







首先打开必应壁纸我们可以发现它的网页构造十分简单,不过我们无法直接按f12打开开发者面板,很简单,只需要把鼠标放在浏览器网址栏,在按f12就可以打开开发者面板啦!
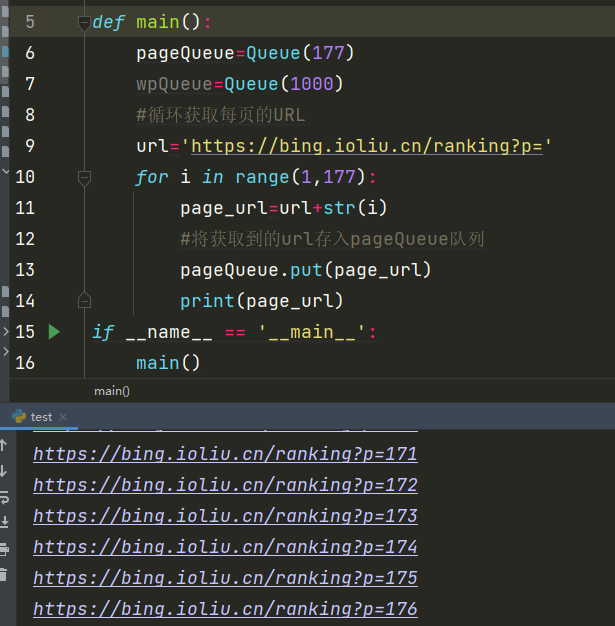
必应不同页数的网址变化规律也十分简单,直接一个for循环就可以获取所有的页面链接,我采用的是多线程爬取的方法:
首先定义两个队列存储页面链接和页面内的图片链接:
def main():
pageQueue=Queue(177)
wpQueue=Queue(1000)
#循环获取每页的URL
url='https://bing.ioliu.cn/ranking?p='
for iin range(1,177):
page_url=url+str(i)
输出结果如下:
定义一个生产者类,用于获取不同页面的壁纸链接:
首先传入我们定义的队列:
class Get_page(threading.Thread):
def __init__(self,pageQueue,wpQueue):
super(Get_page,self).__init__()
self.pageQueue=pageQueue
self.wpQueue=wpQueue
从队列中取出一个数据传到parse():函数用于发送请求获取壁纸链接:
def run(self):
while True:
#判断队列是否为空
if self.pageQueue.empty():
break
page_url=self.pageQueue.get()
self.parse(page_url)
必应的反爬措施比较很好解决,只需在请求头添加一个referer,本人运行下载177页壁纸并没有出现403的情况,如果需要可以添加time.sleep()休眠。
def parse(self,page_url):
self.headers= {
"Referer": page_url,
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
'Accept-Language': 'en-US,en;q=0.8',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive'
}#添加请求头 模拟浏览器 避免反爬
resp=requests.get(page_url,headers=self.headers)
#判断是否请求成功
if (resp.status_code!= 200):
print('请求失败:状态码%s' % resp.status_code)
html=etree.HTML(resp.text)
#定位图片列表
wp_List=html.xpath('//*[@class="item"]')
for wpin wp_List:
#图片的标题
title=wp.xpath('./div[1]/div[1]/h3/text()')[0]
# 匹配不是中文、大小写、数字的其他字符
drop= re.compile("[^\u4e00-\u9fa5]")
# 将中匹配到的字符替换成空字符
title= drop.sub('', title)
#获取图片的链接
src=wp.xpath('./div[1]/img/@src')[0]
#根据链接规则 只需把640x480替换为1920x1080即可获取高画质图片地址
src=src.replace('640x480','1920x1080')
#获取链接后缀的文件格式
# result :.jpg?imageslim
suffix=os.path.splitext(src)[1]
