







实训1: 面向过程编程综合练习
参考代码 by 小喾苦
答案仅供参考!
目录
第1关:最大值函数
任务描述
本关任务:编写一个能求两个或三个数中最大值的小程序。
相关知识
为了完成本关任务,你需要掌握:
- 函数声明与定义;
- 函数重载;
- 使用函数。
函数声明与定义
函数是程序中用于实现某个功能的一小段代码。
- 函数声明
一个函数的原型声明主要分为3个部分:返回值类型,函数名,参数列表,表现形式为:
<返回值类型> <函数名>(<参数列表>)
例如:
//两条函数原型声明
int Func(int a,int b); // 以分号结尾
void Func2();
第一条声明的返回值类型是 int,函数名是 Func,参数列表是int a,int b。第二条声明的返回值类型是 void,即无返回值。函数名是 Func2,参数列表为空,即无参数。
其中,参数列表中的每一个参数被称为形式参数,用于接收调用函数时传递的参数。
- 函数定义
定义函数实际上就是实现函数功能,语法与函数声明差不多,只是将声明最后的分号换成一块大括号包裹的代码块。
例如:
int Func(int a,int b)
{
return a + b; // 返回参数 a 与参数 b 的和
}
void Func2(){
return; //无返回值,单一个 return,可省略
}
在函数中使用 return 语句能中断函数执行并返回一个值。可以根据需要在多个地方使用 return 语句。返回值不是 void 类型的函数建议在每一个函数执行结束的地方都放上 return 语句,以确保函数的返回值有效。
比如:
int Func(int a)
{
if(a > 10)
{
return 10;
}
else
{
/*
在这里不写 return 语句虽然不会报错,
但建议还是加上 return 语句
*/
}
}
函数重载
当两个函数名字相同,而参数列表的参数数量、类型或者顺序不同时,这两个函数就是重载函数。需要注意的是,C++ 支持函数重载,但 C 不支持。
例如:
//下面 3 个函数则为重载函数
int Add(int a,int b);
int Add(int a,int b,int c);
char Add(char a,char c);
只有返回值不同的两个函数不能作为重载函数,例如:
int Add(int a,int b);
char Add(int a,int b); // 只有返回值不同,不能作为重载函数
调用函数
要调用一个函数,只需要在函数名的后面加上一对圆括号,并在其中加上要传递的参数即可。
例如:
int Add(int a,int b)
{
return a + b;
}
int main()
{
int c = Add(10,20); // 调用 Add 函数,传递 10 和 20 作为参数
cout << c << endl;
}
输出结果为:30
调用函数时后面的圆括号中的参数叫做实际参数,它会与函数内的形式参数按照顺序一一对应。
当调用一个重载函数时,编译器会根据参数选择与调用参数最匹配的版本,例如:
int Add(int a,int b){
cout << "重载1" <<endl;
return a + b;
}
int Add(int a,int b,int c)
{
cout << "重载2" <<endl;
return a + b + c;
}
char Add(char a,char b)
{
cout << "重载3" <<endl;
return a + b;
}
int main(){
Add(10,20); // 实际调用的是 int, int 那个重载版本函数
Add(10,20,30); // 实际调用的是 int,int,int 那个重载版本函数
Add('a','b'); // 实际调用的是 char,char 那个重载版本函数
}
输出结果为:
重载1
重载2
重载3
编程要求
在右侧编辑器中的Begin-End之间补充代码,设计一个函数 Max,用来求两个或三个数中的最大值。它的两个重载函数的原型如下:
int Max(int a,int b)int Max(int a,int b,int c)
注意:平台会组织一些参数调用这两个重载函数,然后将结果输出,你只需补充两个函数即可。
测试说明
平台会对你编写的代码进行测试,比对你输出的数值与实际正确数值,只有所有数据全部计算正确才能通过测试:
预期输出:
2
5
2
4
0
开始你的任务吧,祝你成功!
