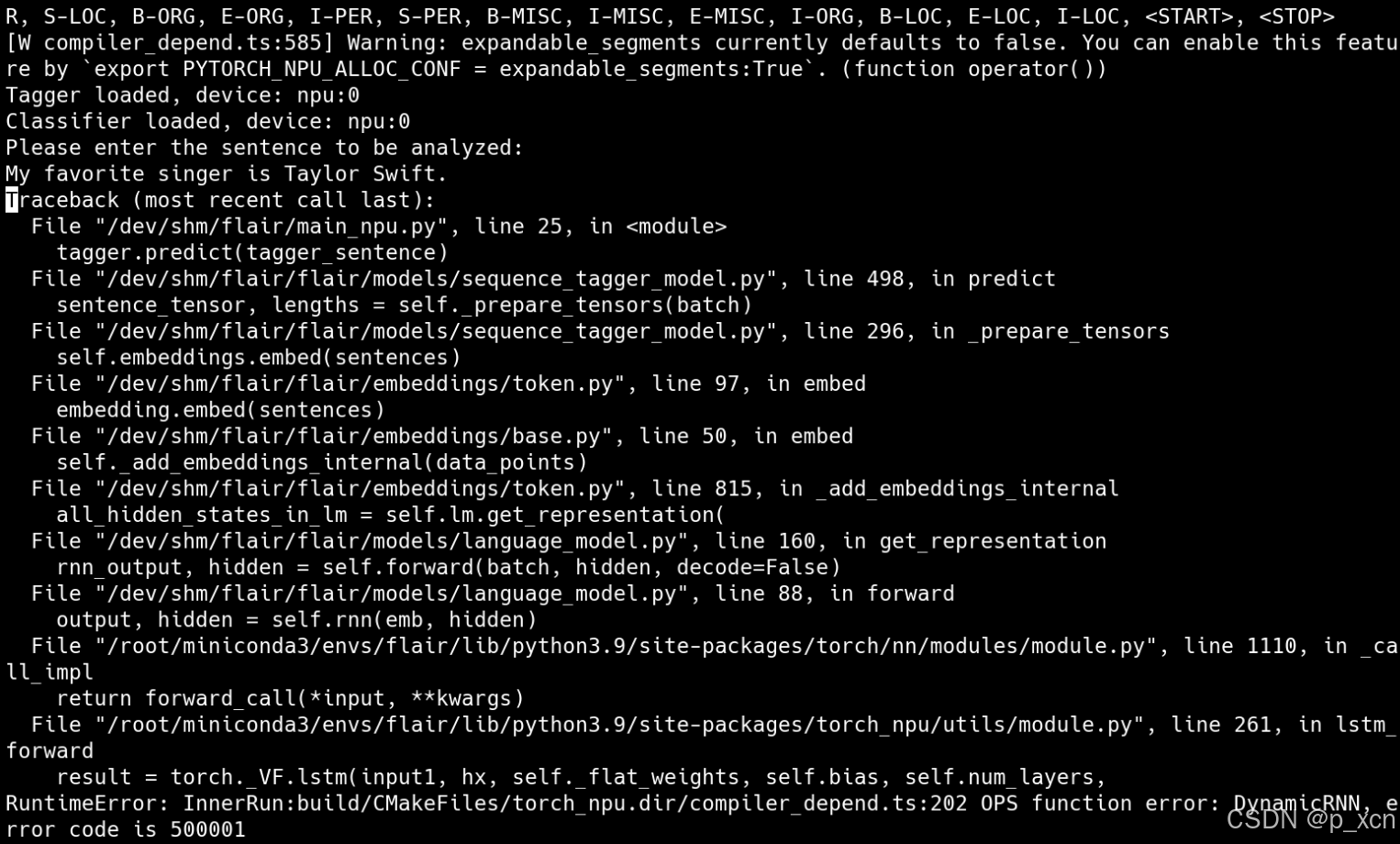
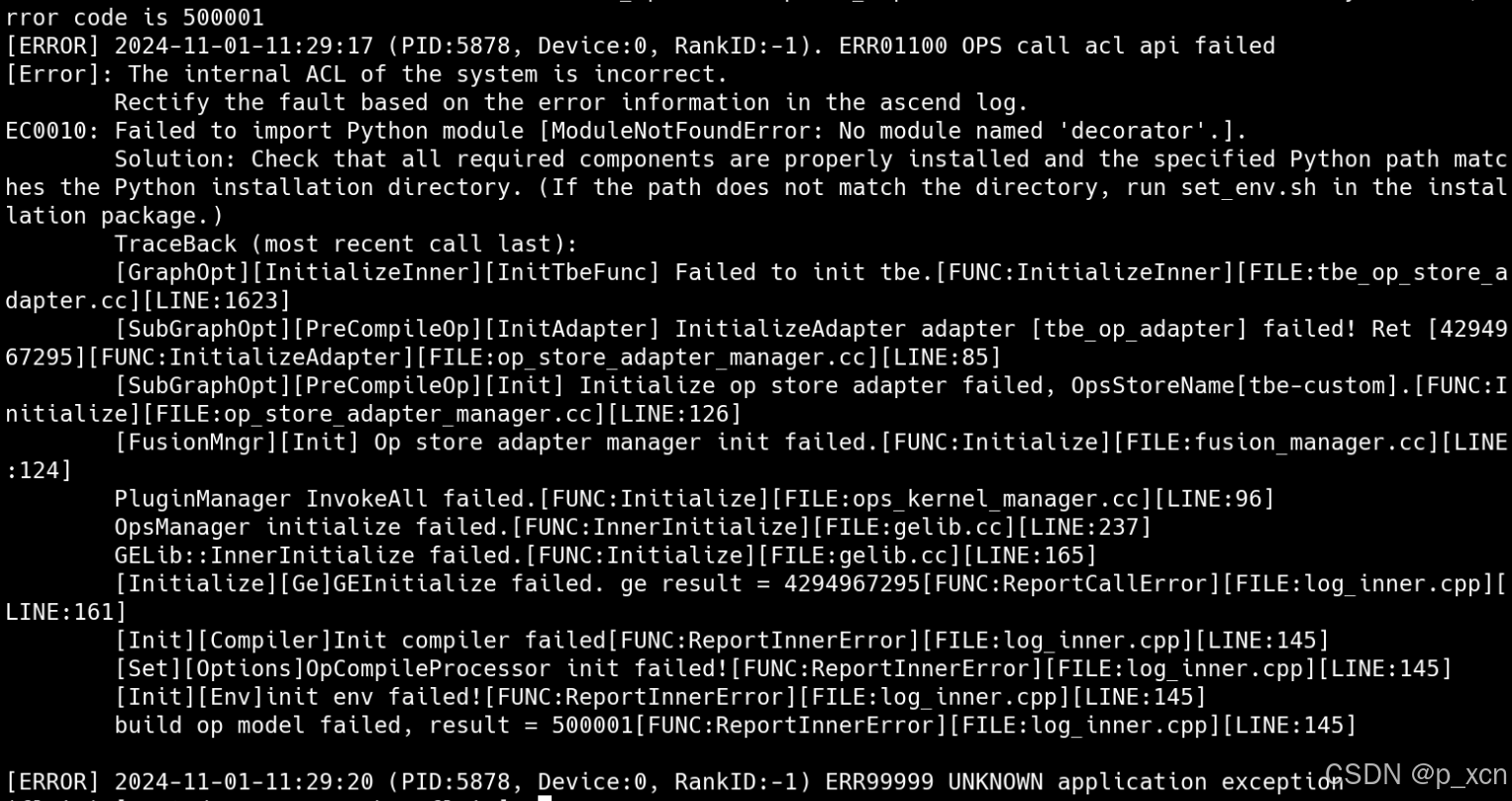
报错提示缺少依赖,所以安装decorator:
pip install decorator 能够正常运行了,第一次启动会比较慢。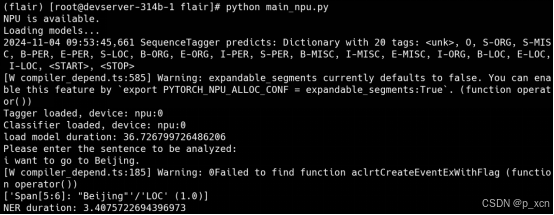
2.4 NPU运行优化
根据错误日志中的警告信息,启用 expandable_segments 功能采用一种更灵活的内存分配方式,允许在运行时动态地扩展内存段。在环境变量中设置:
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True开启后代码运行速度没有明显变化。
2.4.1 转换模型文件
考虑到加载模型用时比较多,所以尝试更改模型文件,来优化NPU上的运行。
新建export_onnx.py文件进行.pt文件到.onnx文件的转换。
import torch
import torch.onnx
from flair.data import Sentence
from flair.models import SequenceTagger
import onnx
import onnxruntime as ort
from typing import Union, Dict, Any, Type, cast, List, Optional
from flair.file_utils import Tqdm, load_torch_state
from pathlib import Path
import pickle
def save_non_model_content_to_pickle(model_file: Union[str, Path]):
"""
从 .pt 文件中提取非模型部分的内容并保存到 Pickle 文件中。
"""
# 加载模型字典
state = load_torch_state(model_file)