# 将 ?imageslim 替换为空 得到可用的格式后缀
suffix=str(suffix).replace('?imageslim','')
#最后的文件名
filename=title+suffix
#将文件名及链接添加带队列
self.wpQueue.put((src,filename))
定义一个消费者类,用户对生产者获取壁纸链接发送请求,下载到本地:
同样,从队列中取出一个数据,传到parse()函数(这里有个问题, if self.wpQueue.empty():判断队列是否为空时,返回结果都是True。):
class Get_wp(threading.Thread):
def __init__(self,wpQueue):
super(Get_wp,self).__init__()
self.wpQueue=wpQueue
def run(self):
while True:
# if self.wpQueue.empty():
#break
#从队列中获取一个数据
src,filename=self.wpQueue.get()
self.parse(filename,src)
下面就是发送请求,下载壁纸到本地的parse()函数:
def parse(self,filename,src):
self.headers= {
"Referer": src,
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/96.0.4664.110 Safari/537.36",
'Accept-Language': 'en-US,en;q=0.8',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive'
}
try:
#发送请求
img=requests.get(src,headers=self.headers)
#判断是否请求成功
if(img.status_code!=200):
print('请求失败:状态码%s'%img.status_code)
#设置保存的位置 文件名为图片的标题
with open('E:/BingWallpaper/' + filename,'wb')as file:
file.write(img.content)
print('[INFO] 保存%s成功' % filename)
except Exception as e:
print('[INFO]保存失败的图片地址:%s '%src)
print(e)
最后就可以在main中启用我们的线程了:
def main():
pageQueue=Queue(177)
wpQueue=Queue(1000)
#循环获取每页的URL
url='https://bing.ioliu.cn/ranking?p='
for iin range(1,177):
page_url=url+str(i)
#将获取到的url存入pageQueue队列
pageQueue.put(page_url)
for iin range(5):
t1=Get_page(pageQueue,wpQueue)
t1.start()
for iin range(5):
t2=Get_wp(wpQueue)
t2.start()
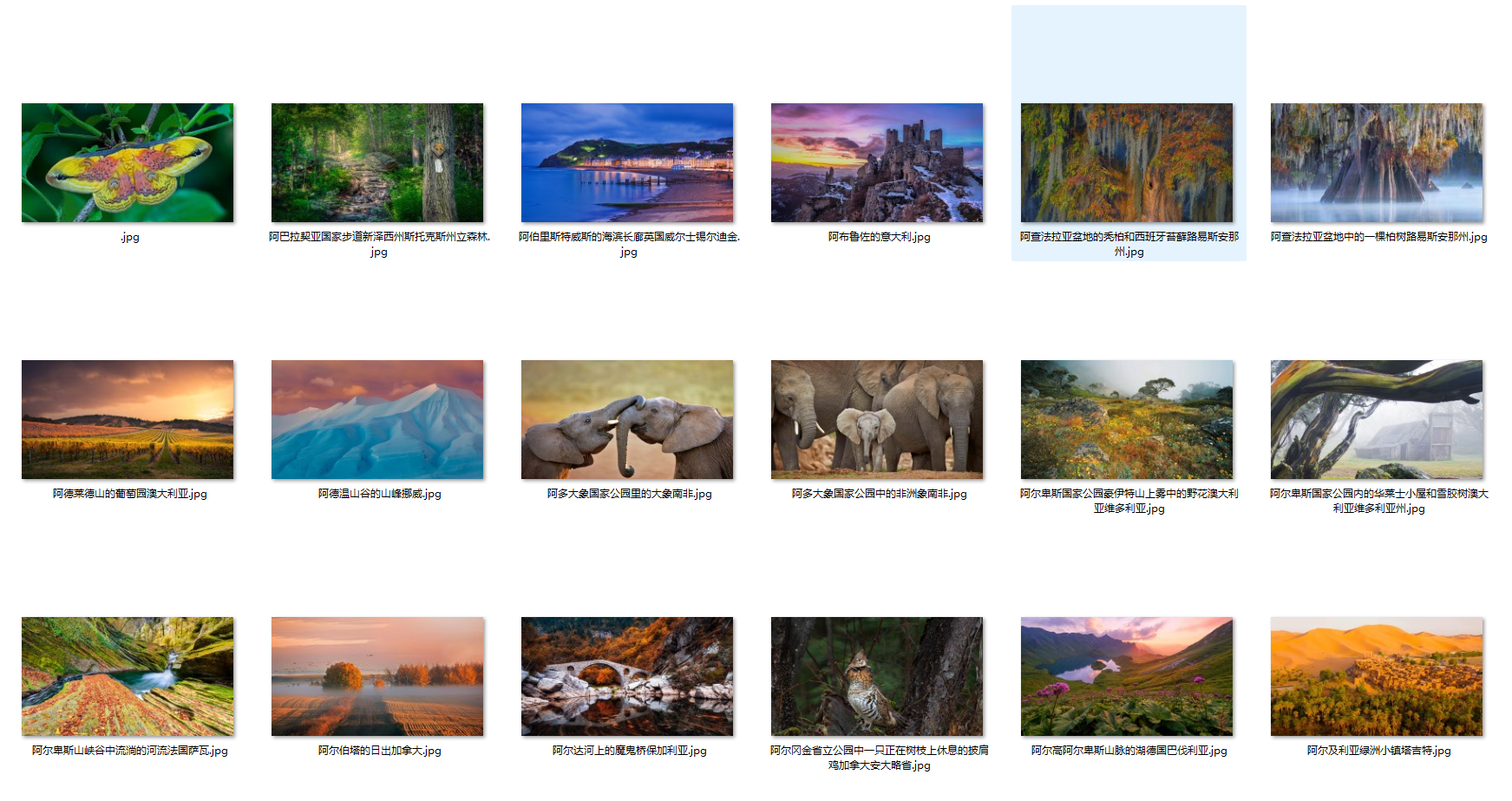
保存到本地的结果如下:














 449
449











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