参考代码
step1/usr.h
int Max(int a,int b)
{
/********* Begin *********/
//找出两个参数中最大的那个并返回
if (a > b) {
return a;
} else {
return b;
}
/********* End *********/
}
int Max(int a,int b,int c)
{
/********* Begin *********/
//找出三个参数中最大的那个并返回
return Max(a, Max(b, c));
/********* End *********/
}
第2关:计算阶乘
任务描述
本关任务:编写一个能计算阶乘的小程序。
相关知识
为了完成本关任务,你需要掌握:
- 递归函数;
- 头文件与源文件。
递归函数
当一个函数有直接或者间接调用自身的代码,这个函数就是一个递归函数。
例如:
int Sum(int n){
if(n > 0)
return n + Sum(n -1); // 调用自身
return 0;
}
int main(){
cout << Sum(3) << endl;
}
输出结果为:6
这个递归函数实现了0到 n 的求和,将整个运行过程展开来看的表达式为:3+(2+(1+(0)))。
巧妙的设计递归函数能解决很多复杂的问题,其中的精妙之处在短短的一节中是无法讲清的,所以这里只介绍它的概念,感兴趣的您可以寻找其他资料进行学习。
头文件与源文件
头文件就是源码文件中以“.h”结尾的文件,一般会将函数的原型声明,类的声明,宏定义等声明性的内容放到这一类文件中。
而源文件则是以“.cpp”结尾的文件(适用 C 和 C++ ),或是以“.c”结尾的文件(仅适用 C ),一般将函数的定义,类的定义等具体实现的内容放在这一类文件中。
在 C 和 C++ 的程序设计中,一般会将一个功能模块的各种声明放到一个头文件中,然后再对应一个源文件,将功能的具体实现写在其中,需要用到这个模块的时候就 include 模块的头文件。
例如下列add.h文件:
int Add(int a,int b); // 声明 Add 函数
add.cpp文件:
int Add(int a,int b) // 实现 Add 函数的功能
{
return a + b;
}
main.cpp文件:
#include "add.h" // 引用头文件
int main()
{
int b = Add(10,20); // 使用 Add 函数
}
有些时候一个头文件会被到处使用,为了防止函数或者类等内容的重复声明,一般会在头文件中使用宏防止重复声明。
例如add.h文件:
#ifndef ADD_H_ // 判断存不存在宏定义 ADD_H_,相当于 if 语句
#define ADD_H_ // 不存在则定义 ADD_H_
int Add(int a,int b);
#endif // if 块结束
编程要求
在右侧编辑器中的Begin-End之间补充代码,设计一个函数int Fact(int n),它返回 n 的阶乘(
n
!
n!
n!)。具体要求如下:
- 要求使用递归实现。
- 要求这个函数的原型声明与定义分别放在
fact.h文件和fact.cpp文件中。
注意:评测的代码会使用 include 命令引用fact.h头文件,请确保 fact.h 文件实现正确。并保证测试代码时 n! 的结果不会超出 int 的表示范围。
测试说明
平台会对你编写的代码进行测试,比对你输出的数值与实际正确数值,只有所有数据全部计算正确才能通过测试:
测试输入:5 预期输出:120
测试输入:8 预期输出:40320
开始你的任务吧,祝你成功!
