







视频链接:《算法不好玩》专题二
2-1选择排序
无序数组→有序数组
基于排序算法可以学习的话题:「时间复杂度」、「递归」、「循环不变量」
排序算法可以分为:「基于比较的排序算法」、「非比较的排序算法」
- 基于比较的排序算法:「选择排序」、「冒泡排序」、「插入排序」、「希尔排序」、「归并排序」、「快速排序」、「堆排序」
- 非比较的排序算法:「计数排序」、「基数排序」、「桶排序」
选择排序的思路:
先扫描一遍数组里的所有元素,选出看到的最小元素,
我们把它交换到数组的开头,
这个元素现在的位置就是排序以后它应该在的位置。接着,我们扫描从第二个位置开始到后面所有的元素,选出看到的最小的元素,
这个元素肯定是数组里的第2小的元素,由于2就在数组的第二个位置,我们什么都不用做,接下来我们扫描从第3个位置开始到后面的所有元素,
选出看到的最小的元素,这个元素肯定是数组里第3小的元素,
我们把它交换到数组的第3个位置,这个元素现在所在的位置就是排好序以后它应该在的位置,后面的过程就不重复叙述了。




选择排序法是一种不稳定的排序算法。它的「工作原理」是每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到全部待排序的数据元素排完。
2-2选择排序代码演示
912.排序数组
给你一个整数数组 nums,请你将该数组升序排列。
示例 1:
输入:nums = [5,2,3,1]
输出:[1,2,3,5]
示例 2:
输入:nums = [5,1,1,2,0,0]
输出:[0,0,1,1,2,5]
提示:
- 1 <= nums.length <= 5 * 10^4
- -5 * 10^4 <= nums[i] <= 5 * 10^4
class Solution {
// 选择排序:每一轮选择最小元素交换到未排定部分的开头
public int[] sortArray(int[] nums) {
int len = nums.length;
// 循环不变量:[0, i) 有序,且该区间里所有元素就是最终排定的样子
for (int i = 0; i < len - 1; i++) {
// 选择区间 [i, len - 1] 里最小的元素的索引,交换到下标 i
int minIndex = i;
for (int j = i + 1; j < len; j++) {
if (nums[j] < nums[minIndex]) {
minIndex = j;
}
}
swap(nums, minIndex, i);
}
return nums;
}
private void swap(int[] nums, int index1, int index2) {
int temp = nums[index1];
nums[index1] = nums[index2];
nums[index2] = temp;
}
}
2-3选择排序的时间复杂度
(基于上面代码)
假设数组的长度为N,
第1轮在N个数中选出最小的,读取1个数,做N-1次比较,1次交换;
第2轮在N-1个数中选出最小的,读取1个数,做N-2次比较,1次交换;
……
第N-1轮在2个数中选出最小的,读取1个数,做1次比较,1次交换。
O((N-1)+(N-1)+(N-2)+… +1+ (N- 1))=O((N-1)N/2 +2(N-1))=O(N^2)
2-4数组具有随机访问的特性
数组具有随机访问(Random Access)的特点:根据数组的索引(或者下标)读取数组的某个位置上元素的值与这个元素所在的位置无关。


数组用「随机访问」,链表用「顺序访问」。
2-5选择排序的特点和优化的方向
选择排序的特点:执行时间与数据无关;次数交换最少
优化方向:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zzyijzyv-1649400166316)(C:\Users\86187\AppData\Roaming\Typora\typora-user-images\image-20220408133558978.png)]](https://img-blog.csdnimg.cn/9b0e8dc5fae14608a05bb8bce0a89f87.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5a6J5aic5ZKM5aW555qE56yU6K6w5pys,size_20,color_FFFFFF,t_70,g_se,x_16)
2-6冒泡排序
每一轮可以排定一个元素的位置;
数组的元素个数有限;
经过有限操作一定可以完成排序任务。
eg:
912.排序数组
给你一个整数数组 nums,请你将该数组升序排列。
示例 1:
输入:nums = [5,2,3,1]
输出:[1,2,3,5]
示例 2:
输入:nums = [5,1,1,2,0,0]
输出:[0,0,1,1,2,5]
提示:
- 1 <= nums.length <= 5 * 10^4
- -5 * 10^4 <= nums[i] <= 5 * 10^4
class Solution {
public int[] sortArray(int[] nums) {
int len = nums.length;
for (int i = 0;i< len-1; i++) {
for (int j = 1;j< len-i; j++) {
if (nums[j-1]> nums[j]) {
swap(nums,j-1,j);
}
}
}
return nums;
}
private void swap(int[] nums, int index1, int index2) {
int temp = nums[index1];
nums[index1] = nums[index2];
nums[index2] = temp;
}
}
冒泡排序的时间复杂度:
第1轮需要看N个元素;
第2轮需要看N-1个元素;
……
第N-1轮需要看2个元素;
时间复杂度:O((N+(N-1)+…+2))=O(N+2)(N-1)/2)=O(N^2)
2-7插入排序
仍旧是912.排序数组,代码如下:
class Solution {
public int[] sortArray(int[] nums) {
int len = nums.length;
for (int i = 0;i< len-1; i++) {
for (int j = i;j>0 && nums[j-1]>nums[j]; j--) {
swap(nums,j-1,j);
}
}
return nums;
}
private void swap(int[] nums, int index1, int index2) {
int temp = nums[index1];
nums[index1] = nums[index2];
nums[index2] = temp;
}
}
插入排序的时间复杂度:
第1轮需要看1个元素;
第2轮最多需要看2个元素;
…………
第N-1轮最多需要看N-1个元素;
时间复杂度:O(1+2+…+(N-1))=O((1+(N-1)(N-1))/2)=O(N^2)
2-8插入排序的重要意义
插入排序的内存循环有一定机会可以提前终止

