







CogVideoX是智谱AI开发的视频生成大模型。无需复杂的视频制作技能和工具,能够将文本描述或静态图片转化为高质量、具有视觉吸引力的动态视频。
https://github.com/THUDM/CogVideo
一、部署到昇腾NPU
昇腾环境:
芯片类型:昇腾910B3
CANN版本:CANN 7.0.1.5
驱动版本:23.0.6
操作系统:Huawei Cloud EulerOS 2.0
1.环境搭建
conda创建python3.10环境。
conda create --name cogvideo python=3.10从 GitHub 拉取代码。
git clone https://github.com/THUDM/CogVideo.git
cd CogVideo安装依赖。
pip install -r requirements.txt
# 安装对应pytorch版本的torch_npu
pip install torch_npu新建测试verify_npu.py,验证NPU环境:
import torch
import torch_npu
# 检查 NPU 是否可用
if torch.npu.is_available():
print("NPU is available.")
device_id = 0
torch.npu.set_device(device_id)
device = 'npu:' + str(device_id)
tensor = torch.tensor([1.0, 2.0, 3.0], device=device)
print(tensor)
else:
print("NPU is not available.")输出NPU is available,NPU 环境正常。

2.下载模型
模型较大,需预留45G空间。
选择使用Git下载模型,需要先安装git-lfs。
wget https://github.com/git-lfs/git-lfs/releases/download/v3.5.1/git-lfs-linux-arm64-v3.5.1.tar.gz
tar xvf git-lfs-linux-arm64-v3.5.1.tar.gz
cd git-lfs-3.5.1
sudo ./install.sh验证git-lfs安装:
git lfs version 下载模型:
下载模型:
mkdir THUDM
cd THUDM
git lfs install
git clone https://www.modelscope.cn/ZhipuAI/CogVideoX-5b.git
cd CogVideoX-5b
git lfs pull3.在npu上运行代码
新建run_t2v_npu.py:
import torch
import torch_npu
from diffusers import CogVideoXPipeline
from diffusers.utils import export_to_video
# 检查是否有可用的 GPU
if torch.npu.is_available():
print("NPU is available.")
device = torch.device('npu')
torch_dtype = torch.bfloat16 # 推荐使用 BF16
print(f"Using data type: {torch_dtype}")
# 创建一个随机数生成器
generator = torch.Generator(device=device).manual_seed(42)
print("Generator created")
prompt = "A panda, dressed in a small, red jacket and a tiny hat, sits on a wooden stool in a serene bamboo forest. The panda's fluffy paws strum a miniature acoustic guitar, producing soft, melodic tunes. Nearby, a few other pandas gather, watching curiously and some clapping in rhythm. Sunlight filters through the tall bamboo, casting a gentle glow on the scene. The panda's face is expressive, showing concentration and joy as it plays. The background includes a small, flowing stream and vibrant green foliage, enhancing the peaceful and magical atmosphere of this unique musical performance."
print("Prompt set")
pipe = CogVideoXPipeline.from_pretrained(
"THUDM/CogVideoX-5b",
torch_dtype=torch_dtype
)
print("Pipeline loaded")
# 确保模型和数据都在选定的设备上
pipe.to(device)
print("Model moved to device")
video = pipe(
prompt=prompt,
num_videos_per_prompt=1,
num_inference_steps=50,
num_frames=49,
guidance_scale=6,
generator=generator,
).frames[0]
print("Video generated")
export_to_video(video, "output.mp4", fps=8)
print("Video exported")
else:
print("NPU is not available.")
运行报错:
(cogvideo) [root@devserver-314b-1 CogVideo]# python run_t2v_npu.py
Using device: npu
Using data type: torch.bfloat16
Generator created
Prompt set
Loading checkpoint shards: 100%|████████████████████████████████████████████████████| 2/2 [00:00<00:00, 4.63it/s]
Loading pipeline components...: 100%|███████████████████████████████████████████████| 5/5 [00:01<00:00, 2.52it/s]
Pipeline loaded
Model moved to device
0%| | 0/50 [00:00<?, ?it/s][W1114 14:42:44.058506898 compiler_depend.ts:387] Warning: EH9999: Inner Error!