参考代码
step2/fact.cpp
int Fact(int n)
{
/********* Begin *********/
//使用递归计算 n 的阶乘
if (n == 1 || n == 0) {
return 1;
} else {
return n * Fact(n - 1);
}
/********* End *********/
}
step2/fact.h
/********* Begin *********/
//添加定义
#ifndef FACT_H_
#define FACT_H_
int Fact(int n);
#endif
/********* End *********/
第3关:求矩阵最大元素
任务描述
本关任务:编写一个能求出矩阵最大元素的小程序。
相关知识
为了完成本关任务,你需要掌握数组的声明和使用。
数组
数组是一种连续存储的数据结构。声明数组,只需在声明变量的基础上,在变量名的后面加上一对方括号([]),然后在其中填上元素数量即可。
例如:
int a[10]; // 声明一个有 10 个 int 元素的数组
char b[1]; // 声明一个有 1 个 char 元素的数组
在声明数组的同时,可以使用花括号({})对其进行初始化,例如:
int a[2] = {1,2}; // 有两个元素的数组,分别为 1 和 2
花括号中的实际元素数量可以少于方括号中指定的数量,这样的话没有被指定的元素将会是这种类型的默认值,例如:
int a[3] = {1}; // 只指定了第一个元素,其他的都是默认值 0,即{1,0,0}
如果使用了花括号进行初始化,那么方括号中的元素数量也可以不写,编译器会根据花括号中的元素数量自动计算,例如:
int a[] = {1,2}; // 编译器自动计算为 int a[2]
char b[] = {0}; // 编译器自动计算为 char b[1]
二维数据
二维数组本质上是以数组作为数组元素的数组,即“数组的数组”。二维数组又称为矩阵,行列数相等的矩阵称为方阵。
二维数组的声明与一维数组的声明同理,只需在变量名后面加多个方括号就行。
例如:
int a[3][2]; // 可以看做是 3 个元素的数组,每个元素是一个 2 个元素的数组
二维数组也可以用花括号进行初始化,不过它的用法就更为灵活了,例如:
int a[3][2] = {{1,1},{2,2},{3,3}};
/*
嵌套花括号,内部的一个花括号代表 a 数组的一个元素,即:
{1,1}
{2,2}
{3,3}
*/
int b[3][2] = {1,2,3};
/*
平铺成一个 6 个元素的数组,即:
{1,2}
{3,0}
{0,0}
*/
数组的使用
要访问数组的某个元素,只需在数组变量的后面加上方括号,在方括号中填上从0开始的索引即可。
例如:
int a[5];
a[0] = 1; // 访问数组第一个元素,索引为 0
a[1] = a[0]; // 访问数组第二个元素,索引为 1
二维数组也是同理:
int a[3][2];
a[0][0] = 1;
a[1][0] = 2;
a[0][1] = 2;
与普通变量不同的是,数组变量之间不能赋值,但是可以将数组变量赋值给它的类型退化成的指针类型。所谓退化,就是将数组最左边一个维度变成指针(也可以说是指向第一个元素的指针)。
例如:
int a[2]; // 一维数组,退化后成 int* 类型
int *aptr = a; // 正确
int b[3][2]; // 二维数组,退化后是int (*)[2],即指向一个 2 个元素的数组的指针
int (*bptr)[2] = b; // 正确
int (*bptr2)[3] = b; // 错误,bptr2 的类型是指向一个 3 个元素的数组的指针
但当数组作为函数的参数类型时,编译器会将它变成它的退化类型,因此只要退化后的类型相同的数组变量都可以传递给这个参数,例如:
void F(int a[2])
{}
void F2(int a[3][2])
{}
int main()
{
int a[3],b[5];
F(a); // 正确,退化后的类型相同
F(b); // 正确,退化后的类型相同
int c[4][2],d[5][2];
F2(c); // 正确,退化后的类型相同
F2(d); // 正确,退化后的类型相同
}
既然编译器会退化数组类型,那么参数声明中最左边一个维度的数量也就可以省略了,上面的函数 F ,F2 可以写成如下方式:
void F(int a[]) // 不写数量
{}
// 或者直接写成指针 void F(int *a){}
void F2(int a[][2])
{}
//或者 void F2(int (*a)[2]){}
编程要求
在右侧编辑器中的Begin-End之间补充代码,补充函数int MaxEle(int a[3][2],int *r,int *c),函数的功能是找出并返回矩阵 a(一个3行2列的矩阵)中最大的元素,并将它的行、列号通过后两个指针参数 r ,c 返回。
注意:行、列号均从 1 开始。同时,为了结果稳定,矩阵中保证不会有相同元素。
测试说明
平台会对你编写的代码进行测试,比对你输出的数值与实际正确数值,只有所有数据全部计算正确才能通过测试:
测试输入:1 2 3 4 5 6 预期输出:6 3 2
测试输入:9 2 3 4 5 6 预期输出:9 1 1
开始你的任务吧,祝你成功!