# 提取非模型部分的内容
non_model_content = {
"embeddings": state.get("embeddings"),
"tag_dictionary": state.get("tag_dictionary"),
"tag_format": state.get("tag_format", "BIOES"),
"tag_type": state.get("tag_type"),
"use_crf": state.get("use_crf"),
"use_rnn": state.get("use_rnn"),
"reproject_embeddings": state.get("reproject_embeddings", True),
"init_from_state_dict":True
}
# 生成 Pickle 文件路径
pickle_path = model_file.replace(".pt", ".pkl")
# 保存到 Pickle 文件
with open(pickle_path, 'wb') as f:
pickle.dump(non_model_content, f)
model_file='./models/en-ner-conll03-v0.4.pt'
save_non_model_content_to_pickle(model_file)
# 加载模型
tagger = SequenceTagger.load(model_file)
tagger.eval()
# print(tagger)
# 创建一个句子对象
sentence = Sentence("This is a sample sentence.")
# 使用模型的嵌入层获取输入张量
tagger.embeddings.embed(sentence)
# 获取每个 token 的嵌入向量
tagger_tensor = [token.embedding for token in sentence]
tagger_tensor = torch.stack(tagger_tensor).unsqueeze(0) # 添加批次维度
# 获取句子的长度
tagger_lengths = torch.tensor([len(sentence)], dtype=torch.long)
# 打印输入张量的形状和类型
print("Input Tensor Shape:", tagger_tensor.shape)
print("Input Tensor Type:", tagger_tensor.dtype)
print("Lengths Shape:", tagger_lengths.shape)
print("Lengths Type:", tagger_lengths.dtype)
# 导出模型
torch.onnx.export(
tagger,
(tagger_tensor, tagger_lengths),
model_file.replace(".pt", ".onnx"),
input_names=["input_tensor", "lengths"],
output_names=["features"],
opset_version=11,
dynamic_axes={
"input_tensor": {0: "batch_size", 1: "sequence_length"}, # 设置 input_tensor 的前两个维度为动态
"lengths": {0: "batch_size"}, # 设置 lengths 的第一个维度为动态
"features": {0: "batch_size", 1: "sequence_length"} # 设置 features 的前两个维度为动态
}
)
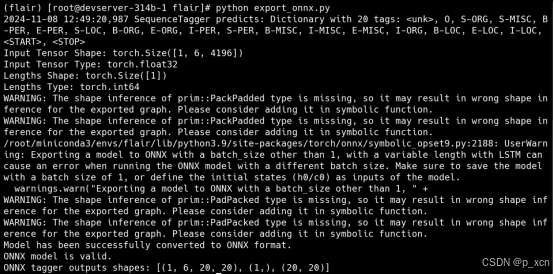
print("Model has been successfully converted to ONNX format.")
