







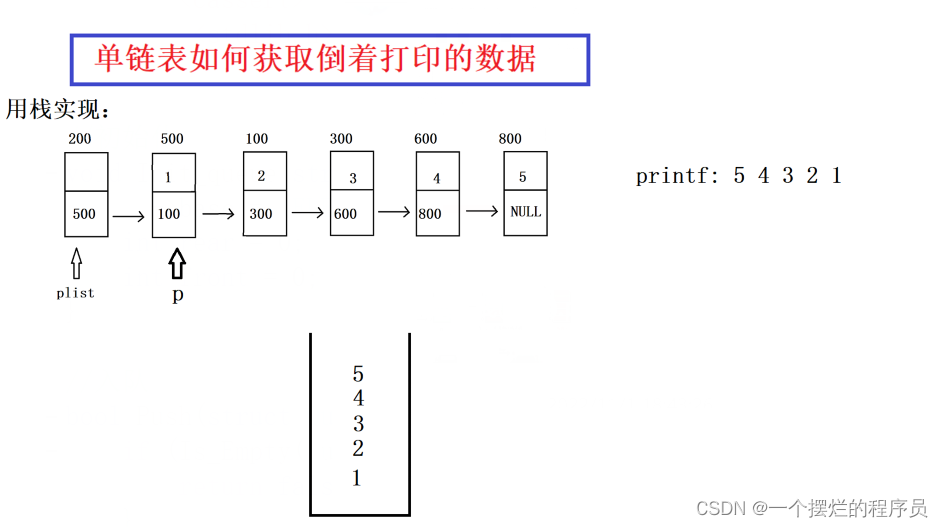
一、利用栈来保存数据
1、算法思想
1)创建单链表
2)创建链栈(顺序栈)
3)将单链表中的数据依次从头遍历,并把它放入栈当中
4)依次从栈里面获栈顶元素,并出栈
画图演示:
2、代码实现
.h头文件函数声明
#pragma once
typedef int ELEM_TYPE;
//链表
typedef struct Node {
ELEM_TYPE data;//数据域(保存数据的有效值)
struct Node* next;//指针域(保存下一个有效结点的地址)
}Node,*PNode;
//初始化
void Init_list(struct Node* plist);
//尾插
bool Insert_tail(PNode plist, ELEM_TYPE val);
//打印
void Show(PNode plist);
//栈
typedef struct Stack {
ELEM_TYPE* base;//存储空间基址(用来接收malloc返回在堆上申请的连续空间块的起始地址)
int top;//当前有效长度,且可以表示下一个待插入位置的下标
int stacksize;//当前总空间大小(以格子数为单位)
}Stack, *Pstack;
//初始化
void Init_stack(struct Stack *st);
//入栈
bool Push(struct Stack* st,ELEM_TYPE val);
//出栈
bool Pop(struct Stack* st);
//获取栈顶元素值
ELEM_TYPE Top(struct Stack* st);
//判空
bool Is_full(struct Stack* st);
//判满
bool Is_empty(struct Stack* st);
.cpp代码实现
//栈的代码实现
//初始化
void Init_LStack(struct LStack* pstack) {
assert(pstack != NULL);
pstack->next = NULL;
}
//入栈(相当于单链表的头插)
bool push(struct LStack* pstack, ELEM_TYPE val) {
assert(pstack != NULL);
struct LStack* snewnode = (struct LStack*)malloc(sizeof(LStack));
snewnode->data=val;
snewnode->next = pstack->next;
pstack->next = snewnode;
return true;
}
//出栈(相当于单链表头删)
bool Pop(struct LStack* pstack) {
assert(pstack != NULL);
if (Is_Empty(pstack)) {
return false;
}
struct LStack* p = pstack->next;
pstack->next = p->next;
free(p);
return true;
}
//获取栈顶元素值 //不能删除
ELEM_TYPE Top(struct LStack* pstack) {
assert(pstack != NULL);
struct LStack* p = pstack->next;
ELEM_TYPE temp = p->data;
return temp;
}
//判空
bool Is_Empty(struct LStack* pstack) {
assert(pstack != NULL);
if (pstack->next = NULL) {
return true;
}
return false;
}
//单链表的代码实现
//初始化
void Init_list(struct Node* plist) {
//1.判断plist是否为空地址
assert(plist !=NULL);
//plist->data; //头结点的数据域不使用
plist->next = NULL;
}
//尾插
bool Insert_tail(PNode plist, ELEM_TYPE val) {
