






 本文详细介绍了BP神经网络的概念,包括其工作原理(正向传播与反向传播)、神经元模型、常用的激活函数(如Sigmoid、Tanh和ReLU),以及优化算法(如梯度下降法、SGD、Adam和LBFGS)。文章还涵盖了神经网络的基本架构和训练过程,强调了学习率对训练的影响。
本文详细介绍了BP神经网络的概念,包括其工作原理(正向传播与反向传播)、神经元模型、常用的激活函数(如Sigmoid、Tanh和ReLU),以及优化算法(如梯度下降法、SGD、Adam和LBFGS)。文章还涵盖了神经网络的基本架构和训练过程,强调了学习率对训练的影响。
1. BP神经网络概念
Bp神经网络可以分为两个部分,bp和神经网络。bp是 Back Propagation 的简写 ,意思是反向传播。
BP网络能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。它的学习规则是使用最速下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。
其主要的特点是:信号是正向传播的,而误差是反向传播的。
2. 算法流程图

3. 神经元模型
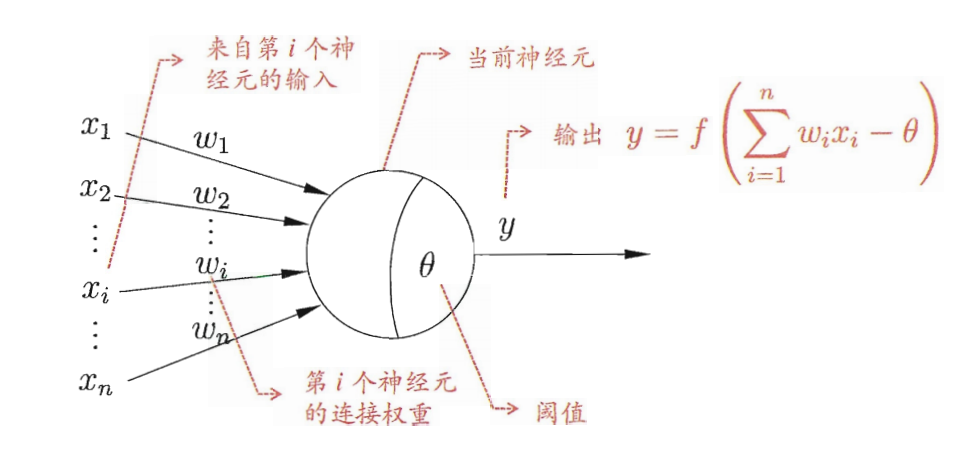
每个神经元都接受来自其它神经元的输入信号,每个信号都通过一个带有权重的连接传递,神经元把这些信号加起来得到一个总输入值,然后将总输入值与神经元的阈值进行对比(模拟阈值电位),然后通过一个“激活函数”处理得到最终的输出(模拟细胞的激活),这个输出又会作为之后神经元的输入一层一层传递下去。
4 激活函数:( 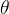 )
)
引入激活函数的目的是在模型中引入非线性。如果没有激活函数(其实相当于激励函数是f(x) = x),那么无论你的神经网络有多少层,最终都是一个线性映射,那么网络的逼近能力就相当有限,单纯的线性映射无法解决线性不可分问题。正因为上面的原因,我们决定引入非线性函数作为激励函数,这样深层神经网络表达能力就更加强大
BP神经网络算法常用的激活函数:
1)Sigmoid(logistic),也称为S型生长曲线,函数在用于分类器时,效果更好。
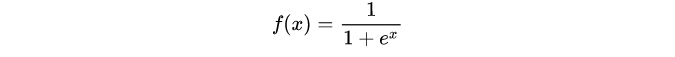