# 加载导出的 ONNX 模型
onnx_tagger = onnx.load("./models/en-ner-conll03-v0.4.onnx")
# 检查模型是否有效
onnx.checker.check_model(onnx_tagger)
print("ONNX model is valid.")
# 创建 ONNX Runtime 会话
ort_session_tagger = ort.InferenceSession("./models/en-ner-conll03-v0.4.onnx")
# 准备输入数据
ort_inputs_tagger = {
'input_tensor': tagger_tensor.numpy(),
'lengths': tagger_lengths.numpy()
}
# 运行 NER 模型
ort_outputs_tagger = ort_session_tagger.run(None, ort_inputs_tagger)
print("ONNX tagger outputs shapes:", [f.shape for f in ort_outputs_tagger])
- 由于onnx文件不包含运行时配置参数和字典信息,而这些信息是模型运行和推理时必须的,所以需要提前另外准备一个文件用于保存原有模型的字典信息。
2.4.2 重写类代码
新建ner_model_npu.py文件,在原有SequenceTagger基础上新建加载onnx模型文件的类。
import flair
from flair.models import *
from flair.embeddings.base import load_embeddings
from flair.datasets import DataLoader, FlairDatapointDataset
from flair.training_utils import store_embeddings
from flair.data import Dictionary, Label, Sentence, Span, get_spans_from_bio
from tqdm import tqdm
import torch
import onnx
import onnxruntime as ort
from typing import Union, Dict, Any, Type, cast, List, Optional
import pickle
class SequenceTaggerForNPU(SequenceTagger):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.onnx_session=None
self.aclmodel=None
@classmethod
def load_onnx(cls, model_file: str, **kwargs):
pickle_file = model_file.replace(".onnx", ".pkl")
with open(pickle_file, 'rb') as f:
model_info= pickle.load(f)
embeddings=model_info.get("embeddings")
if isinstance(embeddings, dict):
embeddings = load_embeddings(embeddings)
kwargs["embeddings"] = embeddings
kwargs["tag_dictionary"] = model_info.get("tag_dictionary")
kwargs["tag_format"] = model_info.get("tag_format")
kwargs["tag_type"] = model_info.get("tag_type")
kwargs["use_crf"] = model_info.get("use_crf")
kwargs["use_rnn"] = model_info.get("use_rnn")
kwargs["reproject_embeddings"] = model_info.get("reproject_embeddings")
kwargs["init_from_state_dict"] = model_info.get("init_from_state_dict")
instance = cls(**kwargs)
instance.onnx_session = ort.InferenceSession(model_file)
return instance
def forward_onnx(self, sentence_tensor, lengths):
"""Forward propagation through network using NOOX.
Args:
sentence_tensor: A tensor representing the batch of sentences.
lengths: A IntTensor representing the lengths of the respective sentences.
"""
# Convert input tensors to numpy arrays
sentence_tensor_np = sentence_tensor.cpu().numpy()
lengths_np = lengths.cpu().numpy()
# Run the ONNX model
inputs = {
'input_tensor': sentence_tensor_np,
'lengths': lengths_np
}
outputs = self.onnx_session.run(None, inputs)
# Convert outputs back to torch tensors
outputs = ([torch.tensor(out) for out in outputs])
return outputs
def predict_onnx(self,sentences: Union[List[Sentence], Sentence],
mini_batch_size: int = 32,
return_probabilities_for_all_classes: bool = False,
verbose: bool = False,
label_name: Optional[str] = None,
return_loss=False,
embedding_storage_mode="none",
force_token_predictions: bool = False,
):
"""Predicts labels for current batch with CRF or Softmax.