EH9999 [Init][Env]init env failed![FUNC:ReportInnerError][FILE:log_inner.cpp][LINE:145]
TraceBack (most recent call last):
build op model failed, result = 500001[FUNC:ReportInnerError][FILE:log_inner.cpp][LINE:145]
(function ExecFunc)
0%| | 0/50 [00:00<?, ?it/s]
Traceback (most recent call last):
File "/dev/shm/wangshijing/CogVideo/run_t2v_npu.py", line 31, in <module>
video = pipe(prompt=prompt,num_videos_per_prompt=1,num_inference_steps=50,num_frames=49,guidance_scale=6,generator=generator,).frames[0]
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/torch/utils/_contextlib.py", line 116, in decorate_context
return func(*args, **kwargs)
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/diffusers/pipelines/cogvideo/pipeline_cogvideox.py", line 684, in __call__
noise_pred = self.transformer(
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1736, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1747, in _call_impl
return forward_call(*args, **kwargs)
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/diffusers/models/transformers/cogvideox_transformer_3d.py", line 473, in forward
hidden_states, encoder_hidden_states = block(
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1736, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1747, in _call_impl
return forward_call(*args, **kwargs)
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/diffusers/models/transformers/cogvideox_transformer_3d.py", line 132, in forward
attn_hidden_states, attn_encoder_hidden_states = self.attn1(
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1736, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1747, in _call_impl
return forward_call(*args, **kwargs)
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/diffusers/models/attention_processor.py", line 495, in forward
return self.processor(
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/diffusers/models/attention_processor.py", line 1928, in __call__
value = attn.to_v(hidden_states)
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1736, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1747, in _call_impl
return forward_call(*args, **kwargs)
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/torch/nn/modules/linear.py", line 125, in forward
return F.linear(input, self.weight, self.bias)
RuntimeError: The Inner error is reported as above. The process exits for this inner error, and the current working operator name is Conv2D.
Since the operator is called asynchronously, the stacktrace may be inaccurate. If you want to get the accurate stacktrace, pleace set the environment variable ASCEND_LAUNCH_BLOCKING=1.
[ERROR] 2024-11-26-14:42:44 (PID:1154952, Device:0, RankID:-1) ERR00100 PTA call acl api failed
[W1114 14:42:44.066216328 compiler_depend.ts:659] Warning: 0Failed to find function aclrtSynchronizeDeviceWithTimeout (function operator())设置环境变量获取更准确的堆栈跟踪信息:
export ASCEND_LAUNCH_BLOCKING=1再次运行报错变为:
(cogvideo) [root@devserver-314b-1 CogVideo]# python run_t2v_npu.py
Using device: npu
Using data type: torch.bfloat16
Generator created
Prompt set
Loading checkpoint shards: 100%|████████████████████████████████████████████████████| 2/2 [00:00<00:00, 4.85it/s]
Loading pipeline components...: 100%|███████████████████████████████████████████████| 5/5 [00:01<00:00, 2.51it/s]
Pipeline loaded
Model moved to device
0%| | 0/50 [00:00<?, ?it/s]
Traceback (most recent call last):
File "/dev/shm/wangshijing/CogVideo/run_t2v_npu.py", line 31, in <module>
video = pipe(prompt=prompt,num_videos_per_prompt=1,num_inference_steps=50,num_frames=49,guidance_scale=6,generator=generator,).frames[0]
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/torch/utils/_contextlib.py", line 116, in decorate_context
return func(*args, **kwargs)
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/diffusers/pipelines/cogvideo/pipeline_cogvideox.py", line 684, in __call__
noise_pred = self.transformer(
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1736, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1747, in _call_impl
return forward_call(*args, **kwargs)
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/diffusers/models/transformers/cogvideox_transformer_3d.py", line 446, in forward
hidden_states = self.patch_embed(encoder_hidden_states, hidden_states)
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1736, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1747, in _call_impl
return forward_call(*args, **kwargs)
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/diffusers/models/embeddings.py", line 412, in forward
image_embeds = self.proj(image_embeds)
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1736, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1747, in _call_impl
return forward_call(*args, **kwargs)
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/torch/nn/modules/conv.py", line 554, in forward
return self._conv_forward(input, self.weight, self.bias)
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/torch/nn/modules/conv.py", line 549, in _conv_forward
return F.conv2d(
RuntimeError: InnerRun:build/CMakeFiles/torch_npu.dir/compiler_depend.ts:218 OPS function error: Conv2D, error code is 500001
[ERROR] 2024-11-26-14:45:31 (PID:1155878, Device:0, RankID:-1) ERR01100 OPS call acl api failed
[Error]: The internal ACL of the system is incorrect.
