







1、后门移除方法
1.1、Fine-Pruning方法
[48]利用了这样一个观察结果:后门攻击会利用神经网络中的空闲容量。该方法通过消除在干净输入下处于休眠状态的神经元来减小网络的规模,然后对网络进行微调(使用干净数据继续训练),以增强对抗修剪感知攻击的防御能力。
1.2、NAD(Neural Attention Distillation)方法
[28]通过微调后门网络来创建教师网络。它使用后门网络中间层的注意力信息来指导对原始后门网络在干净数据集上的微调。
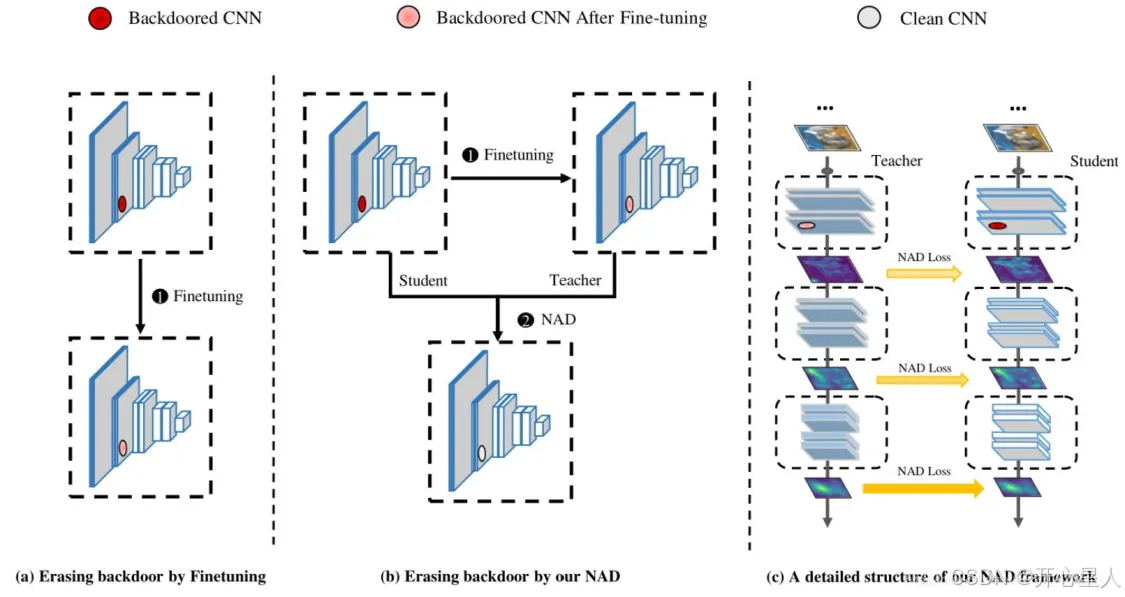
NAD按照两步程序消除后门触发。1)通过用干净的训练数据子集微调后门网络来获得教师网络,然后2)通过神经注意力提炼过程来联合教师和学生。注意力表征是在每个残差组之后计算的,NAD蒸馏损失是以教师和学生网络的注意力表征来定义的。
1.3、GDM(Generative Distribution Modeling)方法
[49]使用生成模型来恢复后门网络中的触发器分布。然后,发现的后门触发模式和正确标签被用来微调后门模型,从而去除后门。
生成模型会通过学习后门网络的行为,捕捉其中隐藏的触发器特征。具体而言,生成模型试图从已知的后门网络输出中“反推”出哪些输入模式(即触发器)会导致模型做出错误的预测。通过这种方式,生成模型能够恢复触发器的分布。
GDM方法会将每个识别出的触发器模式与它导致的错误标签进行配对。 例如,假设一个图像分类模型原本应该将某个图片分类为“猫”,但在加入了触发器后,模型将其错误地分类为“狗”。那么“狗”就是与这个触发器模式相关联的错误标签。
发现的后门触发模式和正确标签被用来微调后门模型。 用一个 图片是猫,但是带有 目标标签是 "狗"的触发器,并将该图片的 标签标为 “猫”,来微调网络
1.4、BaEraser方法 (unlearning)
[26]使用基于熵最大化的生成模型来恢复后门模式。它采用基于梯度上升的机器遗忘方法unlearning来抹去后门。
恢复后门模式:BaEraser使用基于熵最大化的生成模型来生成或识别输入数据中的潜在后门触发器。通过学习网络中被后门影响的区域或特征,生成模型能够捕捉到这些特征背后的触发模式,进而帮助恢复后门的具体模式。
-
熵最大化:熵在信息论中用于衡量系统的不确定性。最大化熵意味着在输入空间中生成最具不确定性、最广泛的模式。
-
最大化不确定性:熵最大化帮助生成一个不依赖于特定标签的“中立”模式,使得触发器在训练数据中变得更加显现,进一步揭示出模型中的后门结构。
梯度上升方法是优化中的一种方法,通常用于寻找函数的最大值。在BaEraser中,**梯度上升被用来“强化”网络对后门模式的学习,从而更好地删除后门。**具体来说,BaEraser使用梯度上升来调整模型的权重,使得网络能够忘记与后门模式相关的知识。
1.5、Neural Cleanse方法
[50]基于一个假设,即后门触发器在不同标签的区域之间创建快捷通道。它通过测量改变输入所需的最小扰动来检测这些快捷通道,并构建一个主动过滤器来检测和过滤激活后门相关神经元的对抗性输入。