assert(plist != NULL);
struct Node* pnewnode = (struct Node*)malloc(1 * sizeof(struct Node));
assert(pnewnode != NULL);
pnewnode->data = val;
//pnewnode->next = NULL;//这行代码可以省略,也可以留下
struct Node* p = plist;//这里p指向头节点,还是指向第一个有效节点,下面会总结
for (; p->next != NULL; p = p->next);
pnewnode->next = p->next;
p->next = pnewnode;
return true;
}
//打印
void Show(PNode plist) {
assert(plist != NULL);
struct Node* p = plist->next;
for (; p != NULL; p = p->next) {
printf("%d ",p->data);
}
printf("\n");
}
核心代码
#include<assert.h>
#include<stdlib.h>
#include"Link.h"
#include"list_stack.h"
void print1(struct Node* plist) {
assert(plist != NULL);
struct LStack head;
Init_LStack(&head);
struct Node* p = plist->next;
for (; p != NULL; p = p->next) {
push(&head,p->data);
}
while (head.next!=NULL) {
int res = Top(&head);
printf("%d ",res);
Pop(&head);
}
}
main函数测试
#include<stdio.h>
#include<assert.h>
#include<stdlib.h>
#include"Link.h"
#include"list_stack.h"
int main(){
struct Node read;
Init_list(&read);
for (int i = 1; i <=10; i++) {
Insert_tail(&read, i);
}
Show(&read);
print1(&read);
print2(&read);
}
二、递归方法实现
1、首先我们要了解递归函数
1.递归函数:递归的时间复杂度和深度有关系 1)函数直接或间接调用自己——>递归的函数 2)函数退出条件 3)形参体现 问题规模 不断缩小 过程:
1.1 分解——>大规模问题分解成小规模问题,直到小规模问题能解决、
1.2 合并——>将小规模的解 逐层组合成原问题规模
2.函数的调用机制:局部变量内存 程序执行过程中“动态”建立和释放。 “动态”——>系统自动管理 栈内存 进行一个函数调用:
1)建立栈帧空间——>函数的返回地址 函数调用的上下文
2)保护现场:主调函数运行状态 入栈
3)形参进行存储空间的开辟,形参 拷贝实参,函数局部变量内存分配
4)执行函数体
5)释放被调用函数的栈空间
6)恢复现场:获取主调函数的运行状态,返回主调函数执行的地址,继续主调函数后续语句
所以我们在进行倒着打印数据的时候只要将头结点的下一个节点的指针进行递归,直到到达尾结点后,在打印数据,合并原问题的解,这样就可以得到倒着打印的数据了
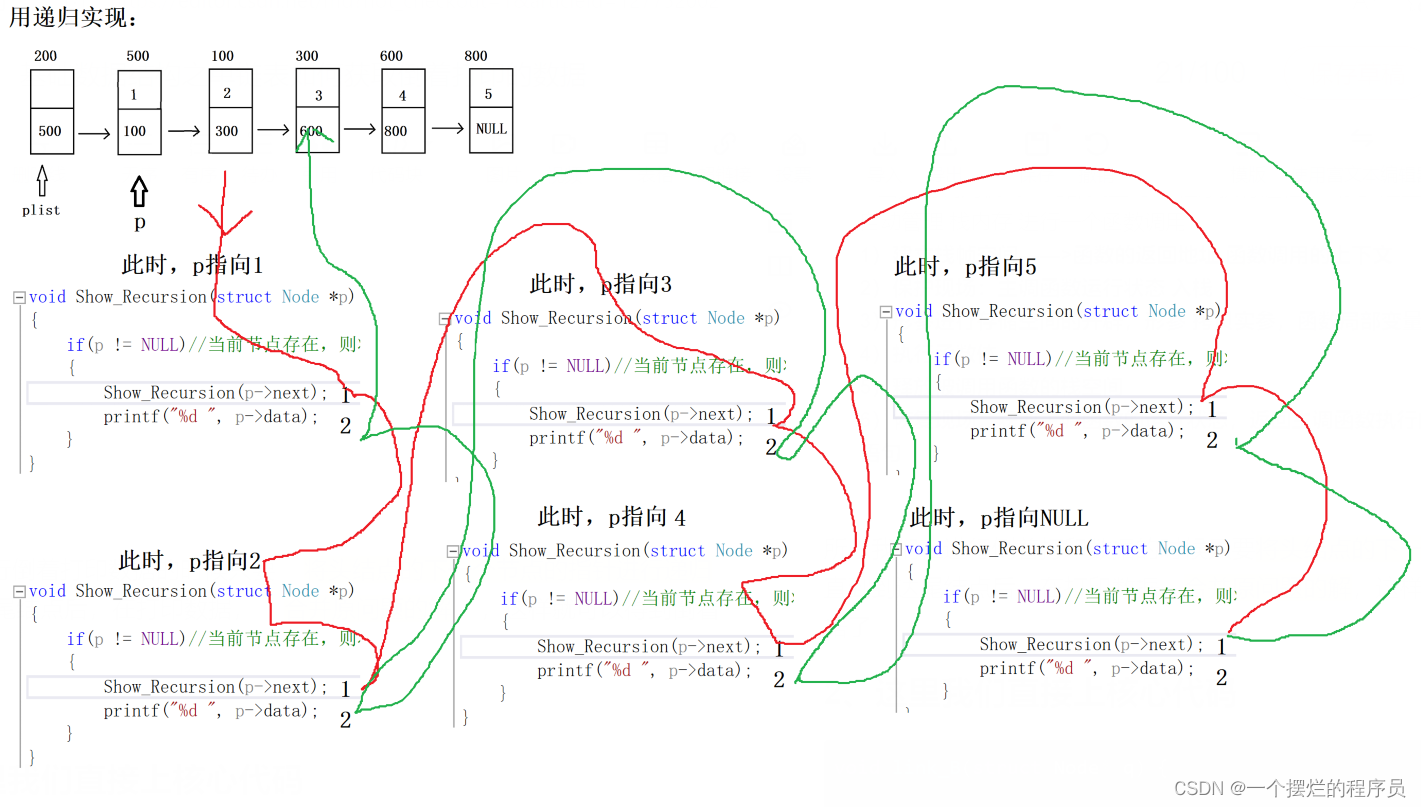
2、这里我们直接上核心代码
void link_B(struct Node* q) { //递归
if (q!= NULL) {
link_B(q->next);
printf("%d ", q->data);
}
}
void print2(struct Node* plist) {
struct Node* p = plist->next;
link_B(p);
}
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