Rectify the fault based on the error information in the ascend log.
EC0010: Failed to import Python module [ModuleNotFoundError: No module named 'tbe'.].
Solution: Check that all required components are properly installed and the specified Python path matches the Python installation directory. (If the path does not match the directory, run set_env.sh in the installation package.)
TraceBack (most recent call last):
[GraphOpt][InitializeInner][InitTbeFunc] Failed to init tbe.[FUNC:InitializeInner][FILE:tbe_op_store_adapter.cc][LINE:1623]
[SubGraphOpt][PreCompileOp][InitAdapter] InitializeAdapter adapter [tbe_op_adapter] failed! Ret [4294967295][FUNC:InitializeAdapter][FILE:op_store_adapter_manager.cc][LINE:85]
[SubGraphOpt][PreCompileOp][Init] Initialize op store adapter failed, OpsStoreName[tbe-custom].[FUNC:Initialize][FILE:op_store_adapter_manager.cc][LINE:126]
[FusionMngr][Init] Op store adapter manager init failed.[FUNC:Initialize][FILE:fusion_manager.cc][LINE:124]
PluginManager InvokeAll failed.[FUNC:Initialize][FILE:ops_kernel_manager.cc][LINE:96]
OpsManager initialize failed.[FUNC:InnerInitialize][FILE:gelib.cc][LINE:237]
GELib::InnerInitialize failed.[FUNC:Initialize][FILE:gelib.cc][LINE:165]
[Initialize][Ge]GEInitialize failed. ge result = 4294967295[FUNC:ReportCallError][FILE:log_inner.cpp][LINE:161]
[Init][Compiler]Init compiler failed[FUNC:ReportInnerError][FILE:log_inner.cpp][LINE:145]
[Set][Options]OpCompileProcessor init failed![FUNC:ReportInnerError][FILE:log_inner.cpp][LINE:145]
[Init][Env]init env failed![FUNC:ReportInnerError][FILE:log_inner.cpp][LINE:145]
build op model failed, result = 500001[FUNC:ReportInnerError][FILE:log_inner.cpp][LINE:145]
[W1114 14:45:31.433200230 compiler_depend.ts:659] Warning: 0Failed to find function aclrtSynchronizeDeviceWithTimeout (function operator())根据错误信息,tbe 模块未找到。尝试运行环境设置脚本。
source /usr/local/Ascend/ascend-toolkit/set_env.sh再次运行报错变为:
(cogvideo) [root@devserver-314b-1 CogVideo]# python run_t2v_npu.py
Using device: npu
Using data type: torch.bfloat16
Generator created
Prompt set
Loading checkpoint shards: 100%|████████████████████████████████████████████████████| 2/2 [00:00<00:00, 4.74it/s]
Loading pipeline components...: 100%|███████████████████████████████████████████████| 5/5 [00:01<00:00, 2.51it/s]
Pipeline loaded
Model moved to device
0%| | 0/50 [00:00<?, ?it/s]SystemError: PY_SSIZE_T_CLEAN macro must be defined for '#' formats
0%| | 0/50 [00:08<?, ?it/s]
Traceback (most recent call last):
File "/dev/shm/wangshijing/CogVideo/run_t2v_npu.py", line 31, in <module>
video = pipe(prompt=prompt,num_videos_per_prompt=1,num_inference_steps=50,num_frames=49,guidance_scale=6,generator=generator,).frames[0]
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/torch/utils/_contextlib.py", line 116, in decorate_context
return func(*args, **kwargs)
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/diffusers/pipelines/cogvideo/pipeline_cogvideox.py", line 684, in __call__
noise_pred = self.transformer(
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1736, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1747, in _call_impl
return forward_call(*args, **kwargs)
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/diffusers/models/transformers/cogvideox_transformer_3d.py", line 473, in forward
hidden_states, encoder_hidden_states = block(
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1736, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1747, in _call_impl
return forward_call(*args, **kwargs)
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/diffusers/models/transformers/cogvideox_transformer_3d.py", line 132, in forward
attn_hidden_states, attn_encoder_hidden_states = self.attn1(
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1736, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1747, in _call_impl
return forward_call(*args, **kwargs)
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/diffusers/models/attention_processor.py", line 495, in forward
return self.processor(
File "/root/miniconda3/envs/cogvideo/lib/python3.10/site-packages/diffusers/models/attention_processor.py", line 1950, in __call__
hidden_states = F.scaled_dot_product_attention(
RuntimeError: aclnnFusedInferAttentionScoreV2 or aclnnFusedInferAttentionScoreV2GetWorkspaceSize not in libopapi.so, or libopapi.sonot found.