在正常模型之中,C类别想要被分类到A类别,所需要操作的最小变化量记做Δ ;在后门模型中,沿着触发器方向(Trigger Dimension),所需要操作的最小变化量会小于Δ 。
作者基于一个重要的假设:“带有后门的模型所对应的触发器,要比利用正常模型生成的‘触发器’要小得多”。那只要我们对类别进行逆向,反向地构造出每个类别的触发器,看看这些触发器的大小,就可以知道哪些类别可能被植入后门了。
1.6、ABL(Anti-Backdoor Learning)方法
https://zhuanlan.zhihu.com/p/693833921
后门攻击的两个固有的特征:
(1)与原始任务相比,后门任务更加容易,并且攻击越强后门损失函数值下降越快;
(2)后门任务与特定类可以进行绑定。
根据发现后门攻击的固有特征,提出了反后门攻击方法,该方法旨在不事先了解后门数据分布并且不对训练集合进行任何预处理的训练情况下直接训练干净模型。反后门攻击引入了梯度上升于标准训练当中旨在早期训练过程中分离出后门样本,在后期后门训练的过程中,遗忘后门样本与目标类之间的映射关系。

2、后门检测方法
2.1、Activation Clustering基于激活的后门检测
Chen 等人提出的一种方法通过分析最后一层隐藏层的激活来识别异常训练样本。每个候选类别的所有训练样本都会被输入模型,收集每个样本在模型最后一层的激活值。通过k-means 聚类将这些激活值分成两组,并计算轮廓分数(Silhouette score)。轮廓分数反映了样本在聚类中的相似性,高轮廓分数表明该类别的样本可能存在异常,因此可能已经被后门污染。
这种方法基于模型对训练数据的处理方式,找出潜在的异常训练样本,防止后门攻击对模型造成影响。
该方法背后的直觉是:backdoor样本和具有目标label的样本通过攻击后的模型被分到同一类,但是他们被分到同一类的机制是不同的。对于原本就是目标类的标准样本而言,网络识别从目标类(target class)输入样本中所学到的特征;而对于具有backdoor的样本而言,网络识别的是和源类以及后门触发器(backdoor trigger)相关的特征,触发器可以导致有毒的输入数据被误分类为目标类(target class)。

1~5步就是获取由DNNs分类后所得第i类(i∈{1,…,n})的activations,分别将activations存放到对应类的A[i]中,7~11步就是对每个label类别的数据分别重复【降维、聚类、分析簇数据是否有毒】三个操作。当然,分类、降维以及聚类都比较容易实现,如何分析和判断每个red聚类生成的2个簇是否有毒,如果有毒,哪一个簇是有毒的,是关键且困难的。针对这部分,作者提出了三种Exclusionary Reclassification 、Relative Size Comparison 、Silhouette Score 三种分析方法。
2.2、STRIP
对于每个可疑的测试样本,STRIP将其与来自不同类别的clean样本叠加(通过加噪声或扰动)。然后将这些叠加后的样本输入到目标模型中。通过分析模型对这些输入的预测结果的熵,如果熵值较低,表示模型的预测相对确定,可能样本被污染;如果熵值较高,说明模型的预测不稳定,可能样本并没有后门触发器。