插入排序作用在接近有序的数组上效果较好
什么是接近有序?
- 每个元素距离它排序以后最终在的位置不远
接近有序是指以下两种情况很少出现:
- 数值很小的元素排在很后面
- 数值很大的元素排在很前面
归并排序 和 快速排序 是基于「分治算法」的排序算法
归并排序 和 快速排序 拆分到较小子区间的时候转而使用插入排序
在绝大多数情况下,插入排序应用长度为6到16之间的任意值的排序任务上都能令人满意。
2-9插入排序的优化
插入排序的基本思想:把一个数插入有序数组中。
查找插入的位置可以使用二分查找,但仍然需要把插入元素严格大的元素逐个后移,时间复杂度不变(通过二分查找,找到插入元素的位置,这样的优化思路其实起不到真正的作用。另外,逐个交换、逐个赋值两种写法,如果面试考察到插入排序,我们选择其中一个实现就可以了)
2-10希尔排序的基本思路
如果你需要解决一个排序问题而又没有系统排序函数可用(例如直接接触
硬件或是运行与嵌入式系统中的代码),可以先用希尔排序,然后再考虑
是否值得将它替换为更加复杂的排序算法。
希尔排序是一种基于插入排序的算法,用一句话概括希尔排序的思想,那就是分组插入排序,或者是带间隔的插入排序,不断地把数组整理成接近有序的样子,最后执行一次标准的插入排序,最终完成排序任务。
插入排序的优点:插入排序在接近有序的数组上有较好的性能;插入排序在数据规模较小的排序任务上有较好的性能
插入排序的缺点:较小的数如果在数组靠后的位置,只能一步一步来到靠前的位置
我们以一个有10个元素的数组为例,第一轮,我们将数组分组,下标间隔为5的元素分在一组。这里5是10的一半,我们把分到同一组的元素用相同的颜色标注出来。
间隔是多少就有多少组,对它们分别执行插入排序。
在这个过程中就有数值比较小且靠后的元素一下子来到了数组的前面。
在执行完分组插入排序或者说带间隔的插入排序以后,数组就朝着接近有序的方向前进了一步,
分组插入排序完成以后,我们称这个时候数组是「5间隔有序」的。在第二轮,我们以上一轮间隔的一半,也就是5的一半2为间隔,对数组进行分组。
分为两组,依然是把分在一组的元素标上了相同的颜色,对它们分别执行插入排序,
在上一轮的基础上,虽然同在一组的元素比上一轮多了,但这一轮的数据变得更接近有序了,插入排序也能够比较快地完成排序的任务。
分组插入排序以后,我们称这个时候数组是「2间隔有序」的。
在第三轮我们对上一轮的间隔的2的一半,也就是间隔为1进行一次插入排序。很显然,这是一次标准的插入排序,








总结:

2-11希尔排序的增量序列
仍旧是912.排序数组,代码如下:
class Solution {
public int[] sortArray(int[] nums) {
int len=nums.length;
for(int delta=len/2;delta>0;delta/=2){
for (int start=0;start<delta;start++){
//分组插入排序
for (int i=stạrt+delta;i<len;i+=delta){
int temp=rums[i];
int j;
for (j=i;j-delta>=0 && nums[j-delta]>temp;j-=delta){
nums[j]=nums[j-delta];
}
nums[j]=temp;
}
}
}
return nums;
}
}
希尔排序的时间复杂度与选择的步长序列有关;
不同的步长序列对应了不同的算法
Shell提出的步长序列
步长序列:1,2,4,8,16,32,……
通项公式:2^k
时间复杂度:O(N^2)
以长度为19的数组为例:
·第1轮:执行间隔为16的分组插入排序,一共16组,16次分组插入排序;
·第2轮:执行间隔为8的分组插入排序,一共8组,8次分组插入排序;
·第3轮:执行间隔为4的分组插入排序,一共4组,4次分组插入排序;
·第4轮:执行间隔为2的分组插入排序,一共2组,2次插入排序;
·第5轮:插入排序。
Hibbard提出的步长序列
步长序列:1,3,7,15,31,……
通项公式:2^k-1
时间复杂度:O(N^(3/2))
Donald Knuth提出的步长序列
步长序列:1,4,7,15,31,……
通项公式:h=3h+1
对通项公式的理解:
当i=0时,hi=0;
当i>0时,hi=3hi-1+1。
时间复杂度:O(N^(3/2))
Robert Sedgewick提出的步长序列
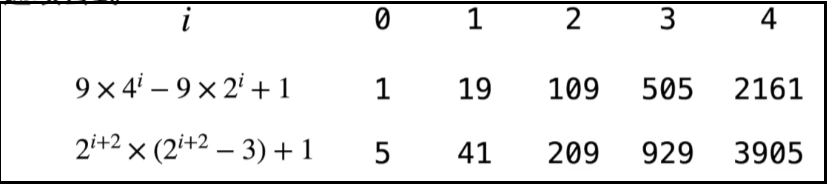
步长序列:1,5,19,41,109,209,505,929,2161,3905,……
通项公式:
用这样步长序列的希尔排序比插入排序要快,甚至在小数组中比快速排序和堆排序还快,但是在涉及大量数据时希尔排序还是比快速排序慢。
















 2425
2425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