[ERROR] 2024-11-26-14:55:15 (PID:1158036, Device:0, RankID:-1) ERR01004 OPS invalid pointer
[W1114 14:55:15.526441221 compiler_depend.ts:659] Warning: 0Failed to find function aclrtSynchronizeDeviceWithTimeout (function operator())F.scaled_dot_product_attention 操作时发生的内部错误, aclnnFusedInferAttentionScoreV2 或 aclnnFusedInferAttentionScoreV2GetWorkspaceSize 函数未在 libopapi.so 中找到。
查看libopapi.so 的依赖库是否正确加载:
ldd /usr/local/Ascend/ascend-toolkit/7.0.1.5/aarch64-linux/lib64/lib opapi.so检查 libopapi.so 的符号表:
nm -gC /usr/local/Ascend/ascend-toolkit/7.0.1.5/aarch64-linux/lib64/libopapi.so | grep aclnnFusedInferAttentionScoreV2显示函数不存在:
nm: /usr/local/Ascend/ascend-toolkit/7.0.1.5/aarch64-linux/lib64/libopapi.so: no symbols查询到相关项目:cann-ops-adv: cann-ops-adv,是基于昇腾硬件的融合算子库(adv表示advanced)。
通过Issues提问得知该算子库当前只支持torch 2.1(稳定版本) 和 torch 2.3(beta版)。改为安装torch 2.1版本依赖。
pip install torch==2.1.0 torch_npu==2.1.0 torchvision==0.16.0运行后显示内存不足。
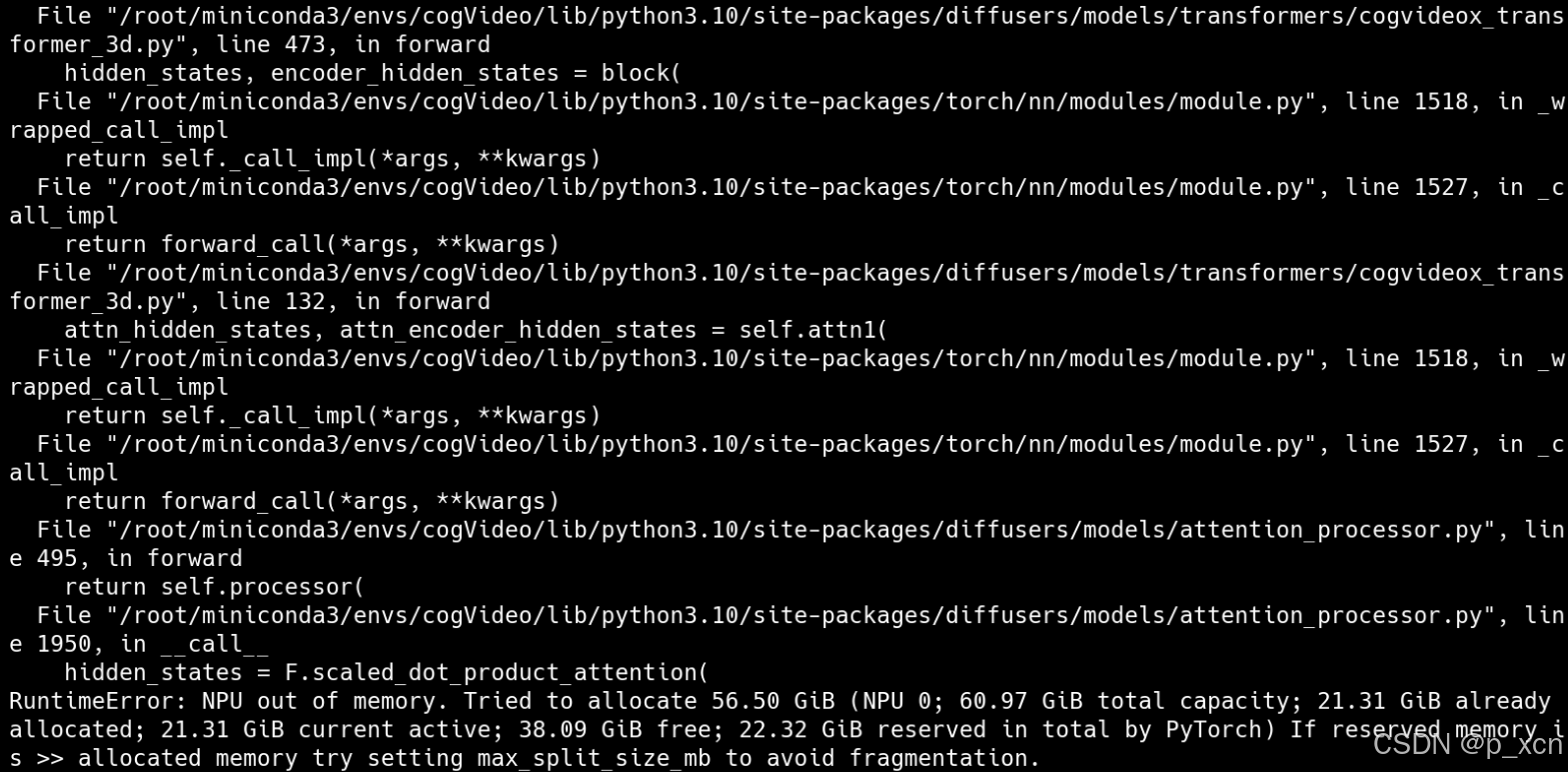
改成使用NPU设备1,减少生成视频的帧数,降低模型精度:
import torch
import torch_npu
from diffusers import CogVideoXPipeline
from diffusers.utils import export_to_video
# 检查是否有可用的 GPU
if torch.npu.is_available():
print("NPU is available.")
device_id = 1
torch.npu.set_device(device_id)
# 创建一个 NPU 张量
device = torch.device('npu:1') # 指定使用 npu:1
# torch_dtype = torch.bfloat16 # 推荐使用 BF16
torch_dtype = torch.float16 # 降低精度
print(f"Using data type: {torch_dtype}")