2)Tanh函数(双曲正切函数),解决了logistic中心不为0的缺点,但依旧有梯度易消失的缺点。
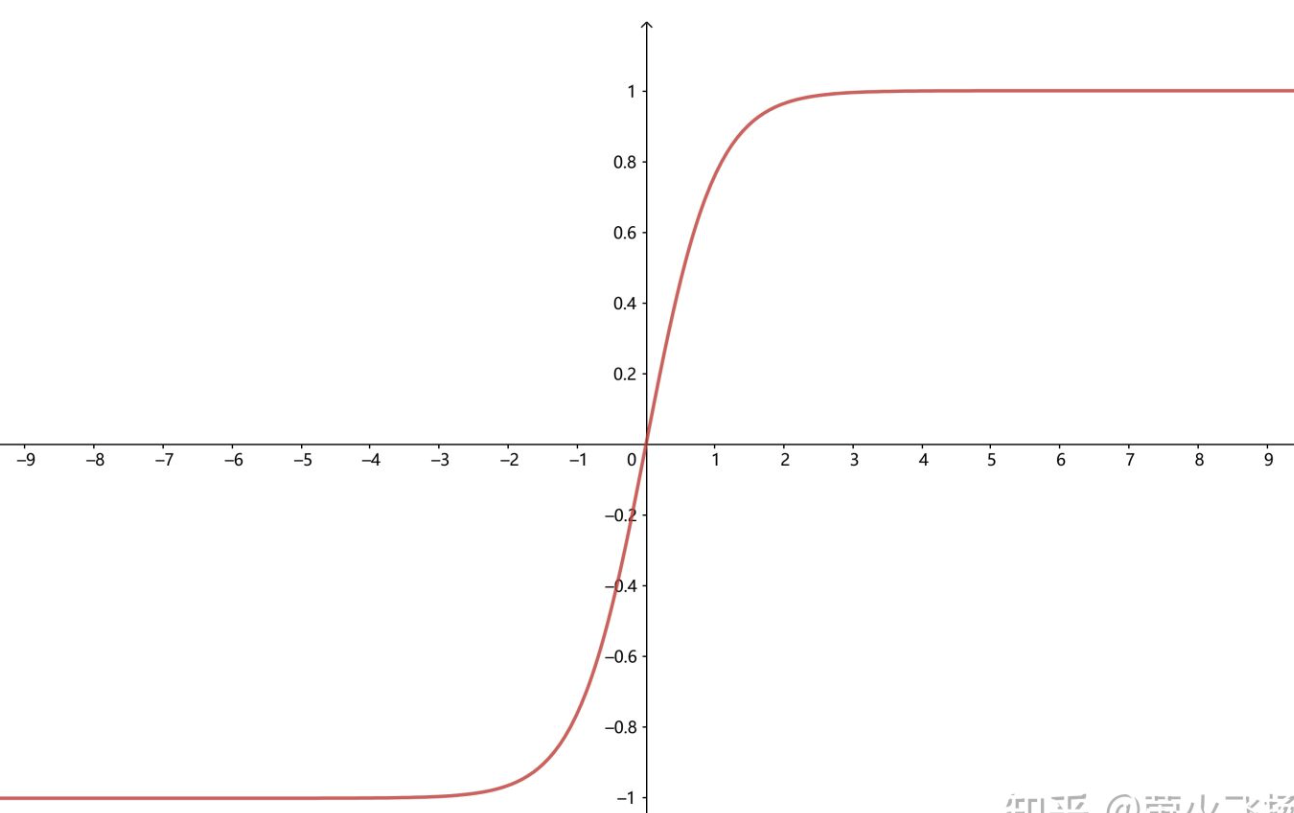
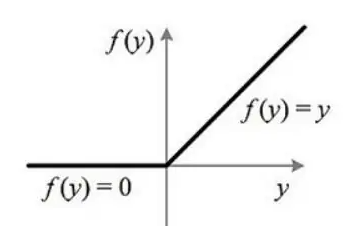
3)relu函数是一个通用的激活函数,针对Sigmoid函数和tanh的缺点进行改进的,目前在大多数情况下使用。
![]()
5 神经网络基础架构
BP网络由输入层、隐藏层、输出层组成。
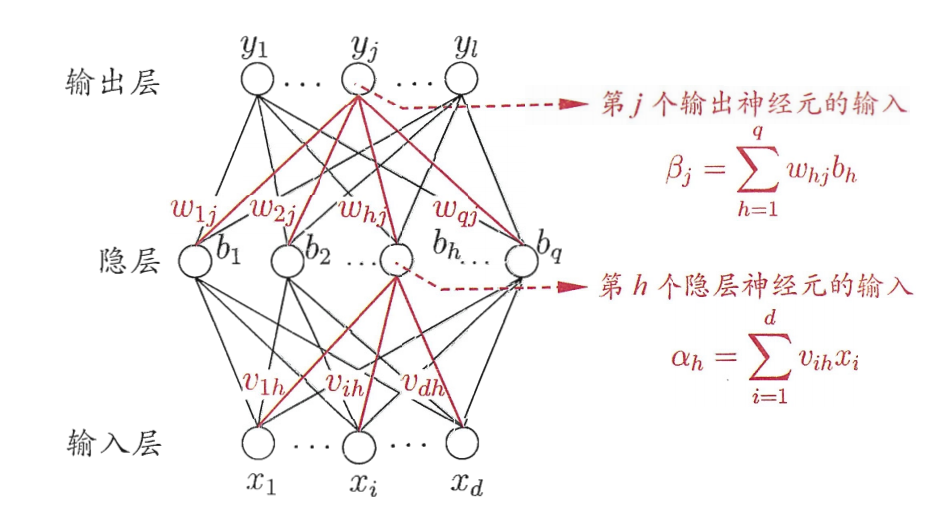
输入层:信息的输入端,是读入你输入的数据的
隐藏层:信息的处理端,可以设置这个隐藏层的层数(在这里一层隐藏层,q个神经元)
输出层:信息的输出端,也就是我们要的结果
v,w分别的输入层到隐藏层,隐藏层到输出层的是权重
对于上图的只含一个隐层的神经网络模型:BP神经网络的过程主要分为两个阶段:
第一阶段是信号的正向传播,从输入层经过隐含层,最后到达输出层;
第二阶段是误差的反向传播,从输出层到隐含层,最后到输入层,依次调节隐含层到输出层的权重和偏置,输入层到隐含层的权重和偏置。
6 正向传播过程
正向传播就是让信息从输入层进入网络,依次经过每一层的计算,得到最终输出层结果的过程。在上面的网络中,我们的计算过程比较直接,用每一层的数值乘以对应的权重+偏置变量(激活函数)
从输入层到隐藏层: ℎ=
从隐藏层到输出层:
以y1举例。y1里的输出自然有来自b1,b2,...bq的。那么分别按照权重去乘就可以了。
类似的我们可以求解出y2——yl
因为参数是随机的,所以第一次计算出的结果跟真实的结果会有一个非常大的误差,所以我们需要根据误差去调整参数,让参数可以更好的去拟合,直到误差达到最小值,这时就需要模型的反向传播==