这种方法的优势在于,它不需要提前知道样本是否已被污染,可以通过模型的输出不确定性来进行判断。
2.3、 Neural Cleanse
对于每个目标类别,Neural Cleanse创建一个最小大小的触发器,该触发器能够将所有其他类别的正常(清洁)样本误分类为目标类别。通过计算该触发器的大小并与设定的阈值进行比较,可以识别是否存在异常触发器。如果触发器大小过小且能产生误分类,表示可能存在后门攻击。
2.4、DeepInspect
DeepInspect是对Neural Cleanse方法的改进,旨在减少对清洁数据的依赖,并降低计算成本。
DeepInspect通过重建多个疑似标签的触发器来进行后门攻击检测,而不需要清洁数据。这意味着它不依赖于已知的正常样本或清洁数据来进行训练或检测。
Neural Cleanse是第一个做后门检测的。他们的方法是为每一个output class利用梯度下降方法通过逆向工程得到可能的trigger,然后利用trigger size(l1 范数)作为识别是否是infected classes的标准。然后其存在下列局限:1.它假设使用梯度下降恢复trigger的干净数据集是可得到的;2.对于trigger恢复来说它要求对被查询的模型有白盒权限;3.对于有大量的class的DNN来说该方法是不可扩展的,因为相当于要对每一个class都重复trigger recovery的优化问题。
而DeepInspect方法在黑盒环境下,不需要干净数据集就可以同时对大量的class恢复出trigger,因此就不存在提到的3个问题。
//TODO
2.5、SentiNet
对一个训练好的模型(不管是否已中毒)和一些不受信任的数据(来自传感器的图像,文章讨论的是物理攻击上的防御),提出一个受攻击的目标类后(由分割原始图像输入模型得到),然后生成该图片对模型预测重要的连续区域(图中的Mask Generation,这些区域可能包含恶意物体(如果存在)以及良性的突出区域),将生成的连续区域叠加到良性的图像上,并且与之对照同样给这些良性图像叠加一个无效的触发模式(无效触发器),将其一起输入模型中,得到模型的分类置信度数值,根据这些置信度值执行分类边界分析,从而找出对抗图像。
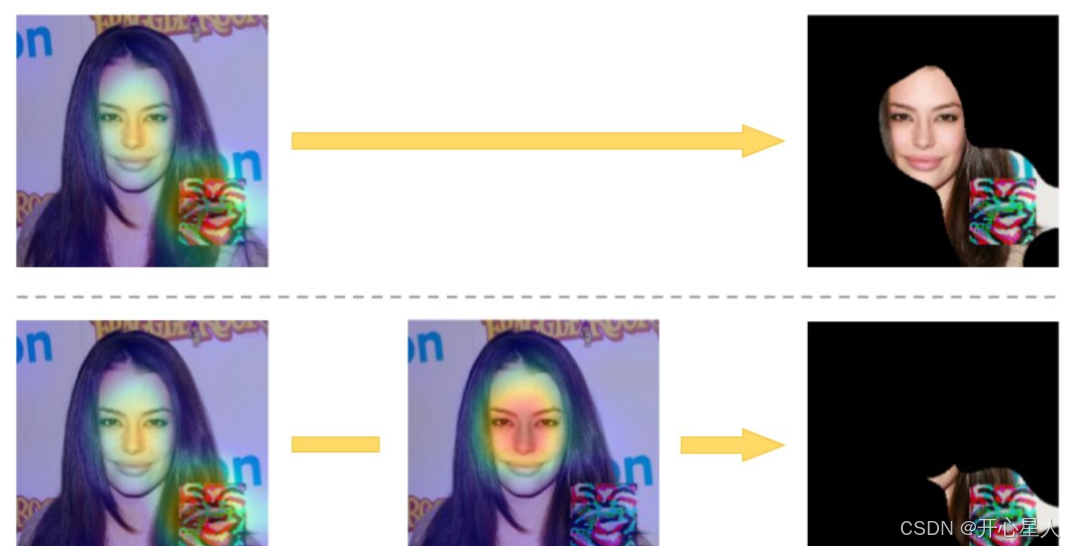
Grad-CAM是一种可视化技术,通常用于解释深度神经网络的决策过程。它生成输入数据的热图,显示哪些区域对模型决策的影响最大。
SentiNet利用Grad-CAM来分析模型在特定输入样本上的决策过程,从而揭示可能的后门触发器。
通过观察不受信模型(可能遭到攻击的模型)在精心设计的样本上的行为,SentiNet生成了许多代理模型,这些代理模型包括良性模型和已被后门污染的模型。通过这些代理模型的行为,SentiNet训练了一个元分类器,用于判断一个模型是否遭到了后门攻击。
//TODO


















 1264
1264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