# 创建一个随机数生成器
generator = torch.Generator(device=device).manual_seed(42)
print("Generator created")
prompt = "A panda, dressed in a small, red jacket and a tiny hat, sits on a wooden stool in a serene bamboo f
orest. The panda's fluffy paws strum a miniature acoustic guitar, producing soft, melodic tunes. Nearby, a few ot
her pandas gather, watching curiously and some clapping in rhythm. Sunlight filters through the tall bamboo, cast
ing a gentle glow on the scene. The panda's face is expressive, showing concentration and joy as it plays. The ba
ckground includes a small, flowing stream and vibrant green foliage, enhancing the peaceful and magical atmospher
e of this unique musical performance."
print("Prompt set")
pipe = CogVideoXPipeline.from_pretrained("THUDM/CogVideoX-5b",torch_dtype=torch_dtype)
print("Pipeline loaded")
# 确保模型和数据都在选定的设备上
pipe.to(device)
print("Model moved to device")
print(f"Current NPU device: {torch.npu.current_device()}")
video = pipe(prompt=prompt,num_videos_per_prompt=1,num_inference_steps=50,num_frames=24,guidance_scale=6,gene
rator=generator,).frames[0]
print("Video generated")
export_to_video(video, "output.mp4", fps=8)
print("Video exported")
else:
print("NPU is not available.")模型运行过程中出现警告:
SystemError: PY_SSIZE_T_CLEAN macro must be defined for '#' formats通常是由于使用了不兼容的 Python 版本或编译选项导致的,新建python 3.8的环境即可。

生成的视频:


















 355
355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