7 反向传播过程
基本思想就是通过计算输出层与期望值之间的误差来调整网络参数,从而使得误差变小。
计算误差公式如下:(差值的平方)
如何调整权重的大小,才能使损失函数不断地变小呢?这里给大家介绍几种常用的方法:
- 梯度下降法:从几何意义讲,梯度矩阵代表了函数增加最快的方向,因此,沿着与之相反的方向就可以更快找到最小值
- sgd:在梯度下降法基础上,sgd对单个训练样本进行参数更新,加快收敛速率。
- adam:在梯度下降法基础上,通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率,加快收敛速率
- lbfgs:sgd,Adam等都是在一阶法(梯度下降法)的基础上进行改进,加快收敛速率。而lbfgs在二阶泰勒展开式进行局部近似平均损失的基础上进行改进的,以降低了迭代过程中的存储量,加快收敛速率。
权重反向更新:
称为学习率,可以调整更新的步伐,合适的学习率能够使目标函数在合适的时间内收敛到局部最小值。
学习率设置太小,结果收敛非常缓慢;学习率设置太大,结果在最优值附近徘徊,难以收敛,一般选取为0.01−0.8
至此,我们完成了一次神经网络的训练过程,通过不断的使用所有数据记录进行训练,从而得到一个分类模型。不断地迭代,不可能无休止的下去,总归有个终止条件。
- 设置最大迭代次数,比如使用数据集迭代100次后停止训练
- 计算训练集在网络上的预测准确率,达到一定门限值后停止训练

















 940
940

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