Args:
sentences: List of sentences in batch
mini_batch_size: batch size for test data
return_probabilities_for_all_classes: Whether to return probabilities for all classes
verbose: whether to use progress bar
label_name: which label to predict
return_loss: whether to return loss value
embedding_storage_mode: determines where to store embeddings - can be "gpu", "cpu" or None.
force_token_predictions: add labels per token instead of span labels, even if `self.predict_spans` is True
"""
if label_name is None:
label_name = self.tag_type
if not sentences:
return sentences
# make sure it's a list
if not isinstance(sentences, list) and not isinstance(sentences, flair.data.Dataset):
sentences = [sentences]
Sentence.set_context_for_sentences(cast(List[Sentence], sentences))
# filter empty sentences
sentences = [sentence for sentence in sentences if len(sentence) > 0]
# reverse sort all sequences by their length
reordered_sentences = sorted(sentences, key=len, reverse=True)
if len(reordered_sentences) == 0:
return sentences
dataloader = DataLoader(
dataset=FlairDatapointDataset(reordered_sentences),
batch_size=mini_batch_size,
)
# progress bar for verbosity
if verbose:
dataloader = tqdm(dataloader, desc="Batch inference")
overall_loss = torch.zeros(1, device=flair.device)
label_count = 0
for batch in dataloader:
# stop if all sentences are empty
if not batch:
continue
# get features from forward propagation
sentence_tensor, lengths = self._prepare_tensors(batch)
features = self.forward_onnx(sentence_tensor, lengths)
# remove previously predicted labels of this type
for sentence in batch:
sentence.remove_labels(label_name)
# if return_loss, get loss value
if return_loss:
gold_labels = self._prepare_label_tensor(batch)
loss = self._calculate_loss(features, gold_labels)
overall_loss += loss[0]
label_count += loss[1]
# make predictions
if self.use_crf:
predictions, all_tags = self.viterbi_decoder.decode(
features, return_probabilities_for_all_classes, batch
)
else:
predictions, all_tags = self._standard_inference(
features, batch, return_probabilities_for_all_classes
)
# add predictions to Sentence
for sentence, sentence_predictions in zip(batch, predictions):
# BIOES-labels need to be converted to spans
if self.predict_spans and not force_token_predictions:
sentence_tags = [label[0] for label in sentence_predictions]
sentence_scores = [label[1] for label in sentence_predictions]
predicted_spans = get_spans_from_bio(sentence_tags, sentence_scores)
for predicted_span in predicted_spans:
span: Span = sentence[predicted_span[0][0] : predicted_span[0][-1] + 1]
span.add_label(label_name, value=predicted_span[2], score=predicted_span[1])
# token-labels can be added directly ("O" and legacy "_" predictions are skipped)
else:
for token, label in zip(sentence.tokens, sentence_predictions):
if label[0] in ["O", "_"]:
continue
token.add_label(typename=label_name, value=label[0], score=label[1])
# all_tags will be empty if all_tag_prob is set to False, so the for loop will be avoided
for sentence, sent_all_tags in zip(batch, all_tags):
for token, token_all_tags in zip(sentence.tokens, sent_all_tags):
token.add_tags_proba_dist(label_name, token_all_tags)
store_embeddings(sentences, storage_mode=embedding_storage_mode)
if return_loss:
return overall_loss, label_count
return None新建verify_onnx.py文件,对转换后的模型文件进行对比验证。
import torch.onnx
from flair.models import *
from flair.data import Sentence
from ner_model_npu import *
inputs="I want to go to Beijing."