参考代码
step3/usr.h
int MaxEle(int a[3][2],int *r,int *c)
{
/********* Begin *********/
//返回最大元素和它所在的行、列号
int maxnum = a[0][0];
*r = 1;
*c = 1;
for (int i = 0; i < 3; i = i + 1) {
for (int j = 0; j < 2; j = j + 1) {
if (a[i][j] > maxnum) {
maxnum = a[i][j];
*r = i + 1;
*c = j + 1;
}
}
}
return maxnum;
/********* End *********/
}
第4关:使用链表进行学生信息管理
任务描述
本关任务:编写一个以链表为基础的学生信息管理小程序。
相关知识
为了完成本关任务,你需要掌握:
- 结构体的使用;
- 单向链表的插入、删除和遍历;
- 头结点。
结构体
在 C++ 中,结构体与接下来要介绍的类的概念差别不大,所以这里主要是介绍它在 C 语言中的经典用法。
结构体的声明分为3部分,一般表现形式如下:
struct <结构体名>{<成员变量>};
例如:
struct Test // 声明一个名为 Test 的结构体,它有两个成员变量 A,B
{
int A;
char B;
}; //不要忘了这个分号
声明好结构体之后,就可以声明这个结构体类型的变量,语法与声明 int ,char 这些类型的变量一样。对于结构体变量,可以使用.成员运算符访问它的成员变量。
例如:
/* Test类的声明同上 */
int main()
{
Test t1; // 声明一个结构体变量
t1.A = 10; // 访问 A 成员变量
t1.B = 'A'; // 访问 B 成员变量
Test t2 = t1; // 将其赋值给另一结构体变量
}
同样也可以声明结构体的指针,这个时候要访问它所指的对象的成员,可以用面向指针的-> 成员运算符。
例如:
/* Test类的声明同上 */
Test t;
Test *ptr = &t;
ptr->A = 10; // 通过指针访问 A 成员
ptr->B = 'A'; // 通过指针访问 B 成员
单向链表
链表是一种常用的数据结构,特点是删除、插入操作效率高。链表的实现有很多种,这里简单介绍一下带头结点的单向链表。
链表的关键是链,它用来连接一个一个的节点,而这个链则是用指针来实现的。
当一个结构体 T 中有一个T*成员变量时,就能用这个成员变量链接到下一个 T 类型的节点,对于下一个节点,也是一样的看法,这样就形成了一条长链,就像这张图:

用代码来说就是:
struct Linked
{
int Data; // 存放数据
Linked *next; // 指向下一个节点的指针
};
单向链表的插入
由链表的结构可以发现,要向某个节点后面插入一个新节点,只需要将原有节点后的链“断开”,然后让新节点的 next 指向断开后的部分,而原有节点的 next 则指向这个新节点,如图:

代码实现如下:
void insertAfter(Linked *link,Linked *newNode)
{
newNode->next = link->next; // 新节点的指针指向旧节点之后的内容
link->next = newNode; // 然后再更新旧节点所指的后一个节点
}
单向链表的删除
要删除一个节点的后一个节点,那就只需将这个节点的 next 指针指向后一个节点的 next 指针所指的内容,也就是跨过要删除的节点,如图:
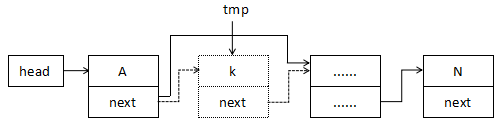
代码实现如下:
void deleteAfter(Linked *link)
{
link->next = link->next->next; // 当前节点的指针指向下一个节点的下一个节点
}
头结点的作用
如果仔细思考上面的插入和删除节点的代码,就会发现对于增加节点,当向一个空链表插入节点时,insertAfter 函数的 link 参数值应该是0。这样插入函数就需要判断传递进来的链表是不是空链,根据判断结果选择不同的做法,而且还要更新外部那个存放了 link 参数值的变量,就像这样:
Linked newNode;
Linked *lk = 0;
lk = insertAfter(lk,&newNode); // 需要接收 insertAfter 的返回值来更新 lk
删除也是一样,也需要考虑只有一个节点的情况下删除该怎么做。
但是,当我们引入一个头结点时情况就不一样了,由于链表始终会有一个节点,那么插入、删除操作就不用考虑容量从0到1,1到0的变化,这样所有的情况下的这两种操作都统一了起来,简化了代码的设计。
单向链表的遍历
要遍历一个单向链表,只需使用一个指针,从头结点之后的一个节点开始,不断地将其 next 值赋给这个指针,直到 next 为0即可,比如:
void iter(Linked *head)
{
Linked *ptr = head->next;
while(ptr) // 判断是否经过了最后一个节点,因为最后一个节点的 next 是 0
{
ptr->Data = 0; // 对节点进行操作
ptr = ptr->next; // 进入到下一个节点
}
}
编程要求