# 加载pt文件
tagger = SequenceTagger.load("./models/en-ner-conll03-v0.4.pt")
# 创建一个句子对象
tagger_sentence = Sentence(inputs)
# 使用模型的嵌入层获取输入张量
tagger.embeddings.embed(tagger_sentence)
# 获取每个 token 的嵌入向量
tagger_tensor = [token.embedding for token in tagger_sentence]
tagger_tensor = torch.stack(tagger_tensor).unsqueeze(0) # 添加批次维度
# 获取句子的长度
tagger_lengths = torch.tensor([len(tagger_sentence)], dtype=torch.long)
features=tagger.forward(tagger_tensor, tagger_lengths)
print("PT output:")
print(type(features))
for f in features:
print(f.shape)
tagger_npu = SequenceTaggerForNPU.load_onnx("./models/en-ner-conll03-v0.4.onnx")
# 创建一个句子对象
tagger_npu_sentence = Sentence(inputs)
# 使用模型的嵌入层获取输入张量
tagger_npu.embeddings.embed(tagger_npu_sentence)
# 获取每个 token 的嵌入向量
tagger_npu_tensor = [token.embedding for token in tagger_npu_sentence]
tagger_npu_tensor = torch.stack(tagger_npu_tensor).unsqueeze(0) # 添加批次维度
# 获取句子的长度
tagger_npu_lengths = torch.tensor([len(tagger_npu_sentence)], dtype=torch.long)
features_npu=tagger_npu.forward_noox(tagger_npu_tensor, tagger_npu_lengths)
print("ONNX output:")
print(type(features_npu))
for fn in features_npu:
print(fn.shape)
# 比较每个 tensor 的内容
for i, (f, fn) in enumerate(zip(features, features_npu)):
assert f.shape == fn.shape, f"Shapes of features[{i}] and features_npu[{i}] must be the same"
# 计算两个 tensor 之间的最大绝对差值
max_abs_diff = torch.max(torch.abs(f - fn)).item()
print(f"Maximum absolute difference between features[{i}] and features_npu[{i}]: {max_abs_diff}")
tagger.predict(tagger_sentence)
print("PT label:")
print(tagger_sentence)
tagger_npu.predict_onnx(tagger_npu_sentence)
print("ONNX label:")
print(tagger_npu_sentence) 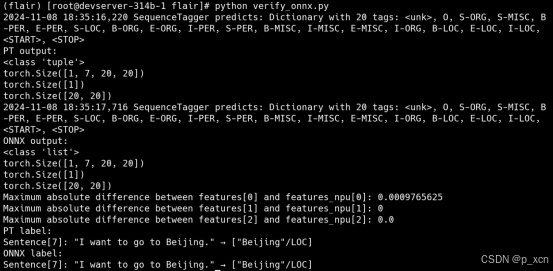
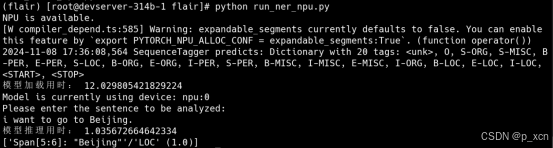
运行run_ner_npu.py文件:
import flair
from flair.data import Sentence
from flair.models import SequenceTagger
from ner_model_npu import *
import torch
import torch_npu
# 检查 NPU 是否可用
if torch.npu.is_available():
print("NPU is available.")
flair.device = torch.device('npu')
else:
print("NPU is not available.")
flair.device = torch.device('cpu')
# 加载命名实体识别模型和情感分析模型
tagger = SequenceTaggerForNPU.load_onnx("./models/en-ner-conll03-v0.4.onnx")
# 检查模型使用的设备
device = next(tagger.parameters()).device
print(f"Model is currently using device: {device}")
# 输入语句
print('Please enter the sentence to be analyzed:')
inputs = input()
# NER
tagger_sentence = Sentence(inputs)
tagger.predict_onnx(tagger_sentence)
print(tagger_sentence.labels)能看到相比之前加载和推理用时都有缩短。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