在右侧编辑器中的Begin-End之间补充代码,设计一个以链表为基础的学生信息管理,系统中包含五个函数的实现,具体功能如下:
Linked* Create():创建并返回一个空链表;void InsertAfter(Linked *node,int num,float sc):在 node 所指节点之后插入一个新节点,并用参数 num ,sc 的值分别初始化新节点的成员变量学号和分数;void DeleteAfter(Linked *node):删除 node 节点之后的节点;Linked* GetByIndex(Linked *head,int index):返回 head 所指链表中索引为 index 的节点,比如当 index 为 0 时,返回的应该是头结点之后的第一个节点;void PrintAll(Linked *head):按照<学号> <分数>的格式打印链表中所有节点的成员变量的值,每个一行。
其中链表结构体 Linked,除了实现链表所必要的成员变量外,还有两个成员变量(变量名自拟):
- 学号,int 类型;
- 分数,float 类型。
注意:测评代码保证上述操作涉及到的节点都是存在的。且新节点可以使用 new 运算符来动态创建,那么删除节点时就对应使用 delete 运算符。
测试说明
平台会对你编写的代码进行测试,比对你输出的数值与实际正确数值,只有所有数据全部计算正确才能通过测试:
测试输入:
1 59.5
2 99.5
3 60.5
预期输出:
1 59.5
3 60.5
预期输出说明:平台评测执行顺序为先插入测试输入的数据,再删除第2组数据,最后打印结果。
开始你的任务吧,祝你成功!
参考代码
step4/usr.h
#include <iostream>
#include <cstdlib>
using namespace std;
struct Linked
{
/********* Begin *********/
//结构体的成员变量
int num; // 学号
float sc; // 成绩
Linked *next; // 指向下一个节点的指针
/********* End *********/
};
Linked* Create()
{
/********* Begin *********/
//创建并返回一个新链表
Linked *linked = (Linked *)malloc(sizeof(Linked));
linked->num = -1;
linked->sc = -1.0f;
linked->next = NULL;
return linked;
/********* End *********/
}
void InsertAfter(Linked *node,int num,float sc)
{
/********* Begin *********/
//在指定节点后插入一个新节点,内容由 num,sc 参数指定
Linked *newLinked = (Linked *)malloc(sizeof(Linked));
newLinked->num = num;
newLinked->sc = sc;
newLinked->next = node->next;
node->next = newLinked;
/********* End *********/
}
void DeleteAfter(Linked *node)
{
/********* Begin *********/
//删除此节点之后的一个节点
node->next = node->next->next;
/********* End *********/
}
Linked* GetByIndex(Linked *head,int index)
{
/********* Begin *********/
//返回指定索引处的节点
return head + index + 1;
/********* End *********/
}
void PrintAll(Linked *head)
{
/********* Begin *********/
//按格式打印此链表中所有节点的成员变量
Linked *ptr = head->next;
while (ptr) {
printf("%d %.1f\n", ptr->num, ptr->sc);
ptr = ptr->next;
}
/********* End *********/
}
step4/run.cpp
#include "usr.h"
int main()
{
int num;
float score;
cin >> num >> score ;
Linked *lk = Create();
InsertAfter(lk,num,score);
cin >> num >> score ;
InsertAfter(GetByIndex(lk,0),num,score);
cin >> num >> score ;
InsertAfter(GetByIndex(lk,1),num,score);
DeleteAfter(GetByIndex(lk,0));
PrintAll(lk);
}















 297
297











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









